
距离我们发布关于如何使用 Qdrant 构建混合搜索系统的原创文章已经一年多了。最初的想法很简单:结合不同搜索方法的结果以提高检索质量。早在 2023 年,你仍然需要使用额外的服务来提供词汇搜索功能并合并所有中间结果。从那时起,情况发生了变化。一旦我们引入了对稀疏向量的支持,额外的搜索服务就变得多余了,但你仍然需要在你的端合并不同方法的结果。
Qdrant 1.10 引入了新的查询 API,让你可以通过结合不同的搜索方法来构建搜索系统,以提高检索质量。现在所有操作都在服务器端完成,你可以专注于为用户构建最佳的搜索体验。在本文中,我们将向你展示如何利用新的 查询 API 来构建混合搜索系统。
推出新的查询 API
在 Qdrant,我们相信向量搜索功能远不止简单的最近邻搜索。这就是为什么我们为不同的搜索用例提供了单独的方法,例如 search、recommend 或 discover。随着最新版本的发布,我们很高兴推出新的查询 API,它将所有这些方法组合到一个端点中,并且还支持创建可用于构建复杂搜索管道的嵌套多阶段查询。
如果你是 Qdrant 的现有用户,你可能有一个正在运行的搜索机制,无论是稀疏的还是密集的,你都希望对其进行改进。任何更改之前都应该对其有效性进行适当的评估。
你的搜索系统效率如何?
如果你不衡量质量,任何实验都没有意义。否则你将如何比较哪种方法更适合你的用例?最常见的方法是使用标准指标,例如 precision@k、MRR 或 NDCG。有一些现有的库,例如 ranx,可以帮助你完成这项工作。我们需要拥有真实数据集来计算其中任何一个,但整理它是一个单独的任务。
from ranx import Qrels, Run, evaluate
# Qrels, or query relevance judgments, keep the ground truth data
qrels_dict = { "q_1": { "d_12": 5, "d_25": 3 },
"q_2": { "d_11": 6, "d_22": 1 } }
# Runs are built from the search results
run_dict = { "q_1": { "d_12": 0.9, "d_23": 0.8, "d_25": 0.7,
"d_36": 0.6, "d_32": 0.5, "d_35": 0.4 },
"q_2": { "d_12": 0.9, "d_11": 0.8, "d_25": 0.7,
"d_36": 0.6, "d_22": 0.5, "d_35": 0.4 } }
# We need to create both objects, and then we can evaluate the run against the qrels
qrels = Qrels(qrels_dict)
run = Run(run_dict)
# Calculating the NDCG@5 metric is as simple as that
evaluate(qrels, run, "ndcg@5")
使用查询 API 的可用嵌入选项
Qdrant 中对每个点多个向量的支持并不是什么新鲜事,但引入查询 API 使其功能更加强大。1.10 版本支持多向量,允许你将嵌入列表视为单个实体。利用此功能的方法有很多种,最突出的一种是支持延迟交互模型,例如 ColBERT。这类模型不是为每个文档或查询提供单个嵌入,而是为文本的每个标记创建一个单独的嵌入。在搜索过程中,最终分数是根据查询和文档标记之间的交互计算的。与交叉编码器相反,文档嵌入可以预先计算并存储在数据库中,这使得搜索过程快得多。如果你对细节感兴趣,请查看 我们来自 Jina AI 的朋友撰写的关于 ColBERT 的文章。
除了多向量,你还可以使用常规的密集和稀疏向量,并尝试使用较小的数据类型来减少内存使用。命名向量可以帮助你存储不同维度的嵌入,这在你使用多个模型来表示数据或希望利用套娃嵌入时很有用。

构建混合搜索的方法并非只有一种。设计它的过程是一个探索性练习,你需要测试各种设置并衡量它们的有效性。构建适当的搜索体验是一项复杂的任务,最好是数据驱动的,而不仅仅是依靠直觉。
融合与重排序
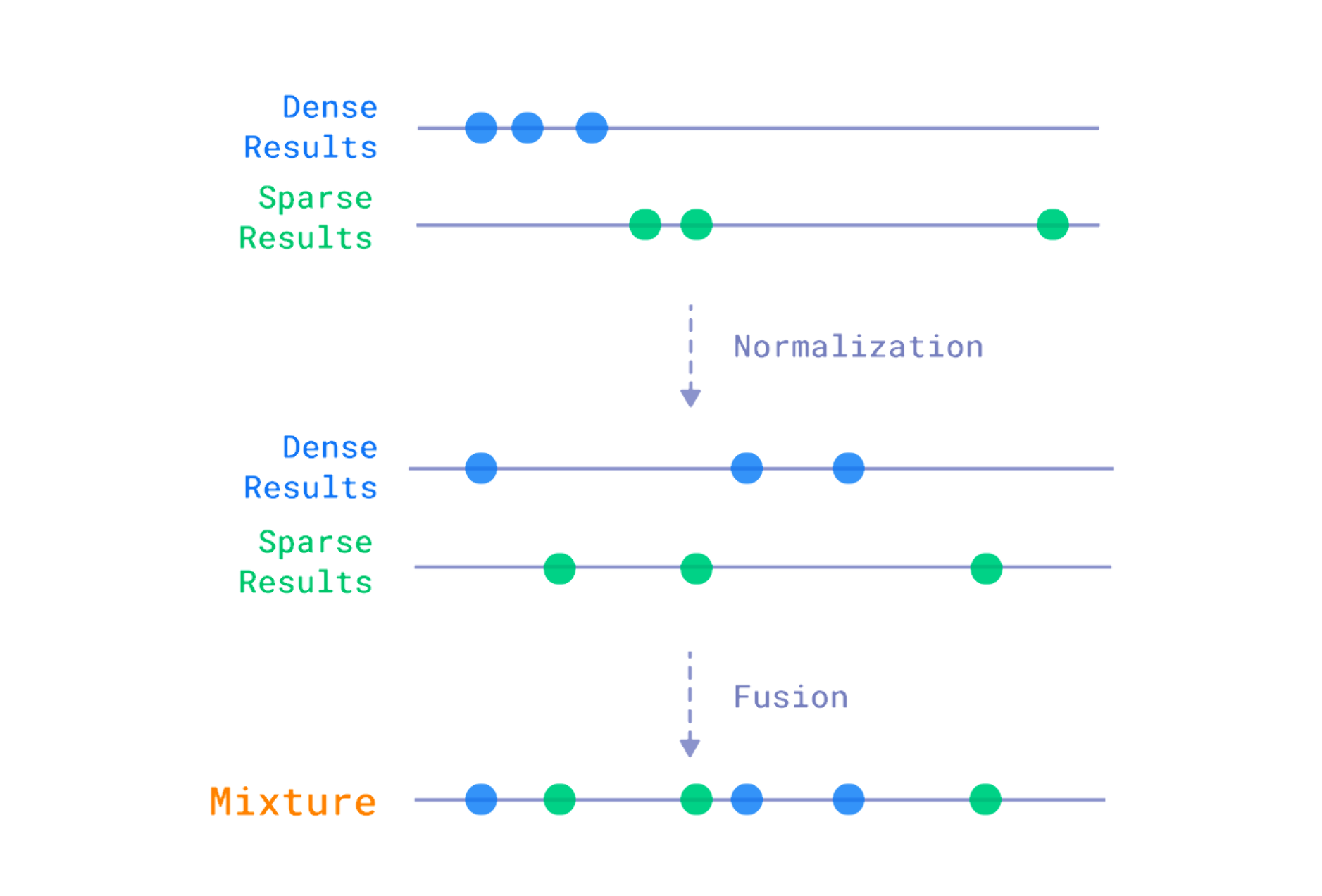
我们可以区分构建混合搜索系统的两种主要方法:融合和重排序。前者是根据每种方法返回的分数来组合不同搜索方法的结果。这通常涉及一些归一化,因为不同方法返回的分数可能在不同的范围内。之后,有一个公式,它采用相关性度量并计算我们稍后用于重新排序文档的最终分数。Qdrant 内置支持倒数排序融合方法,这是该领域的实际标准。
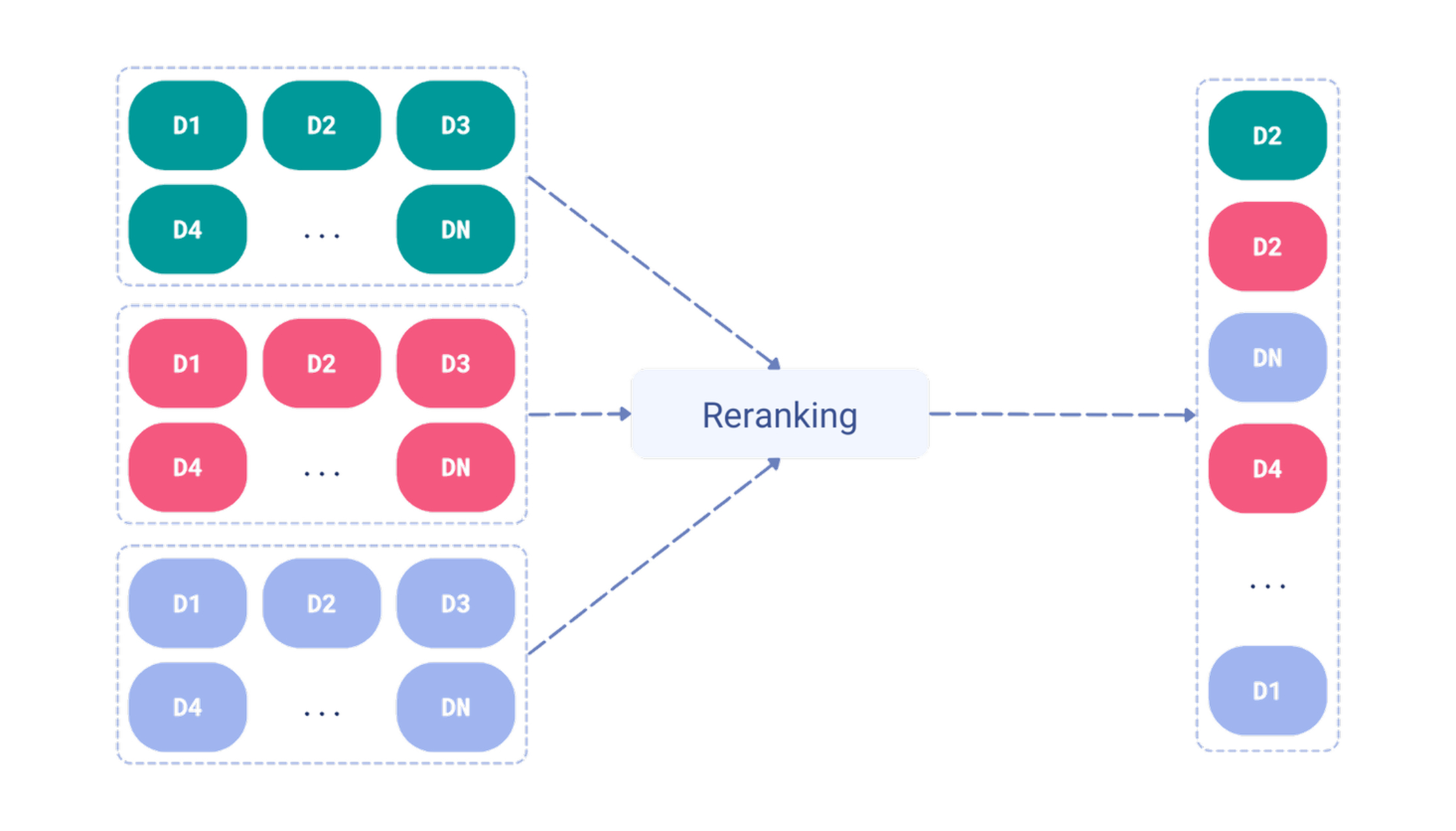
另一方面,重排序是获取不同搜索方法的结果,并根据使用文档内容而不是仅仅分数进行的一些额外处理来重新排序它们。这种处理可能依赖于额外的神经网络模型,例如交叉编码器,它在整个数据集上使用效率低下。这些方法实际上只适用于在较快的搜索方法返回的较小候选子集上使用时才适用。在这种情况下,延迟交互模型,例如 ColBERT,效率更高,因为它们可以用于对候选进行重排序,而无需访问集合中的所有文档。
为什么不使用线性组合?
人们经常建议使用全文和向量搜索分数来形成线性组合公式来重新排序结果。所以它是这样的:
final_score = 0.7 * vector_score + 0.3 * full_text_score
然而,我们甚至没有考虑过这样的设置。为什么?这些分数并不能使问题线性可分。我们使用 BM25 分数和余弦向量相似度,将它们都用作 2 维空间中的点坐标。图表显示了这些点的分布情况:
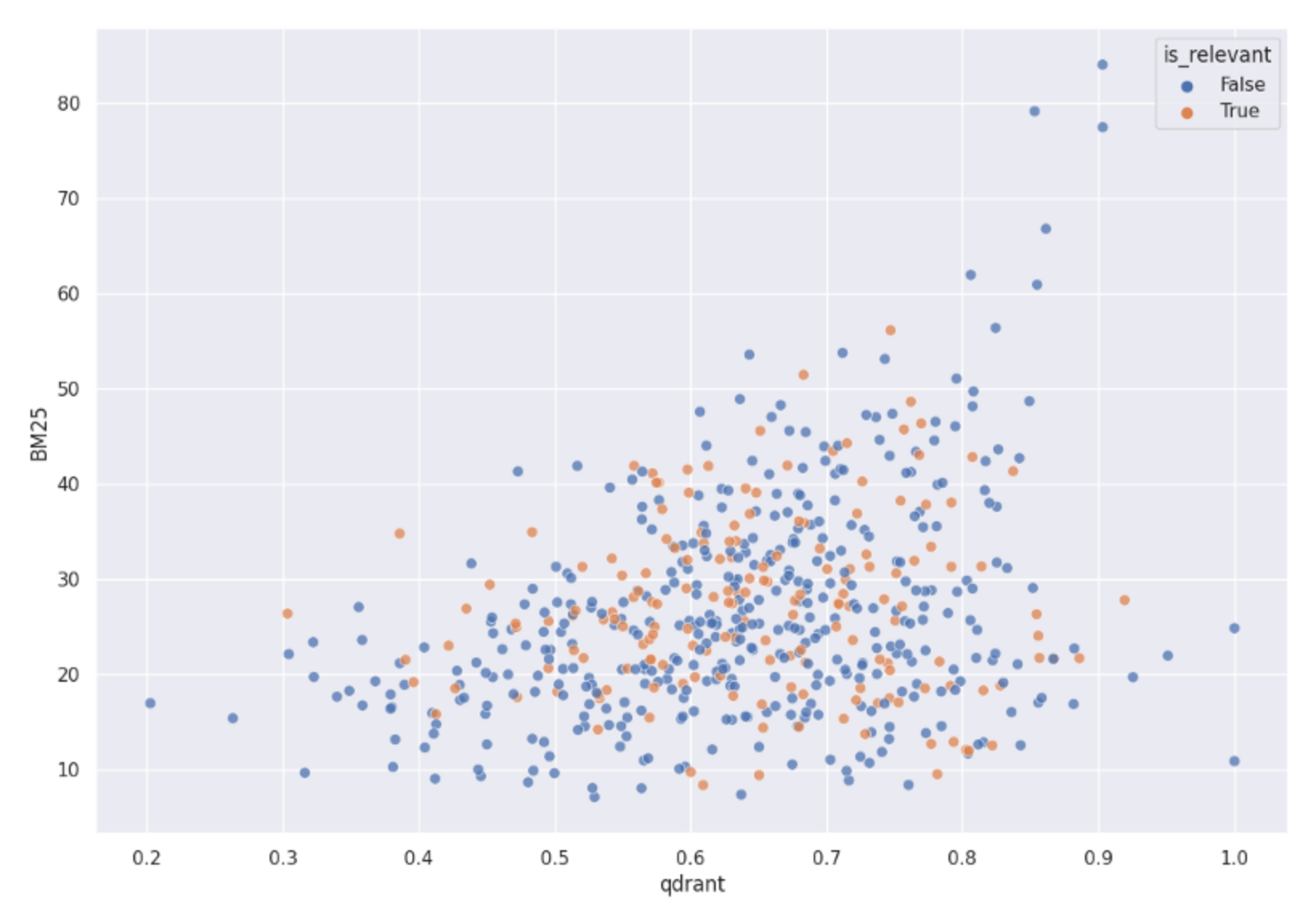
Qdrant 和 BM25 分数在 2D 空间中的分布。它清楚地表明,相关和不相关的对象在该空间中不是线性可分的,因此使用这两个分数的线性组合无法给我们一个适当的混合搜索。
相关和不相关的项目混杂在一起。没有任何线性公式能够区分它们。因此,这不是解决它的方法。
在 Qdrant 中构建混合搜索系统
最终,任何搜索机制也可能是一个重排序机制。你可以使用稀疏向量预取结果,然后使用密集向量对其进行重排序,反之亦然。或者,如果你有套娃嵌入,你可以从使用最低维度的密集向量对候选进行过采样开始,然后通过使用更高维度的嵌入对其进行重排序来逐渐减少候选的数量。没有什么能阻止你结合融合和重排序。
让我们更进一步,构建一个混合搜索机制,它结合了套娃嵌入、密集向量和稀疏向量的结果,然后使用延迟交互模型对其进行重排序。同时,我们将引入额外的重排序和融合步骤。
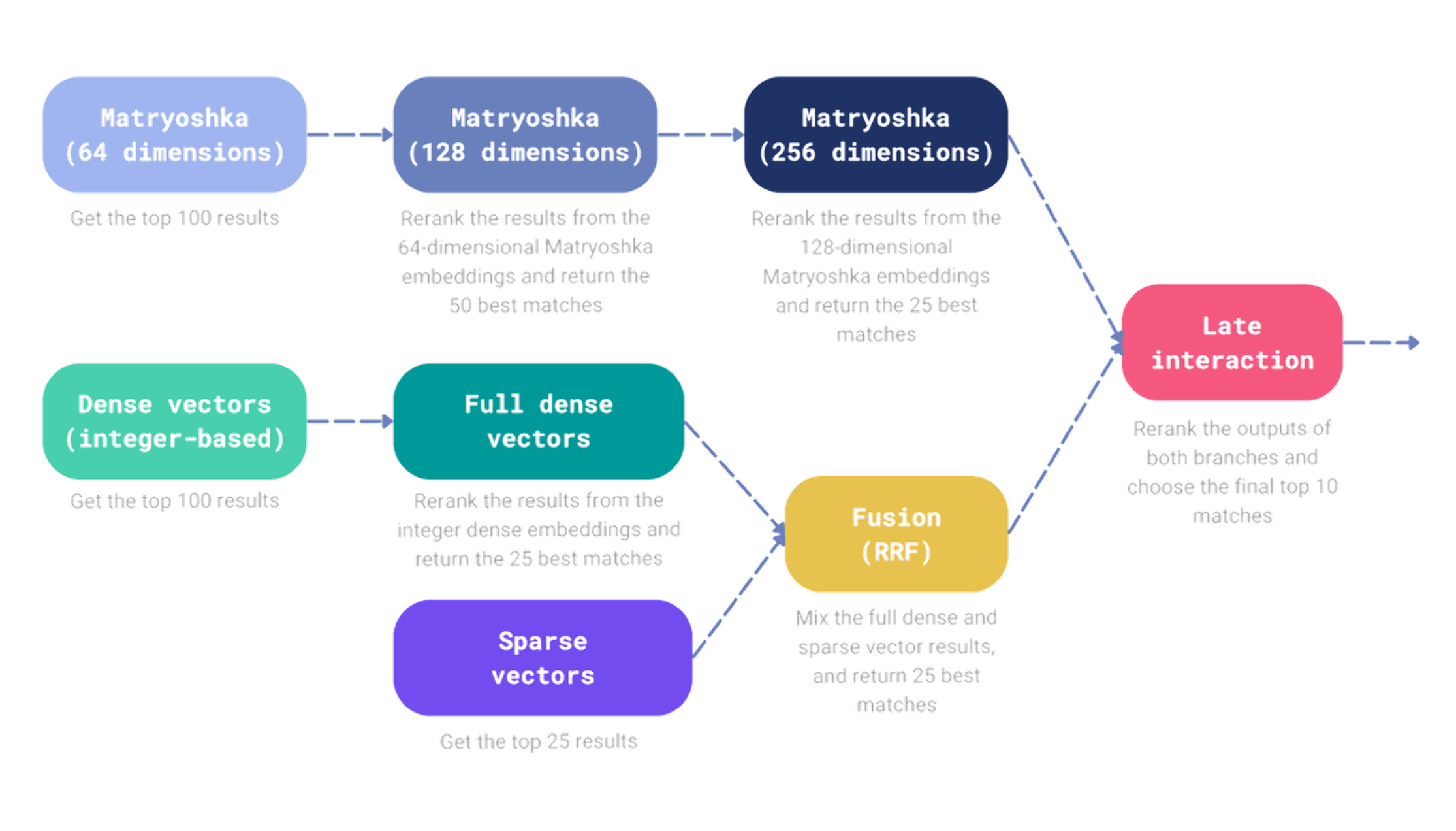
我们的搜索管道由两个分支组成,每个分支负责检索一部分文档,我们最终希望使用延迟交互模型对其进行重排序。让我们首先连接到 Qdrant,然后构建搜索管道。
from qdrant_client import QdrantClient, models
client = QdrantClient("https://:6333")
所有利用套娃嵌入的步骤都可以在查询 API 中指定为嵌套结构:
# The first branch of our search pipeline retrieves 25 documents
# using the Matryoshka embeddings with multistep retrieval.
matryoshka_prefetch = models.Prefetch(
prefetch=[
models.Prefetch(
prefetch=[
# The first prefetch operation retrieves 100 documents
# using the Matryoshka embeddings with the lowest
# dimensionality of 64.
models.Prefetch(
query=[0.456, -0.789, ..., 0.239],
using="matryoshka-64dim",
limit=100,
),
],
# Then, the retrieved documents are re-ranked using the
# Matryoshka embeddings with the dimensionality of 128.
query=[0.456, -0.789, ..., -0.789],
using="matryoshka-128dim",
limit=50,
)
],
# Finally, the results are re-ranked using the Matryoshka
# embeddings with the dimensionality of 256.
query=[0.456, -0.789, ..., 0.123],
using="matryoshka-256dim",
limit=25,
)
同样,我们可以构建搜索管道的第二个分支,它使用密集和稀疏向量检索文档,并使用倒数排序融合方法对它们进行融合:
# The second branch of our search pipeline also retrieves 25 documents,
# but uses the dense and sparse vectors, with their results combined
# using the Reciprocal Rank Fusion.
sparse_dense_rrf_prefetch = models.Prefetch(
prefetch=[
models.Prefetch(
prefetch=[
# The first prefetch operation retrieves 100 documents
# using dense vectors using integer data type. Retrieval
# is faster, but quality is lower.
models.Prefetch(
query=[7, 63, ..., 92],
using="dense-uint8",
limit=100,
)
],
# Integer-based embeddings are then re-ranked using the
# float-based embeddings. Here we just want to retrieve
# 25 documents.
query=[-1.234, 0.762, ..., 1.532],
using="dense",
limit=25,
),
# Here we just add another 25 documents using the sparse
# vectors only.
models.Prefetch(
query=models.SparseVector(
indices=[125, 9325, 58214],
values=[-0.164, 0.229, 0.731],
),
using="sparse",
limit=25,
),
],
# RRF is activated below, so there is no need to specify the
# query vector here, as fusion is done on the scores of the
# retrieved documents.
query=models.FusionQuery(
fusion=models.Fusion.RRF,
),
)
第二个分支可能已经被称为混合分支,因为它结合了密集和稀疏向量的结果以及融合。然而,没有什么能阻止我们构建更复杂的搜索管道。
以下是 Python 中对查询 API 的目标调用示例:
client.query_points(
"my-collection",
prefetch=[
matryoshka_prefetch,
sparse_dense_rrf_prefetch,
],
# Finally rerank the results with the late interaction model. It only
# considers the documents retrieved by all the prefetch operations above.
# Return 10 final results.
query=[
[1.928, -0.654, ..., 0.213],
[-1.197, 0.583, ..., 1.901],
...,
[0.112, -1.473, ..., 1.786],
],
using="late-interaction",
with_payload=False,
limit=10,
)
选项是无限的,新的查询 API 为你提供了尝试不同设置的灵活性。你很少需要构建如此复杂的搜索管道,但很高兴知道你可以在需要时做到这一点。
经验教训:多向量表示
你们许多人已经开始构建混合搜索系统,并向我们提出了问题和反馈。我们看到了许多不同的方法,但一个反复出现的想法是利用多向量表示与 ColBERT 风格模型作为重排序步骤,在通过单向量密集和/或稀疏方法检索候选之后。这反映了该领域的最新趋势,因为单向量方法仍然最有效,但多向量能更好地捕捉文本的细微差别。
假设你从不单独使用延迟交互模型进行检索,而只用于重排序,那么这种设置会带来隐性成本。默认情况下,集合中每个配置的密集向量都将创建一个相应的 HNSW 图。即使它是多向量。
from qdrant_client import QdrantClient, models
client = QdrantClient(...)
client.create_collection(
collection_name="my-collection",
vectors_config={
"dense": models.VectorParams(...),
"late-interaction": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
)
},
sparse_vectors_config={
"sparse": models.SparseVectorParams(...)
},
)
重排序永远不会使用创建的图,因为所有候选都已检索到。多向量排序只会应用于前一步骤检索到的候选,因此不需要搜索操作。HNSW 变得多余,而索引过程仍然必须执行,在这种情况下,它会非常繁重。ColBERT 类似模型为每个文档创建数百个嵌入,因此开销很大。为避免这种情况,你可以为这种模型禁用 HNSW 图的创建:
client.create_collection(
collection_name="my-collection",
vectors_config={
"dense": models.VectorParams(...),
"late-interaction": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
hnsw_config=models.HnswConfigDiff(
m=0, # Disable HNSW graph creation
),
)
},
sparse_vectors_config={
"sparse": models.SparseVectorParams(...)
},
)
你不会注意到搜索性能有任何差异,但当你将嵌入上传到集合时,资源使用量将显著降低。
一些轶事观察
两种算法都不是在所有情况下都表现最佳。在某些情况下,基于关键词的搜索会获胜,反之亦然。下表显示了我们在实验期间在 WANDS 数据集中发现的一些有趣的例子:
| 查询 | BM25 搜索 | 向量搜索 |
|---|---|---|
| cybersport desk | desk ❌ | gaming desk ✅ |
| plates for icecream | "eat" plates on wood wall décor ❌ | alicyn 8.5 '' melamine dessert plate ✅ |
| kitchen table with a thick board | craft kitchen acacia wood cutting board ❌ | industrial solid wood dining table ✅ |
| wooden bedside table | 30 '' bedside table lamp ❌ | portable bedside end table ✅ |
还有一些基于关键词的搜索表现更好的例子
| 查询 | BM25 搜索 | 向量搜索 |
|---|---|---|
| computer chair | vibrant computer task chair ✅ | office chair ❌ |
| 64.2 inch console table | cervantez 64.2 '' console table ✅ | 69.5 '' console table ❌ |
尝试 Qdrant 1.10 中的新查询 API
Qdrant 1.10 中引入的新查询 API 是构建混合搜索系统的游戏规则改变者。你不需要任何额外的服务来组合来自不同搜索方法的结果,你甚至可以创建更复杂的管道并直接从 Qdrant 提供它们。
我们关于《构建终极混合搜索》的网络研讨会带你了解使用 Qdrant 查询 API 构建混合搜索系统的过程。如果你错过了,可以观看录像,或查看笔记。
如果你在构建混合搜索系统时有任何问题或需要帮助,请随时在 Discord 上联系我们。