
无论您是刚刚踏入向量搜索领域的新手,还是经验丰富的从业者,您可能都曾想过如何选择合适的嵌入模型以达到最佳搜索质量。有一些公开基准,例如 MTEB,可以帮助您缩小选择范围,但这些基准中使用的数据集很少能代表您的特定领域数据。此外,搜索质量可能不是您唯一的要求。例如,一些最佳模型在检索方面可能非常准确,但您可能无法负担运行它们,例如由于高资源使用或预算限制。
选择最佳嵌入模型是一个多目标优化问题,没有一刀切的解决方案,而且可能永远不会有。在本文中,我们将尝试提供一些指导,说明如何以实用的方式解决此问题,以及如何从模型选择过渡到将其投入生产。
评估:向量搜索的“圣杯”
不衡量就无法改进。这句老话虽然陈词滥调,但对于检索来说也是如此。搜索质量不仅应该在运行系统中衡量,而且在做出最重要的决策——选择哪个嵌入模型之前,也应该进行衡量。
了解您的模型所“说”的语言
嵌入模型在训练时会考虑特定的语言。在评估模型时,请考虑它是否支持您数据中现有或预计拥有的所有语言。如果您的数据不统一,您可能需要一个多语言模型,该模型可以正确嵌入不同语言的文本。如果您使用开源模型,那么您的模型很可能在 Hugging Face Hub 上有文档。例如,在演示中流行的 all-MiniLM-L6-v2 仅在英语数据上进行训练,因此如果您有其他语言的数据,它不是一个好的选择。
然而,这不仅仅关乎语言,还关乎模型如何处理输入数据。令人惊讶的是,这常常被忽视。文本嵌入模型使用特定的分词器将输入数据分块,然后 通过为每个标记分配特定的输入向量表示来启动所有 Transformer 魔法。
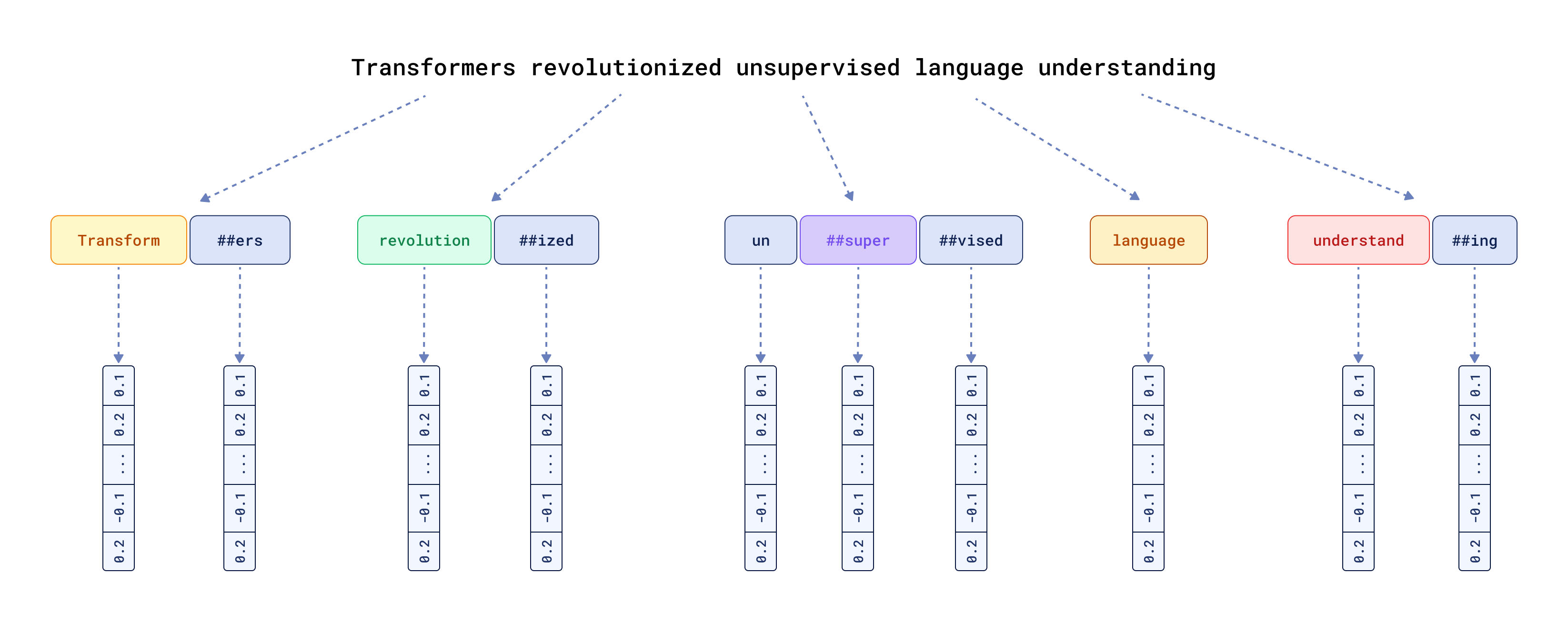
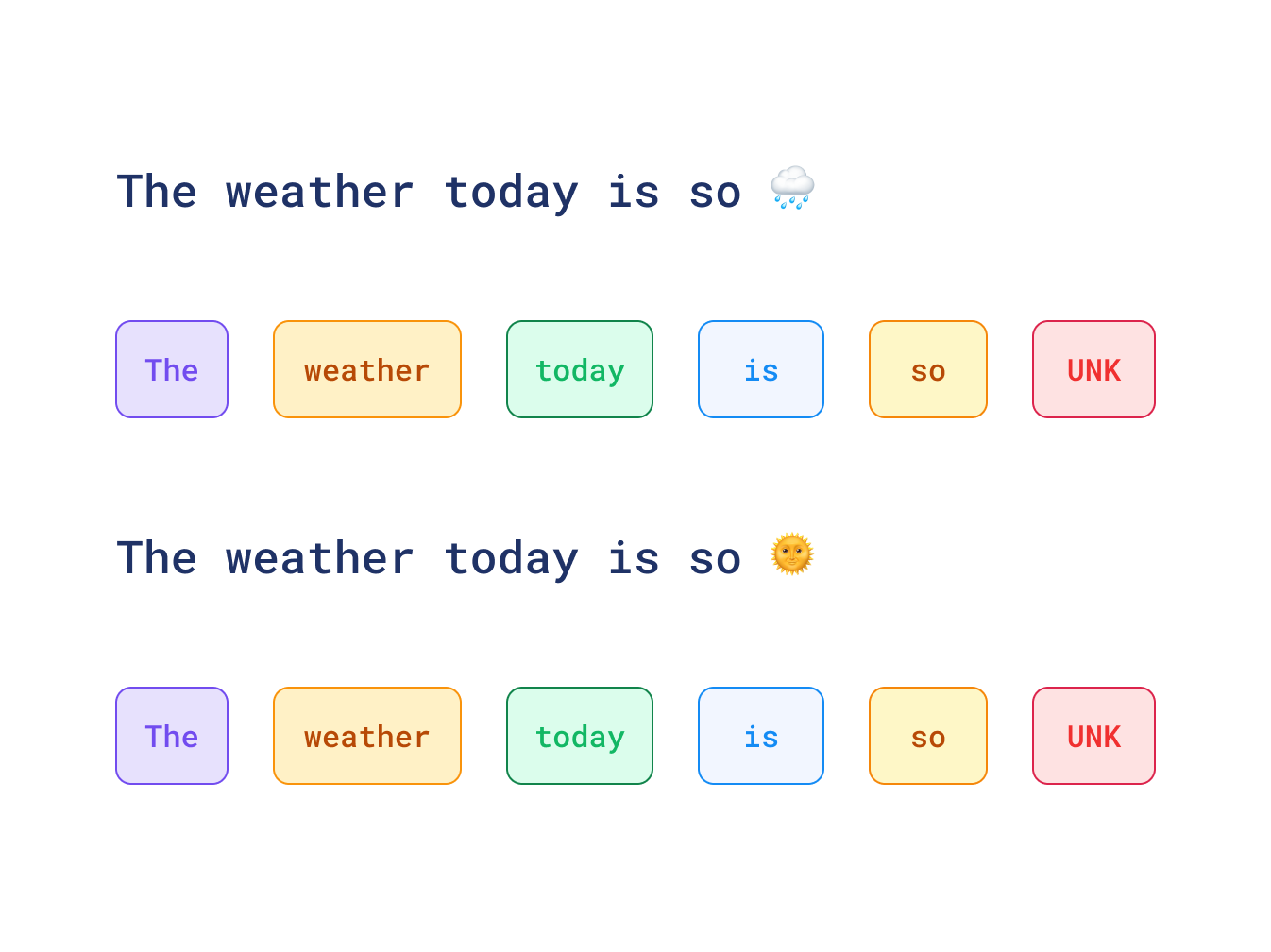
这种内部工作原理的一个影响是,模型只能理解其分词器所训练的内容(是的,分词器也是可训练的组件)。因此,它在训练期间从未见过的任何字符都将被特殊 UNK 标记替换。如果您分析社交媒体数据,那么您可能会惊讶地发现两个相互矛盾的句子在您的搜索中实际上是完美匹配的,如下例所示:
对于您的目标语言中占主导地位的带重音字母、不同字母表等,情况可能也如此。然而,在这种情况下,您根本不应该使用这样的模型,因为它无论如何都不支持您的语言。分词对嵌入质量的影响比许多人想象的要大。如果您想了解分词的影响是什么,我们建议您参加我们与 DeepLearning.AI 共同录制的 检索优化:从分词到向量量化 课程。如果您仍然想知道为什么您的语义搜索引擎无法处理数值数据(例如价格或日期)以及如何解决这些问题,您可能会发现该课程特别有趣。
您如何知道分词器是否支持目标语言?对于开源模型来说,这相当容易,因为您可以直接运行分词器而无需模型,然后查看生成的标记是什么样子。对于商业模型来说,这可能稍微困难一些,但像 OpenAI 和 Cohere 这样的公司对此非常透明,并开源了它们的分词器。在最坏的情况下,您可以修改一些可疑的标记,然后查看模型在原始文本和修改后文本之间的相似性方面如何反应。
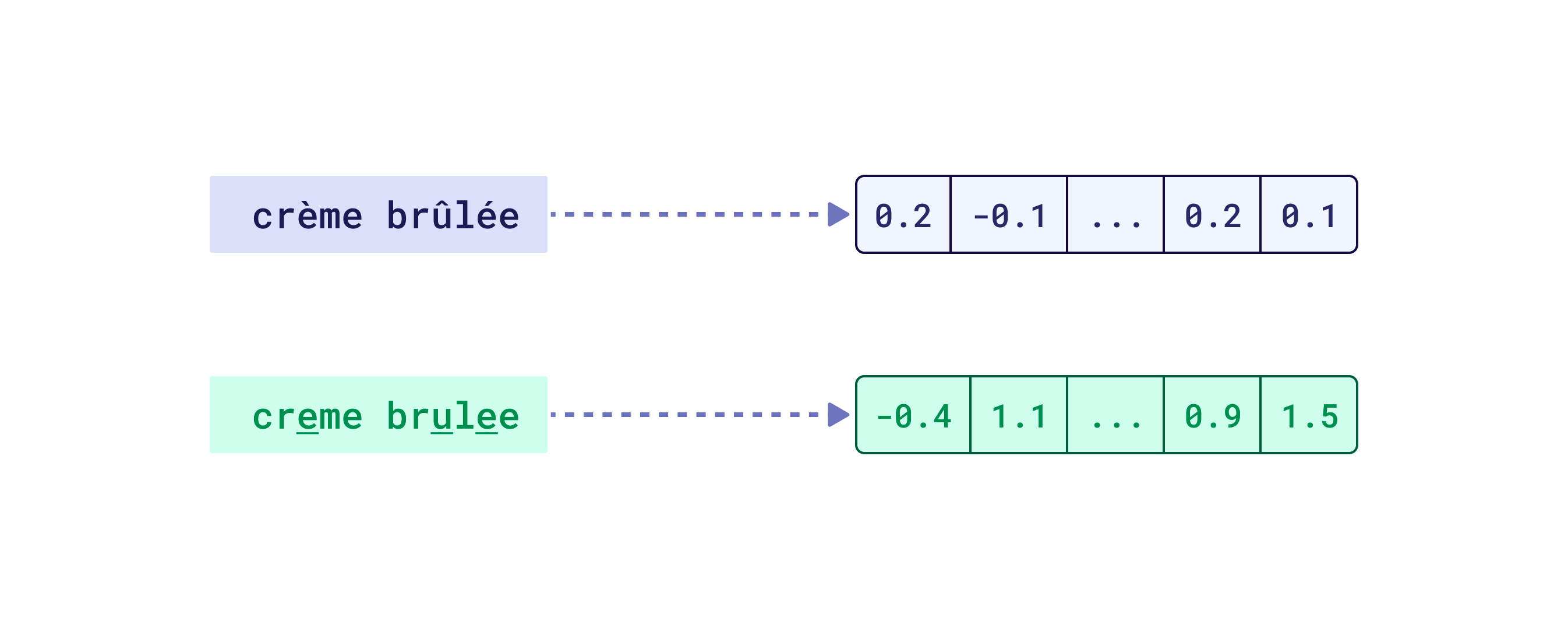
如果创建的表示在向量空间中相距甚远,则可能表明某些不支持的字符被替换为 UNK 标记,因此模型无法正确嵌入输入数据。
需要考虑的事项清单
然而,评估并非只关注输入标记。首先,我们应该衡量特定模型处理我们希望用于的任务的能力。向量嵌入是多用途工具,有些模型可能更适合语义相似性,而另一些则适用于检索或问答。除了您自己,没有人能告诉您您试图解决的问题的性质。任务类型不是选择正确嵌入模型时唯一需要考虑的因素。
- 序列长度 - 嵌入模型一次可以处理的输入大小有限。检查您的文档有多长以及它们包含多少个标记。如果您使用开源模型,您可以在 Hugging Face Hub 上的模型卡中查看最大序列长度。对于商业模型,最好直接询问提供商。
- 模型大小 - 较大的模型具有更多的参数并需要更多的内存。推理时间也取决于模型架构和您的硬件。有些模型只能在 GPU 上有效运行,而另一些则可以在 CPU 上运行。
- 优化支持 - 并非所有模型都兼容所有优化技术。例如,二值量化和套娃嵌入需要特定的模型特征。
这个列表并非详尽无遗,因为可能还有许多其他事情需要考虑,但您应该明白了。
这就是为什么您需要精确定义您真正想要解决的任务,亲自动手处理系统应该处理的数据,并为其构建一个真实数据集,这样您才能做出明智的决定。
构建真实数据集
数据集的样式取决于您要评估的任务。如果我们谈论语义相似性,那么您将需要成对的文本,并附带一个指示它们相似程度的分数。
对于语义相似性任务,您的数据集可能如下所示:
[
{
"text1": "I love this movie, it's fantastic",
"text2": "This film is amazing, I really enjoyed it",
"similarity_score": 0.92
},
{
"text1": "The weather is nice today",
"text2": "I need to buy groceries",
"similarity_score": 0.12
}
]
通常,Qdrant 用户会构建检索系统,他们单独使用这些系统,或将其与大型语言模型结合以构建检索增强生成。当我们进行检索时,我们需要与语义相似性略有不同的黄金数据集结构。检索问题是为给定查询找到 K 个最相关的文档。因此,我们需要一组查询和一组我们期望为每个查询接收的文档。还有三种不同粒度级别定义相关性的方法:
- 二元相关性 - 文档要么相关,要么不相关。
- 序数相关性 - 文档可以或多或少相关(排名)。
- 带分数的关联性 - 文档可以有一个分数,表示其关联程度。
[
{
"query": "How do vector databases work?",
"relevant_documents": [
{
"id": "doc_123",
"text": "Vector databases store and index vector embeddings...",
"relevance": 3 // Highly relevant (scale 0-3)
},
{
"id": "doc_456",
"text": "The architecture of modern vector search engines...",
"relevance": 2 // Moderately relevant
}
]
},
{
"query": "Python code example for Qdrant",
"relevant_documents": [
{
"id": "doc_789",
"text": "```python\nfrom qdrant_client import QdrantClient\n...",
"relevance": 3 // Highly relevant
}
]
}
]
拥有数据集后,您就可以开始使用评估指标(例如 precision@k、MRR 或 NDCG)评估模型。有一些现有库,例如 ranx 可以帮助您完成此操作。运行评估过程是了解不同模型在您的数据上表现如何的好方法。您甚至可以通过这种方式测试专有模型。然而,这并非您选择最佳模型时唯一应考虑的因素。
请不要害怕构建您的评估数据集。它并不像看起来那么复杂,而且是关键一步!您不需要数百万个样本就能很好地了解模型的表现。数百个精心策划的示例可能是一个很好的起点。即使几十个也比没有强!
计算资源限制
即使您为您的领域找到了性能最佳的嵌入模型,也并不意味着您可以使用它。软件项目并非孤立存在,您必须考虑大局。例如,您可能面临预算限制,从而限制您的选择。这还关乎务实。如果一个模型精度提高了 1%,但速度慢了 10 倍,消耗的资源也多了 10 倍,那它真的值得吗?
最终,在某些情况下,享受过程比达到目标更重要,但这对于搜索而言并非如此。达到目标的方式越简单、越快速,就越好。
吞吐量、延迟和成本
在选择用于生产的嵌入模型时,您需要考虑三个关键的运营因素:
- 吞吐量:每秒可以生成多少个嵌入?这直接影响您的系统处理负载的能力。较大的模型通常吞吐量较低,这可能在数据摄取或高流量期间成为瓶颈。
- 延迟:获取单个嵌入的速度有多快?对于像边输入边搜索或交互式聊天机器人这样的实时应用程序,低延迟至关重要。较大模型的量化版本可以显著改善延迟。
- 成本:这包括基础设施成本(CPU/GPU 资源、内存)以及(对于基于 API 的模型)按令牌或按请求收费。例如,运行您自己的模型可能前期成本较高,但每请求成本低于某些 SaaS 模型。
正确的平衡取决于您的具体用例。新闻推荐系统可能优先考虑吞吐量,以实时处理大量文章,而网站搜索可能优先考虑延迟,以实现实时结果。同样,使用大型语言模型生成响应的聊天机器人可能优先考虑成本效益,因为大型语言模型通常较慢,而检索并非该过程中最耗时的部分。
平衡各方面
经过所有这些考虑,您应该会得到一个表格,其中总结了您在所有不同条件下评估的每个模型。现在事情变得困难了,答案也不再显而易见。
下面是一个这样的比较表可能是什么样子的示例:
| 模型 | Precision@10 | MRR | 推理时间 | 内存使用 | 成本 | 多语言 | 最大序列长度 |
|---|---|---|---|---|---|---|---|
| 昂贵的专有 SaaS 专用 | 0.92 | 0.87 | 依赖 API | 不适用 | 0.25 美元/百万 token | 可能,但尚未记录 | 8192 |
| 更便宜的专有多语言 | 0.89 | 0.84 | 依赖 API | 不适用 | 0.01 美元/百万 token | 是 (94 种语言) | 4096 |
| 开源 GPU 必需 | 0.88 | 0.83 | 120 毫秒 | 15GB | 自托管 | 英语 | 1024 |
| CPU 上的开源 | 0.85 | 0.79 | 30 毫秒 | 120MB | 自托管 | 英语 | 512 |
决策过程应以您的具体要求为指导。面临预算限制的组织可能会倾向于自托管选项,而那些倾向于避免处理基础设施管理的组织可能会选择基于 API 的解决方案。谁知道呢?也许您的项目不需要最高的精度,而一个较小的模型就能很好地完成任务。

请记住,这并非一锤定音的决定。随着您的应用程序的发展,您可能需要重新审视嵌入模型的选择。Qdrant 的架构使其相对容易在需要时迁移到不同的模型。命名向量有助于创建包含多个模型的系统,并根据查询在它们之间切换,或者构建一个利用不同模型或更复杂搜索管道的 混合搜索。
一个重要的决定还在于嵌入模型的托管位置。也许您更喜欢不处理基础设施管理,而是以原始形式发送您处理的数据?Qdrant 现在为您提供了解决方案!
本地源嵌入
如果能将您选择的嵌入模型尽可能靠近您的搜索引擎运行,那岂不是太棒了?网络延迟可能是最大的敌人之一,如果从较远的位置传输数百万个向量,可能需要更长时间。此外,一些云提供商会向您收取数据传输费用,因此这不仅关乎延迟,还关乎成本。最后,在本地运行嵌入模型需要一些专业知识和资源,如果您想专注于核心业务,您可能更愿意避免这样做。

Qdrant 的云推理通过允许您在运行向量数据库的集群旁边运行嵌入模型来解决这些问题。对于那些不想担心模型推理,只想使用适用于其现有数据的搜索的人来说,这是一个完美的解决方案。请查看 云推理文档 以了解更多信息。