
使用二值量化优化高维向量
Qdrant 旨在应对典型的扩展挑战:高吞吐量、低延迟和高效索引。 二值量化 (BQ) 是我们为客户提供高效扩展所需优势的最新尝试。此功能对于具有大向量长度和大量点的集合尤其出色。
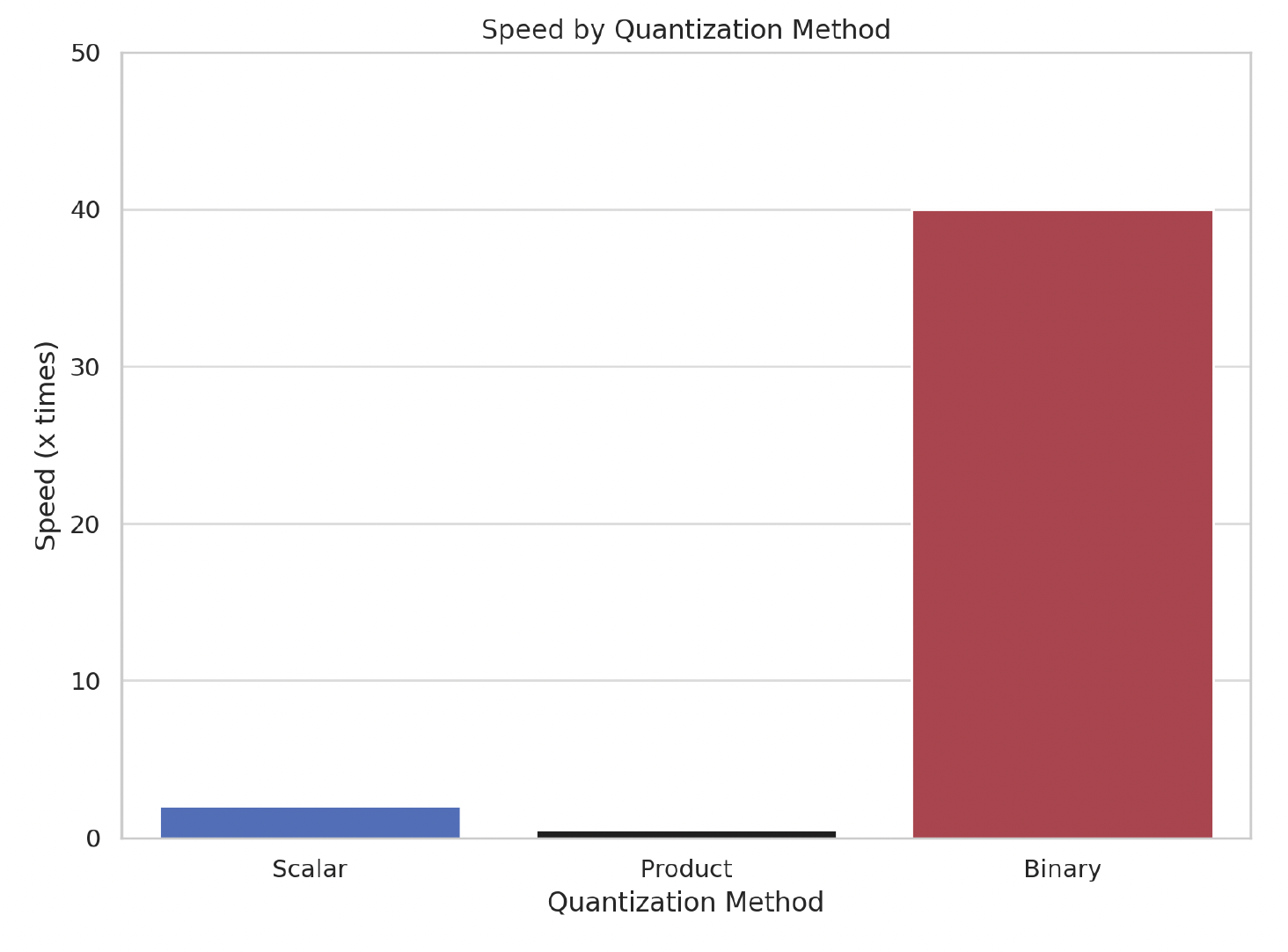
我们的结果是显著的:使用 BQ 将减少您的内存消耗,并将检索速度提高多达 40 倍。
与其他量化方法一样,这些优势是以召回率下降为代价的。但是,我们的实现允许您在搜索时而不是索引创建时平衡速度和召回准确性之间的权衡。
本文的其余部分将涵盖
- 二值量化的重要性
- 使用我们的 Python 客户端进行基本实现
- 基准分析和使用建议
什么是二值量化?
二值量化 (BQ) 将任何浮点数的向量嵌入转换为二进制或布尔值的向量。此功能是我们过去在标量量化方面工作的扩展,我们在此工作中将 float32 转换为 uint8,然后利用特定的 SIMD CPU 指令执行快速向量比较。
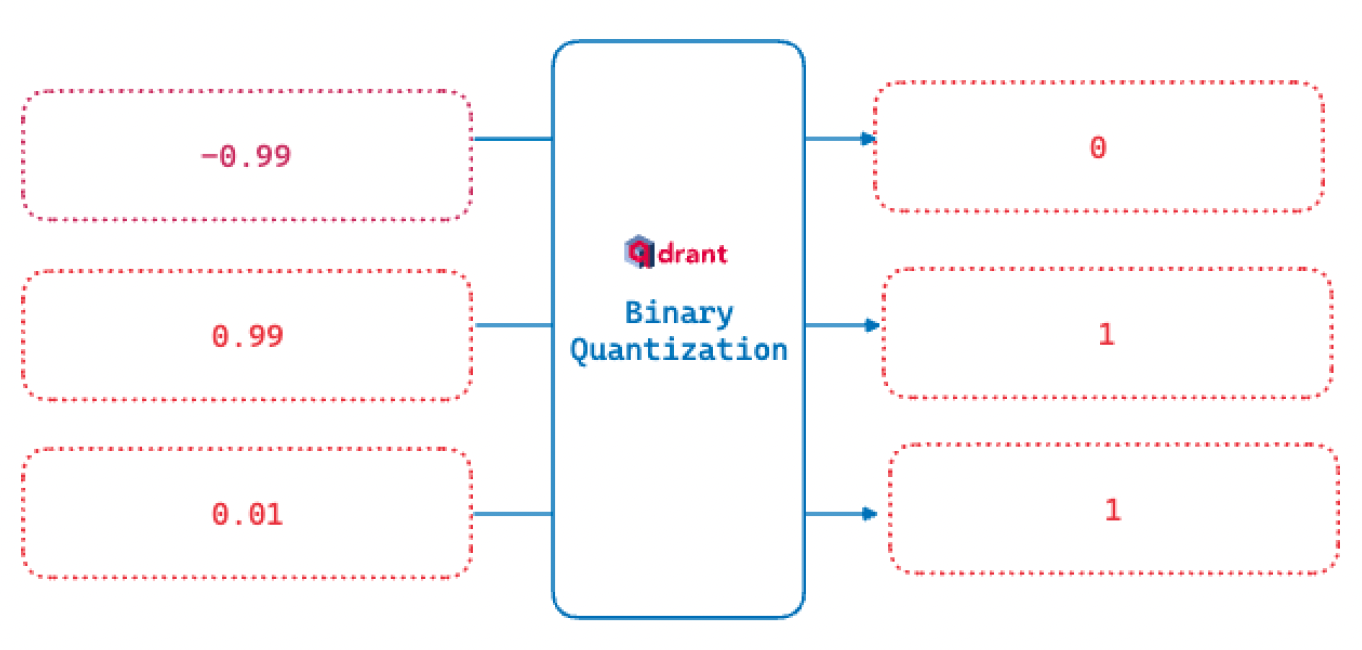
此二值化函数是我们如何将范围转换为二进制值。所有大于零的数字都标记为 1。如果为零或更小,则变为 0。
将向量嵌入减少到二进制值的好处是布尔运算速度非常快,并且需要的 CPU 指令明显更少。通过将我们的 32 位嵌入减少到 1 位嵌入,我们可以看到检索速度提升高达 40 倍!
向量搜索在如此高的压缩率下仍然有效的原因之一是这些大向量对于检索而言是过参数化的。这是因为它们是为排名、聚类和类似用例而设计的,这些用例通常需要在向量中编码更多信息。
例如,1536 维的 OpenAI 嵌入在检索和排名方面不如 384 维的开源对应物。具体来说,它在相同的嵌入检索基准上得分为 49.25,而开源的 bge-small 得分为 51.82。这 2.57 分的差异很快就会累积起来。
我们的量化实现在排名时的完整大向量和搜索检索时的二值向量之间取得了很好的平衡。它还允许您根据您的用例调整这种平衡。
更快的搜索和检索
与乘积量化不同,二值量化不依赖于减少每个探头的搜索空间。相反,我们构建了一个二值索引,帮助我们大大提高搜索速度。
HNSW 是近似最近邻搜索。这意味着我们的准确性会随着我们检查索引以查找更多相似候选而提高,直到收益递减点。在二值量化的上下文中,这被称为过采样率。
例如,如果 oversampling=2.0 且 limit=100,则首先使用量化索引选择 200 个向量。对于这 200 个向量,将使用完整的 32 位向量及其 HNSW 索引来获得更准确的 100 个项目结果集。与执行完整的 HNSW 搜索不同,我们对初步搜索进行过采样,然后仅对这组小得多的向量进行完整搜索。
提高存储效率
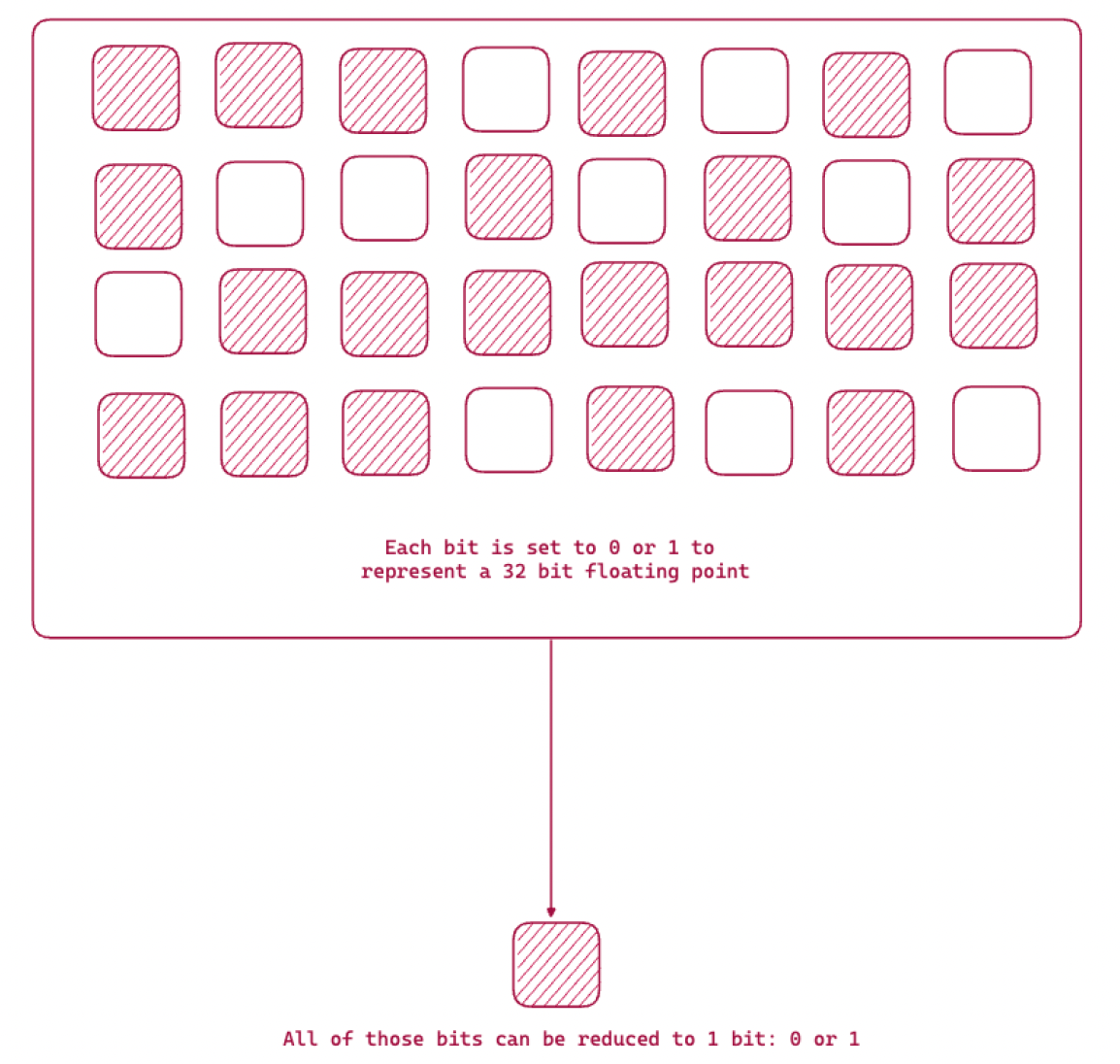
下图显示了二值化函数,通过该函数,我们将 32 位存储减少到 1 位信息。
文本嵌入可以超过 1024 个浮点 32 位数字元素。例如,请记住 OpenAI 嵌入是 1536 元素向量。这意味着每个向量仅存储向量就需要 6KB。
除了存储向量,我们还需要维护一个索引以加快搜索和检索速度。Qdrant 估计总内存消耗的公式是
memory_size = 1.5 * 向量数 * 向量维度 * 4 字节
对于 100K OpenAI Embedding (ada-002) 向量,我们需要 900 兆字节的 RAM 和磁盘空间。随着您创建多个集合或向数据库添加更多项目,此消耗会迅速增加。
使用二值量化,相同的 100K OpenAI 向量仅需要 128 MB 的 RAM。 我们使用与我们的标量量化内存估算中介绍的方法类似的方法对这一结果进行了基准测试。
RAM 使用量的减少是通过二进制转换中发生的压缩实现的。HNSW 和量化向量将驻留在 RAM 中以实现快速访问,而原始向量可以仅卸载到磁盘。对于搜索,量化 HNSW 将提供过采样候选,然后使用其磁盘存储的原始向量重新评估它们,以完善最终结果。所有这些都在后台进行,无需您进行任何额外干预。
什么时候不应该使用 BQ?
由于此方法利用了嵌入的过参数化,因此对于小型嵌入(即小于 1024 维)可能会得到较差的结果。由于元素数量较少,二进制向量中没有足够的保留信息来获得良好的结果。
您仍然会获得更快的布尔运算和更少的 RAM 使用量,但准确性下降可能太高。
示例实现
现在我们已经向您介绍了二值量化,让我们尝试一个基本实现。在此示例中,我们将使用带有 Qdrant 的 OpenAI 和 Cohere。
创建启用了二值量化的集合
在创建集合时,您应该在索引时执行以下操作
- 我们将所有“完整”向量存储在磁盘上。
- 然后我们将二进制嵌入设置为在 RAM 中。
默认情况下,完整向量和 BQ 都存储在 RAM 中。我们将完整向量移动到磁盘,因为这可以节省内存并允许我们在 RAM 中存储更多向量。通过这样做,我们通过设置 always_ram=True 明确地将二进制向量移动到内存中。
from qdrant_client import QdrantClient
#collect to our Qdrant Server
client = QdrantClient(
url="https://:6333",
prefer_grpc=True,
)
#Create the collection to hold our embeddings
# on_disk=True and the quantization_config are the areas to focus on
collection_name = "binary-quantization"
if not client.collection_exists(collection_name):
client.create_collection(
collection_name=f"{collection_name}",
vectors_config=models.VectorParams(
size=1536,
distance=models.Distance.DOT,
on_disk=True,
),
optimizers_config=models.OptimizersConfigDiff(
default_segment_number=5,
),
hnsw_config=models.HnswConfigDiff(
m=0,
),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(always_ram=True),
),
)
HnswConfig 中发生了什么?
我们将 m 设置为 0,即禁用 HNSW 图构造。这允许更快地上传向量和负载。一旦所有数据加载完毕,我们将在下面将其重新打开。
接下来,我们将我们的向量上传到此,然后启用图构造
batch_size = 10000
client.upload_collection(
collection_name=collection_name,
ids=range(len(dataset)),
vectors=dataset["openai"],
payload=[
{"text": x} for x in dataset["text"]
],
parallel=10, # based on the machine
)
再次启用 HNSW 图构造
client.update_collection(
collection_name=f"{collection_name}",
hnsw_config=models.HnswConfigDiff(
m=16,
,
)
配置搜索参数
在设置搜索参数时,我们指定要使用 oversampling 和 rescore。这是一个示例片段
client.search(
collection_name="{collection_name}",
query_vector=[0.2, 0.1, 0.9, 0.7, ...],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
ignore=False,
rescore=True,
oversampling=2.0,
)
)
)
Qdrant 拉取过采样向量集后,完整向量(例如 OpenAI 的 1536 维)将从磁盘中拉取。Qdrant 计算与查询向量的最近邻居,并返回准确、重新评分的顺序。此方法产生更准确的结果。我们通过设置 rescore=True 启用了此功能。
这两个参数是您平衡速度与准确性的方式。过采样的大小越大,您需要从磁盘读取的项目就越多,并且您必须使用相对较慢的完整向量索引搜索的元素就越多。另一方面,这样做会产生更准确的结果。
如果您的准确性要求较低,您甚至可以尝试在不重新评分的情况下进行小规模过采样。或者,对于您的数据集结合您的准确性与速度要求,您可以只搜索二进制索引而不重新评分,即在搜索查询中省略这两个参数。
基准测试结果
我们使用 DBPedia OpenAI 1M 向量数据集检索了限制与过采样之间关系的一些早期结果。我们在一台 Qdrant 实例上运行了所有这些实验,该实例索引了 100K 向量并使用了 100 个随机查询。
我们改变了影响查询时间和准确性的 3 个参数:限制、重新评分和过采样。我们将这些作为此新功能的初步探索。我们强烈建议您使用自己的数据集重现这些实验。
附注:由于这是向量数据库中的一项新创新,我们渴望听到反馈和结果。加入我们的 Discord 服务器进行进一步讨论!
过采样:在下图中,我们说明了召回率与候选数量之间的关系
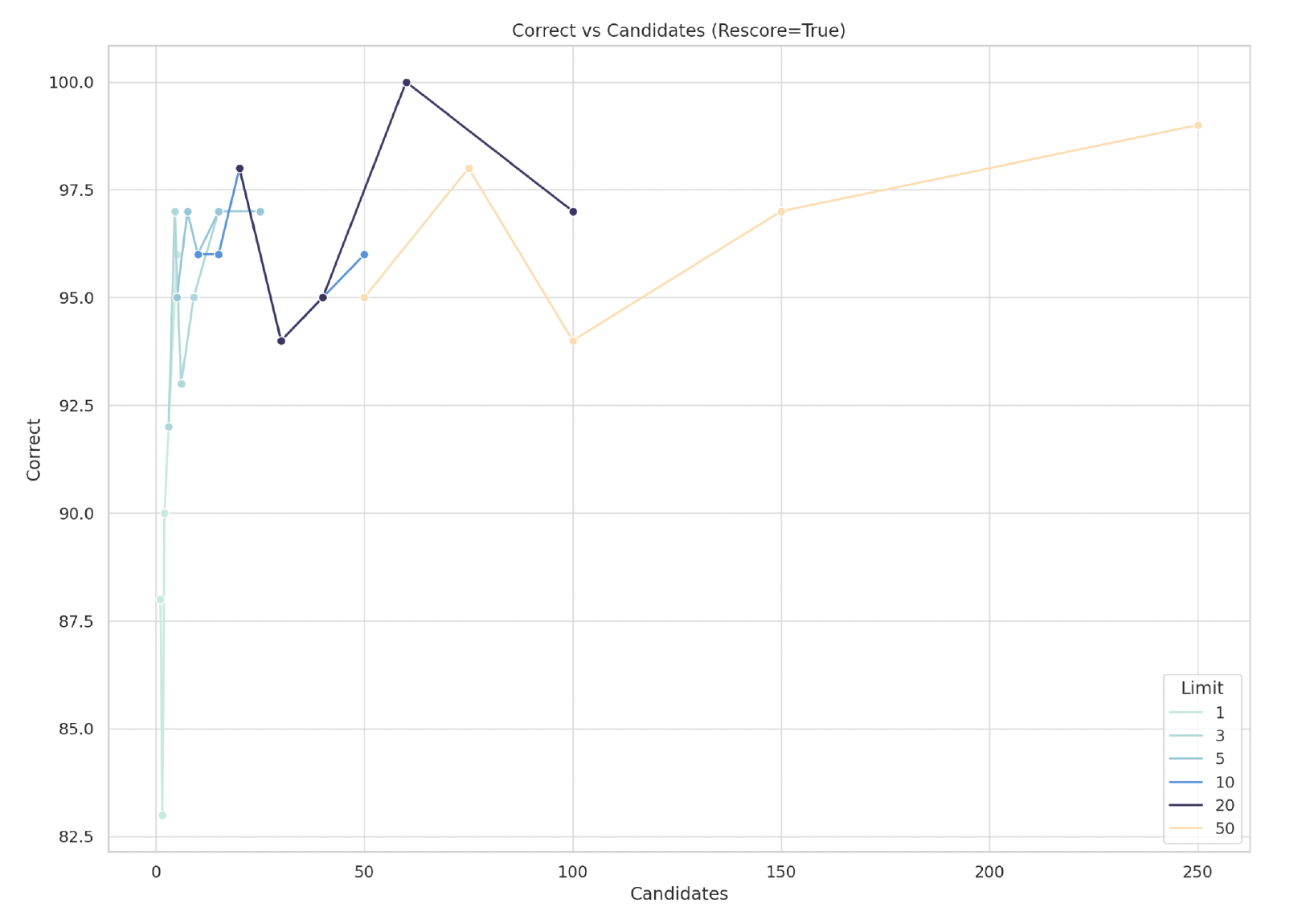
我们看到“正确”结果(即召回率)随着潜在“候选”数量的增加(限制 x 过采样)而增加。为了突出改变 limit 的影响,不同的限制值被分解为不同的曲线。例如,我们看到限制为 50 时的最低召回率约为 94 个正确结果,具有 100 个候选。这也意味着我们使用了 2.0 的过采样
随着过采样的增加,我们看到结果普遍改善——但这并非在所有情况下都成立。
重新评分:正如预期的那样,重新评分会增加返回查询所需的时间。我们还重复了过采样实验,但这次我们研究了重新评分如何影响结果准确性。
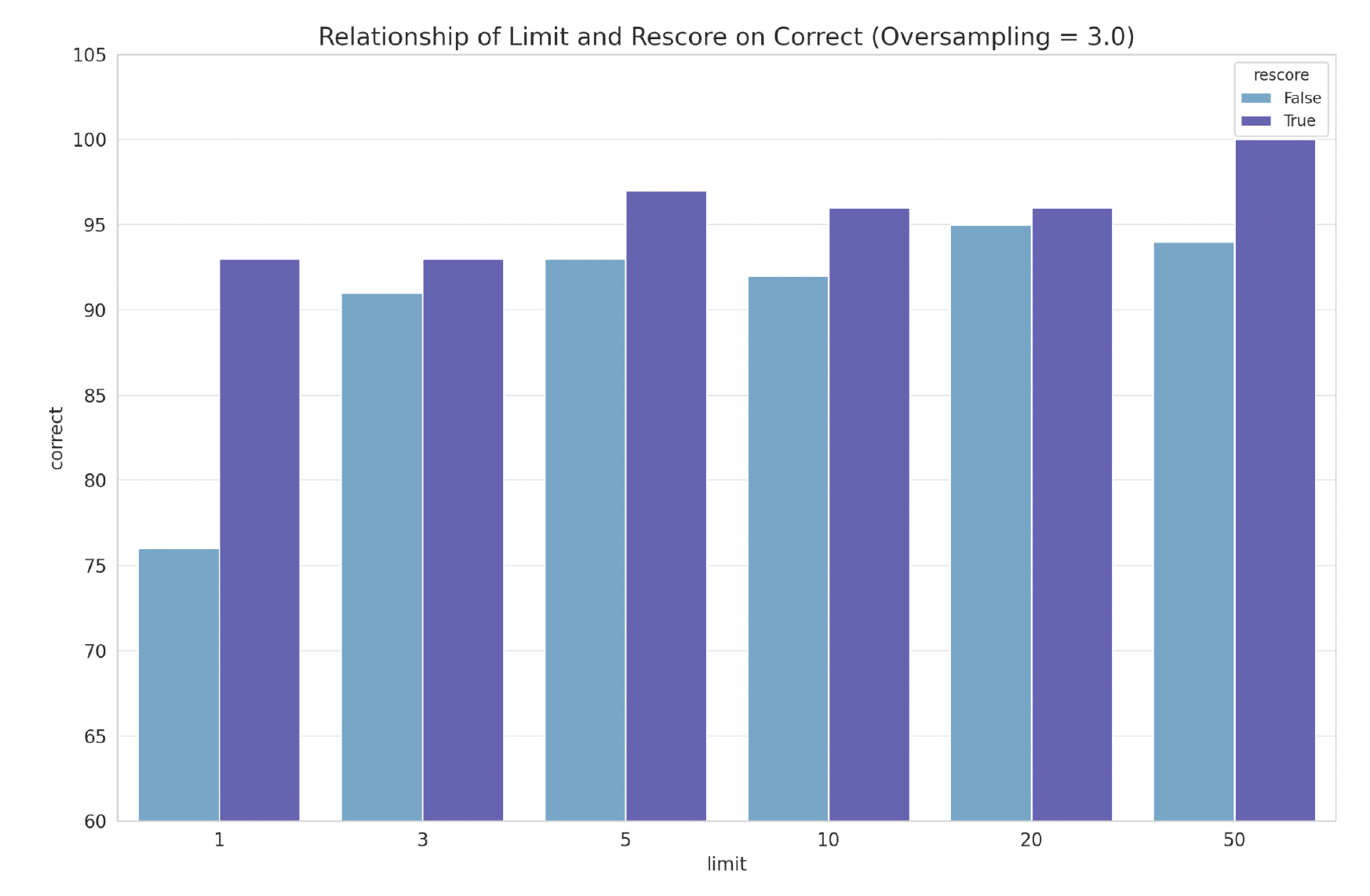
限制:我们实验了从 Top 1 到 Top 50 的限制,并且能够在限制为 50 时,在具有 100K 向量的索引中,通过 rescore=True 达到 100% 的召回率。
推荐
量化使您能够根据其他参数进行权衡:维度计数/嵌入大小、吞吐量和延迟要求、召回要求
如果您正在使用 OpenAI 或 Cohere 嵌入,我们建议以下过采样设置
| 方法 | 维度 | 测试数据集 | 召回率 | 过采样 |
|---|---|---|---|---|
| OpenAI text-embedding-3-large | 3072 | DBpedia 1M | 0.9966 | 3x |
| OpenAI text-embedding-3-small | 1536 | DBpedia 100K | 0.9847 | 3x |
| OpenAI text-embedding-3-large | 1536 | DBpedia 1M | 0.9826 | 3x |
| OpenAI text-embedding-ada-002 | 1536 | DbPedia 1M | 0.98 | 4x |
| Gemini | 768 | 无公开数据 | 0.9563 | 3x |
| Mistral Embed | 768 | 无公开数据 | 0.9445 | 3x |
如果您确定二值量化适用于您的数据集和查询,那么我们建议以下设置
- 二值量化,always_ram=True
- 向量存储在磁盘上
- 过采样=2.0(或更多)
- 重新评分=True
接下来是什么?
如果您需要在高召回率预期下处理大量数据,二值量化是卓越的。您可以通过在本地启动Qdrant 容器镜像,或者通过我们的云托管服务中的免费帐户让我们为您创建一个,来尝试此功能。
本文提供了您可以使用的数据集和配置示例。我们的文档涵盖了向您的 Qdrant 实例添加大型数据集以及更多量化方法。
如果您有任何反馈,请在 Twitter 或 LinkedIn 上给我们留言,告诉我们您的结果。加入我们活跃的 Discord 服务器,如果您想与志同道合的人讨论 BQ!