
自从数据科学界发现向量搜索显著改善了大型语言模型(LLM)的答案以来,各种供应商和爱好者一直在争论存储嵌入的正确解决方案。
一些人说将它们存储在专门的引擎(即向量数据库)中更好。另一些人则认为,使用现有数据库的插件就足够了。
本文将阐述我们对该主题的观点和论据。我们将:
- 解释为什么以及何时您真正需要一个专用的向量解决方案
- 驳斥一些没有根据的说法和在构建向量搜索系统时应避免的反模式。
目录
- 每个数据库供应商迟早都会引入向量能力…… [点击]
- 拥有专用向量数据库需要数据重复。 [点击]
- 拥有专用向量数据库需要复杂的数据同步。 [点击]
- 您需要为向量服务的正常运行时间和两种解决方案的数据传输付费。 [点击]
- 还有什么比您的当前数据库增加向量搜索功能更无缝的呢? [点击]
- 数据库可以端到端支持RAG用例。 [点击]
回应主张
每个数据库供应商迟早都会引入向量能力。这将使每个数据库都成为向量数据库。
这种误解的根源在于对“向量数据库”一词的粗心使用。当我们想到数据库时,我们潜意识中会想到像Postgres或MySQL这样的关系型数据库。或者,更科学地说,一个基于ACID原则构建的服务,提供事务、强一致性保证和原子性。
大多数向量数据库并非这种意义上的“数据库”。更准确地称它们为“搜索引擎”,但不幸的是,“向量数据库”这个营销术语已经根深蒂固,不太可能改变。
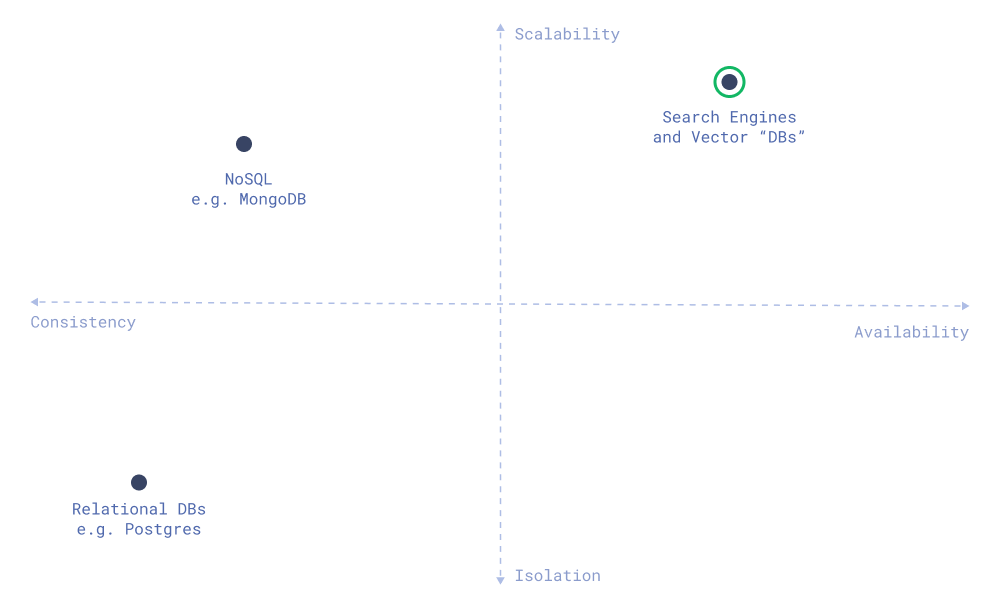
是什么让搜索引擎与众不同,以及为什么向量数据库被构建为搜索引擎?
首先,搜索引擎假定不同的工作负载模式,并优先考虑系统的不同特性。这些解决方案的核心架构围绕这些优先级构建。
搜索引擎优先考虑哪些类型的特性?
- 可伸缩性。搜索引擎旨在处理大量数据和查询。它们被设计成可水平扩展,并能处理比单个机器所能容纳的更多数据。
- 搜索速度。搜索引擎应保证查询的低延迟,而更新的原子性则不那么重要。
- 可用性。如果集群中的大多数节点宕机,搜索引擎必须保持可用。同时,它们可以容忍更新的最终一致性。
数据库保证指南
这些优先级导致了不同的架构决策,这些决策在通用数据库中无法复制,即使它支持向量索引。
拥有专用向量数据库需要数据重复。
就其本质而言,向量嵌入是原始源数据的派生。
在绝大多数情况下,嵌入是从其他数据(如文本、图像或系统中存储的附加信息)派生出来的。因此,实际上,系统中所有的嵌入都可以被认为是某些原始源的转换。
派生数据的一个显著特点是,当转换管道改变时,它也会改变。在向量嵌入的情况下,这些变化的场景非常简单:每次您更新编码器模型时,所有的嵌入都会改变。
在将向量嵌入与主数据源融合的系统中,进行此类迁移而不显著影响生产系统是不可能的。
因此,即使您想使用单个数据库来存储各种数据,您仍然需要在内部复制数据。
拥有专用向量数据库需要复杂的数据同步。
大多数生产系统倾向于将不同类型的工作负载隔离到单独的服务中。在许多情况下,这些隔离的服务甚至与搜索用例无关。
例如,用于分析的数据库和用于提供服务的数据库可以从同一源更新。然而,它们可以以最适合其典型工作负载的方式存储和组织数据。
搜索引擎通常出于同样的原因被隔离:您希望避免产生“吵闹的邻居”问题,从而影响主数据库的性能。
为了给您一些直观的感受,让我们考虑一个实际的例子。
假设我们有一个包含100万条记录的数据库。按照现代任何关系型数据库的标准,这都是一个小型数据库。您可能可以使用任何云提供商的最小免费套餐来托管它。
但是如果我们想将这个数据库用于向量搜索,100万个OpenAI的text-embedding-ada-002嵌入将占用约6GB的RAM(注意!)。正如您所看到的,向量搜索的用例完全压倒了主数据库的资源需求。实际上,这意味着您的主数据库将承受高内存需求,并且由于受限于单台机器的大小而无法高效扩展。
幸运的是,数据同步问题并非新生事物,也绝非向量搜索独有。存在许多众所周知的解决方案,从消息队列到专门的ETL工具。
例如,我们最近发布了与Airbyte的集成,允许您将来自各种来源的数据增量同步到Qdrant。
您需要为向量服务的正常运行时间和两种解决方案的数据传输付费。
在开源世界中,您支付的是所使用的资源,而不是运行的不同数据库的数量。资源更多地取决于每个用例的最佳解决方案。因此,运行一个专用的向量搜索引擎甚至可能更便宜,因为它允许专门针对向量搜索用例进行优化。
例如,Qdrant实现了一些量化技术,可以显著减少嵌入的内存占用。
在数据传输成本方面,在大多数云提供商上,区域内的网络使用通常是免费的。只要您将原始源数据和向量存储放在同一区域,就不会产生额外的数据传输成本。
还有什么比您的当前数据库增加向量搜索功能更无缝的呢?
与集成解决方案的短期吸引力相反,专用搜索引擎提供了灵活性和模块化方法。您不需要每次更新一些向量插件时都更新整个生产数据库。专用搜索引擎的维护与主数据库一样独立于数据本身。
事实上,对于更复杂的场景,例如读/写分离,使用专用向量解决方案会容易得多。您可以轻松构建跨区域复制以确保用户的低延迟。
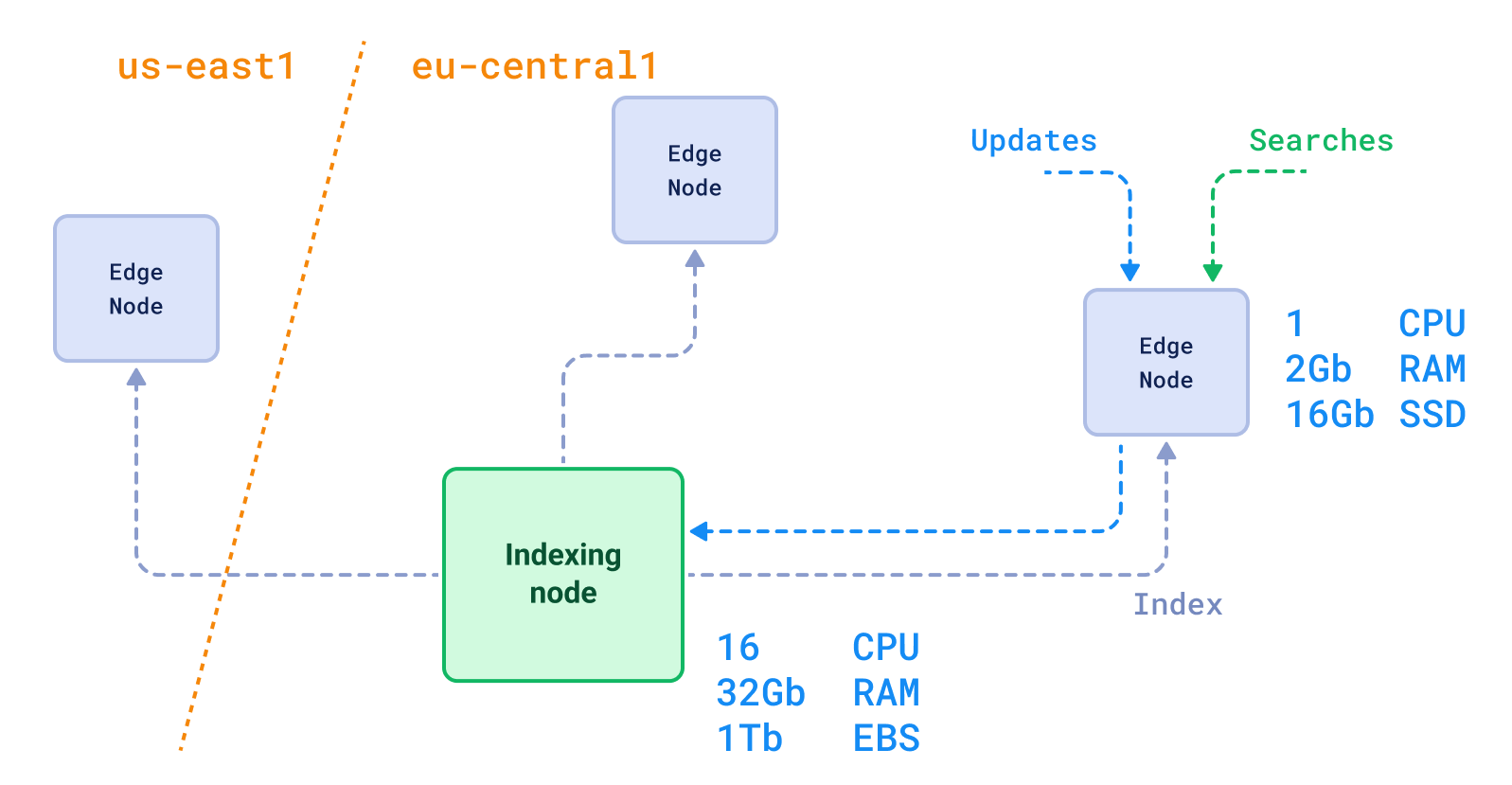
读/写分离 + 跨区域部署
这在大型企业组织中尤为重要,因为系统不同部分的职责分配给不同的团队。在这种情况下,为AI团队维护一个专用的搜索引擎,比说服核心团队更新整个主数据库要容易得多。
最后,一体化数据库的向量能力与整个技术栈的开发和发布周期紧密相连。其悠久的使用历史也意味着它们需要为向后兼容性付出高昂代价。
数据库可以端到端支持RAG用例。
抛开性能和可扩展性问题不谈,关于在数据库中实现RAG的整个讨论都假设传统数据库中唯一缺少的是向量索引和进行快速ANN查询的能力。
事实上,向量搜索的当前能力仅仅触及了可能性的皮毛。例如,在我们最近的文章中,我们讨论了构建探索API的可能性,以推动发现过程——这是kNN搜索的替代方案,在这种情况下您甚至不知道自己具体在寻找什么。
总结
最终,如果您只寻求简单的向量搜索功能且数据量不大,您不需要向量数据库。我们真诚地建议您从现有技术栈中的任何工具开始进行原型设计。但如果您的应用程序将向量搜索作为核心功能,并且您希望从中获得更多,那么您就需要一个。这就像使用多功能工具快速完成某事,或者使用高度优化针对特定用例的专用工具一样。
大规模生产系统通常由不同的专业服务和存储类型组成,这是有充分理由的,因为它是现代软件架构的最佳实践之一。这与微服务架构中独立构建块的编排类似。
当您在数据库中塞入向量索引时,您会损害主数据库的性能和可伸缩性,以及向量搜索能力。没有一种一刀切的方法能在不损害性能或灵活性方面取得两全其美。因此,如果您的用例以任何重要方式利用向量搜索,那么投入一个专用的向量搜索引擎(即向量数据库)是值得的。