
简介
大家好!我是Huong (Celine) Hoang,我很高兴能分享今年夏天我在Qdrant作为2024编程之夏项目一部分的工作经验。在实习期间,我致力于将交叉编码器集成到FastEmbed库中,用于重新排序任务。这一增强扩展了Qdrant生态系统的功能,使开发人员能够使用Qdrant的库套件构建更多上下文感知的搜索应用程序,例如问答系统。
这个项目在技术上既具有挑战性又充满回报,促使我在处理大规模ONNX(开放神经网络交换)模型集成、分词等方面提升了技能。让我带您了解整个过程、学到的经验以及未来的发展方向。
项目概述
Qdrant以其向量搜索能力而闻名,但我的任务是更进一步——引入交叉编码器进行重新排序。传统上,FastEmbed库会生成嵌入,但交叉编码器不这样做。相反,它们根据查询与文档列表的匹配程度提供一个分数列表。这种重新排序在您想要优化搜索结果并将最相关的答案置于顶部时至关重要。
该项目围绕着创建一个新的输入-输出方案:文本数据到分数。为此,我设计了一系列类来支持ONNX模型。我使用的一些关键模型包括Xenova/ms-marco-MiniLM-L-6-v2、Xenova/ms-marco-MiniLM-L-12-v2和BAAI/bge-reranker,所有这些都专为重新排序任务设计。
需要提及的一个重要点是,FastEmbed是一个极简主义的库:它没有像PyTorch或TensorFlow那样的重依赖,因此它轻量且占用更少的存储空间。
下面是一个图表,展示了该项目的整体工作流程,详细说明了从用户交互到最终输出验证的关键步骤。
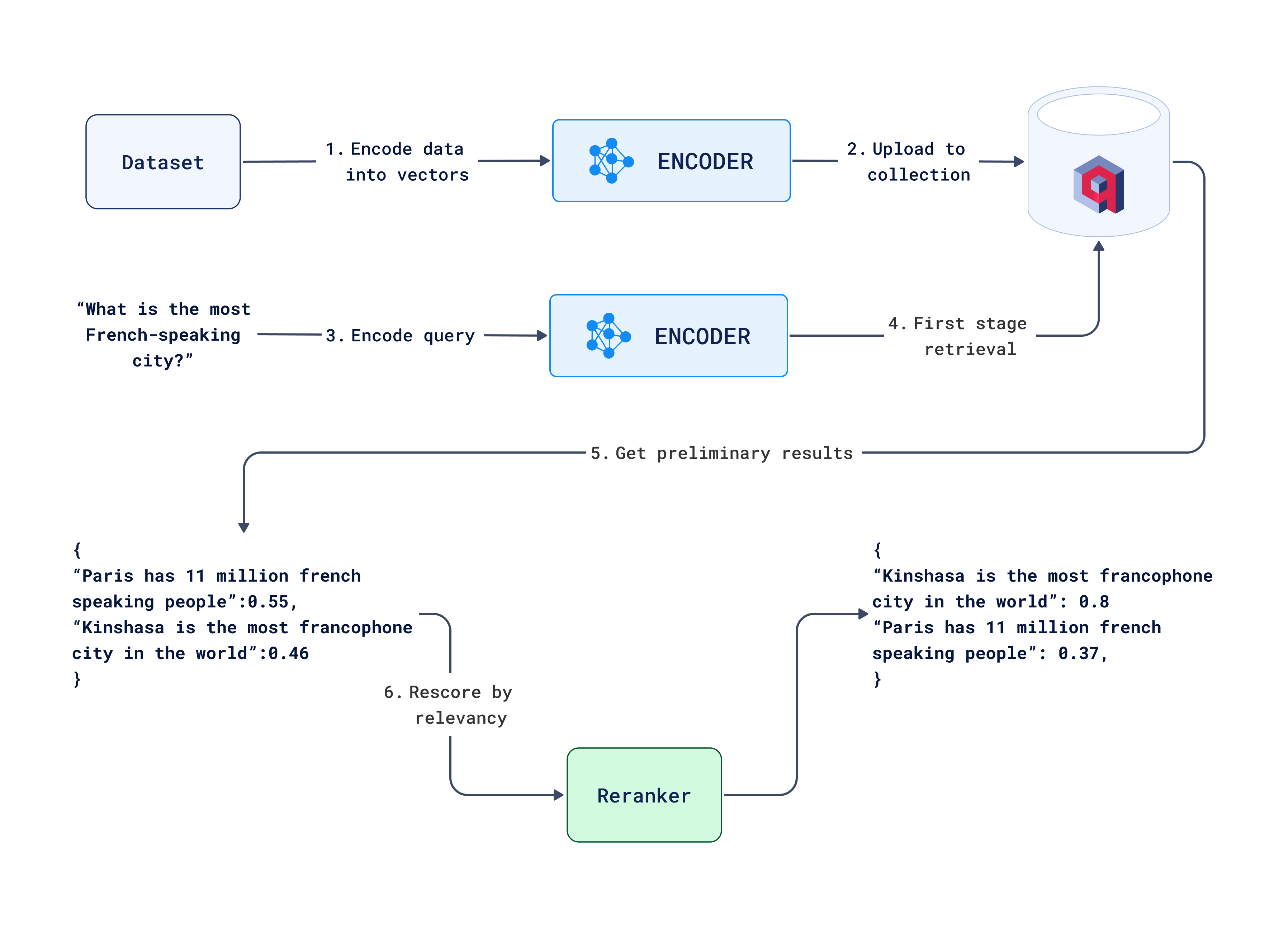
带重新排序的搜索工作流程
技术挑战
1. 构建新的输入-输出方案
FastEmbed已经支持嵌入,但使用交叉编码器进行重新排序意味着构建一个全新的类族。这些模型接受一个查询和一组文档,然后返回一个相关性分数列表。为此,我创建了像TextCrossEncoderBase和OnnxCrossEncoder这样的基类,借鉴了现有的文本嵌入模型。
我必须确保新类的层次结构对用户友好。用户应该能够使用交叉编码器,而无需了解底层模型的复杂性。例如,他们应该能够直接编写
from fastembed.rerank.cross_encoder import TextCrossEncoder
encoder = TextCrossEncoder(model_name="Xenova/ms-marco-MiniLM-L-6-v2")
scores = encoder.rerank(query, documents)
同时,在幕后,我们管理所有模型的加载、分词和评分。
2. 处理交叉编码器的分词
交叉编码器需要仔细的分词,因为它们需要区分查询和文档。这是通过令牌类型ID完成的,它帮助模型区分两者。为了实现这一点,我配置了分词器来处理成对的输入——将查询与每个文档连接起来,并相应地分配令牌类型。
高效的分词对于确保模型的性能至关重要,我专门为ONNX模型对其进行了优化。
3. 模型加载与集成
项目中最有价值的部分之一是将ONNX模型集成到FastEmbed库中。ONNX模型需要加载到一个能够高效管理计算的运行时环境中。
虽然PyTorch是这类任务的常用框架,但FastEmbed独家支持ONNX模型,使其既轻量又高效。我专注于广泛的测试,以确保ONNX模型与其PyTorch对应模型表现相当,从而确保用户可以信任结果。
我还添加了批处理支持,允许用户在不影响速度的情况下重新排序大量文档。
4. 调试和代码审查
在项目中,我遇到了许多挑战,包括模型配置、分词器和测试用例方面的问题。在我的导师George Panchuk的帮助下,我解决了这些问题,并提高了对最佳实践的理解,特别是在代码可读性、可维护性和风格方面。
一个值得注意的教训是保持代码组织性和可维护性的重要性,并重点关注可读性。这包括正确地构建模块,并确保整个代码库遵循清晰、一致的风格。
5. 测试与验证
为了确保模型的准确性和性能,我进行了广泛的测试。我将ONNX模型的输出与PyTorch对应模型的输出进行了比较,以确保转换为ONNX是正确的。这一过程的一个关键部分是严格的测试,以验证输出并识别潜在问题,例如不正确的转换或我们实现中的错误。
例如,一个验证模型输出的测试结构如下:
def test_rerank():
is_ci = os.getenv("CI")
for model_desc in TextCrossEncoder.list_supported_models():
if not is_ci and model_desc["size_in_GB"] > 1:
continue
model_name = model_desc["model"]
model = TextCrossEncoder(model_name=model_name)
query = "What is the capital of France?"
documents = ["Paris is the capital of France.", "Berlin is the capital of Germany."]
scores = np.array(model.rerank(query, documents))
canonical_scores = CANONICAL_SCORE_VALUES[model_name]
assert np.allclose(
scores, canonical_scores, atol=1e-3
), f"Model: {model_name}, Scores: {scores}, Expected: {canonical_scores}"
CANONICAL_SCORE_VALUES直接从将原始PyTorch模型应用于相同输入的结果中检索。
成果与未来改进
到项目结束时,我成功地将交叉编码器添加到了FastEmbed库中,允许用户根据相关性分数重新排序搜索结果。这一增强为依赖上下文排名(如搜索引擎和推荐系统)的应用程序开辟了新的可能性。此功能将在FastEmbed 0.4.0中提供。
未来改进的一些领域包括:
- 扩展模型支持:我们可以添加更多交叉编码器模型,特别是来自句子转换器库的模型,以提供用户更多选择。
- 并行化:优化批处理以处理更大的数据集可以进一步提高性能。
- 自定义分词:对于具有非标准分词的模型,例如BAAI/bge-reranker,可以添加更具体的分词器配置。
总体经验与总结
回顾过去,这次实习是一次非常有价值的经历。我不仅作为一名开发人员成长了,也作为一个能够承担复杂项目并将其从头到尾完成的人成长了。Qdrant团队非常支持我,尤其是在调试和审查阶段。我学到了很多关于模型集成、ONNX以及如何构建用户友好且可扩展的工具的知识。
对我来说,一个重要的收获是理解用户体验的重要性。这不仅仅是让模型工作,更是确保它们易于使用并集成到实际应用程序中。这次经历巩固了我对构建真正有影响力的解决方案的热情,我很高兴未来能继续从事这样的项目。
感谢您花时间阅读我与Qdrant和FastEmbed库的旅程。我很高兴看到这项工作将如何继续改善用户的搜索体验!