
OpenAI Ada-003嵌入是自然语言处理(NLP)的强大工具。然而,嵌入的大小是一个挑战,尤其是在实时搜索和检索方面。在本文中,我们将探讨如何使用Qdrant的二值量化来提高OpenAI嵌入的性能和效率。
在这篇文章中,我们将讨论
- OpenAI嵌入的重要性及实际挑战。
- Qdrant的二值量化,以及它如何提升OpenAI嵌入的性能。
- 一项突出搜索效率和准确性改进的实验结果。
- 这些发现对实际应用的影响。
- 利用二值量化增强OpenAI嵌入的最佳实践。
如果您是二值量化的新手,请考虑阅读我们的文章,它将引导您了解这个概念以及如何与Qdrant一起使用它。
您还可以尝试OpenAI二值量化中描述的这些技术,其中包括Jupyter Notebook。
新的OpenAI嵌入:性能与变化
随着嵌入模型技术的进步,需求也随之增长。用户正在寻求更强大、更高效的文本嵌入模型。OpenAI的Ada-003嵌入在广泛的NLP任务中提供了最先进的性能,包括MTEB和MIRACL中提到的那些。
这些模型支持100多种语言的多语言。从text-embedding-ada-002到text-embedding-3-large的过渡导致性能分数显著提升(MIRACL上从31.4%到54.9%)。
俄罗斯套娃表示学习
新的OpenAI模型采用了一种新颖的方法,称为“俄罗斯套娃表示学习”进行训练。开发者可以设置不同大小(维度数量)的嵌入。在这篇文章中,我们使用小型和大型变体。开发者可以选择平衡准确性和大小的嵌入。
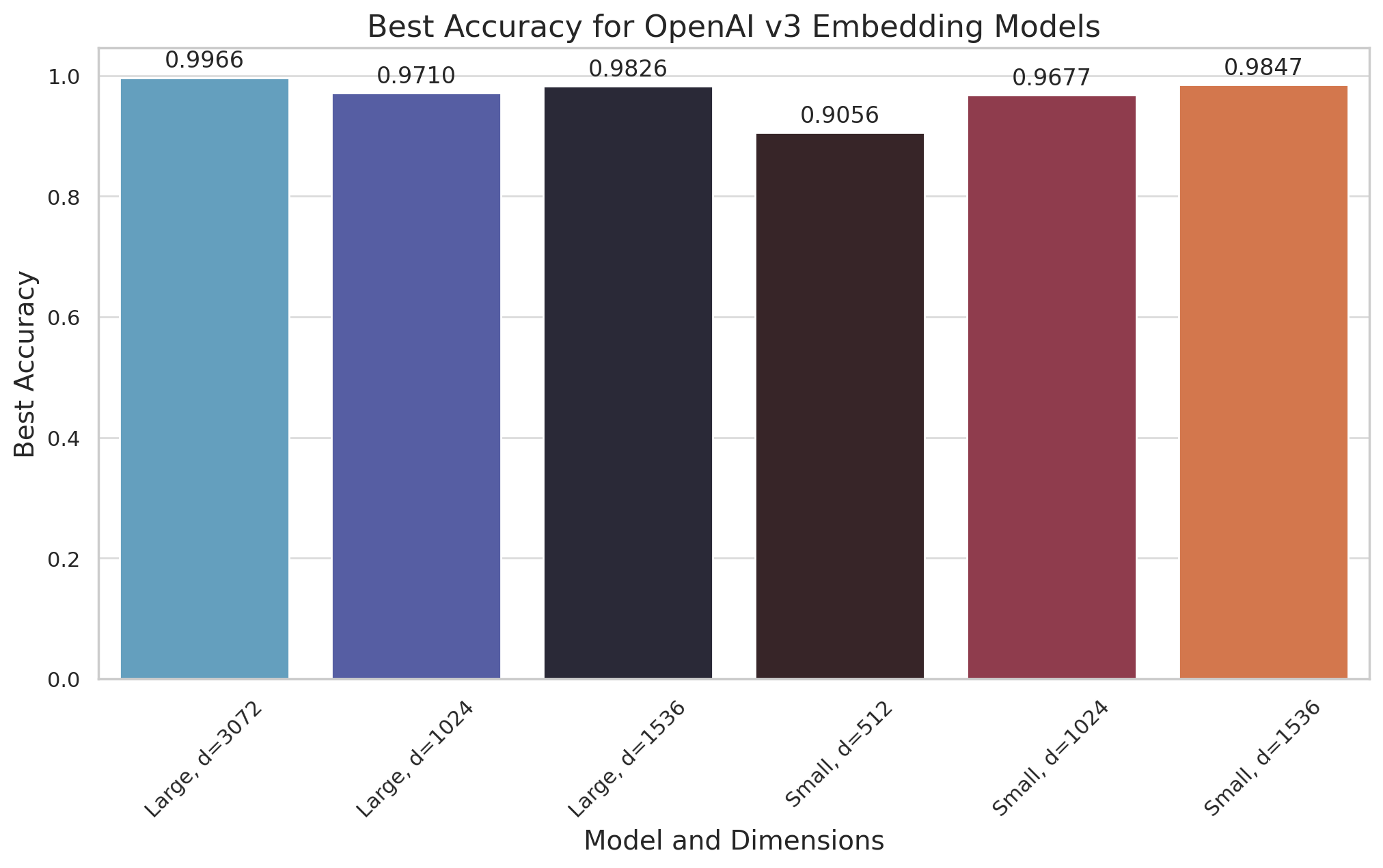
在这里,我们展示了二值量化在不同维度下(对于两种模型)的准确性都相当不错。
通过二值量化提高性能和效率
通过减少存储需求,您可以以更低的成本扩展应用程序。这解决了原始嵌入大小带来的关键挑战。二值量化还加快了搜索过程。它将向量之间复杂的距离计算简化为更易于管理的位操作,这支持在庞大数据集上进行潜在的实时搜索。
附图展示了二值量化在不同模型尺寸下可实现的有前景的准确性水平,展示了其在不严重影响性能的情况下实现实用性的能力。存储减少和搜索能力加速的双重优势,凸显了二值量化在各种实际应用中更有效地部署OpenAI嵌入的变革潜力。
二值量化带来的效率提升如下:
- 减少存储空间:它有助于处理大规模数据集。它还节省内存,并以相同的成本扩展30倍。
- 提高数据检索速度:较小的数据量通常会导致更快的搜索。
- 加速搜索过程:它基于将向量之间简化的距离计算转换为位操作。这使得即使在大型数据库中也能进行实时查询。
实验设置:聚焦OpenAI嵌入
为了识别二值量化对搜索效率和准确性的影响,我们基于OpenAI文本嵌入模型设计了实验。这些模型捕捉细微的语言特征和语义关系,是我们的分析基础。然后,我们深入探讨了Qdrant的二值量化功能可能带来的增强。
这种方法不仅利用了高质量的OpenAI嵌入,还为评估正在审查的搜索机制提供了广泛的基础。
数据集
该研究使用了OpenAI 1M数据集中10万个随机样本,重点关注100个随机选择的记录。这些记录在实验中作为查询,旨在评估二值量化如何影响数据集中搜索效率和精度。然后我们使用查询的嵌入来搜索数据集中最近的邻居。
参数:过采样、重新评分和搜索限制
对于每条记录,我们对过采样、重新评分和搜索限制的数量进行参数扫描。然后我们可以了解这些参数对搜索准确性和效率的影响。我们的实验旨在根据以下参数评估二值量化在各种条件下的影响:
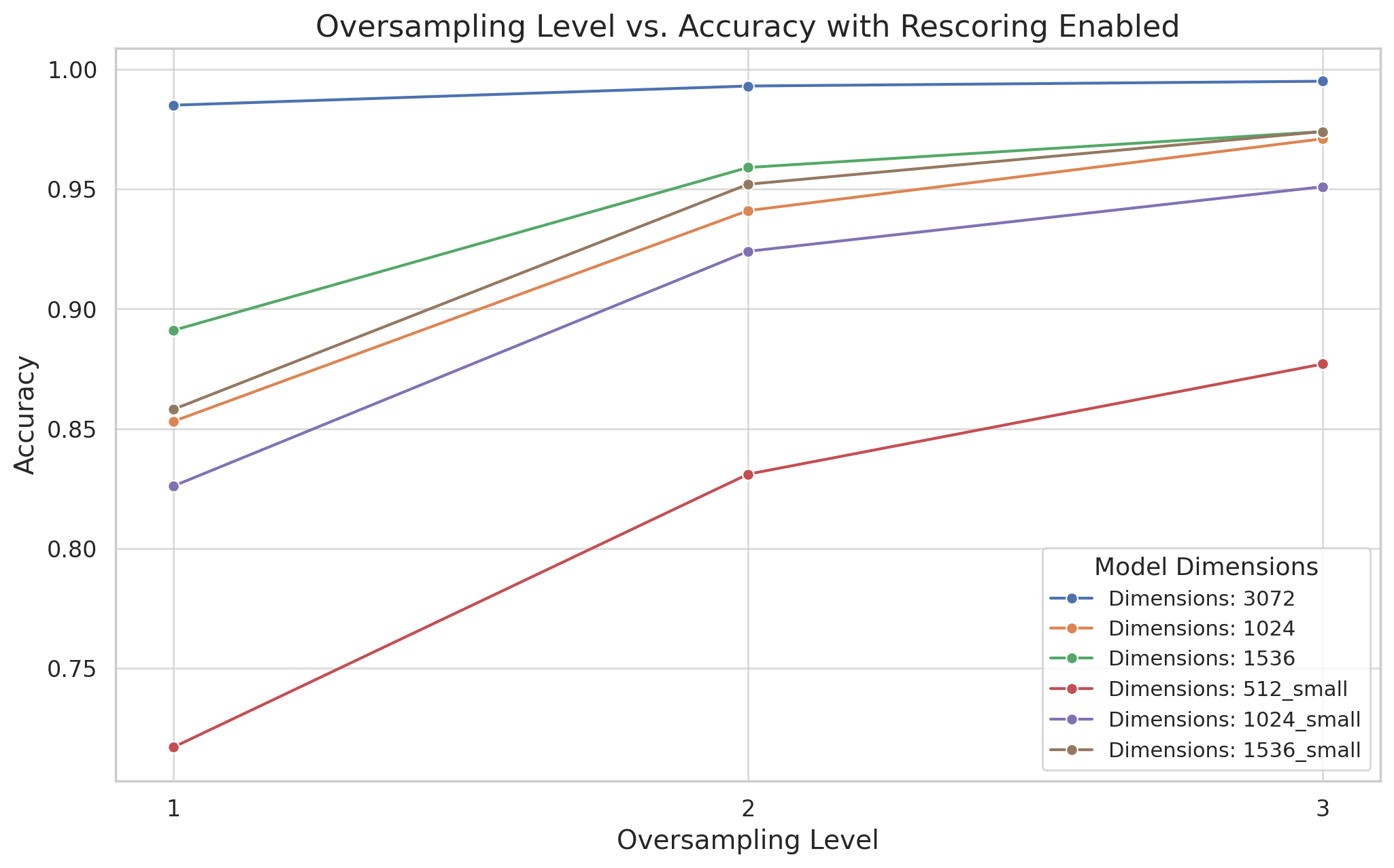
过采样:通过过采样,我们可以限制量化固有的信息损失。这也有助于保留您的OpenAI嵌入的语义丰富性。我们尝试了不同的过采样因子,并确定了其对搜索准确性和效率的影响。剧透:较高的过采样因子往往会提高搜索的准确性。然而,它们通常需要更多的计算资源。
重新评分:重新评分可以优化初始二分搜索的初步结果。此过程利用原始的高维向量来细化搜索结果,从而**始终**提高准确性。我们通过开启和关闭重新评分来衡量其与二值量化结合时的有效性。我们还测量了其对搜索性能的影响。
搜索限制:我们指定搜索过程的结果数量。我们尝试了各种搜索限制来衡量它们对准确性和效率的影响。我们探讨了搜索深度和性能之间的权衡。结果为具有不同精度和速度要求的应用程序提供了见解。
通过这种详细的设置,我们的实验旨在揭示二值量化与OpenAI模型产生的高质量嵌入之间微妙的相互作用。通过精心调整和观察不同条件下的结果,我们旨在发现可操作的见解,使S用户能够充分利用Qdrant与OpenAI嵌入相结合的潜力,无论其特定的应用需求如何。
结果:二值量化对OpenAI嵌入的影响
为了分析重新评分(True或False)的影响,我们比较了不同模型配置和搜索限制下的结果。重新评分根据初始查询的结果设置更精确的搜索。
重新评分

以下是一些关键观察结果,分析了重新评分(True或False)的影响:
显著提高准确性:
- 在所有模型和维度配置中,启用重新评分(
True)始终比禁用重新评分(False)获得更高的准确性分数。 - 在各种搜索限制(10、20、50、100)下,准确性都有所提高。
- 在所有模型和维度配置中,启用重新评分(
模型和维度特定观察:
- 对于具有3072维度的
text-embedding-3-large模型,重新评分将准确性从平均约76-77%(不重新评分)提升至97-99%(重新评分),具体取决于搜索限制和过采样率。 - 当启用重新评分时,增加过采样对准确性的改善更为明显,这表明在优化搜索结果时更好地利用了额外的二进制代码。
- 使用512维度的
text-embedding-3-small模型,准确性从不重新评分的约53-55%增加到重新评分的71-91%,这凸显了重新评分的显著影响,尤其是在较低维度下。
- 对于具有3072维度的
相比之下,对于低维度模型(例如512维度的text-embedding-3-small),即使启用了重新评分,增加过采样水平带来的增量准确性收益也不那么显著。这表明在低维度空间中,过采样率越高,准确性提高的收益递减。
- 搜索限制的影响:
- 重新评分带来的性能提升似乎在不同的搜索限制下相对稳定,这表明无论考虑的顶部结果数量如何,重新评分都始终能提高准确性。
总而言之,在所有测试配置中,启用重新评分都显著提高了搜索准确性。对于精度至关重要的应用程序来说,这是一个关键功能。重新评分提供的持续性能提升突显了其在优化搜索结果方面的价值,特别是在处理OpenAI嵌入等复杂、高维数据时。这种增强对于要求高准确性的应用程序至关重要,例如语义搜索、内容发现和推荐系统,在这些应用程序中,搜索结果的质量直接影响用户体验和满意度。
数据集组合
对于探索文本嵌入模型与Qdrant集成的用户而言,考虑各种模型配置以获得最佳性能至关重要。上述定义的数据集组合展示了针对Qdrant进行测试的不同配置。这些组合主要基于两个属性而异:
模型名称:表示特定的文本嵌入模型变体,例如“text-embedding-3-large”或“text-embedding-3-small”。这种区别与模型的容量相关,“large”模型提供更详细的嵌入,但以增加计算资源为代价。
维度:指模型生成的向量嵌入的大小。选项范围从512到3072维。更高的维度可能导致更精确的嵌入,但也可能增加Qdrant中的搜索时间和内存使用。
优化这些参数是搜索准确性与资源效率之间的平衡。通过测试这些组合,用户可以确定最符合其特定需求的配置,同时考虑计算资源和搜索结果质量之间的权衡。
dataset_combinations = [
{
"model_name": "text-embedding-3-large",
"dimensions": 3072,
},
{
"model_name": "text-embedding-3-large",
"dimensions": 1024,
},
{
"model_name": "text-embedding-3-large",
"dimensions": 1536,
},
{
"model_name": "text-embedding-3-small",
"dimensions": 512,
},
{
"model_name": "text-embedding-3-small",
"dimensions": 1024,
},
{
"model_name": "text-embedding-3-small",
"dimensions": 1536,
},
]
探索数据集组合及其对模型性能的影响
代码片段遍历预定义的数据集和模型组合。对于每个以模型名称及其维度为特征的组合,都会加载相应的实验结果。这些以JSON格式存储的结果包括不同配置下的性能指标:有无过采样,以及有无重新评分步骤。
提取这些指标后,代码计算不同设置下的平均准确率,排除了非常低限制(特别是限制为1和5)的极端情况。此计算按过采样、重新评分的存在和限制对结果进行分组,然后计算每个子组的平均准确率。
在收集和处理这些数据后,平均准确率被组织到一个透视表中。该表以限制(考虑的顶部结果数量)作为索引,列则根据过采样和重新评分的组合形成。
import pandas as pd
for combination in dataset_combinations:
model_name = combination["model_name"]
dimensions = combination["dimensions"]
print(f"Model: {model_name}, dimensions: {dimensions}")
results = pd.read_json(f"../results/results-{model_name}-{dimensions}.json", lines=True)
average_accuracy = results[results["limit"] != 1]
average_accuracy = average_accuracy[average_accuracy["limit"] != 5]
average_accuracy = average_accuracy.groupby(["oversampling", "rescore", "limit"])[
"accuracy"
].mean()
average_accuracy = average_accuracy.reset_index()
acc = average_accuracy.pivot(
index="limit", columns=["oversampling", "rescore"], values="accuracy"
)
print(acc)
以下是这些结果的选定切片,其中rescore=True
| 方法 | 维度 | 测试数据集 | 召回率 | 过采样 |
|---|---|---|---|---|
| OpenAI text-embedding-3-large(表中MTEB分数最高) | 3072 | DBpedia 1M | 0.9966 | 3x |
| OpenAI text-embedding-3-small | 1536 | DBpedia 100K | 0.9847 | 3x |
| OpenAI text-embedding-3-large | 1536 | DBpedia 1M | 0.9826 | 3x |
过采样的影响
您可以在机器学习中使用过采样来抵消数据集中的不平衡。当一个类别显著多于其他类别时,它效果很好。这种不平衡可能会扭曲模型的性能,使其偏向多数类别而牺牲其他类别。通过从少数类别创建额外的样本,过采样有助于平衡训练数据集中类别的表示,从而实现对真实场景更公平和准确的建模。
屏幕截图展示了过采样对模型性能指标的影响。虽然未显示实际指标,但我们期望看到精度、召回率或F1分数等指标的改进。这些改进说明了过采样在创建更平衡数据集方面的有效性。它使模型能够更好地学习所有类别的表示,而不仅仅是占主导地位的类别。
在没有明确的代码片段或输出的情况下,我们重点关注过采样在模型公平性和性能中的作用。通过图形表示,您可以设置前后比较。这些比较说明了对机器学习项目的贡献。
利用二值量化:最佳实践
我们建议使用以下最佳实践来利用二值量化增强OpenAI嵌入:
- 嵌入模型:使用MTEB中的text-embedding-3-large。它是测试中最准确的模型。
- 维度:使用模型可用的最高维度,以最大限度地提高准确性。结果对英语和其他语言都适用。
- 过采样:使用3的过采样因子,以在准确性和效率之间取得最佳平衡。此因子适用于各种应用程序。
- 重新评分:启用重新评分以提高搜索结果的准确性。
- 内存:将完整的向量和有效载荷存储在磁盘上。将从内存加载的内容限制为二值量化索引。这有助于减少内存占用并提高系统的整体效率。与Qdrant中二值评分的延迟节省相比,磁盘读取的增量延迟可以忽略不计,Qdrant在可能的情况下使用SIMD指令。
接下来是什么?
如果您需要在高召回率预期下处理大量数据,二值量化是例外。您可以通过在本地启动Qdrant容器镜像来尝试此功能,或者让我们通过我们的云托管服务中的免费帐户为您创建一个。
本文提供了您可以用来开始使用的数据集和配置示例。我们的文档涵盖了将大型数据集添加到Qdrant实例以及更多量化方法。
想讨论这些发现并了解更多关于二值量化的信息吗?加入我们的Discord社区。