
在过去的40年里,BM25 一直是搜索引擎的标准。它是一种简单而强大的算法,被许多搜索引擎使用,包括 Google、Bing 和 Yahoo。
尽管向量搜索的出现似乎会削弱其影响力,但这只是一部分。当前最先进的检索方法试图将 BM25 与嵌入结合起来,构建混合搜索系统。
然而,自 RAG 引入以来,文本检索的使用场景已发生了显著变化。BM25 构建所依赖的许多假设不再有效。
例如,传统 Web 搜索与现代 RAG 系统中文档和查询的典型长度差异很大。
在本文中,我们将回顾 BM25 之所以长时间保持相关性的原因,以及为何其替代方案难以取代它。最后,我们将讨论 BM42,作为词汇搜索演进的下一步。
为何 BM25 能长时间保持相关性?
要理解这一点,我们需要分析其组成部分。
著名的 BM25 公式定义为
$$ \text{score}(D,Q) = \sum_{i=1}^{N} \text{IDF}(q_i) \times \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot \left(1 - b + b \cdot \frac{|D|}{\text{avgdl}}\right)} $$
让我们简化一下,以便更好地理解。
$\text{score}(D, Q)$ - 意味着我们计算每对文档 $D$ 和查询 $Q$ 的得分。
$\sum_{i=1}^{N}$ - 意味着查询中的 $N$ 个词项的每一个都作为总和的一部分贡献最终得分。
$\text{IDF}(q_i)$ - 是逆文档频率。词项 $q_i$ 越罕见,它对得分的贡献越大。一个简化公式如下:
$$ \text{IDF}(q_i) = \frac{\text{Number of documents}}{\text{Number of documents with } q_i} $$
公平地说,IDF 是 BM25 公式中最重要的部分。IDF 相对于特定的文档集合选择查询中最重要的词项。所以直观地,我们可以将 IDF 理解为 词库中的词项重要性。
这解释了为何 BM25 在处理密集嵌入认为是域外(out-of-domain)的查询时表现如此出色。
公式的最后一个组成部分可以直观地理解为 文档中的词项重要性。这可能看起来有点复杂,所以让我们分解一下。
$$ \text{Term importance in document }(q_i) = \color{red}\frac{f(q_i, D)\color{gray} \cdot \color{blue}(k_1 + 1) \color{gray} }{\color{red}f(q_i, D)\color{gray} + \color{blue}k_1\color{gray} \cdot \left(1 - \color{blue}b\color{gray} + \color{blue}b\color{gray} \cdot \frac{|D|}{\text{avgdl}}\right)} $$
- $\color{red}f(q_i, D)\color{gray}$ - 是词项 $q_i$ 在文档 $D$ 中的频率。换句话说,词项 $q_i$ 在文档 $D$ 中出现的次数。
- $\color{blue}k_1\color{gray}$ 和 $\color{blue}b\color{gray}$ 是 BM25 公式的超参数。在大多数实现中,它们是常数,设定为 $k_1=1.5$ 和 $b=0.75$。这些常数定义了词频和文档长度在公式中的相对影响。
- $\frac{|D|}{\text{avgdl}}$ - 是文档 $D$ 相对于词库中平均文档长度的相对长度。这部分的直觉是:如果标记出现在较小的文档中,则该标记对该文档更重要的可能性更大。
BM25 中的“文档中的词项重要性”是否适用于 RAG?
如我们所见,文档中的词项重要性 严重依赖于文档内的统计信息。此外,统计信息在文档足够长时才能很好地工作。因此,它适用于搜索网页、书籍、文章等。
然而,它是否也同样适用于现代搜索应用,例如 RAG?我们来看看。
RAG 中文档的典型长度远短于 Web 搜索。实际上,即使我们处理的是网页和文章,我们也更倾向于将它们分割成块,以便 a) 密集模型可以处理它们,b) 我们可以精确定位文档中与查询相关的确切部分。
因此,RAG 中的文档大小通常较小且固定。
这使得 BM25 公式中“文档中的词项重要性”部分实际上变得无用。词项在文档中的频率总是 0 或 1,而文档的相对长度总是 1。
所以,BM25 公式中唯一仍然与 RAG 相关的是 IDF。我们来看看如何利用它。
为何 SPLADE 不总是答案
在讨论我们的新方法之前,让我们先看看 BM25 当前最先进的替代方案——SPLADE。
SPLADE 背后的想法很有趣——如果我们让一个智能的、端到端训练的模型为我们生成文本的词袋表示呢?它会为标记分配所有权重,这样我们就无需为统计信息和超参数烦恼了。然后文档被表示为稀疏嵌入,其中每个标记表示为稀疏向量的一个元素。
它在学术基准测试中表现良好。许多论文报告称,在检索质量方面,SPLADE 优于 BM25。然而,这种性能是有代价的。
不合适的 Tokenizer:为了将 transformer 用于此任务,SPLADE 模型需要使用标准的 transformer tokenizer。这些 tokenizer 并非为检索任务设计。例如,如果词汇表中不存在(非常有限的)词语,它将被分割成子词或替换为
[UNK]标记。这种行为适用于语言建模,但对检索任务来说是完全破坏性的。昂贵的标记扩展:为了弥补分词问题,SPLADE 使用了 *标记扩展* 技术。这意味着我们为查询中的每个标记生成一组相似的标记。这种方法存在一些问题:
- 它计算和内存开销大。我们需要为文档中的每个标记生成更多值,这增加了存储大小和检索时间。
- 标记扩展在哪里停止并不总是清楚。生成的标记越多,越有可能获得相关标记。但同时,生成的标记越多,越有可能获得不相关的结果。
- 标记扩展稀释了搜索的可解释性。我们无法区分文档中使用了哪些标记,哪些是通过标记扩展生成的。
领域和语言依赖性:SPLADE 模型在特定语料库上训练。这意味着它们并非总是能泛化到新的或罕见的领域。由于它们不使用任何来自语料库的统计信息,因此无法在不进行微调的情况下适应新领域。
推理时间:此外,当前可用的 SPLADE 模型相当大且慢。它们通常需要 GPU 才能在合理的时间内完成推理。
在 Qdrant,我们认识到上述问题,并正在寻找解决方案。我们的想法是结合两者的优点——BM25 的简单性和可解释性以及 transformer 的智能性,同时避免 SPLADE 的缺陷。
这就是我们提出的方案。
两全其美
如前所述,IDF 是 BM25 公式中最重要的部分。事实上,它如此重要,我们决定将其计算内置到 Qdrant 引擎本身中。请查看我们最新的发布说明。这种分离方式允许流式更新稀疏嵌入,同时保持 IDF 计算的最新状态。
至于公式的第二部分,文档中的词项重要性 需要重新思考。
既然我们不能依赖文档内的统计信息,我们可以尝试改用文档的语义。而语义正是 transformer 擅长的。因此,我们只需要解决两个问题:
- 如何从 transformer 中提取重要性信息?
- 如何避免分词问题?
注意力就是你所需要的一切(Attention is all you need)
Transformer 模型,即使是用于生成嵌入的模型,也会生成大量不同的输出。其中一些输出用于生成嵌入。
其他输出用于解决其他类型的任务,例如分类、文本生成等。
对我们特别有趣的一个输出是注意力矩阵。
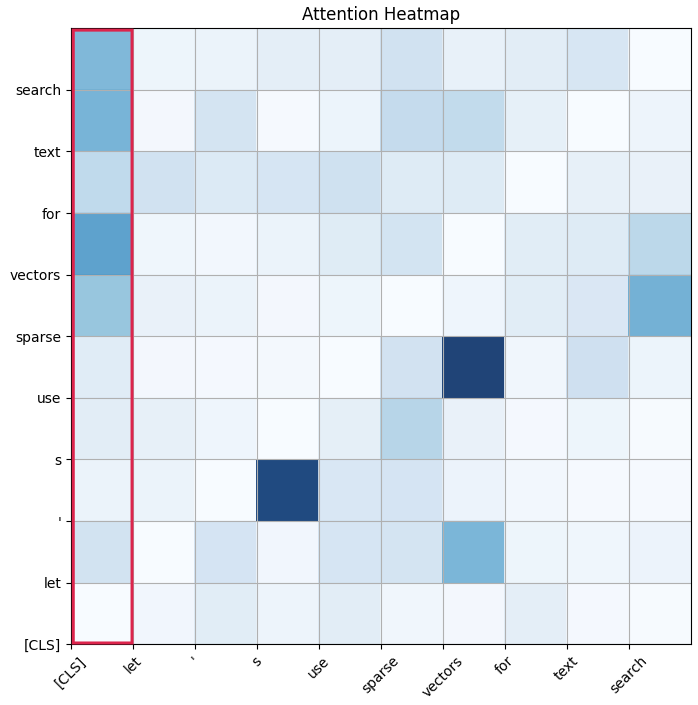
注意力矩阵
注意力矩阵是一个方阵,其中每行和每列对应于输入序列中的标记。它表示输入序列中每个标记对其他标记的重要性。
经典的 transformer 模型被训练来预测上下文中的被掩码标记,因此注意力权重定义了哪些上下文标记对被掩码标记的影响最大。
除了常规文本标记外,transformer 模型还有一个特殊的标记叫做 [CLS]。这个标记在分类任务中代表整个序列,这正是我们所需要的。
通过查看 [CLS] 标记的注意力行,我们可以获得文档中每个标记对整个文档的重要性。
sentences = "Hello, World - is the starting point in most programming languages"
features = transformer.tokenize(sentences)
# ...
attentions = transformer.auto_model(**features, output_attentions=True).attentions
weights = torch.mean(attentions[-1][0,:,0], axis=0)
# ▲ ▲ ▲ ▲
# │ │ │ └─── [CLS] token is the first one
# │ │ └─────── First item of the batch
# │ └────────── Last transformer layer
# └────────────────────────── Average all 6 attention heads
for weight, token in zip(weights, tokens):
print(f"{token}: {weight}")
# [CLS] : 0.434 // Filter out the [CLS] token
# hello : 0.039
# , : 0.039
# world : 0.107 // <-- The most important token
# - : 0.033
# is : 0.024
# the : 0.031
# starting : 0.054
# point : 0.028
# in : 0.018
# most : 0.016
# programming : 0.060 // <-- The third most important token
# languages : 0.062 // <-- The second most important token
# [SEP] : 0.047 // Filter out the [SEP] token
BM42 得分的最终公式如下:
$$ \text{score}(D,Q) = \sum_{i=1}^{N} \text{IDF}(q_i) \times \text{Attention}(\text{CLS}, q_i) $$
请注意,经典 transformer 有多个注意力头,因此我们可以为同一文档获得多个重要性向量。最简单的组合方法就是简单地平均它们。
这些平均后的注意力向量构成了我们正在寻找的重要性信息。最棒的是,可以从任何 transformer 模型中获取它们,无需额外训练。因此,只要有对应的 transformer 模型,BM42 就可以支持任何自然语言。
在我们的实现中,我们使用 sentence-transformers/all-MiniLM-L6-v2 模型,与 SPLADE 模型相比,该模型大大提高了推理速度。实际上,可以使用任何 transformer 模型。它不需要任何额外的训练,并且可以轻松适配作为 BM42 的后端工作。
WordPiece 重分词
我们需要解决的最后一个难题是分词问题。为了获得注意力向量,我们需要使用原生 transformer 分词。但这种分词方式不适用于检索任务。我们该怎么办?
实际上,我们想出的解决方案非常简单。我们在获得注意力向量后逆转分词过程。
Transformer 使用 WordPiece 分词。如果它看到一个不在词汇表中的词语,它会将其分割成子词。
看起来是这样的:
"unbelievable" -> ["un", "##believ", "##able"]
我们可以将子词合并回词语。幸运的是,子词用 ## 前缀标记,所以我们可以轻松检测它们。由于注意力权重是归一化的,我们可以简单地对子词的注意力权重求和,以获得该词语的注意力权重。
之后,我们可以应用相同的传统 NLP 技术,例如:
- 移除停用词
- 移除标点符号
- 词形还原
通过这种方式,我们可以显著减少标记数量,从而最大限度地减少稀疏嵌入的内存占用。同时,我们不会损害匹配(几乎)精确标记的能力。
实用示例
| 特性 | BM25 | SPLADE | BM42 |
|---|---|---|---|
| 可解释性 | 高 ✅ | 尚可 🆗 | 高 ✅ |
| 文档推理速度 | 非常高 ✅ | 慢 🐌 | 高 ✅ |
| 查询推理速度 | 非常高 ✅ | 慢 🐌 | 非常高 ✅ |
| 内存占用 | 低 ✅ | 高 ❌ | 低 ✅ |
| 域内准确性 | 尚可 🆗 | 高 ✅ | 高 ✅ |
| 域外准确性 | 尚可 🆗 | 低 ❌ | 尚可 🆗 |
| 小文档准确性 | 低 ❌ | 高 ✅ | 高 ✅ |
| 大文档准确性 | 高 ✅ | 低 ❌ | 尚可 🆗 |
| 未知标记处理 | 是 ✅ | 差 ❌ | 是 ✅ |
| 多语言支持 | 是 ✅ | 否 ❌ | 是 ✅ |
| 最佳匹配 | 是 ✅ | 否 ❌ | 是 ✅ |
从 Qdrant v1.10.0 开始,可以通过 FastEmbed 推理在 Qdrant 中使用 BM42。
让我们看看如何使用 BM42 和 jina.ai 密集嵌入来设置混合搜索集合。
PUT collections/my-hybrid-collection
{
"vectors": {
"jina": {
"size": 768,
"distance": "Cosine"
}
},
"sparse_vectors": {
"bm42": {
"modifier": "idf" // <--- This parameter enables the IDF calculation
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient()
client.create_collection(
collection_name="my-hybrid-collection",
vectors_config={
"jina": models.VectorParams(
size=768,
distance=models.Distance.COSINE,
)
},
sparse_vectors_config={
"bm42": models.SparseVectorParams(
modifier=models.Modifier.IDF,
)
}
)
搜索查询将使用密集嵌入和稀疏嵌入检索文档,并使用倒数排名融合 (RRF) 算法组合得分。
from fastembed import SparseTextEmbedding, TextEmbedding
query_text = "best programming language for beginners?"
model_bm42 = SparseTextEmbedding(model_name="Qdrant/bm42-all-minilm-l6-v2-attentions")
model_jina = TextEmbedding(model_name="jinaai/jina-embeddings-v2-base-en")
sparse_embedding = list(model_bm42.query_embed(query_text))[0]
dense_embedding = list(model_jina.query_embed(query_text))[0]
client.query_points(
collection_name="my-hybrid-collection",
prefetch=[
models.Prefetch(query=sparse_embedding.as_object(), using="bm42", limit=10),
models.Prefetch(query=dense_embedding.tolist(), using="jina", limit=10),
],
query=models.FusionQuery(fusion=models.Fusion.RRF), # <--- Combine the scores
limit=10
)
基准测试
为了进一步证明这一点,我们进行了一些基准测试,以突出 BM42 优于 BM25 的情况。请注意,我们无意进行详尽的评估,因为我们正在展示一种新方法,而不是一个新模型。
对于我们的实验,我们选择了 quora 数据集,它代表了问题去重任务 问题回答任务。
数据集的典型示例如下:
{"_id": "109", "text": "How GST affects the CAs and tax officers?"}
{"_id": "110", "text": "Why can't I do my homework?"}
{"_id": "111", "text": "How difficult is it get into RSI?"}
如您所见,它的文本很短,没有太多统计信息可以依赖。
使用 BM42 编码后,平均向量大小仅为每个文档 5.6 个元素。
在 Qdrant 中使用 datatype: uint8,约 53万个文档的稀疏向量索引总大小约为 13MB。
作为参考点,我们使用:
- 使用 tantivy 的 BM25
- 与 BM42 使用相同预处理流程(分词、移除停用词和词形还原)的稀疏向量 BM25 实现
| BM25 (tantivy) | BM25 (稀疏) | BM42 | |
|---|---|---|---|
| 召回率 @ 10 | 0.83 | 0.85 |
* - 由于评估脚本中的错误,这些值在发布后已更正。
为了使我们的基准测试透明,我们发布了用于评估的脚本:请参见github 仓库。
请注意,BM25 和 BM42 单独使用在生产环境中都不会表现良好。最佳结果是通过混合方法结合使用稀疏嵌入和密集嵌入实现的。在这种情况下,两种模型相互补充。稀疏模型负责精确标记匹配,而密集模型负责语义匹配。
一些更高级的模型可能会优于我们使用的默认 sentence-transformers/all-MiniLM-L6-v2 模型。我们鼓励参与训练嵌入模型的开发人员包含一种提取注意力权重的方法,并为 BM42 后端做出贡献。
培养好奇心和实验精神
尽管有其所有优势,BM42 并非总是灵丹妙药。对于未分块的大文档,BM25 可能仍然是更好的选择。
可能存在更智能的方法从 transformer 中提取重要性信息。可能有更好的方法来权衡 IDF 和注意力分数。
Qdrant 不专注于模型训练。我们的核心项目是搜索引擎本身。然而,我们明白我们并非孤立存在。通过引入 BM42,我们正在迈出一步,为我们的社区提供新颖的实验工具。
我们坚信,稀疏向量方法正处于能够产生强大而灵活结果的抽象级别。
许多人正在我们的 Discord 频道中分享你们最近的 Qdrant 项目。请随时尝试 BM42,并告诉我们你们发现了什么。