
并非所有搜索旅程都始于一个明确的目的地。有时,你只是想探索一下,看看外面有什么,以及你可能会喜欢什么。当涉及到食物时,这一点尤其明显。你可能渴望甜食,但不知道具体是什么。你也可能正在寻找一道新菜,只想看看可用的选择。在这些情况下,你不可能用文本查询来表达你的需求,因为你正在寻找的东西尚未明确。当难以用语言表达你的品味时,Qdrant 的图像语义搜索会很有用。
通用架构
我们很高兴地宣布我们的美食发现演示的更新版本。这次它以开源项目的形式提供,因此你可以轻松地自行部署并使用它。如果你更喜欢直接深入研究源代码,请随时查看 GitHub 仓库。否则,请继续阅读以了解有关此演示及其工作原理的更多信息!
一般来说,我们的应用程序由三部分组成:一个 FastAPI 后端、一个 React 前端和一个 Qdrant 实例。下面的架构图显示了这些组件如何相互作用。

为什么我们使用 CLIP 模型?
CLIP 是一种神经网络,可用于将图像和文本编码为向量。更重要的是,图像和文本都被矢量化到相同的潜在空间中,因此我们可以直接比较它们。这使你可以使用文本查询对图像执行语义搜索,反之亦然。例如,如果你搜索“带配料的扁面包”,你会得到披萨的图片。或者如果你搜索“披萨”,你会得到一些带配料的扁面包的图片,即使它们没有被标记为“披萨”。这是因为 CLIP 嵌入捕获了图像和文本的语义,并且无论措辞如何,都可以找到它们之间的相似性。
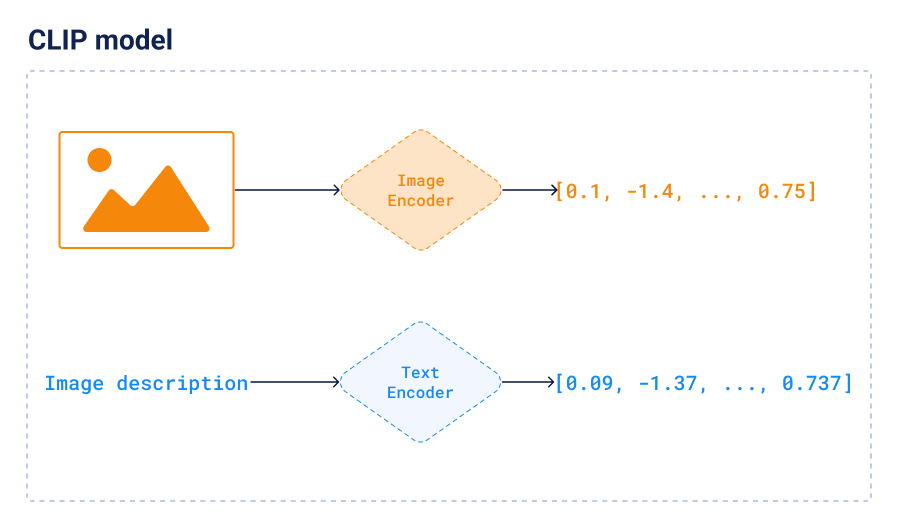
CLIP 以许多不同的方式提供。我们使用了 Sentence-Transformers 库中可用的预训练 clip-ViT-B-32 模型,因为这是最简单的入门方式。
数据集
该演示基于 Wolt 数据集。它包含超过 2M 张来自不同餐厅的菜肴图片以及一些附加元数据。单个菜肴的有效载荷如下所示
{
"cafe": {
"address": "VGX7+6R2 Vecchia Napoli, Valletta",
"categories": ["italian", "pasta", "pizza", "burgers", "mediterranean"],
"location": {"lat": 35.8980154, "lon": 14.5145106},
"menu_id": "610936a4ee8ea7a56f4a372a",
"name": "Vecchia Napoli Is-Suq Tal-Belt",
"rating": 9,
"slug": "vecchia-napoli-skyparks-suq-tal-belt"
},
"description": "Tomato sauce, mozzarella fior di latte, crispy guanciale, Pecorino Romano cheese and a hint of chilli",
"image": "https://wolt-menu-images-cdn.wolt.com/menu-images/610936a4ee8ea7a56f4a372a/005dfeb2-e734-11ec-b667-ced7a78a5abd_l_amatriciana_pizza_joel_gueller1.jpeg",
"name": "L'Amatriciana"
}
处理如此大量记录需要一些时间,因此我们预先计算了 CLIP 嵌入,将它们存储在 Qdrant 集合中,并将该集合导出为快照。你可以在这里下载。
不同的搜索模式
FastAPI 后端只公开了一个端点,但它处理多种场景。让我们逐一深入了解它们,并理解为什么需要它们。
冷启动
推荐系统面临冷启动问题。当新用户加入系统时,没有关于他们偏好的数据,因此很难推荐任何东西。这同样适用于我们的演示。当你打开它时,你会看到随机选择的菜肴,并且每次刷新页面时都会发生变化。在内部,演示选择向量空间中的一些随机点。
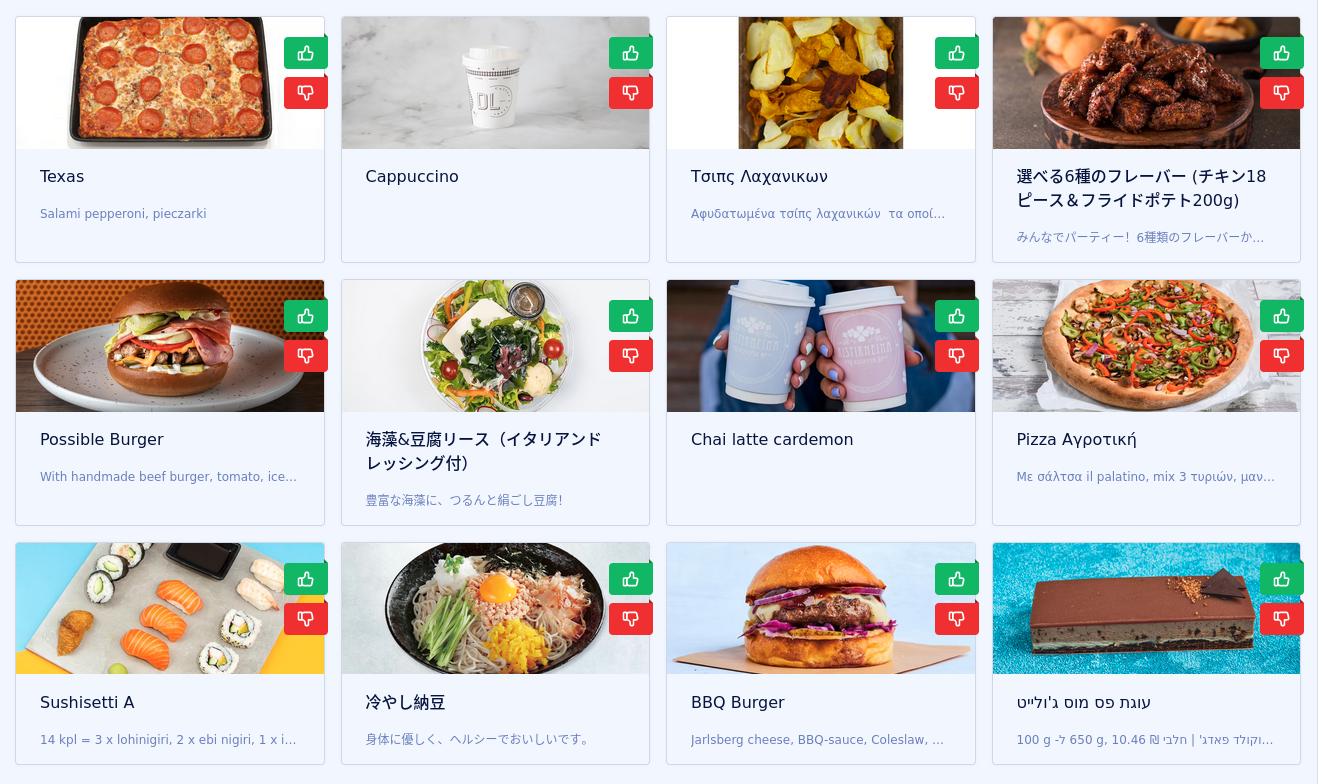
该过程应该会返回多样化的结果,因此我们有更高的机会向用户展示一些有趣的东西。
文本搜索
由于演示存在冷启动问题,我们实现了一种文本搜索模式,这对于开始探索数据很有用。你可以通过点击右上角的搜索图标输入任何文本查询。演示将使用 CLIP 模型将查询编码为向量,然后在向量空间中搜索最近邻。
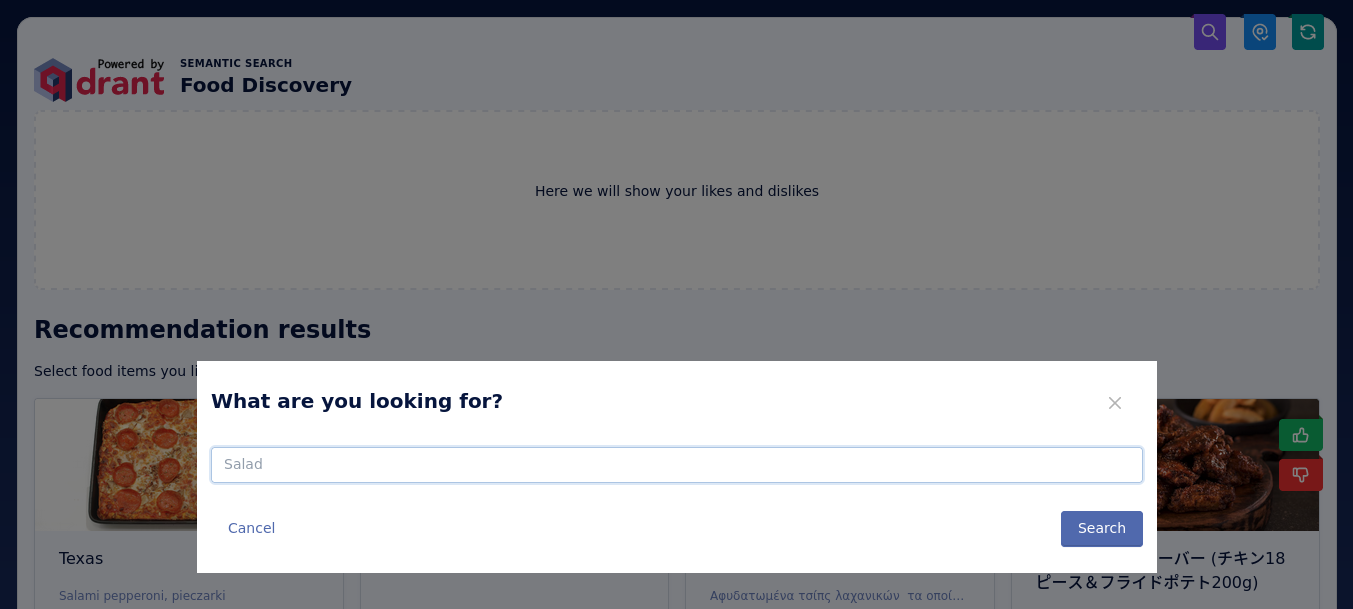
这被实现为 Qdrant 的分组搜索查询。我们没有使用简单的搜索,而是按餐厅进行分组以获得更多样化的结果。搜索组是一种类似于 SQL 中 GROUP BY 子句的机制,当你希望每个组获得特定数量的结果时(在我们的例子中只有一个),它会很有用。
import settings
# Encode query into a vector, model is an instance of
# sentence_transformers.SentenceTransformer that loaded CLIP model
query_vector = model.encode(query).tolist()
# Search for nearest neighbors, client is an instance of
# qdrant_client.QdrantClient that has to be initialized before
response = client.search_groups(
settings.QDRANT_COLLECTION,
query_vector=query_vector,
group_by=settings.GROUP_BY_FIELD,
limit=search_query.limit,
)
探索结果
该演示的主要功能是能够探索菜肴空间。你可以点击任何菜肴以查看更多详细信息,但首先你可以喜欢或不喜欢它,演示将相应地更新搜索结果。
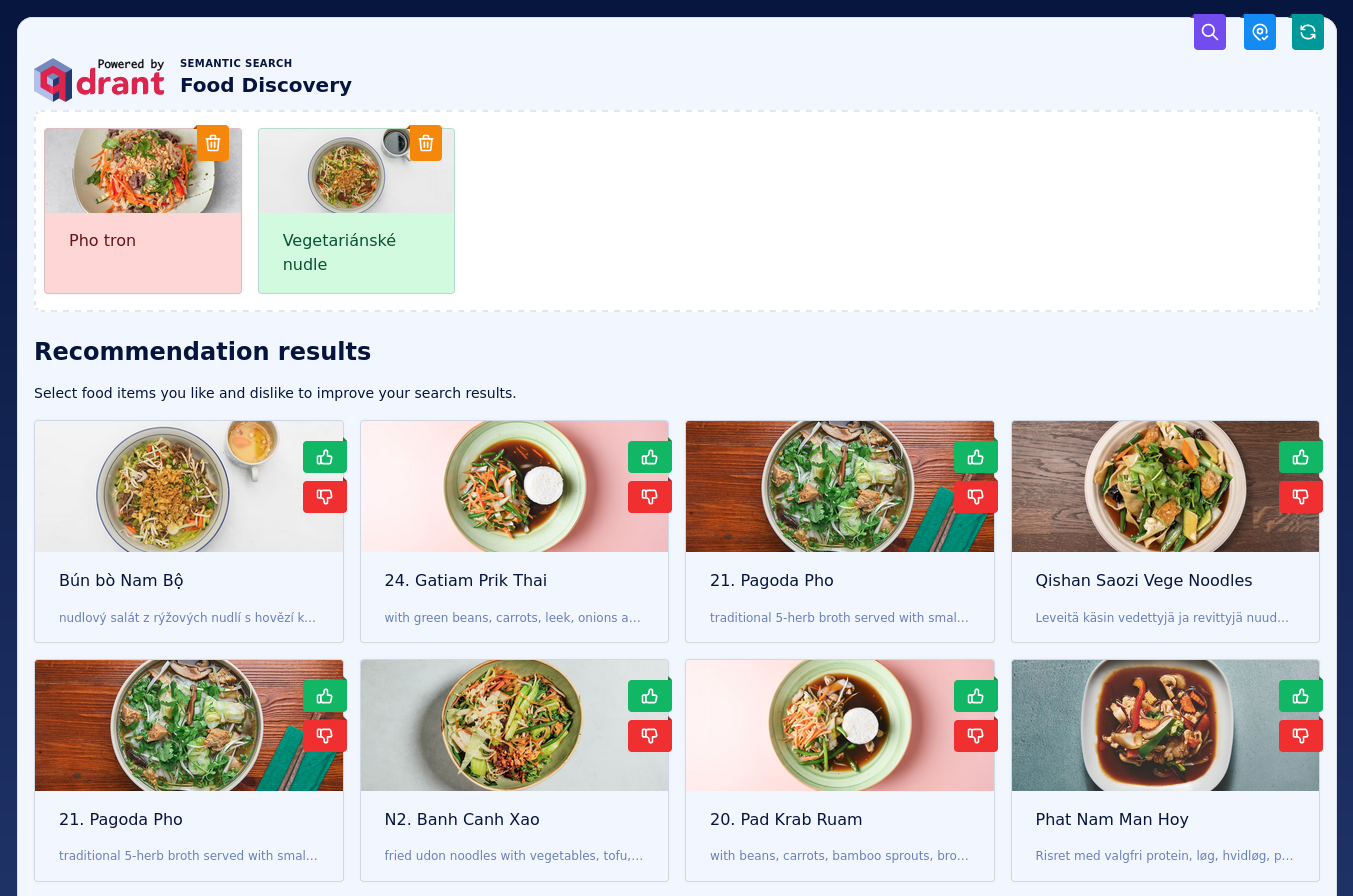
仅负面反馈
Qdrant 推荐 API 至少需要一个正面示例才能工作。然而,在我们的演示中,我们希望能够只提供负面示例。这是因为我们希望能够在没有先喜欢任何东西的情况下说“我不喜欢这道菜”。为了实现这一点,我们使用了一个技巧。我们将不喜欢的菜肴的向量取反,并将其平均值用作查询。这样,不喜欢的菜肴就会被推离搜索结果。这之所以有效,是因为余弦距离是基于两个向量之间的角度,而一个向量与其反向向量之间的角度是 180 度。
美食发现演示通过两次调用 Qdrant 来实现这个技巧。首先,我们使用 Scroll API 查找不喜欢的项目,然后计算所有这些向量的取反平均值。这允许使用 Search Groups API 查找取反平均向量的最近邻居。
import numpy as np
# Retrieve the disliked points based on their ids
disliked_points, _ = client.scroll(
settings.QDRANT_COLLECTION,
scroll_filter=models.Filter(
must=[
models.HasIdCondition(has_id=search_query.negative),
]
),
with_vectors=True,
)
# Calculate a mean vector of disliked points
disliked_vectors = np.array([point.vector for point in disliked_points])
mean_vector = np.mean(disliked_vectors, axis=0)
negated_vector = -mean_vector
# Search for nearest neighbors of the negated mean vector
response = client.search_groups(
settings.QDRANT_COLLECTION,
query_vector=negated_vector.tolist(),
group_by=settings.GROUP_BY_FIELD,
limit=search_query.limit,
)
积极和消极反馈
由于推荐 API 至少需要一个正面示例,因此我们只有在用户至少喜欢一道菜时才能使用它。理论上我们可以使用上面相同的技巧并对不喜欢的菜肴取反,但这会有点奇怪,因为 Qdrant 已经内置了该功能,我们可以只调用一次即可完成任务。始终最好在服务器端执行搜索。因此,在这种情况下,我们只需调用 Qdrant 服务器并提供正面和负面示例列表,以便它能够找到接近正面示例且远离负面示例的点。
response = client.recommend_groups(
settings.QDRANT_COLLECTION,
positive=search_query.positive,
negative=search_query.negative,
group_by=settings.GROUP_BY_FIELD,
limit=search_query.limit,
)
从用户角度来看,与上一个案例相比没有任何变化。
基于位置的搜索
最后但同样重要的是,位置在美食发现过程中扮演着重要角色。你肯定在寻找附近能找到的东西,而不是在地球的另一端。因此,你的当前位置可以作为过滤条件进行切换。你可以通过点击右上角的“在我附近查找”图标来启用它。这样你就可以找到你附近最好的披萨,而不是全世界最好的。Qdrant 地理半径过滤器 是一个完美的选择。它允许你根据与给定点的距离来过滤结果。
from qdrant_client import models
# Create a geo radius filter
query_filter = models.Filter(
must=[
models.FieldCondition(
key="cafe.location",
geo_radius=models.GeoRadius(
center=models.GeoPoint(
lon=location.longitude,
lat=location.latitude,
),
radius=location.radius_km * 1000,
),
)
]
)
这样的过滤器需要 一个有效载荷索引 才能高效工作,并且它是在我们用于创建快照的集合上创建的。当你将其导入到你的实例中时,该索引将已经存在。
使用演示
美食发现演示在线可用,但如果你更喜欢在本地运行它,可以使用 Docker。 README 中更详细地描述了所有步骤,但这里有一个快速入门
git clone git@github.com:qdrant/demo-food-discovery.git
cd demo-food-discovery
# Create .env file based on .env.example
docker-compose up -d
该演示将在 https://:8001 可用,但除非你将快照导入到你的 Qdrant 实例,否则你将无法搜索任何内容。如果你不想费心托管本地实例,可以使用 Qdrant Cloud 集群。4 GB RAM 足以加载所有 2 百万条目。
分叉并重用
我们的演示是完全开源的。欢迎自由分叉,用你自己的数据集更新,或根据你的用例调整应用程序。无论你是想了解语义搜索的机制,还是想为构建更大的项目奠定基础,这个演示都可以作为起点。查看 美食发现演示仓库以开始使用。如果你有任何问题,请随时通过 Discord 联系我们。