
如今,人们创建了大量不同类型的应用程序,并解决了不同领域的问题。尽管它们种类繁多,但它们有一个共同点——它们需要处理数据。真实世界的数据是一个鲜活的结构,它日复一日地增长,变化很大,并且变得越来越难以处理。
在某些情况下,您需要对数据进行分类或标注,考虑到其规模,这可能是一个棘手的问题。分割或标注过程容易出错,而这些错误可能会付出巨大的代价。想象一下,由于不准确的标签,您未能达到模型所需的质量。更糟糕的是,您的用户面临大量不相关的项目,无法找到他们需要的东西,并因此感到恼火。因此,您的用户留存率会很差,这直接影响公司的收入。避免数据中出现此类错误至关重要。
家具电商平台
假设您正在一个在线家具市场工作。
家具市场
在这种情况下,为了确保良好的用户体验,您需要将商品分成不同的类别:桌子、椅子、床等。您可以手动整理所有商品,这将花费大量金钱和时间。还有另一种方法:训练一个分类或相似性模型并依赖它。这两种方法都很难避免错误。手动标注是一项繁琐的任务,但它需要集中注意力。一旦您分心或眼睛模糊,错误就不会让您等待。模型也可能出错。您可以分析最不确定的预测并修复它们,但其他错误仍然会泄露到网站上。没有灵丹妙药。您应该彻底验证您的数据集,并且您需要工具来完成此操作。
当您确信没有太多对象放置在错误的类别中时,它们可以被视为异常值或异常。因此,您可以训练一个模型或一组模型来寻找异常,例如自编码器和在其上运行的分类器。然而,这再次是一个资源密集型任务,无论是时间还是人工劳动,因为必须为分类提供标签。相反,如果放错位置的元素比例足够高,异常值搜索方法很可能无用。
相似性搜索
相似性搜索背后的思想是衡量数据相关部分之间的语义相似性。例如,类别标题和商品图片之间。假设不适合的商品相似度会较低。
我们无法直接比较文本和图像数据。为此,我们需要一个中间表示——嵌入。嵌入只是包含语义信息的数值向量。我们可以将预训练模型应用于我们的数据以生成这些向量。创建嵌入后,我们可以测量它们之间的距离。
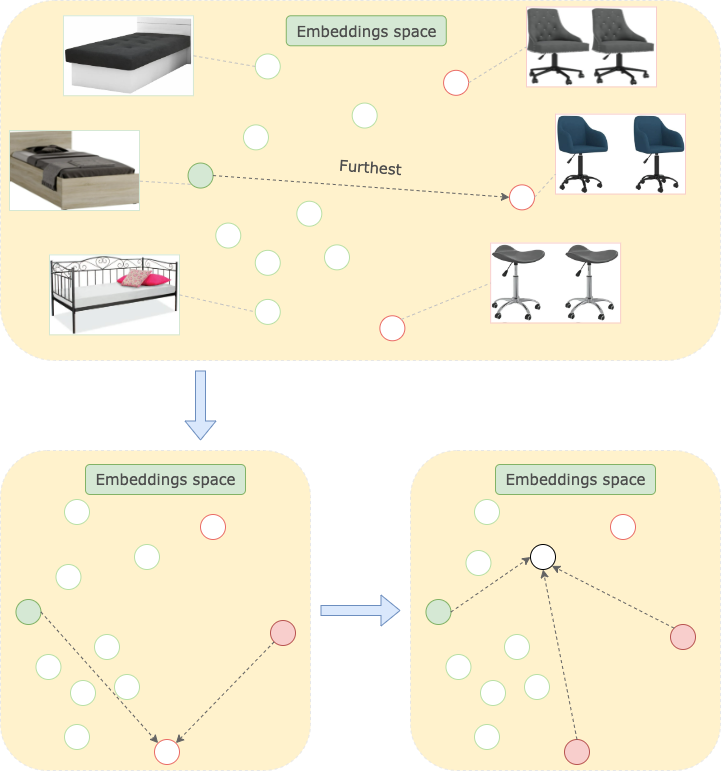
假设我们想在“单人床”类别中搜索除了单人床以外的东西。
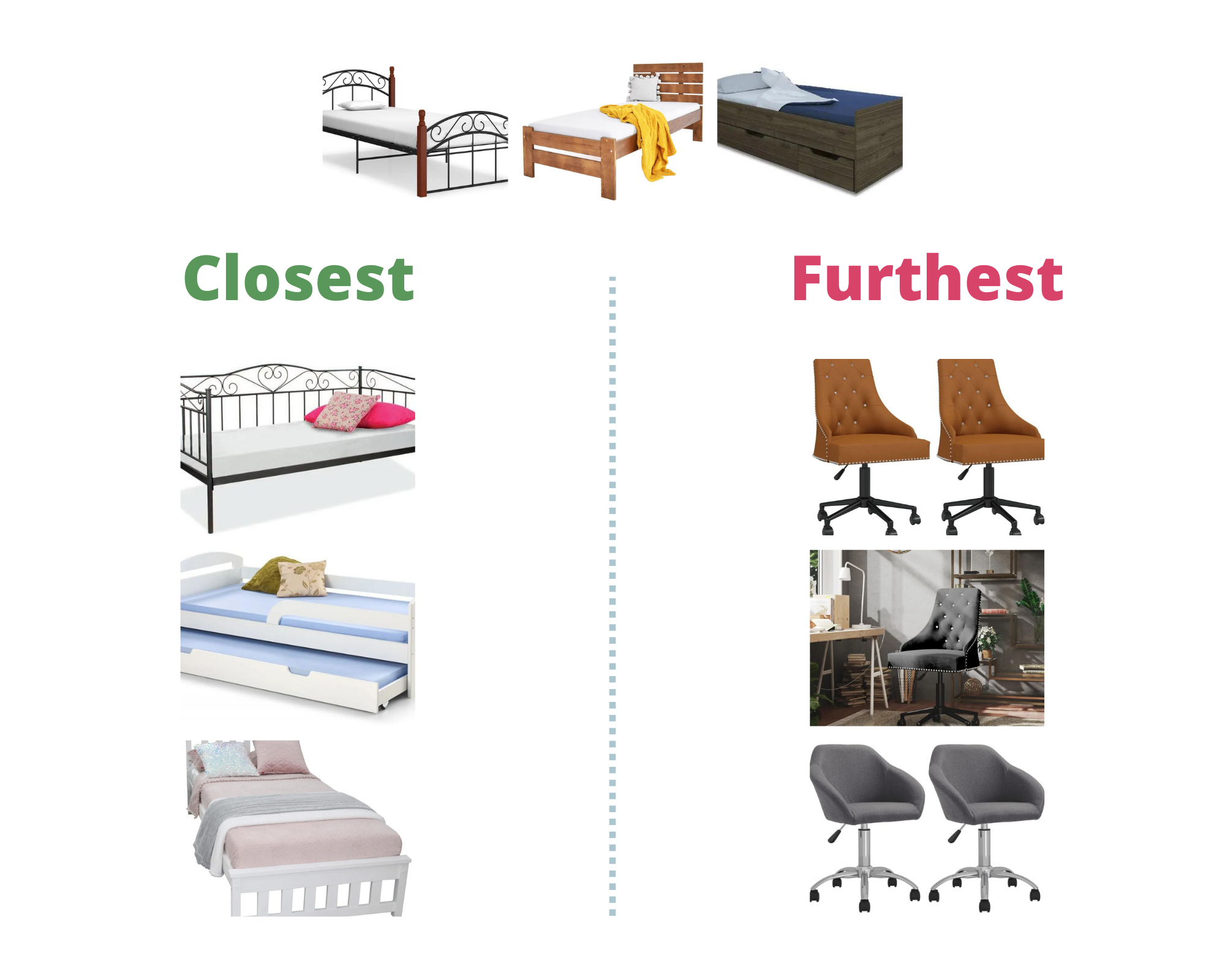
相似性搜索
可能的流程之一如下所示
- 将类别名称作为锚点并计算锚点嵌入。
- 计算放置在此类别中的每个对象的图像的嵌入。
- 比较获得的锚点和对象嵌入。
- 找到最远的。
例如,我们可以使用CLIP模型来完成。
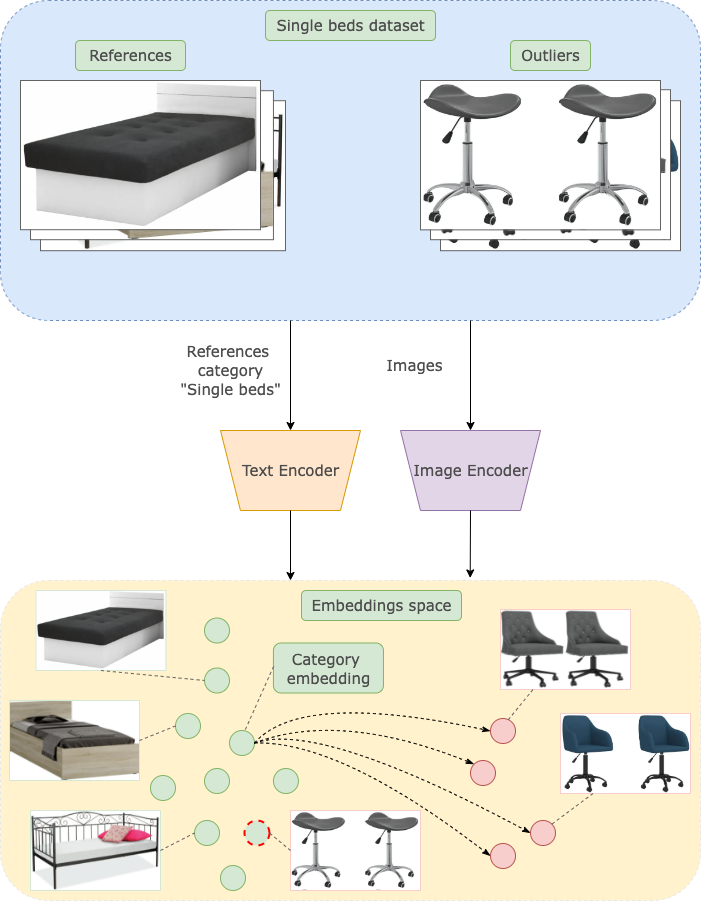
类别 vs 图像
我们还可以计算标题而不是图像的嵌入,甚至同时计算两者的嵌入以发现更多错误。
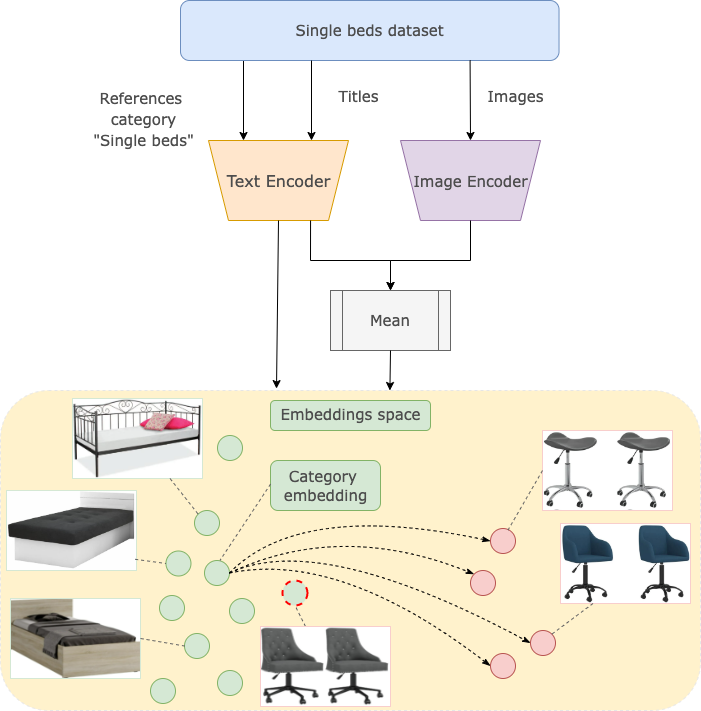
类别 vs 标题和图像
如您所见,不同的方法可以发现新的错误或相同的错误。堆叠多种技术,甚至使用不同模型的相同技术,可以提供更好的覆盖范围。提示:缓存相同模型的嵌入并在不同方法中重复使用它们可以显著加快您的查找速度。
多样性搜索
由于预训练模型只拥有关于数据的通用知识,它们仍然可能遗漏一些未被检测到的错位项目。您可能会发现自己处于这样一种情况:模型专注于不重要的特征,选择大量不相关的元素,并且未能发现真正的错误。为了缓解这个问题,您可以执行多样性搜索。
多样性搜索是一种在数据中寻找最具特色示例的方法。与相似性搜索一样,它也在嵌入上操作并测量它们之间的距离。区别在于决定接下来应该提取哪个点。
让我们想象一下如何通过相似性搜索然后通过多样性搜索获取 3 个点。
相似性
- 计算距离矩阵
- 选择您的锚点
- 从距离矩阵中获取与所选锚点距离对应的向量
- 排序获取的向量
- 获取前 3 个嵌入
多样性
- 计算距离矩阵
- 初始化起始点(随机或根据特定条件)
- 从距离矩阵中获取所选起始点的距离向量
- 找到最远的点
- 获取新点的距离向量
- 找到离所有已获取点最远的点
多样性搜索
多样性搜索利用相同的嵌入,您可以重复使用它们。如果您的数据量巨大且无法放入内存,像 Qdrant 这样的向量搜索引擎可能会有所帮助。
尽管所描述的方法可以独立使用。但它们很容易组合并提高检测能力。如果质量仍然不足,您可以使用相似性学习方法(例如使用 Quaterion)对模型进行微调,以更好地表示您的数据并在空间中分离不相似的对象。
结论
在本文中,我们阐述了基于距离的方法来查找分类数据集中的错误。展示了如何在家具网店中查找放置不正确的商品。我希望这些方法能帮助您捕获潜入数据错误类别中的“狡猾”样本,并让您的用户体验更愉快。
戳一下演示。
敬请关注 :)