
标准 检索增强生成 遵循一种可预测的线性路径:接收查询,检索相关文档,然后生成响应。在许多情况下,这可能足以解决特定问题。在最坏的情况下,您的 LLM 只会决定不回答该问题,因为上下文没有提供足够的信息。
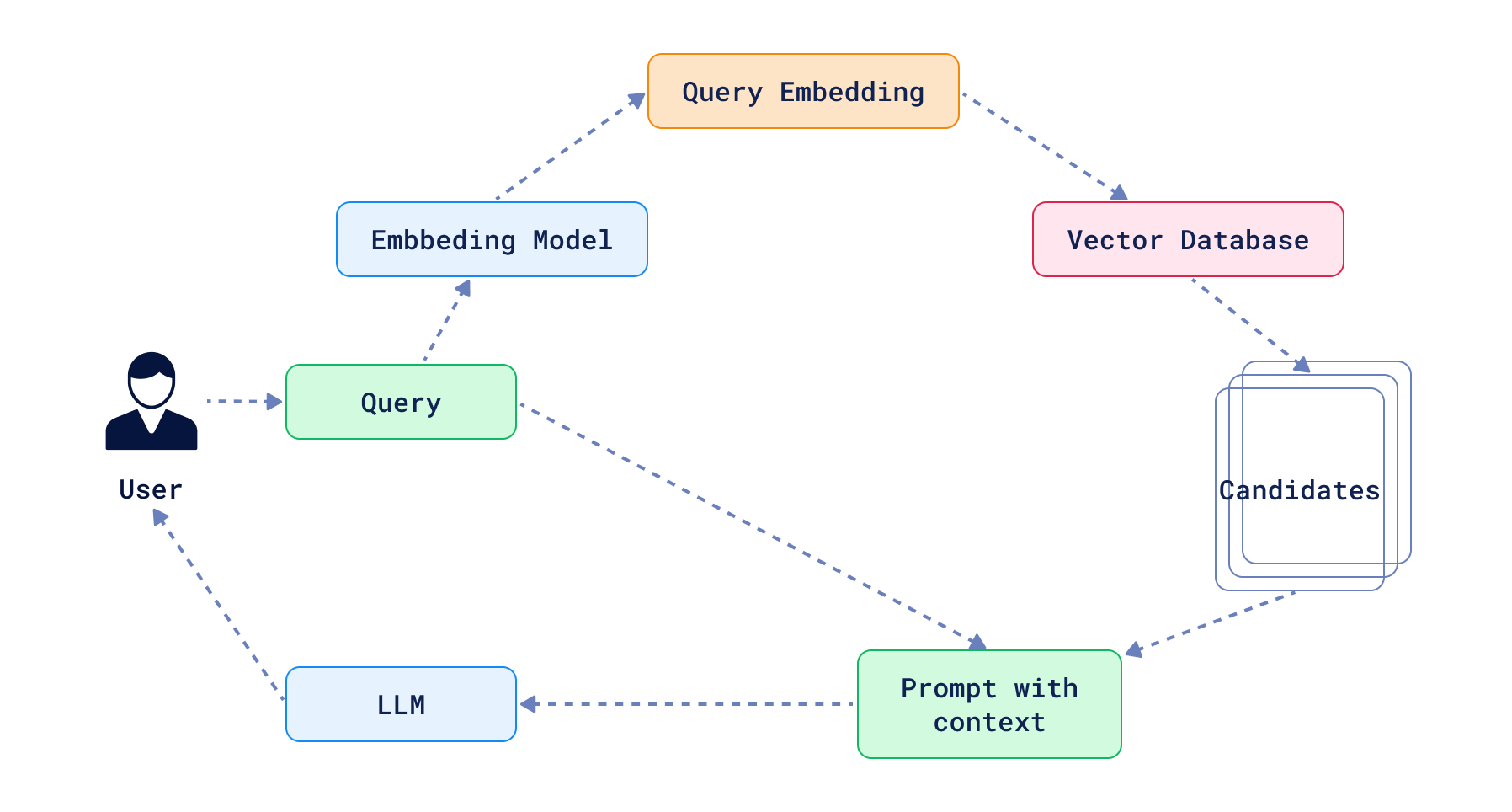
另一方面,我们有代理(agent)。这些系统被赋予了更大的行动自由,可以采取多个非线性步骤来实现特定目标。关于代理是什么没有单一的定义,但总的来说,它是一个使用 LLM 和通常一些工具与外部世界通信的应用程序。LLM 被用作决策者,决定下一步要采取什么行动。行动可以是任何事情,但通常是定义明确的,并限于一定的可能性集合。如果上下文不足以做出决定,其中一个行动可能是查询向量数据库(如 Qdrant)以检索相关文档。然而,RAG 只是代理工具箱中的一个工具。
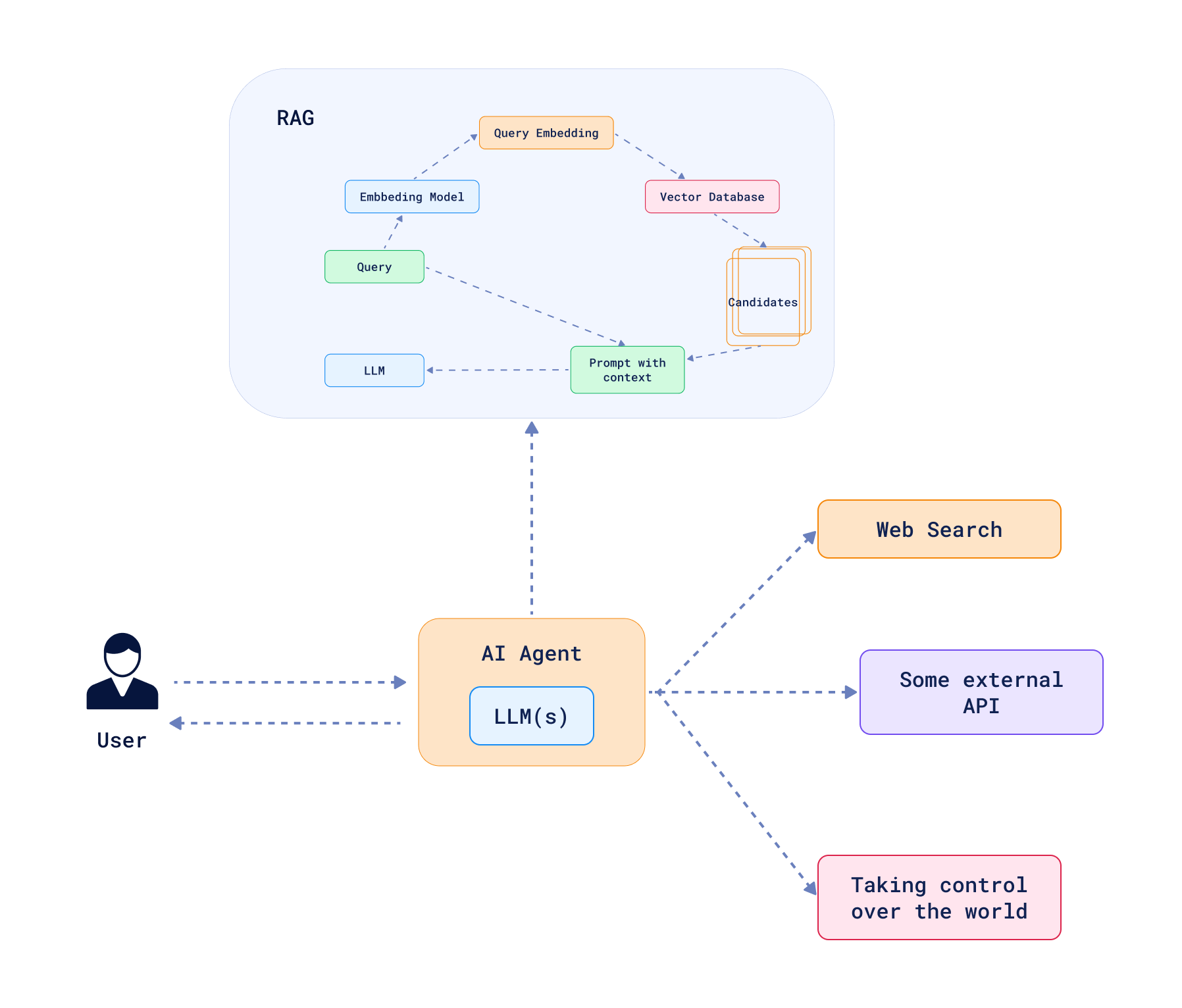
Agentic RAG:将 RAG 与代理相结合
由于代理的定义模糊,Agentic RAG 的概念也尚未明确定义。总的来说,它指的是 RAG 与代理的结合。这使得代理能够利用外部知识源做出决策,主要是决定何时需要外部知识。如果一个系统打破了标准 RAG 系统的线性流程,并赋予代理采取多步骤实现目标的能力,我们可以将其描述为 Agentic RAG。
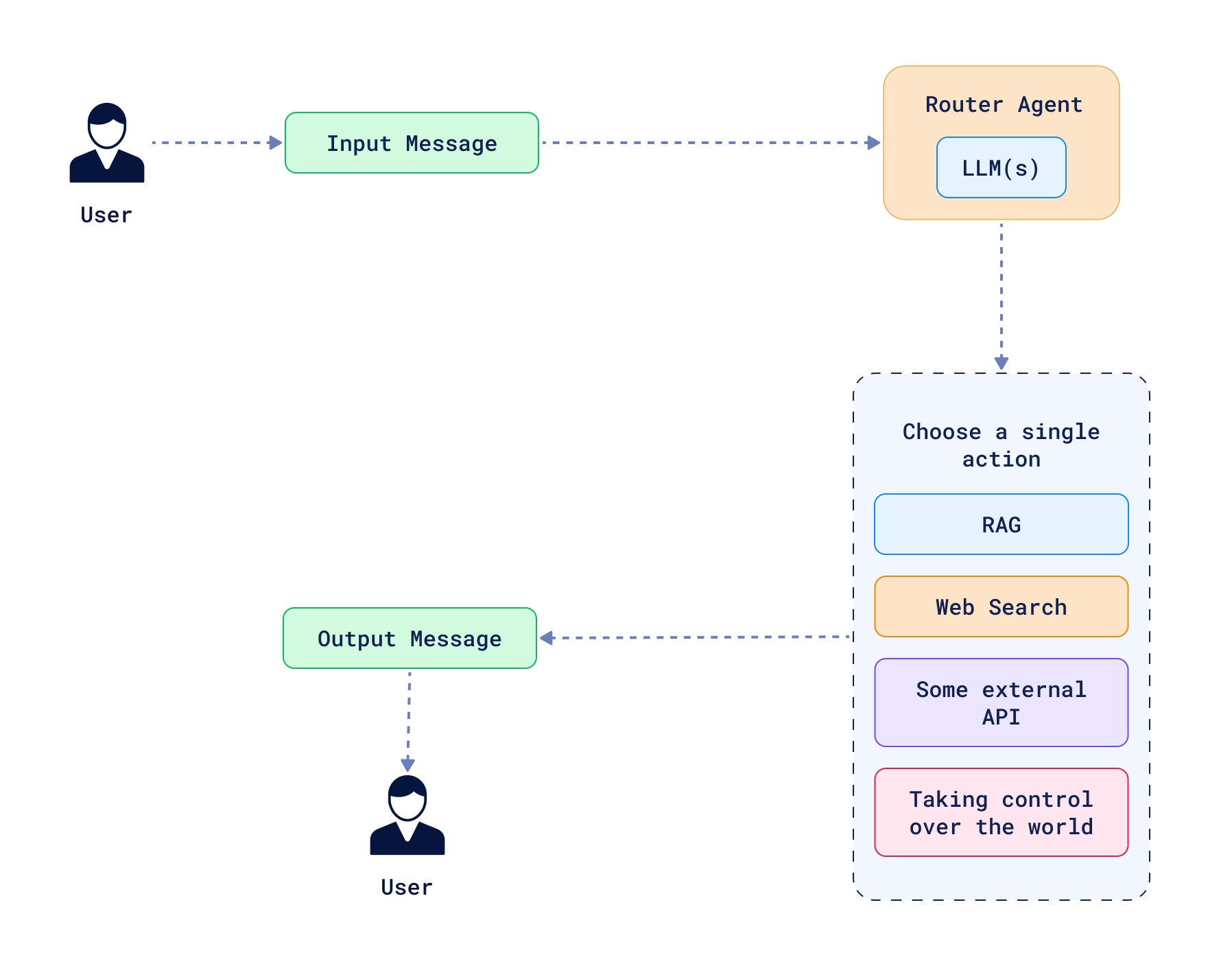
一个选择遵循路径的简单路由器通常被描述为代理最简单的形式。这样的系统有多个路径,并带有描述何时采取特定路径的条件。在 Agentic RAG 的上下文中,如果上下文不足以回答问题,代理可以决定查询向量数据库;如果上下文足够,则跳过查询;或者当问题涉及常识时跳过。另外,可能有多个集合存储不同类型的信息,代理可以根据上下文决定查询哪个集合。关键因素在于,选择路径的决定是由 LLM 做出的,这是代理的核心。路由代理从不返回上一步,因此它本质上只是一个条件决策系统。
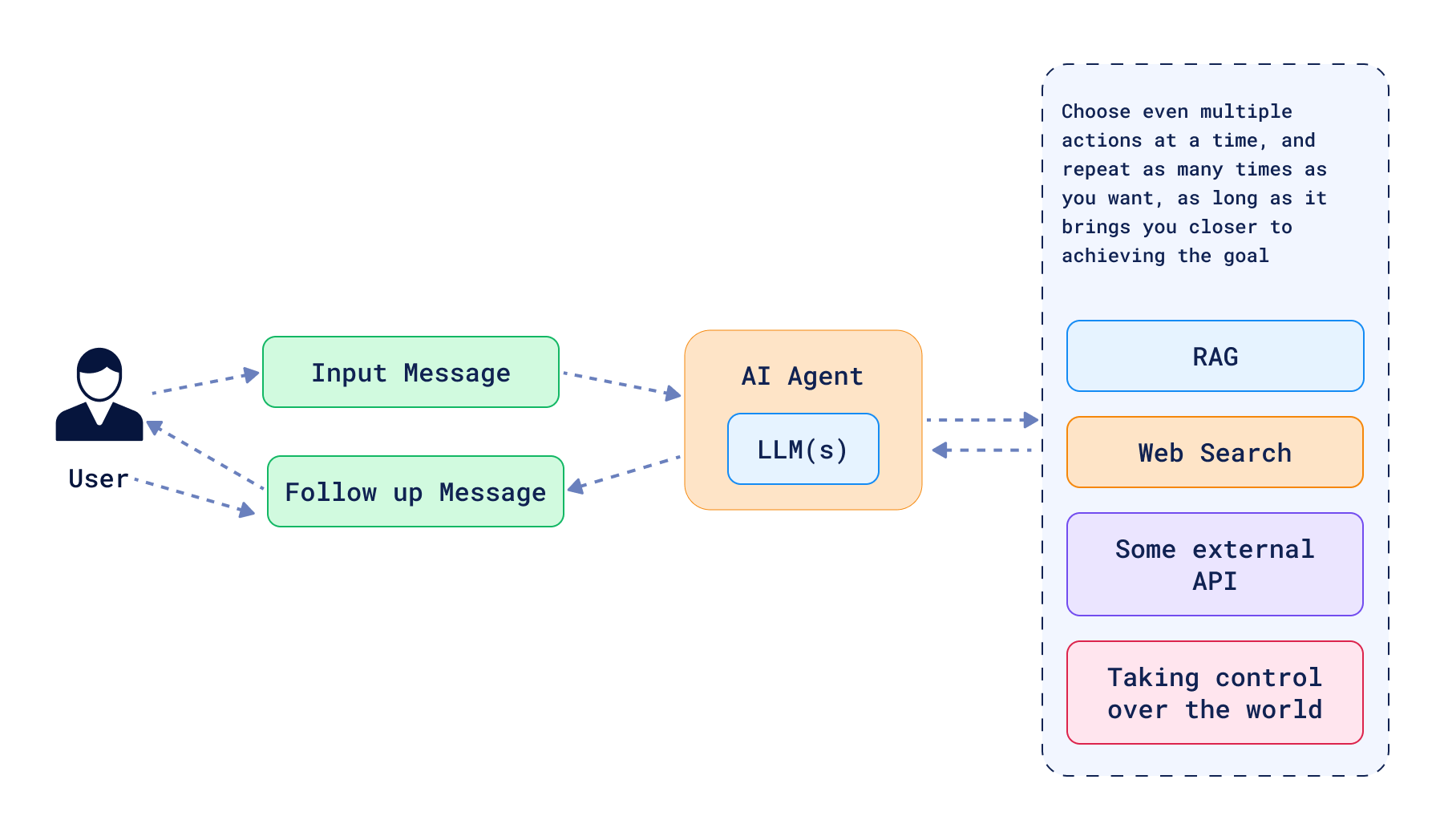
然而,路由只是开始。代理可以复杂得多,极端形式的代理可以拥有完全的行动自由。在这种情况下,代理被赋予一套工具,并可以自主决定使用哪些工具、如何使用以及按什么顺序使用。LLM 被要求规划和执行行动,代理可以采取多个步骤来实现目标,包括必要时回溯。这样的系统不必遵循 DAG 结构(有向无环图),并且可以有循环来帮助自我纠正过去做出的决定。以这种方式构建的 Agentic RAG 系统不仅可以拥有查询向量数据库的工具,还可以对查询进行操作、总结结果,甚至生成新数据来回答问题。可能性是无限的,但在实际中可以观察到一些常见模式。
使用 LLM 解决信息检索问题
总的来说,Agentic RAG 系统中暴露的工具用于解决信息检索问题,这对于搜索社区来说并不新鲜。LLM 改变了我们处理这些问题的方式,但问题的核心保持不变。在 Agentic RAG 中,您可以考虑使用哪些类型的工具?以下是一些示例
- 查询向量数据库 - Agentic RAG 系统中最常用的工具。它允许代理根据查询检索相关文档。
- 查询扩展 - 一个可用于改进查询的工具。它可以用于添加同义词、纠正拼写错误,甚至根据原始查询生成新的查询。

- 提取过滤器 - 仅凭向量搜索有时是不够的。在许多情况下,您可能希望根据特定参数缩小结果范围。这个提取过程可以自动从查询中识别出相关的条件。否则,您的用户将不得不手动定义这些搜索约束。
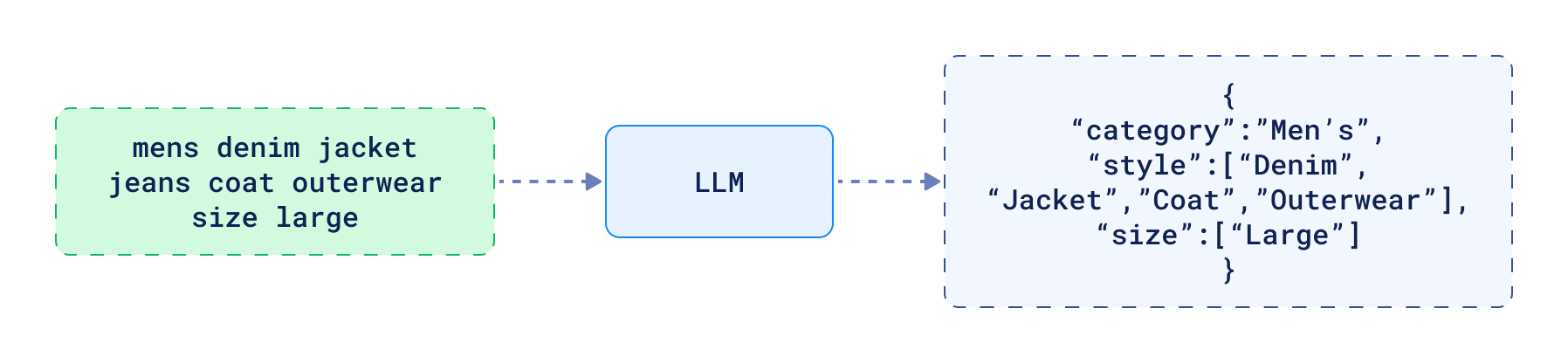
- 质量判断 - 了解给定查询结果的质量可用于决定它们是否足以回答问题,或者代理是否应采取进一步步骤以某种方式改进它们。或者,它也可以承认未能提供良好响应。
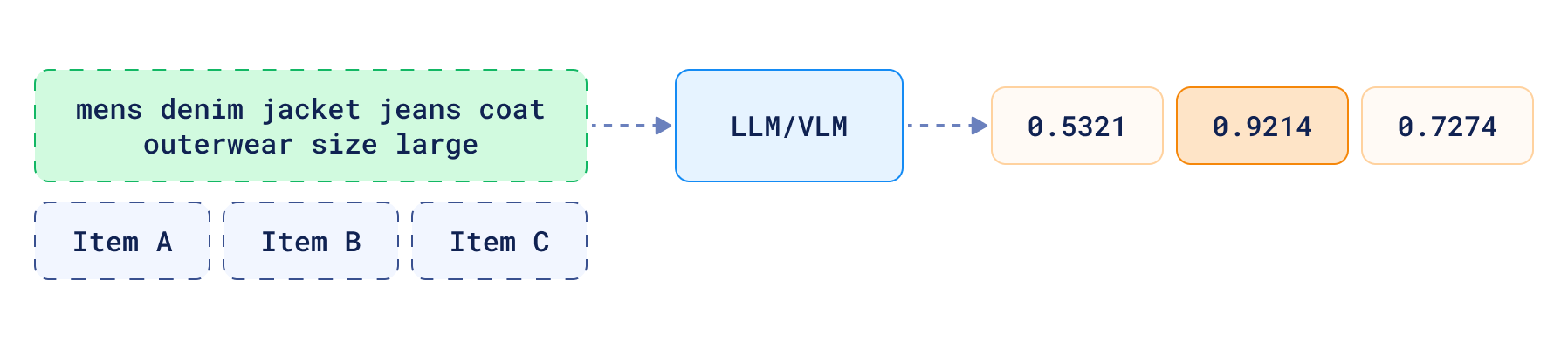
这些只是一些示例,但列表并未详尽。例如,您的 LLM 可能可以调整 Qdrant 的搜索参数,或者选择不同的查询方法。举个例子?如果您的用户使用某些特定关键词进行搜索,您可能更偏好稀疏向量而不是密集向量,因为在这种情况下它们更高效。在这种情况下,您必须为您的代理配备工具,以便决定何时使用稀疏向量以及何时使用密集向量。了解集合结构的代理可以轻松做出此类决定。
这些工具中的每一个都可能是一个独立的代理,多代理系统并不少见。在这种情况下,代理之间可以相互通信,一个代理可以决定使用另一个代理来解决特定问题。Agentic RAG 中一个非常有用的组件是人类参与(human in the loop),它可以用来纠正代理的决定,或者将其引导到正确的方向。
代理的应用场景?
代理是一个有趣的概念,但由于它们严重依赖 LLM,因此并非适用于所有问题。使用大型语言模型既昂贵又往往很慢,在许多情况下不值得花费成本。标准 RAG 只涉及对 LLM 的一次调用,并且响应以可预测的方式生成。另一方面,代理可以采取多个步骤,用户感受到的延迟会累积。在许多情况下,这是不可接受的。Agentic RAG 可能不太适用于电子商务搜索,用户期望快速响应;但对于客户支持可能没问题,因为用户愿意等待更长时间以获得更好的答案。
哪个框架最适合?
有许多可用于构建代理的框架,选择最佳框架并不容易。这取决于您现有的技术栈或您熟悉的工具。一些最流行的 LLM 库已经转向了代理范式,并提供了构建它们的工具。然而,也有一些主要为代理开发而构建的工具,因此让我们重点关注这些工具。
LangGraph
由 LangChain 团队开发,对于那些已经使用 LangChain 构建 RAG 系统并希望开始使用 Agentic RAG 的人来说,LangGraph 似乎是一个自然的扩展。
令人惊讶的是,LangGraph 本身与大型语言模型无关。它是一个用于构建基于图的应用程序的框架,其中每个节点是工作流程的一个步骤。每个节点将应用程序状态作为输入,并产生修改后的状态作为输出。然后状态被传递到下一个节点,依此类推。节点之间的边可以是条件性的,从而实现分支。与某些基于 DAG 的工具(例如 Apache Airflow)相反,LangGraph 允许图中存在循环,这使得实现循环工作流程成为可能,从而使代理能够实现自我反思和自我纠正。理论上,LangGraph 可以用于以基于图的方式构建任何类型的应用程序,而不仅仅是 LLM 代理。
LangGraph 的一些优点包括
- 持久性 - 工作流程图的状态被存储为检查点。这发生在每个所谓的超级步骤(即图中的单个顺序节点)。它使得重放工作流程的某些步骤、容错和包含人类参与成为可能。这个机制也充当短期记忆,可以在特定工作流程执行的上下文中访问。
- 长期记忆 - LangGraph 也有在不同工作流程运行之间共享的记忆概念。然而,这个机制必须由我们的节点显式处理。Qdrant 凭借其语义搜索能力,通常被用作长期记忆层。
- 多代理支持 - 虽然 LangGraph 中没有独立的多代理系统概念,但可以通过构建包含多个代理和某种监督者(决定在给定情况下使用哪个代理)的图来创建这种架构。如果一个节点可以是任何东西,那么它也可以是另一个代理。
LangGraph 的其他一些有趣特性包括可视化图的能力、自动化失败步骤的重试以及包含人类参与的交互。
一个 Agentic RAG 的最小示例可以改进用户查询,例如通过修正拼写错误、用同义词扩展查询,甚至根据原始查询生成新的查询。然后,代理可以根据改进后的查询从向量数据库检索文档,并生成响应。实现此方法的 LangGraph 应用程序可能如下所示
from typing import Sequence
from typing_extensions import TypedDict, Annotated
from langchain_core.messages import BaseMessage
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
class AgentState(TypedDict):
# The state of the agent includes at least the messages exchanged between the agent(s)
# and the user. It is, however, possible to include other information in the state, as
# it depends on the specific agent.
messages: Annotated[Sequence[BaseMessage], add_messages]
def improve_query(state: AgentState):
...
def retrieve_documents(state: AgentState):
...
def generate_response(state: AgentState):
...
# Building a graph requires defining nodes and building the flow between them with edges.
builder = StateGraph(AgentState)
builder.add_node("improve_query", improve_query)
builder.add_node("retrieve_documents", retrieve_documents)
builder.add_node("generate_response", generate_response)
builder.add_edge(START, "improve_query")
builder.add_edge("improve_query", "retrieve_documents")
builder.add_edge("retrieve_documents", "generate_response")
builder.add_edge("generate_response", END)
# Compiling the graph performs some checks and prepares the graph for execution.
compiled_graph = builder.compile()
# Compiled graph might be invoked with the initial state to start.
compiled_graph.invoke({
"messages": [
("user", "Why Qdrant is the best vector database out there?"),
]
})
过程中的每个节点都只是一个执行特定操作的 Python 函数。如果您愿意,可以在其中调用您选择的 LLM,但没有关于消息是由任何 AI 创建的假设。LangGraph 更像是一个运行时,它以特定顺序启动这些函数,并在它们之间传递状态。虽然 LangGraph 与 LangChain 生态系统很好地集成,但它可以独立使用。对于寻求额外支持和功能的团队,还有一个名为 LangGraph Platform 的商业产品。该框架适用于 Python 和 JavaScript 环境,使其可以在不同的技术栈中使用。
CrewAI
CrewAI 是构建代理(包括 Agentic RAG)的另一个流行选择。它是一个高级框架,假设有一些基于 LLM 的代理协同工作以实现共同目标。 CrewAI 中的“crew”(团队)正是由此而来。CrewAI 在设计时考虑了多代理系统。与 LangGraph 不同,开发者不创建处理图,而是定义代理及其在团队中的角色。
CrewAI 的一些关键概念包括
- 代理 - 一个具有特定角色和目标、由 LLM 控制的单元。它可以选择使用一些外部工具与外部世界通信,但通常由我们提供给 LLM 的 prompt 指导。
- 流程 - 目前可以是顺序式或层级式。它定义了任务如何由代理执行。在顺序式流程中,代理一个接一个地执行;而在层级式流程中,代理由负责决定在给定情况下使用哪个代理的管理器代理选择。
- 角色和目标 - 每个代理在团队中都有特定的角色和应努力实现的目标。这些在定义代理时设置,并用于决定在给定情况下使用哪个代理。
- 记忆 - 一个广泛的记忆系统,由短期记忆、长期记忆、实体记忆和结合了前三者的上下文记忆组成。还有用于偏好和个性化的用户记忆。Qdrant 在这里发挥作用,因为它可以作为长期记忆层使用。
CrewAI 提供了集成到框架中的丰富的工具集。对于那些希望将 RAG 与例如代码执行或图像生成相结合的人来说,这可能是一个巨大的优势。其生态系统非常丰富,但是引入自己的工具也并非难事,因为 CrewAI 设计为可扩展的。
在 CrewAI 中实现的简单 Agentic RAG 应用程序可能如下所示
from crewai import Crew, Agent, Task
from crewai.memory.entity.entity_memory import EntityMemory
from crewai.memory.short_term.short_term_memory import ShortTermMemory
from crewai.memory.storage.rag_storage import RAGStorage
class QdrantStorage(RAGStorage):
...
response_generator_agent = Agent(
role="Generate response based on the conversation",
goal="Provide the best response, or admit when the response is not available.",
backstory=(
"I am a response generator agent. I generate "
"responses based on the conversation."
),
verbose=True,
)
query_reformulation_agent = Agent(
role="Reformulate the query",
goal="Rewrite the query to get better results. Fix typos, grammar, word choice, etc.",
backstory=(
"I am a query reformulation agent. I reformulate the "
"query to get better results."
),
verbose=True,
)
task = Task(
description="Let me know why Qdrant is the best vector database out there.",
expected_output="3 bullet points",
agent=response_generator_agent,
)
crew = Crew(
agents=[response_generator_agent, query_reformulation_agent],
tasks=[task],
memory=True,
entity_memory=EntityMemory(storage=QdrantStorage("entity")),
short_term_memory=ShortTermMemory(storage=QdrantStorage("short-term")),
)
crew.kickoff()
免责声明:QdrantStorage 不是 CrewAI 框架的一部分,它取自 Qdrant 文档中关于如何将 Qdrant 与 CrewAI 集成的内容。
尽管这不是一个技术优势,但 CrewAI 拥有出色的文档。该框架支持 Python,并且入门非常简单。CrewAI 还提供商业产品 CrewAI Enterprise,提供了一个大规模构建和部署代理的平台。
AutoGen
AutoGen 将多代理架构强调为一个基本设计原则。该框架要求任何系统中至少有两个代理才能真正称为 Agentic 应用程序——通常是助理代理和用户代理通过交换消息来达到共同目标。AutoGen 也支持两个以上代理的顺序聊天,以及用于内部对话的群聊和嵌套聊天。然而,AutoGen 不假设代理之间传递结构化状态,并且聊天对话是它们之间唯一的通信方式。
该框架中有许多有趣的概念,其中一些甚至相当独特
- 工具/函数 - 代理可用于与外部世界通信的外部组件。它们被定义为 Python 可调用对象,可用于我们希望允许代理进行的任何外部交互。类型注解用于定义工具的输入和输出,并且支持 Pydantic 模型以实现更复杂的类型模式。AutoGen 目前仅支持与 OpenAI 兼容的工具调用 API。
- 代码执行器 - 内置的代码执行器包括本地命令、Docker 命令和 Jupyter。代理可以编写和启动代码,因此理论上代理可以做 Python 中能做的任何事情。没有其他框架将代码生成和执行做得如此突出。代码执行是 AutoGen 中的一等公民,这是一个有趣的概念。
每个 AutoGen 代理至少使用以下组件之一:人类参与、代码执行器、工具执行器或 LLM。一个基于两个代理对话的简单 Agentic RAG,它们可以从向量数据库检索文档或改进查询,可能如下所示
from os import environ
from autogen import ConversableAgent
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgent
from qdrant_client import QdrantClient
client = QdrantClient(...)
response_generator_agent = ConversableAgent(
name="response_generator_agent",
system_message=(
"You answer user questions based solely on the provided context. You ask to retrieve relevant documents for "
"your query, or reformulate the query, if it is incorrect in some way."
),
description="A response generator agent that can answer your queries.",
llm_config={"config_list": [{"model": "gpt-4", "api_key": environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER",
)
user_proxy = RetrieveUserProxyAgent(
name="retrieval_user",
llm_config={"config_list": [{"model": "gpt-4", "api_key": environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER",
retrieve_config={
"task": "qa",
"chunk_token_size": 2000,
"vector_db": "qdrant",
"db_config": {"client": client},
"get_or_create": True,
"overwrite": True,
},
)
result = user_proxy.initiate_chat(
response_generator_agent,
message=user_proxy.message_generator,
problem="Why Qdrant is the best vector database out there?",
max_turns=10,
)
对于刚接触代理开发的开发者,AutoGen 提供了 AutoGen Studio,这是一个用于快速构建代理原型的低代码界面。虽然不适用于生产环境,但它显著降低了实验代理架构的入门门槛。
值得注意的是,AutoGen 目前正在进行重大更新,开发中的 0.4.x 版本引入了与稳定版本 0.2.x 相比的实质性 API 变更。虽然该框架目前内置的持久性和状态管理能力有限,但这些功能可能会在未来的版本中演进。
OpenAI Swarm
与本文中描述的其他框架不同,OpenAI Swarm 是一个教育项目,尚未准备好投入生产使用。不过,值得一提的是,它非常轻量级且易于上手。OpenAI Swarm 是一个用于编排多代理工作流程的实验性框架,它侧重于通过直接交接而不是复杂的编排模式来实现代理协调。
在这种设置下,代理只是在聊天中交换消息,可以选择调用一些 Python 函数与外部服务通信,或者如果另一个代理似乎更适合回答问题,则将对话移交给它。每个代理都有特定的角色,由我们需要定义的指令来决定。我们必须决定特定代理将使用哪个 LLM,以及它可以调用的一组函数。例如,一个检索代理可以使用向量数据库检索文档,并将结果返回给下一个代理。这意味着,应该有一个代表它执行语义搜索的函数,但模型将决定查询应该是什么样子。
在 OpenAI Swarm 中实现的类似 Agentic RAG 应用程序可能如下所示
from swarm import Swarm, Agent
client = Swarm()
def retrieve_documents(query: str) -> list[str]:
"""
Retrieve documents based on the query.
"""
...
def transfer_to_query_improve_agent():
return query_improve_agent
query_improve_agent = Agent(
name="Query Improve Agent",
instructions=(
"You are a search expert that takes user queries and improves them to get better results. You fix typos and "
"extend queries with synonyms, if needed. You never ask the user for more information."
),
)
response_generation_agent = Agent(
name="Response Generation Agent",
instructions=(
"You take the whole conversation and generate a final response based on the chat history. "
"If you don't have enough information, you can retrieve the documents from the knowledge base or "
"reformulate the query by transferring to other agent. You never ask the user for more information. "
"You have to always be the last participant of each conversation."
),
functions=[retrieve_documents, transfer_to_query_improve_agent],
)
response = client.run(
agent=response_generation_agent,
messages=[
{
"role": "user",
"content": "Why Qdrant is the best vector database out there?"
}
],
)
即使我们没有明确定义处理流程图,代理仍然可以决定将处理移交给不同的代理。没有状态的概念,所以一切都依赖于不同组件之间交换的消息。
OpenAI Swarm 不侧重于与外部工具的集成,因此,如果您想将语义搜索与 Qdrant 集成,您将需要完全自己实现。显然,该库与 OpenAI 模型紧密耦合,虽然可以使用其他模型,但这需要一些额外的工作,例如设置一个代理来调整接口以适应 OpenAI API。
胜者?
为您的 Agentic RAG 系统选择最佳框架取决于您现有的技术栈、团队专业知识以及项目的具体要求。所有描述的工具都是强有力的竞争者,并且它们正快速发展。值得关注所有这些工具,因为它们可能会随着时间而演进和改进。最终,您应该能够使用其中任何一个构建相同的流程,但其中一些可能更适合您的代理想要交互的特定工具生态系统。
然而,在为您的 Agentic RAG 系统选择框架时,有一些重要的因素需要考虑
- 人类参与(Human-in-the-loop) - 即使我们的目标是构建自主代理,通常包含人类的反馈也很重要,这样我们的代理就不会执行恶意操作。
- 可观察性 - 调试系统有多容易,以及理解内部发生的事情有多容易。这一点尤其重要,因为我们正在处理大量的 LLM prompt。
尽管如此,选择合适的工具包取决于您的项目状态以及您的具体需求。如果您想将代理与许多外部工具集成,CrewAI 可能是最佳选择,因为它提供的现成集成最多。然而,LangGraph 与 LangChain 很好地集成,所以如果您熟悉该生态系统,它可能更适合您。
所有框架在构建代理方面都有不同的方法,因此值得尝试所有这些框架,看看哪个最适合您的需求。LangGraph 和 CrewAI 更成熟,功能更多,而 AutoGen 和 OpenAI Swarm 更轻量级且更具实验性。然而,现有框架都无法解决所有提到的信息检索问题,因此您仍然需要构建自己的工具来填补空白。
使用 Qdrant 构建 Agentic RAG
无论您选择哪个框架,Qdrant 都是构建 Agentic RAG 系统的绝佳工具。请查看我们的集成,为您的用例和偏好选择最合适的一个。开始使用 Qdrant 最简单的方法是使用我们的托管服务 Qdrant Cloud。提供免费的 1GB 集群,您可以几分钟内开始构建您的 Agentic RAG 系统。
延伸阅读
了解 Qdrant 如何与以下项目集成