
通过 Qdrant 1.3.0 版本,我们为基于 Linux 的系统引入了基于 io_uring 的替代性异步 uring 存储后端。自引入以来,io_uring 已知在操作系统系统调用开销过高时能提高异步吞吐量,这通常发生在软件变得 IO 密集型(即主要等待磁盘)的情况下。
输入+输出
大约在90年代中期,互联网开始兴起。最初的服务器采用每请求一个进程的设置,这对于处理成百上千的并发请求来说是很好的。POSIX 输入+输出(IO)以严格同步的方式建模。为每个请求启动一个新进程的开销使得这种模型不可持续。因此,服务器开始放弃进程隔离,转而采用每请求一个线程的模型。但即使是这种模型也遇到了限制。
我清楚地记得,有人问服务器是否能处理1万个并发连接,这在当时会耗尽大多数系统的内存(因为每个线程都必须有自己的栈和其他一些元数据,这很快就会填满可用内存)。结果,同步 IO 在 2.5 内核更新期间被异步 IO 取代,通过 select 或 epoll(后者仅限于 Linux,但效率稍高,因此当时大多数服务器都使用它)。
然而,即使是这种粗略形式的异步 IO,每次操作也至少带来一次系统调用的开销。每次系统调用都会导致一次上下文切换,虽然这个操作本身并不慢,但切换会扰乱缓存。今天的 CPU 比内存快得多,但如果它们的缓存开始丢失数据,所需的内存访问会导致 CPU 等待时间越来越长。
内存映射IO
处理文件 IO 的另一种方式(与网络 IO 不同,文件 IO 没有严格的时间要求)是将文件的一部分映射到内存中——系统伪装成将文件的该部分加载到内存中,因此当你从那里读取数据时,内核会中断你的进程以从磁盘加载所需数据,并在完成后恢复你的进程;而写入内存也会通知内核。此外,内核可以在程序运行时预取数据,从而减少中断的可能性。
因此仍然存在一些开销,但(尤其是在异步应用程序中)它远低于使用 epoll。这个 API 很少用于 Web 服务器的原因是,Web 服务器通常需要访问多种多样的文件,这与数据库不同,数据库可以一次将其自身的后端存储映射到内存中。
对抗“轮询”污染
有许多实验来改进情况,有些甚至将 HTTP 服务器移入内核,这当然也带来了它自身的问题。其他像英特尔则添加了自己的 API,这些 API 忽略内核并直接在硬件上工作。
最终,Jens Axboe 亲自动手,提出了一种基于环形缓冲区的接口,称为 io_uring。缓冲区不是直接用于数据,而是用于操作。用户进程可以设置一个提交队列(SQ)和一个完成队列(CQ),这两个队列在进程和内核之间共享,因此没有复制开销。
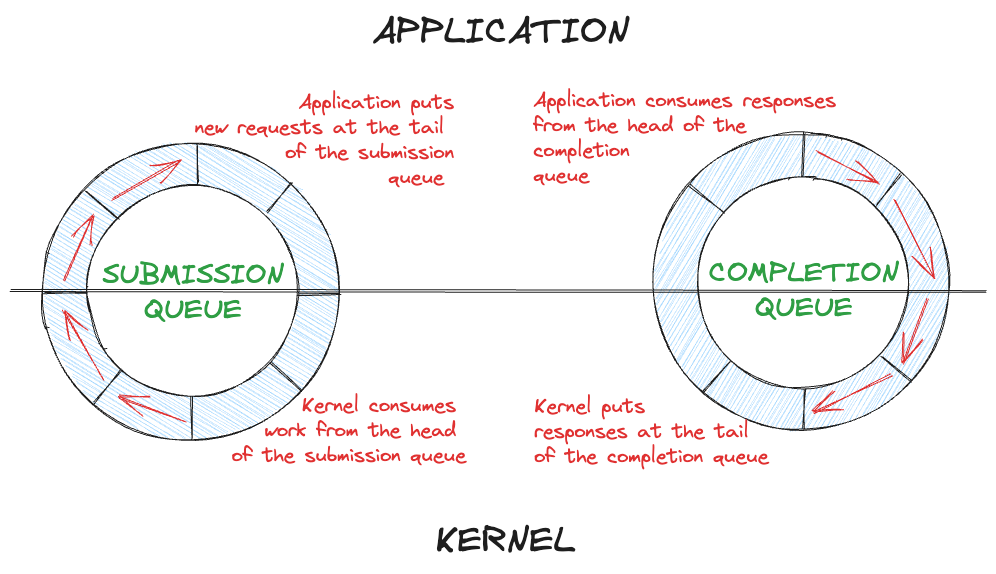
除了避免复制开销,基于队列的架构也适用于多线程,因为项目的插入/提取可以做到无锁,一旦队列设置完成,就不会有进一步的系统调用来停止任何用户线程。
使用此技术的服务器可以轻松达到超过10万个并发请求。如今,Linux 允许通过 io_uring 进行网络、磁盘和其他端口的异步 IO,例如用于打印或录制视频。
Qdrant又如何呢?
Qdrant 可以将所有数据存储在内存中,但并非所有数据集都能容纳,这可能需要存储在磁盘上。在 io_uring 之前,Qdrant 使用 mmap 进行 IO。这在磁盘延迟的情况下导致了一些适度的开销。内核可能会停止尝试访问映射区域的用户线程,这会产生一些上下文切换开销,加上等待磁盘 IO 完成的时间。最终,这与 Qdrant 核心的异步特性配合得非常好。
Qdrant 提供的一项重要优化是量化(无论是标量还是产品量化)。然而,除非集合完全驻留在内存中,否则这种优化方法会产生大量的磁盘 IO,因此它是可能改进的首要候选。
如果您在 Linux 上运行 Qdrant,您可以在配置中通过以下方式启用 io_uring
# within the storage config
storage:
# enable the async scorer which uses io_uring
async_scorer: true
您可以通过删除 async_scorer 条目或将值设置为 false 来返回到基于 mmap 的后端。
基准测试
要运行基准测试,请使用 Qdrant 的测试实例。如有必要,启动一个 Docker 容器并加载您想要进行基准测试的集合快照。您可以复制和编辑我们的基准测试脚本来运行基准测试。在启用和不启用 storage.async_scorer 的情况下各运行一次脚本。您可以使用另一个控制台中的 iostat 测量 IO 使用情况。
对于我们的基准测试,我们选择了 laion 数据集,选取了500万个768维条目。我们启用了标量量化 + HNSW,m=16 和 ef_construct=512。我们在 RAM 中进行量化,HNSW 在 RAM 中,但原始向量保留在磁盘上(这是一个从 Hetzner 租用的网络驱动器,用于基准测试)。
如果您想复现这些基准测试,可以获取包含数据集的快照
运行基准测试,我们得到以下 IOPS、CPU 负载和实际耗时
| 过采样 | 并行 | ~最大 IOPS | CPU% (4 核) | 时间 (秒) (3 次平均) | |
|---|---|---|---|---|---|
| io_uring | 1 | 4 | 4000 | 200 | 12 |
| mmap | 1 | 4 | 2000 | 93 | 43 |
| io_uring | 1 | 8 | 4000 | 200 | 12 |
| mmap | 1 | 8 | 2000 | 90 | 43 |
| io_uring | 4 | 8 | 7000 | 100 | 30 |
| mmap | 4 | 8 | 2300 | 50 | 145 |
请注意,在这种情况下,由于使用了网络磁盘,IO 操作的延迟相对较高。因此,内核需要更多时间来满足 mmap 请求,应用程序线程需要等待,这反映在 CPU 百分比中。另一方面,使用 io_uring 后端,应用程序线程可以更好地利用可用核心进行重新评分操作,而不会出现任何 IO 引起的延迟。
过采样是一项新功能,旨在以牺牲部分性能为代价来提高准确性。它允许设置一个因子,在搜索时将其乘以 limit。然后使用原始向量重新评分结果,之后才选择达到限制的顶部结果。
讨论
回想过去,磁盘 IO 曾经是非常串行化的;在移动盘片上重新定位读写头是一项缓慢而繁琐的工作。因此系统开销并不那么重要,但如今有了固态硬盘,它们通常甚至可以并行操作,同时提供近乎完美的随机访问,开销开始变得相当明显。虽然内存映射 IO 在易用性和性能方面为我们提供了相当大的便利,但我们可以通过增加一些适度的复杂性来提高后者。
io_uring 仍然相当年轻,仅在 2019 年随内核 5.1 引入,因此一些管理员会警惕引入它。当然,就像性能一样,正确的答案通常是“视情况而定”,所以请审查您的个人风险状况并采取相应行动。
最佳实践
如果您的磁盘集合的查询性能对您来说优先级足够高,请启用基于 io_uring 的 async_scorer,以大幅减少磁盘 IO 带来的操作系统开销。另一方面,如果您的集合仅存在于内存中,激活它将无效。另请注意,许多查询并非 IO 密集型,因此开销在您的工作负载中可能无法被测量到。最后,设备上的磁盘通常比网络驱动器具有更低的延迟,这也可能影响 mmap 的开销。
因此,在您推出 io_uring 之前,请使用 mmap 和 io_uring 执行上述或类似的基准测试,并测量实际运行时间 (wall time) 和 IOps。基准测试总是高度依赖用例,因此您的结果可能会有所不同。尽管如此,进行一次这样的基准测试,对于可能获得的性能提升来说,代价是很小的。另外,请告诉我们您的基准测试结果!