
批量上传期间的内存消耗优化
在处理大规模向量数据时,高效的内存管理是一个持续的挑战。在高吞吐量摄取场景中,即使看似微小的配置选择也可能显著影响稳定性和性能。
让我们来看看最佳实践和建议,以帮助您在Qdrant中批量上传期间优化内存使用。我们将涵盖密集和稀疏向量的场景,帮助您的部署即使在高负载下也能保持高性能,并避免内存不足错误。
密集向量与稀疏向量的索引
密集向量
Qdrant采用基于HNSW的索引,用于对密集向量进行快速相似性搜索。默认情况下,当段中未索引向量的数量超过设定的indexing_threshold时,HNSW将被构建或更新。尽管它提供了出色的查询速度,但如果HNSW图频繁或跨许多小段构建或更新,可能会消耗大量资源。
稀疏向量
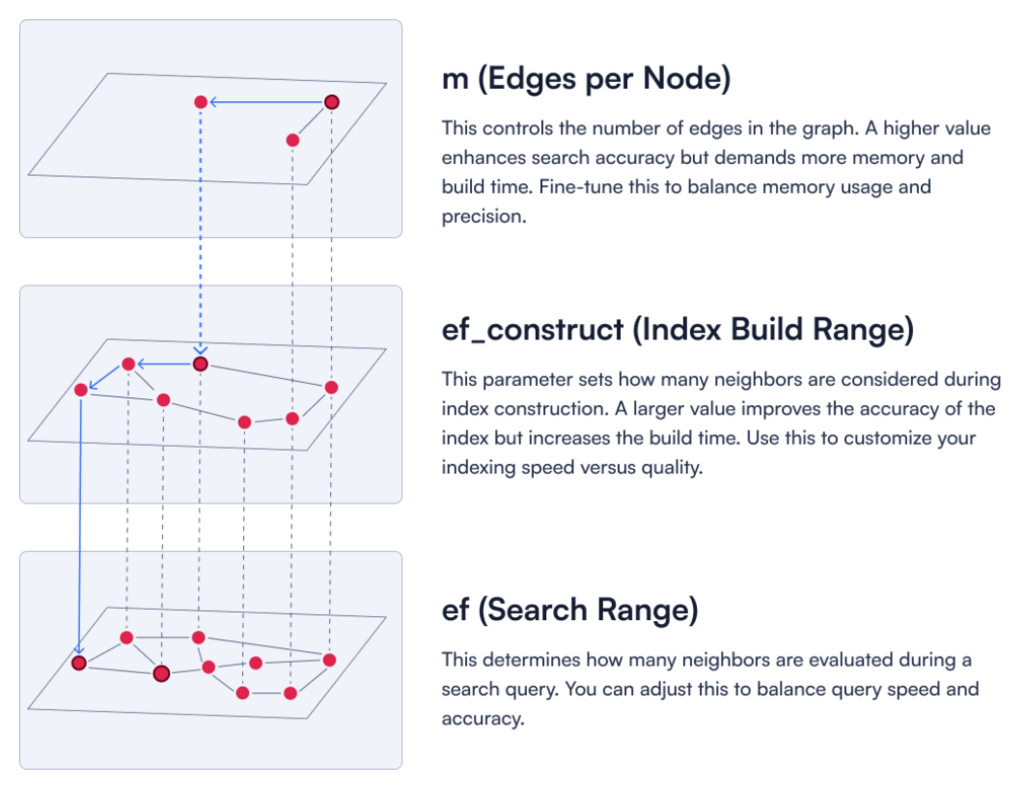
稀疏向量使用倒排索引。此索引在upsertion时更新,这意味着您不能禁用或推迟稀疏向量的索引。在大多数情况下,其开销小于构建HNSW图的开销,但您仍应注意每次upsert都会触发稀疏索引更新。
密集向量的批量上传配置
在执行大批量向量摄取时,您有两种主要选择来处理索引开销。您应该根据您的特定工作负载和内存限制进行选择。
- 禁用HNSW索引
为了在批量摄取期间减少内存和CPU压力,您可以通过设置"m": 0来完全禁用HNSW索引。对于密集向量,m参数定义了HNSW图中每个节点可以有多少条边。这样,将不会构建密集向量索引,从而避免摄取期间不必要的CPU使用。
图1:三个关键HNSW参数的描述。
PATCH /collections/your_collection
{
"hnsw_config": {
"m": 0
}
}
摄取完成后,您可以通过将m设置回生产值(通常为16或32)来重新启用HNSW。请记住,在索引构建完成之前,搜索不会使用HNSW,因此在此期间搜索性能可能会较慢。
- 完全禁用优化
indexing_threshold告诉Qdrant在构建HNSW图之前,一个段中可以累积多少个未索引的密集向量。设置"indexing_threshold"=0会完全推迟索引,从而使摄取速度达到最大。然而,这意味着上传的向量在上传时不会移动到磁盘,这可能导致高RAM使用率。
PATCH /collections/your_collection
{
"optimizer_config": {
"indexing_threshold": 0
}
}
批量摄取后,将indexing_threshold设置为正值,以确保向量通过HNSW进行索引和搜索。在执行索引之前,向量将无法通过HNSW进行搜索。
小阈值(例如100)意味着更频繁的索引,如果存在许多段,这仍然可能代价高昂。大阈值(例如10000)会延迟索引,以便一次性批量处理更多向量,这可能会在索引构建时使用更多RAM,但总体构建次数会减少。
在这两种方法之间,我们通常建议在批量摄取期间禁用HNSW("m"=0),以保持内存使用的可预测性。使用indexing_threshold=0可以作为替代方案,但前提是您的系统有足够的内存来容纳RAM中的未索引向量。
Qdrant中的磁盘存储
默认情况下,Qdrant将向量、payload数据和索引保留在内存中,以确保低延迟查询。然而,在大规模或内存受限的场景中,您可以配置将其中部分或全部存储在磁盘上。这有助于减少RAM使用,但代价是查询延迟可能增加,特别是对于冷读取。
何时使用磁盘存储:
- 您有非常大或很少使用的payload数据或索引,并且释放RAM值得潜在的I/O开销。
- 您的数据集无法舒适地适应可用内存。
- 您想要减少内存压力。
- 如果您能容忍较慢的查询,以确保系统在重负载下保持稳定。
内存映射存储和分段
Qdrant使用内存映射文件(段)将数据存储在磁盘上。Qdrant不是将所有向量加载到RAM中,而是将每个段映射到其地址空间中,按需分页进出数据。这有助于保持较低的活动RAM占用,因为如果内存压力很高,数据可以分页出去。但每个段仍然会产生开销(元数据、页表条目等)。
在大批量摄取期间,您可能会累积数十个小段。Qdrant的优化器稍后可以将这些小段合并为更少、更大的段,从而减少每段开销并降低总内存使用量。
当您使用"on_disk": true创建集合时,Qdrant将从一开始就将新插入的向量存储在内存映射存储中。例如:
PATCH /collections/your_collection
{
"vectors": {
"on_disk": true
}
}
这种方法立即将所有传入的向量放置到磁盘上,这在批量摄取的情况下非常高效。
然而,向量数据和索引是分开存储的,因此为向量启用on_disk并不会自动将它们的索引存储在磁盘上。要完全优化内存使用,您可能需要独立配置向量存储和索引存储。
对于密集向量,您可以同时为向量数据和HNSW索引启用磁盘存储。
PATCH /collections/your_collection
{
"vectors": {
"on_disk": true
},
"hnsw_config": {
"on_disk": true
}
}
对于稀疏向量,您需要分别为向量数据和稀疏索引启用on_disk。
PATCH /collections/your_collection
{
"sparse_vectors": {
"text": {
"on_disk": true,
"index": {
"on_disk": true
}
}
}
}
大批量向量摄取的最佳实践
批量摄取可能导致高内存消耗,甚至内存不足(OOM)错误。如果您当前的设置正在经历内存不足错误,暂时扩展(增加可用RAM)将提供一个缓冲,同时您调整Qdrant的配置以实现更高效的数据摄取。
这里的关键是控制索引开销。让我们来看看在内存受限环境中进行大批量向量摄取的最佳实践。
1. 立即将向量数据存储到磁盘
减少内存使用最有效的方法是使用on_disk: true从一开始就将向量数据存储到磁盘。这可以防止RAM在优化启动之前被原始向量过载。
PATCH /collections/your_collection
{
"vectors": {
"on_disk": true
}
}
以前,向量数据必须保存在RAM中,直到优化器可以将其移动到磁盘,这导致了显著的内存压力。现在,通过直接将向量写入磁盘,内存开销显著减少,使批量摄取更加高效。
2. 禁用密集向量的HNSW(m=0)
在初始批量加载期间,您可以通过设置"m": 0来禁用密集索引。这确保Qdrant不会为传入的向量构建HNSW图,从而避免不必要的内存和CPU使用。
PATCH /collections/your_collection
{
"hnsw_config": {
"m": 0
},
"optimizer_config": {
"indexing_threshold": 10000
}
}
3. 在批量上传之后运行优化器
Qdrant的优化器不断重构数据以提高搜索效率。然而,在批量上传期间,由于新数据仍在到达,段不断重组,这可能导致过多的数据移动和开销。
为了避免这种情况,首先上传所有数据,然后允许优化器一次性处理所有内容。这可以最大限度地减少冗余操作并确保更高效的段结构。
4. 等待索引清理内存
在执行其他操作之前,允许Qdrant完成任何正在进行的索引。大型索引作业可能会使内存使用量保持很高,直到它们完全完成。
监控Qdrant日志或指标以确认索引何时完成——一旦完成,随着中间数据结构的释放,内存消耗应该会下降。
5. 摄取后重新启用HNSW
摄取阶段结束后,内存使用量稳定下来后,通过将m设置回生产值(通常为16或32)来重新启用密集向量的HNSW。
PATCH /collections/your_collection
{
"hnsw_config": {
"m": 16
}
}
5. 启用量化
如果您计划将所有密集向量存储在磁盘上,请注意,由于内存压力高时频繁的磁盘I/O,搜索可能会急剧减慢。一种更平衡的方法是标量量化:压缩向量(例如,压缩为int8),以便它们可以适应RAM,而不会占用与完整浮点值一样多的空间。
PATCH /collections/your_collection
{
"quantization_config": {
"scalar": {
"type": "int8",
"always_ram": true
}
}
}
量化向量保持内存中,但占用空间更少,保留了基于RAM搜索的大部分性能优势。了解更多关于向量量化的信息。
结论
大批量向量摄取可能对Qdrant施加显著的内存需求,特别是如果密集向量是实时索引的。通过遵循这些提示,您可以大大降低内存不足错误的风险,并在内存受限的环境中保持稳定的性能。
一如既往,监控您的系统行为。查看日志,观察指标,并密切关注内存使用情况。每个工作负载都不同,因此根据您的硬件和数据规模微调Qdrant的参数是明智之举。