
* 至少是任何开源模型,因为你需要访问其内部结构。
你可以调整密集嵌入模型以进行后期交互
Qdrant 1.10 引入了对多向量表示的支持,其中后期交互是这种模型的一个突出示例。本质上,文档和查询都由多个向量表示,识别最相关的文档涉及根据相应查询和文档嵌入之间的相似性计算得分。如果你不熟悉这种范式,我们更新的混合搜索文章解释了多向量表示如何提高检索质量。
图1:我们可以可视化相应文档-查询嵌入对之间的后期交互。
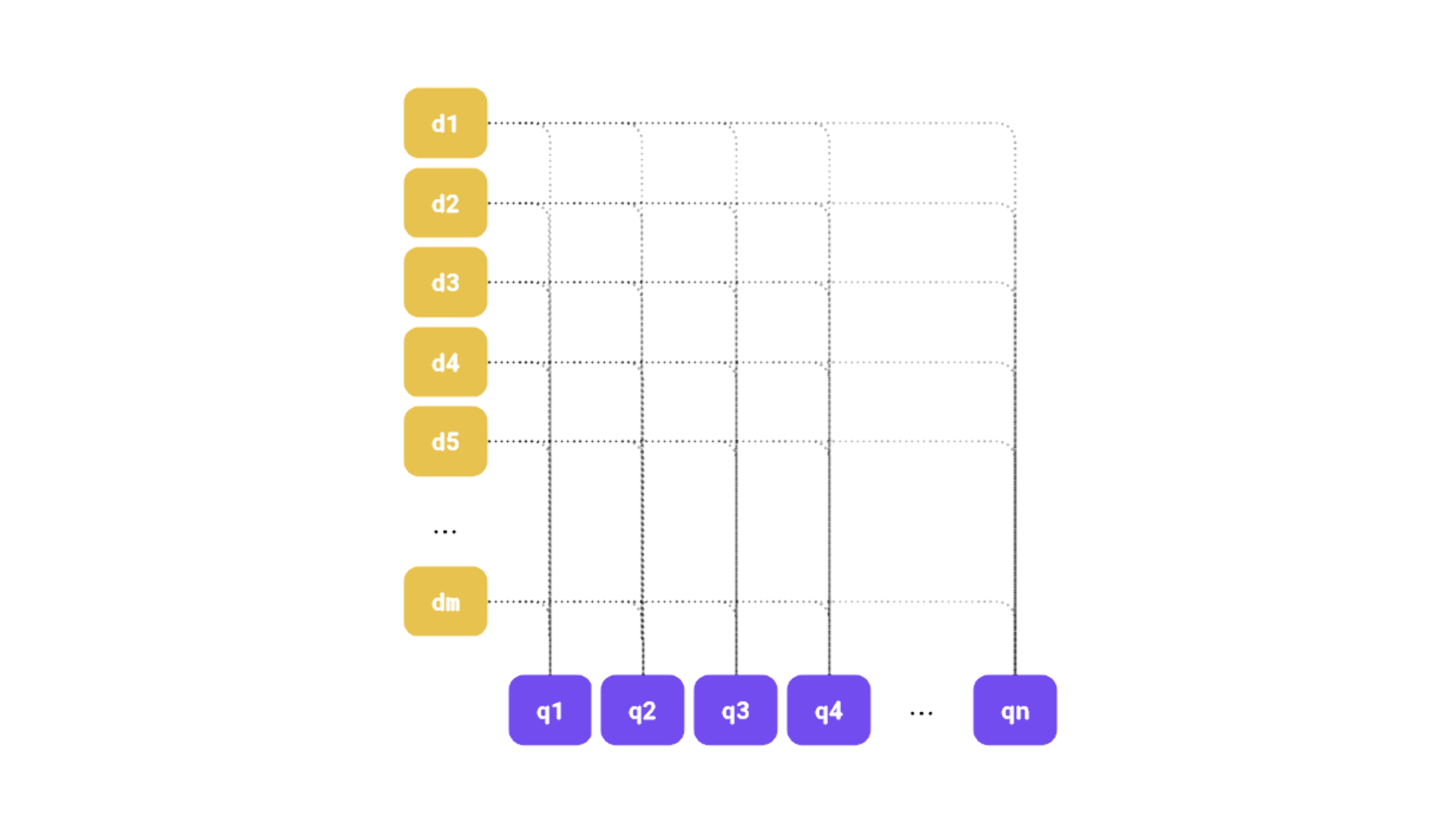
有许多专门的后期交互模型,例如ColBERT,但似乎常规的密集嵌入模型也可以通过这种方式有效利用。
在本研究中,我们将证明传统上用于单向量表示的标准密集嵌入模型,可以使用输出词元嵌入作为多向量表示,有效地适应后期交互场景。
通过测试Qdrant的多向量功能检索,我们将展示这些模型在检索性能上可以媲美甚至超越专门的后期交互模型,同时具有更低的复杂性和更高的效率。这项工作重新定义了密集模型在高级搜索管道中的潜力,提出了一种优化检索系统的新方法。
理解嵌入模型
嵌入模型的内部工作原理可能会让一些人感到惊讶。模型不直接操作输入文本;相反,它需要一个词元化步骤将文本转换为词元标识符序列。然后,每个词元标识符通过一个嵌入层,将其转换为密集向量。本质上,嵌入层充当一个查找表,将词元标识符映射到密集向量。这些向量然后作为输入馈送到Transformer模型中。
图2:在向量添加到Transformer模型之前发生的词元化步骤。
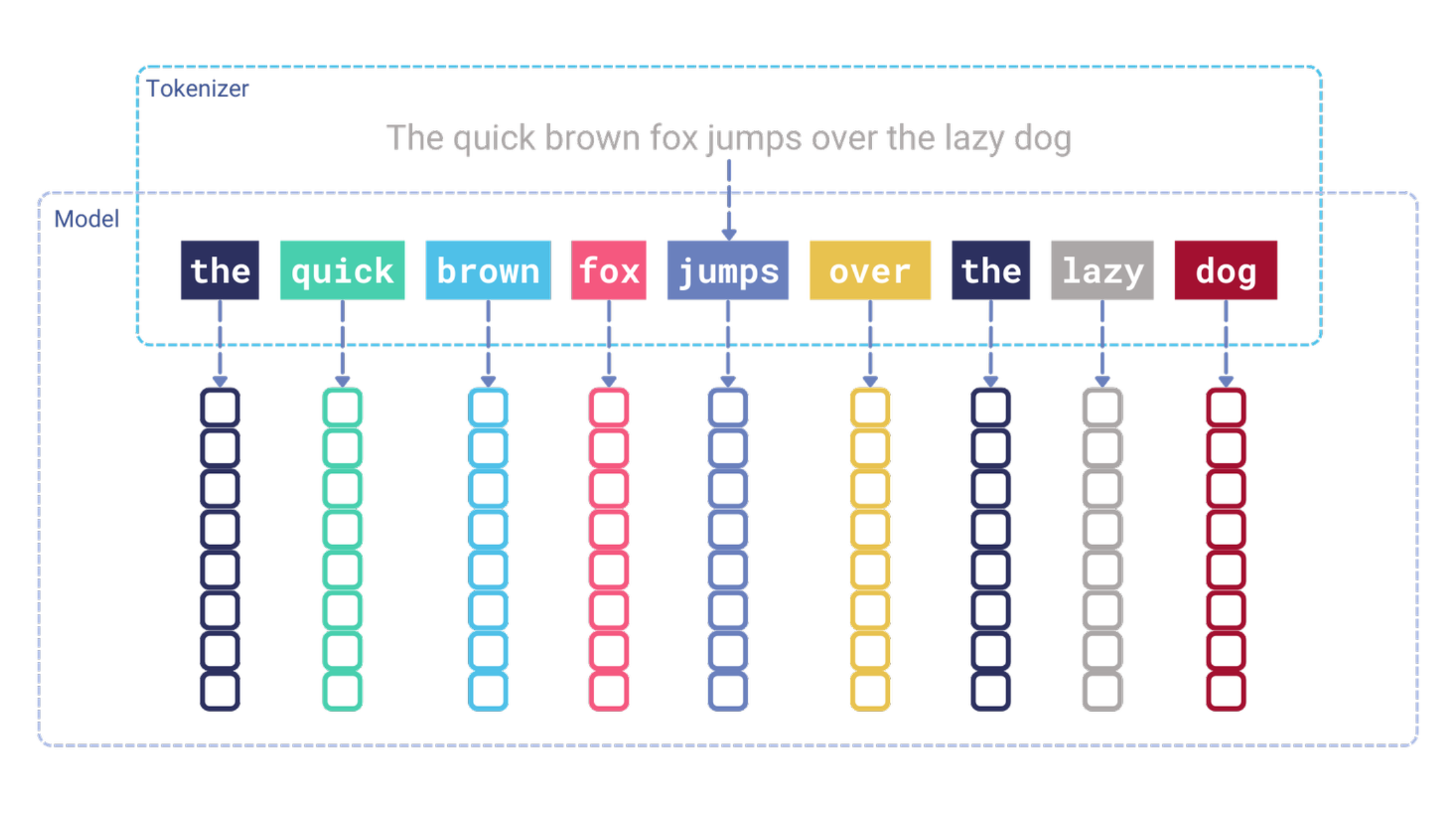
输入词元嵌入是无上下文的,并在模型训练过程中学习。这意味着每个词元总是接收相同的嵌入,无论其在文本中的位置如何。在此阶段,词元嵌入不了解它们出现的上下文。Transformer模型的作用是使这些嵌入语境化。
关于Transformer模型中注意力的作用已经讨论了很多,但本质上,这种机制负责捕捉跨词元关系。每个Transformer模块都接收一个词元嵌入序列作为输入,并生成一个输出词元嵌入序列。两个序列的长度相同,每个词元嵌入都通过当前步骤中其他词元嵌入的信息得到丰富。
图3:生成输出词元嵌入序列的机制。
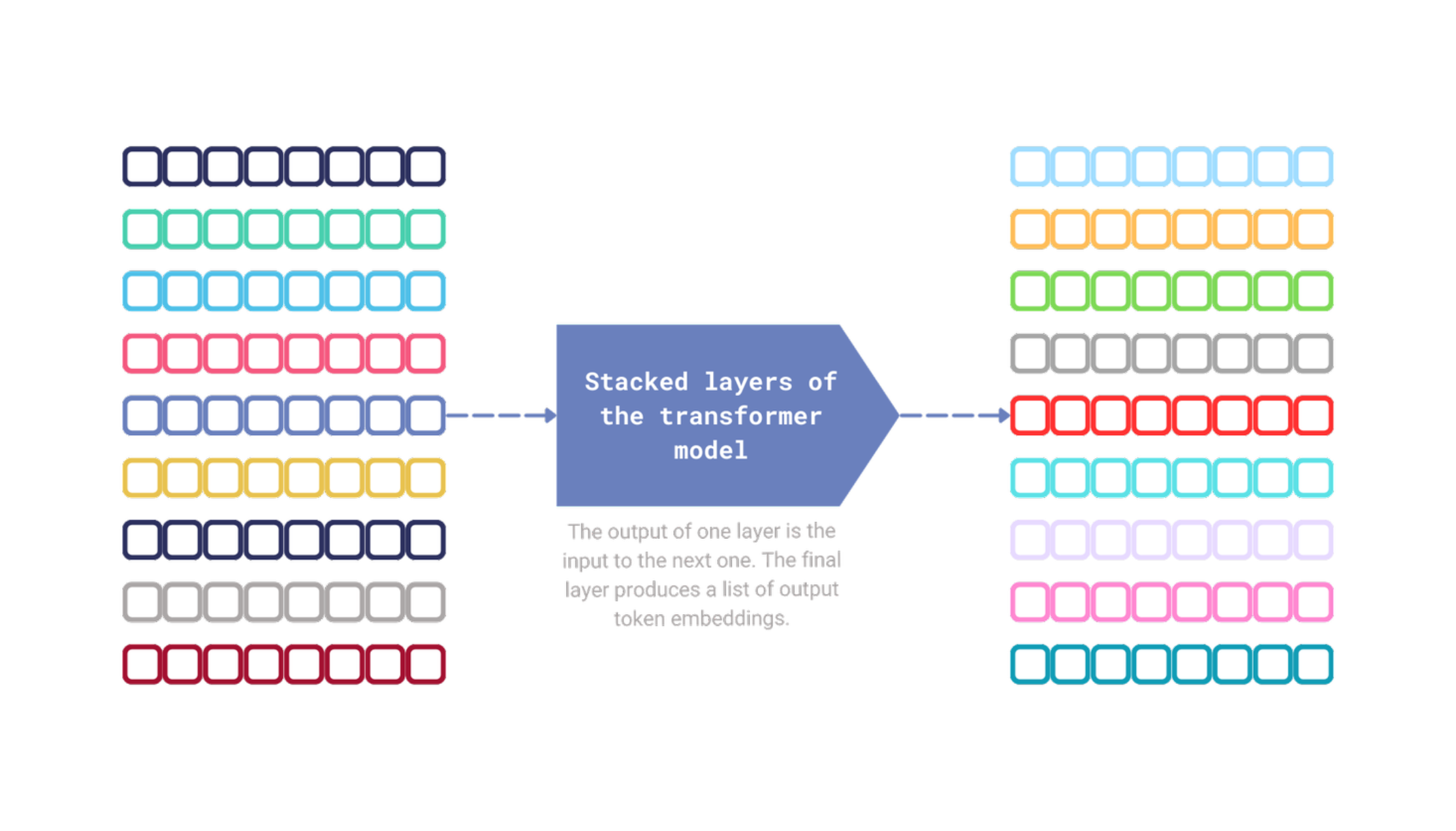
图4:嵌入模型执行的最后一步是池化输出词元嵌入,以生成输入文本的单个向量表示。
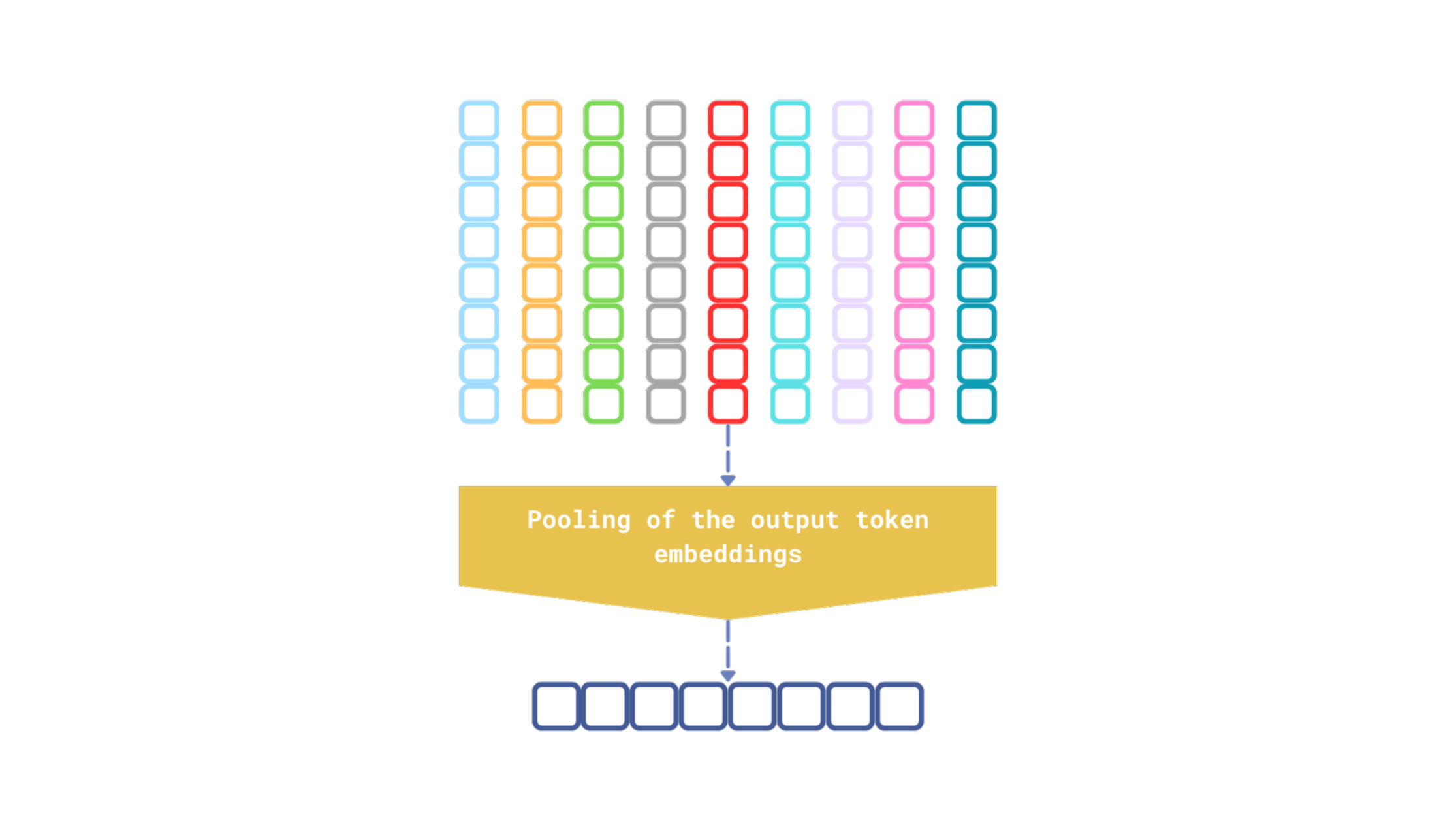
有几种池化策略,但无论模型使用哪种策略,输出始终是单个向量表示,这不可避免地会丢失一些关于输入的信息。这类似于向某人提供前往最近杂货店的详细分步说明,而不是简单地指向大致方向。虽然模糊的方向在某些情况下可能足够,但详细的说明更有可能带来预期的结果。
使用输出词元嵌入进行多向量表示
我们经常忽略输出词元嵌入,但事实是——它们也作为输入文本的多向量表示。那么,为什么不在类似于后期交互模型的多向量检索模型中探索它们的使用呢?
实验结果
我们进行了几次实验,以确定输出词元嵌入是否可以有效地替代传统的后期交互模型。结果非常有前景。
| 数据集 | 模型 | 实验 | NDCG@10 |
|---|---|---|---|
| SciFact | prithivida/Splade_PP_en_v1 | 稀疏向量 | 0.70928 |
colbert-ir/colbertv2.0 | 后期交互模型 | 0.69579 | |
all-MiniLM-L6-v2 | 单一密集向量表示 | 0.64508 | |
| 输出词元嵌入 | 0.70724 | ||
BAAI/bge-small-en | 单一密集向量表示 | 0.68213 | |
| 输出词元嵌入 | 0.73696 | ||
| NFCorpus | prithivida/Splade_PP_en_v1 | 稀疏向量 | 0.34166 |
colbert-ir/colbertv2.0 | 后期交互模型 | 0.35036 | |
all-MiniLM-L6-v2 | 单一密集向量表示 | 0.31594 | |
| 输出词元嵌入 | 0.35779 | ||
BAAI/bge-small-en | 单一密集向量表示 | 0.29696 | |
| 输出词元嵌入 | 0.37502 | ||
| ArguAna | prithivida/Splade_PP_en_v1 | 稀疏向量 | 0.47271 |
colbert-ir/colbertv2.0 | 后期交互模型 | 0.44534 | |
all-MiniLM-L6-v2 | 单一密集向量表示 | 0.50167 | |
| 输出词元嵌入 | 0.45997 | ||
BAAI/bge-small-en | 单一密集向量表示 | 0.58857 | |
| 输出词元嵌入 | 0.57648 | ||
这些实验的源代码是开源的,并利用了beir-qdrant,它是Qdrant与BeIR库的集成。虽然这个包并非由Qdrant团队官方维护,但对于那些有兴趣试验各种Qdrant配置以了解它们如何影响检索质量的人来说,它可能会非常有用。所有实验均使用Qdrant在精确搜索模式下进行,确保结果不受近似搜索的影响。
即使是简单的all-MiniLM-L6-v2模型也可以以后期交互模型的方式应用,从而对检索质量产生积极影响。然而,最佳结果是通过BAAI/bge-small-en模型实现的,它超越了稀疏模型和后期交互模型。
值得注意的是,ColBERT尚未在BeIR数据集上进行训练,这使其性能完全超出领域。尽管如此,all-MiniLM-L6-v2的训练数据集也缺乏任何BeIR数据,但它仍然表现出色。
密集模型与后期交互模型的比较分析
检索质量不言而喻,但还有其他重要因素需要考虑。
我们测试的传统密集嵌入模型比后期交互或稀疏模型更不复杂。参数更少,这些模型在推理期间预计会更快,维护成本也更低。下面是实验中使用的模型比较
| 模型 | 参数数量 |
|---|---|
prithivida/Splade_PP_en_v1 | 109,514,298 |
colbert-ir/colbertv2.0 | 109,580,544 |
BAAI/bge-small-en | 33,360,000 |
all-MiniLM-L6-v2 | 22,713,216 |
反对使用输出词元嵌入的一个论点是与ColBERT类模型相比,存储需求增加。例如,all-MiniLM-L6-v2模型生成384维的输出词元嵌入,这是ColBERT类模型生成的128维嵌入的三倍。这种增加不仅导致更高的内存使用量,还影响检索的计算成本,因为计算距离需要更多时间。通过向量压缩来缓解这个问题将非常有意义。
探索多向量表示的量化
二进制量化通常对高维向量更有效,这使得all-MiniLM-L6-v2模型因其相对低维的输出而不太适合这种方法。然而,标量量化似乎是一个可行的替代方案。下表总结了量化对检索质量的影响。
| 数据集 | 模型 | 实验 | NDCG@10 |
|---|---|---|---|
| SciFact | all-MiniLM-L6-v2 | 输出词元嵌入 | 0.70724 |
| 输出词元嵌入 (uint8) | 0.70297 | ||
| NFCorpus | all-MiniLM-L6-v2 | 输出词元嵌入 | 0.35779 |
| 输出词元嵌入 (uint8) | 0.35572 | ||
需要注意的是,量化并不总能保持相同的检索质量,但在本例中,标量量化似乎对检索性能影响最小。效果可以忽略不计,而内存节省则相当可观。
我们设法在内存使用减少四倍的情况下保持了原始质量。此外,量化向量需要384字节,而ColBERT需要512字节。这使得内存使用减少了25%,同时检索质量几乎保持不变。
实际应用:使用密集模型增强检索
如果你正在使用某个句子Transformer模型,默认情况下会计算输出词元嵌入。虽然单一向量表示在存储和计算方面效率更高,但无需丢弃输出词元嵌入。根据我们的实验,这些嵌入可以显著提高检索质量。你可以在Qdrant中同时存储单一向量和输出词元嵌入,使用单一向量进行初始检索步骤,然后使用输出词元嵌入对结果进行重新排序。
图5:一个仅依赖输出词元嵌入进行重新排序的单一模型管道。
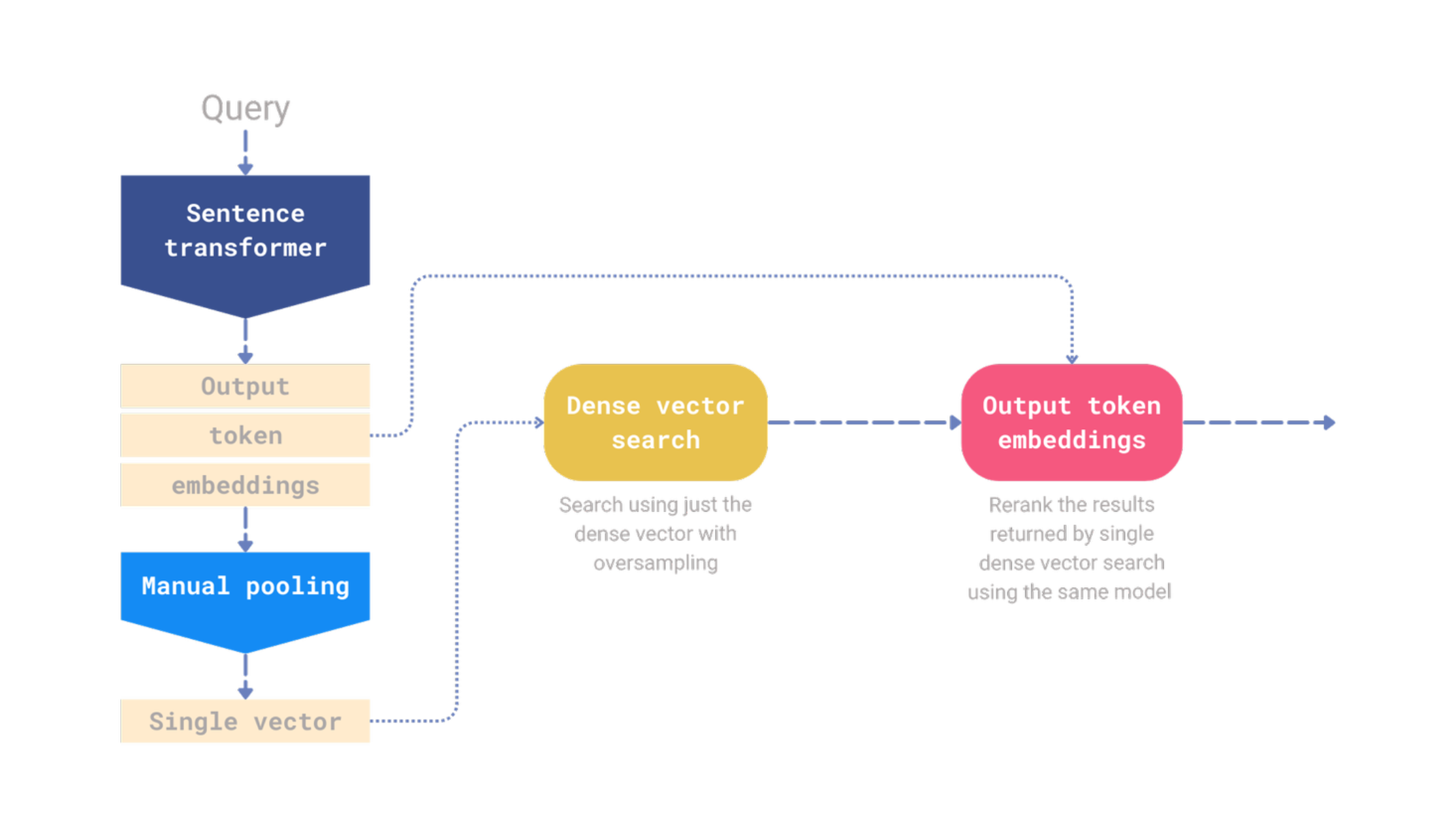
为了演示这个概念,我们在Qdrant中实现了一个简单的重新排序管道。此管道使用密集嵌入模型进行初始过采样检索,然后仅依赖输出词元嵌入进行重新排序步骤。
单一模型检索和重新排序基准测试
我们的测试侧重于使用相同的模型进行检索和重新排序。报告的指标是NDCG@10。在所有测试中,我们应用了5倍的过采样因子,这意味着检索步骤返回了50个结果,然后在重新排序步骤中缩小到10个。以下是BeIR数据集中一些结果
| 数据集 | all-miniLM-L6-v2 | BAAI/bge-small-en | ||
|---|---|---|---|---|
| 仅密集嵌入 | 密集 + 重新排序 | 仅密集嵌入 | 密集 + 重新排序 | |
| SciFact | 0.64508 | 0.70293 | 0.68213 | 0.73053 |
| NFCorpus | 0.31594 | 0.34297 | 0.29696 | 0.35996 |
| ArguAna | 0.50167 | 0.45378 | 0.58857 | 0.57302 |
| Touche-2020 | 0.16904 | 0.19693 | 0.13055 | 0.19821 |
| TREC-COVID | 0.47246 | 0.6379 | 0.45788 | 0.53539 |
| FiQA-2018 | 0.36867 | 0.41587 | 0.31091 | 0.39067 |
基准测试的源代码是公开的,你可以在beir-qdrant包的仓库中找到它。
总的来说,使用相同的模型添加重新排序步骤通常会提高检索质量。然而,各种后期交互模型的质量通常是根据当BM25用于初始检索时的重新排序性能来报告的。本实验旨在演示如何有效地将单一模型用于检索和重新排序,结果非常有前景。
现在,让我们探讨如何使用Qdrant 1.10中引入的新Query API来实现这一点。
设置Qdrant以进行后期交互
Qdrant 1.10中新的Query API能够构建更复杂的检索管道。我们可以使用池化后创建的单一向量进行初始检索步骤,然后使用输出词元嵌入对结果进行重新排序。
假设集合名为my-collection,并且配置为存储两个命名向量:dense-vector和output-token-embeddings,以下是在Qdrant中创建此类集合的方式
from qdrant_client import QdrantClient, models
client = QdrantClient("https://:6333")
client.create_collection(
collection_name="my-collection",
vectors_config={
"dense-vector": models.VectorParams(
size=384,
distance=models.Distance.COSINE,
),
"output-token-embeddings": models.VectorParams(
size=384,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
),
}
)
两个向量的大小相同,因为它们是由同一个all-MiniLM-L6-v2模型生成的。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
现在,我们不再仅仅使用单个密集向量进行搜索API,而是可以创建一个重新排序管道。首先,我们使用密集向量检索50个结果,然后使用输出词元嵌入对它们进行重新排序,以获得前10个结果。
query = "What else can be done with just all-MiniLM-L6-v2 model?"
client.query_points(
collection_name="my-collection",
prefetch=[
# Prefetch the dense embeddings of the top-50 documents
models.Prefetch(
query=model.encode(query).tolist(),
using="dense-vector",
limit=50,
)
],
# Rerank the top-50 documents retrieved by the dense embedding model
# and return just the top-10. Please note we call the same model, but
# we ask for the token embeddings by setting the output_value parameter.
query=model.encode(query, output_value="token_embeddings").tolist(),
using="output-token-embeddings",
limit=10,
)
亲自尝试这个实验
在实际场景中,你可能会更进一步,首先计算词元嵌入,然后进行池化以获得单一向量表示。这种方法允许你一次性完成所有操作。
开始在Qdrant中试验构建复杂重新排序管道的最简单方法是使用Qdrant Cloud上永久免费的集群并阅读Qdrant的文档。
这些实验的源代码是开源的,并使用了beir-qdrant,它是Qdrant与BeIR库的集成。
未来方向和研究机会
在检索过程中使用输出词元嵌入的初步实验已取得可喜成果。然而,我们计划进行进一步的基准测试以验证这些发现,并探索将稀疏方法纳入初始检索。此外,我们旨在研究量化对多向量表示及其对检索质量的影响。最后,我们将评估检索速度,这是许多应用程序的关键因素。