
在保持生产运行的同时,抽出足够的时间研究所有现代解决方案,这通常是不可行的。密集检索器、混合检索器、后期交互……它们如何工作,最适合在哪里?要是我们能像在亚马逊上比较产品一样轻松地比较检索器就好了!
我们探索了最流行的现代稀疏神经网络检索模型,并为您进行了细分。通过本文的阅读,您将对稀疏神经网络检索的当前格局有一个清晰的理解,并学会如何驾驭复杂、数学繁重且NDCG分数极高的研究论文,而不会感到不知所措。
本文的第一部分是理论性的,比较了现代稀疏神经网络检索中使用的不同方法。
本文的第二部分更具实践性,展示了现代稀疏神经网络检索中最好的模型SPLADE++如何在Qdrant中使用,以及何时为您的解决方案选择稀疏神经网络检索的建议。
稀疏神经网络检索:如果基于关键词的检索器能理解语义
基于关键词(词汇)的检索器,如BM25,提供了良好的可解释性。如果一个文档与查询匹配,很容易理解原因:查询词出现在文档中,如果这些是罕见的词,它们对于检索就更重要。
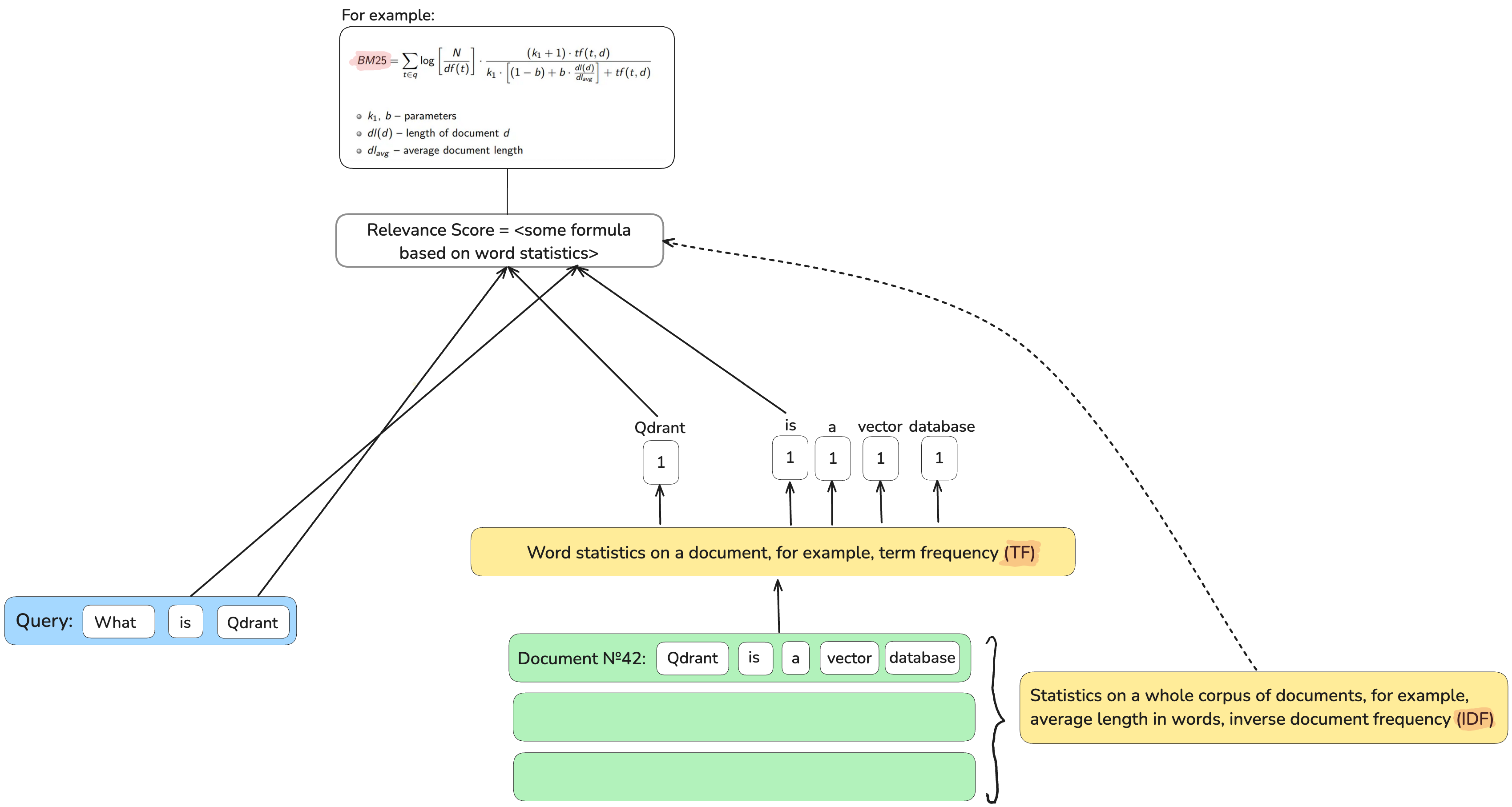
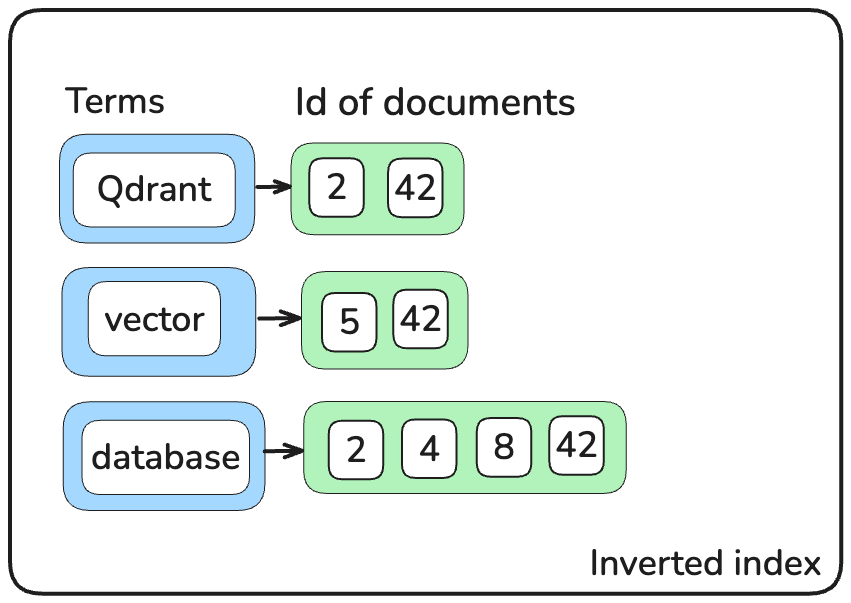
通过其精确词匹配机制,它们检索速度极快。一个简单的倒排索引,将词映射回包含该词的文档列表,可以节省检查数百万文档的时间。
词汇检索器在检索任务中仍然是一个强大的基线。然而,从设计上讲,它们无法弥合词汇和语义不匹配的鸿沟。想象一下,在网上商店搜索“美味奶酪”,却无法在您的购物车中找到“高达”或“布里”。
密集检索器,基于机器学习模型,将文档和查询编码成密集向量表示,能够弥合这一鸿沟,为您找到“一块高达奶酪”。
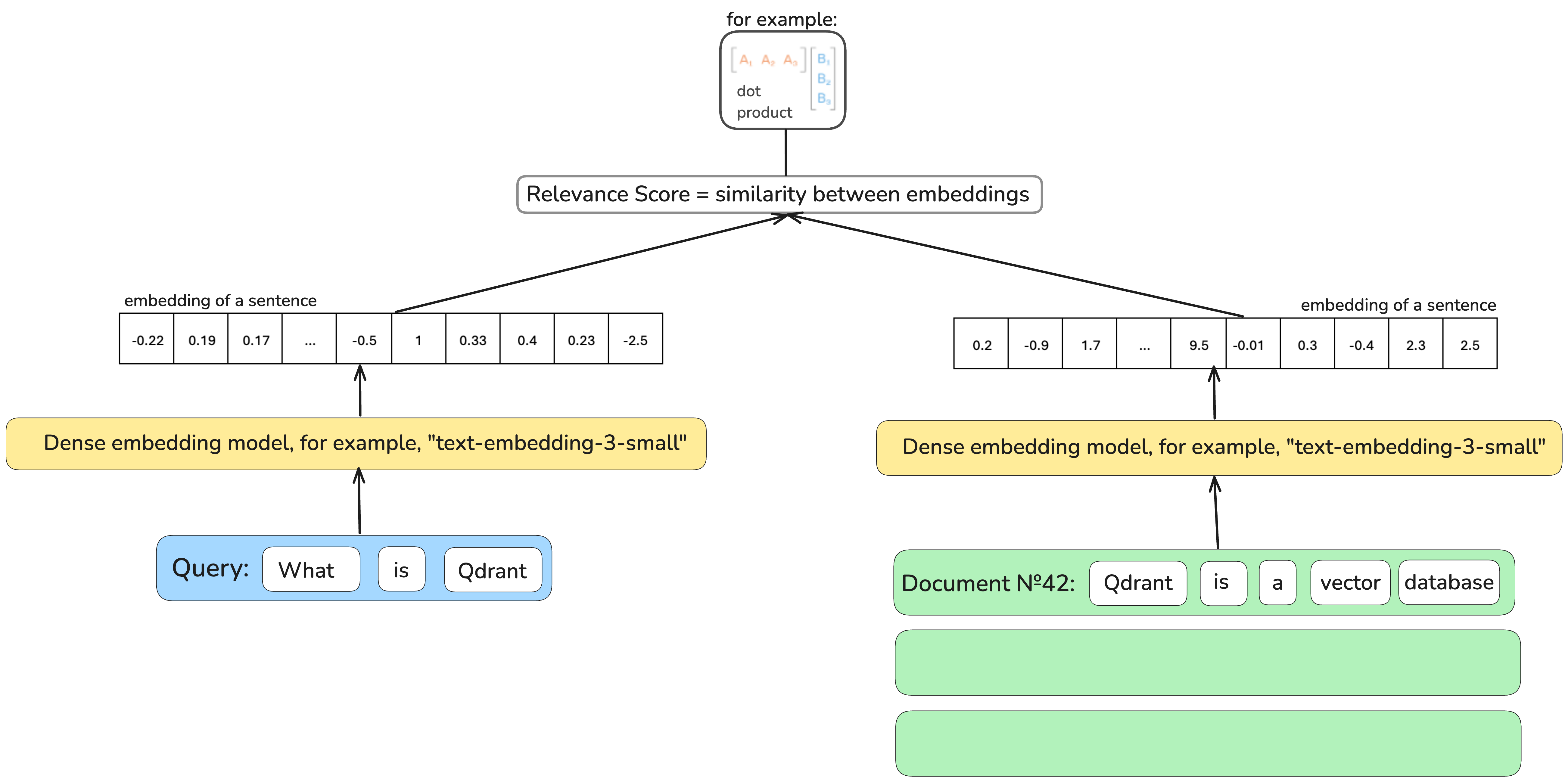
然而,这里的可解释性受到了影响:为什么这个查询表示与这个文档表示如此接近?为什么搜索“奶酪”时,我们还会被推荐“捕鼠器”?这个向量表示中的每个数字代表什么?哪个数字捕捉了奶酪的特性?
如果没有扎实的理解,平衡结果质量和资源消耗将变得具有挑战性。因为,理论上,任何文档都可能匹配查询,依赖精确匹配的倒排索引是不可行的。这并不意味着密集检索器天生就慢。然而,词汇检索已经存在足够长时间,足以启发一些有效的架构选择,这些选择通常值得重复利用。
迟早会有人说:“等等,如果我想要像BM25那样经久耐用但又具有语义理解能力的东西呢?”
稀疏神经网络检索演进
想象一下搜索一个“令人震惊的谋杀”故事。“令人震惊的”是一个很少使用的词,因此基于关键词的检索器,例如BM25,会赋予它巨大的重要性。因此,很可能一篇与任何犯罪无关但提到了“令人震惊的”文本会出现在顶部结果中。
如果我们不依赖文档中词频作为词重要性的代理(如BM25中那样),而是直接预测词的重要性,那会怎样?目标是让稀有但无影响的词被赋予比同等频率的重要词小得多的权重,而这两种词在BM25场景中都会被同等对待。
我们如何判断一个词是否比另一个词更重要?词的影响力与其含义相关,其含义可以从其上下文(围绕这个特定词的词)中推导出来。这就是密集上下文嵌入模型出现的原因。
所有稀疏检索器都基于这样一个想法:采用一个模型,该模型为词产生上下文密集向量表示,并教导它产生稀疏表示。通常,来自Transformer的双向编码器表示(BERT)被用作基础模型,并在其之上添加一个非常简单的可训练神经网络以稀疏化表示。训练这个小型神经网络通常通过从MS MARCO数据集中采样查询、相关和不相关文档来完成,并沿着相关性方向调整神经网络的参数。
稀疏神经网络检索的先驱
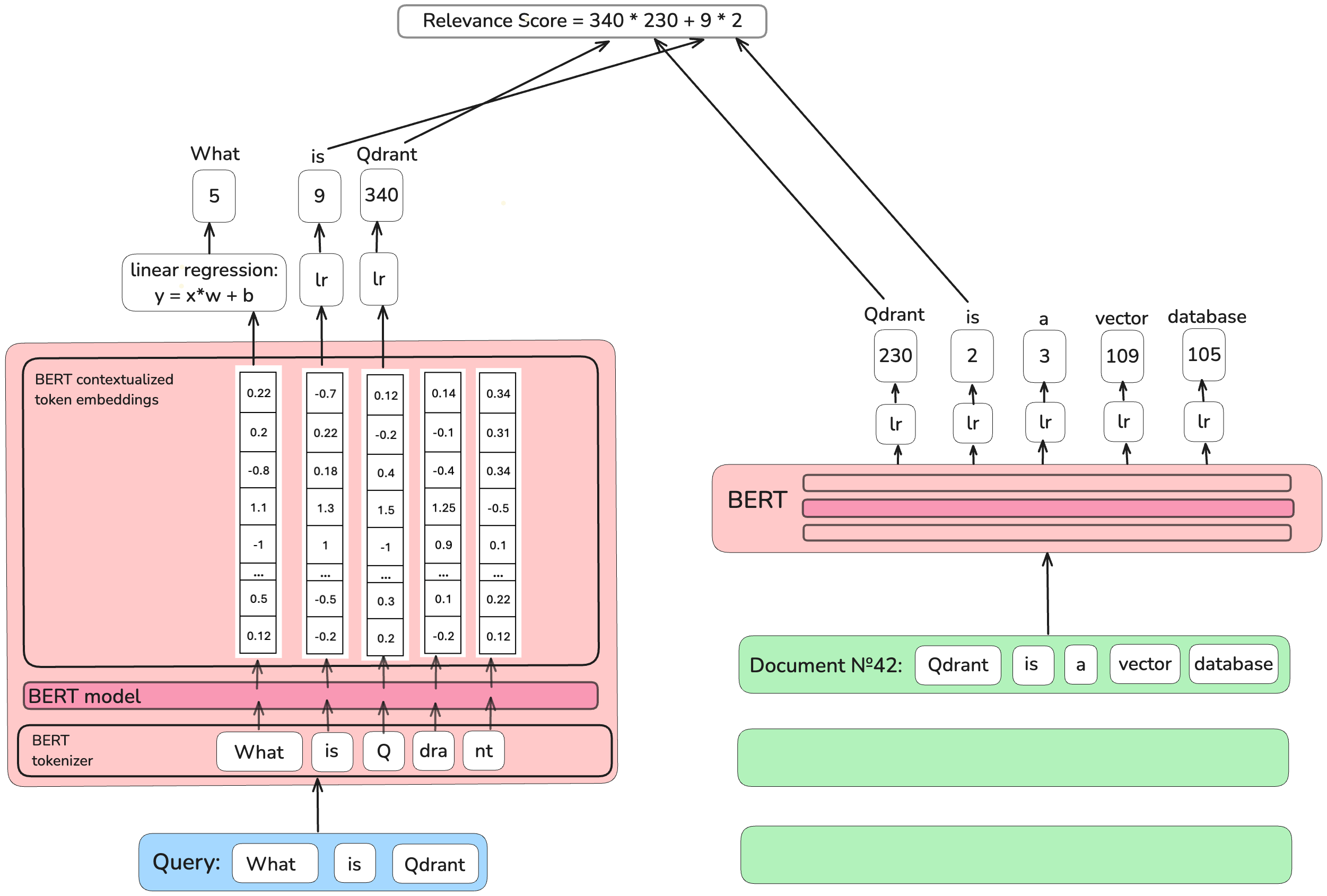 首批稀疏检索器之一——
首批稀疏检索器之一——深度上下文词权重框架(DeepCT)的作者,为文档和查询中的每个唯一词分别预测一个整数词影响力值。他们在基础BERT模型生成的上下文表示之上使用线性回归模型,模型输出会被四舍五入。
当文档上传到数据库时,文档中词的重要性由训练好的线性回归模型预测,并以与BM25检索器中词频相同的方式存储在倒排索引中。然后,检索过程与BM25相同。
为什么DeepCT不是一个完美的解决方案? 为了训练线性回归,作者需要提供每个词重要性的真实值(ground truth),以便模型能够“看到”正确的答案应该是什么。这个分数很难定义,使其真正表达查询-文档的相关性。当这个词来自一个五页的文档时,与查询最相关的词应该有什么分数?第二个相关的?第三个?
基于相关性目标的稀疏神经网络检索
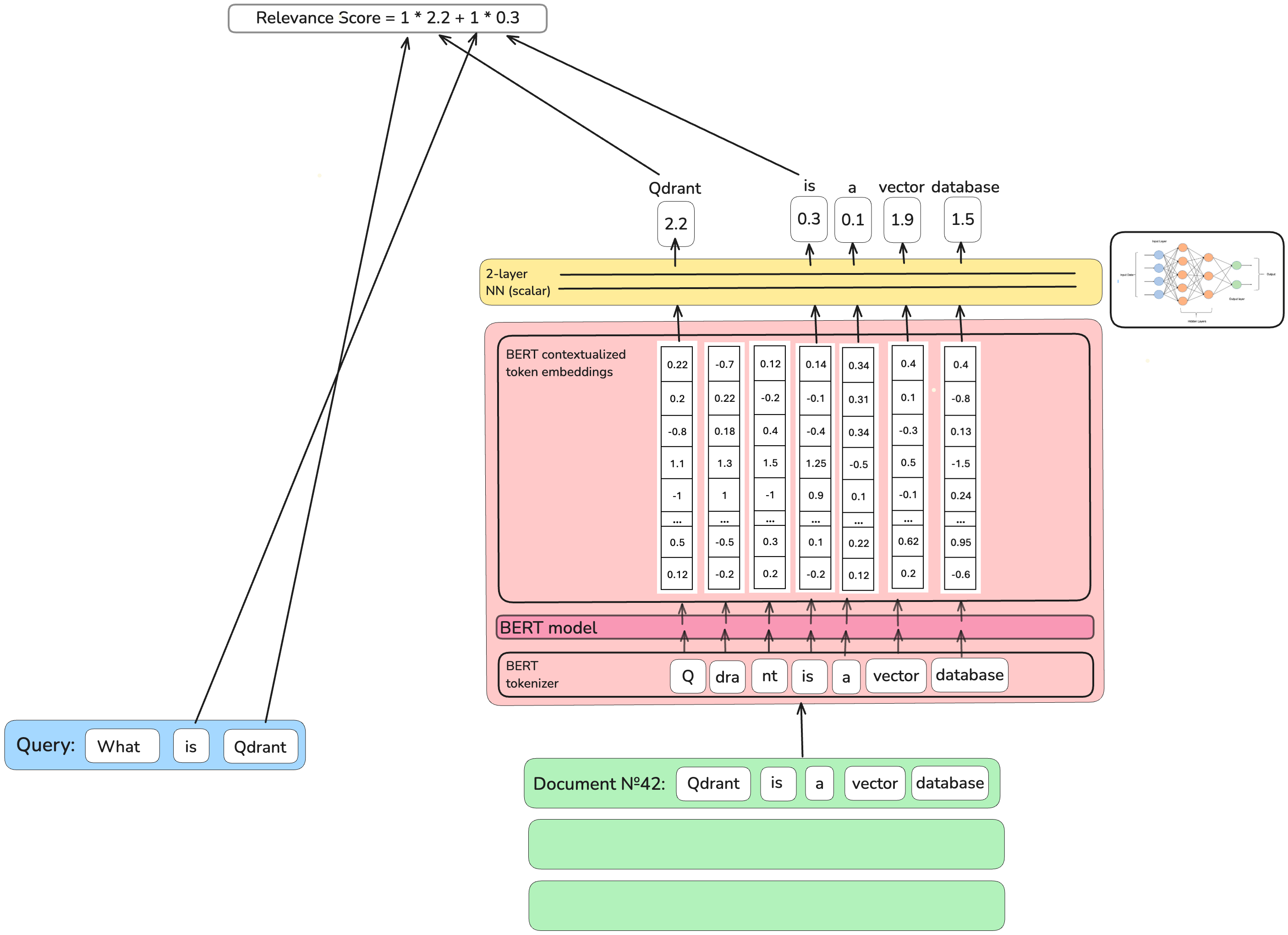 定义一个文档作为一个整体是否与查询相关或不相关要容易得多。这就是为什么
定义一个文档作为一个整体是否与查询相关或不相关要容易得多。这就是为什么DeepImpact稀疏神经网络检索的作者直接将查询与文档之间的相关性作为训练目标。他们获取BERT的文档词的上下文嵌入,通过一个简单的2层神经网络将其转换为单个标量分数,并将这些分数对每个与查询重叠的词进行求和。训练目标是使这个分数反映查询和文档之间的相关性。
为什么DeepImpact不是一个完美的解决方案? 在将文本转换为密集向量表示时,BERT模型并非在词层面工作。有时,它会将词拆分为部分。例如,词“vector”将被BERT作为一个整体处理,但对于一些BERT从未见过的词,它会将其切割成碎片,如“Qdrant”会变成“Q”、“#dra”和“#nt”。
DeepImpact模型(像DeepCT模型一样)取BERT为单词生成的第一个片段并丢弃其余部分。然而,如果搜索“Q”而不是“Qdrant”,能找到什么呢?
了解您的分词
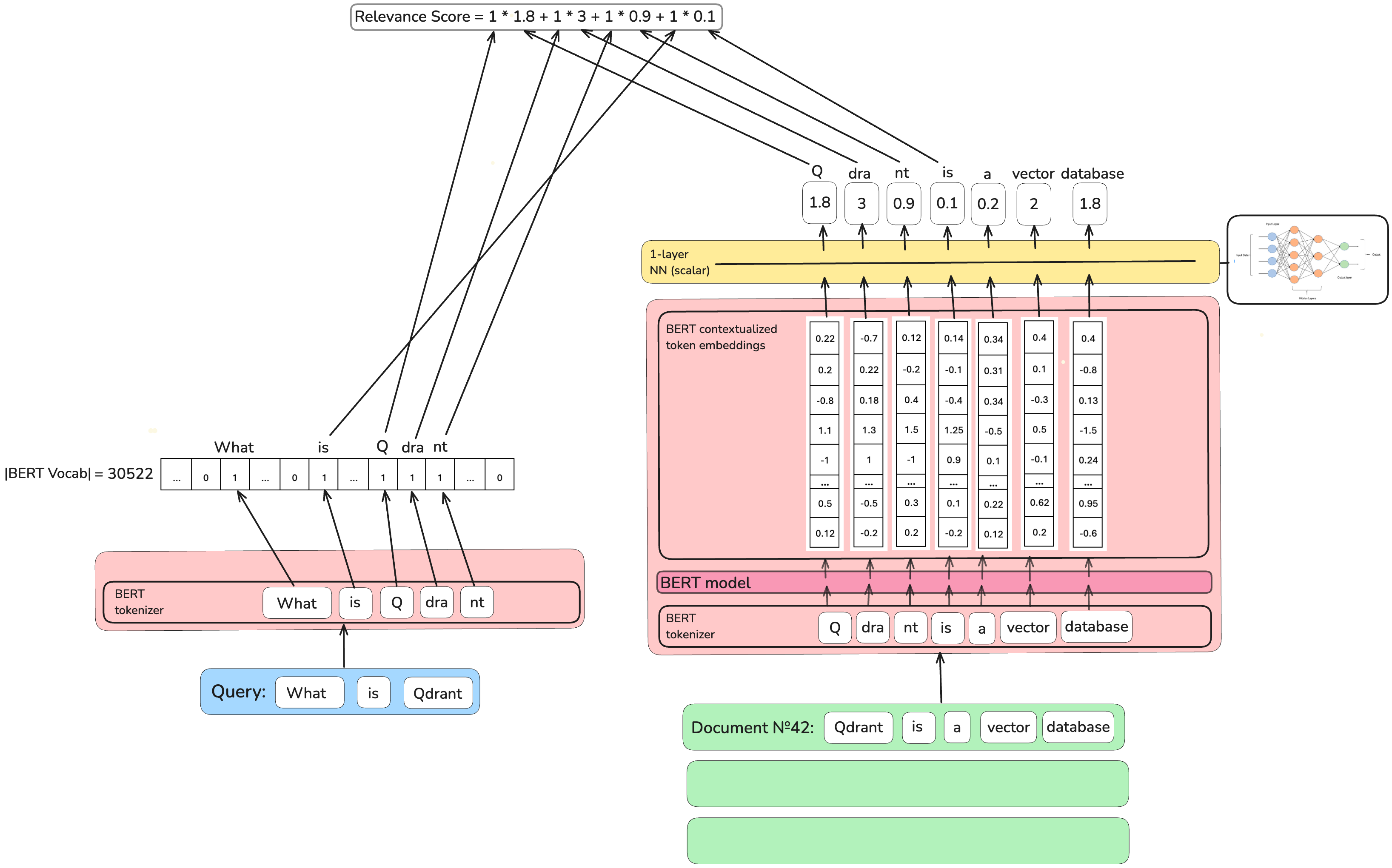 为了解决DeepImpact架构的问题,
为了解决DeepImpact架构的问题,词独立似然模型v2 (TILDEv2)在BERT的表示层而不是词层生成稀疏编码。除此之外,它的作者使用了与DeepImpact模型相同的架构。
为什么TILDEv2不是一个完美的解决方案? 单个标量重要性分数可能不足以捕捉一个词的所有不同含义。同音异义词(pizza、cocktail、flower和女性名字“Margherita”)是信息检索中的麻烦制造者之一。
理解同音异义词的稀疏神经网络检索器
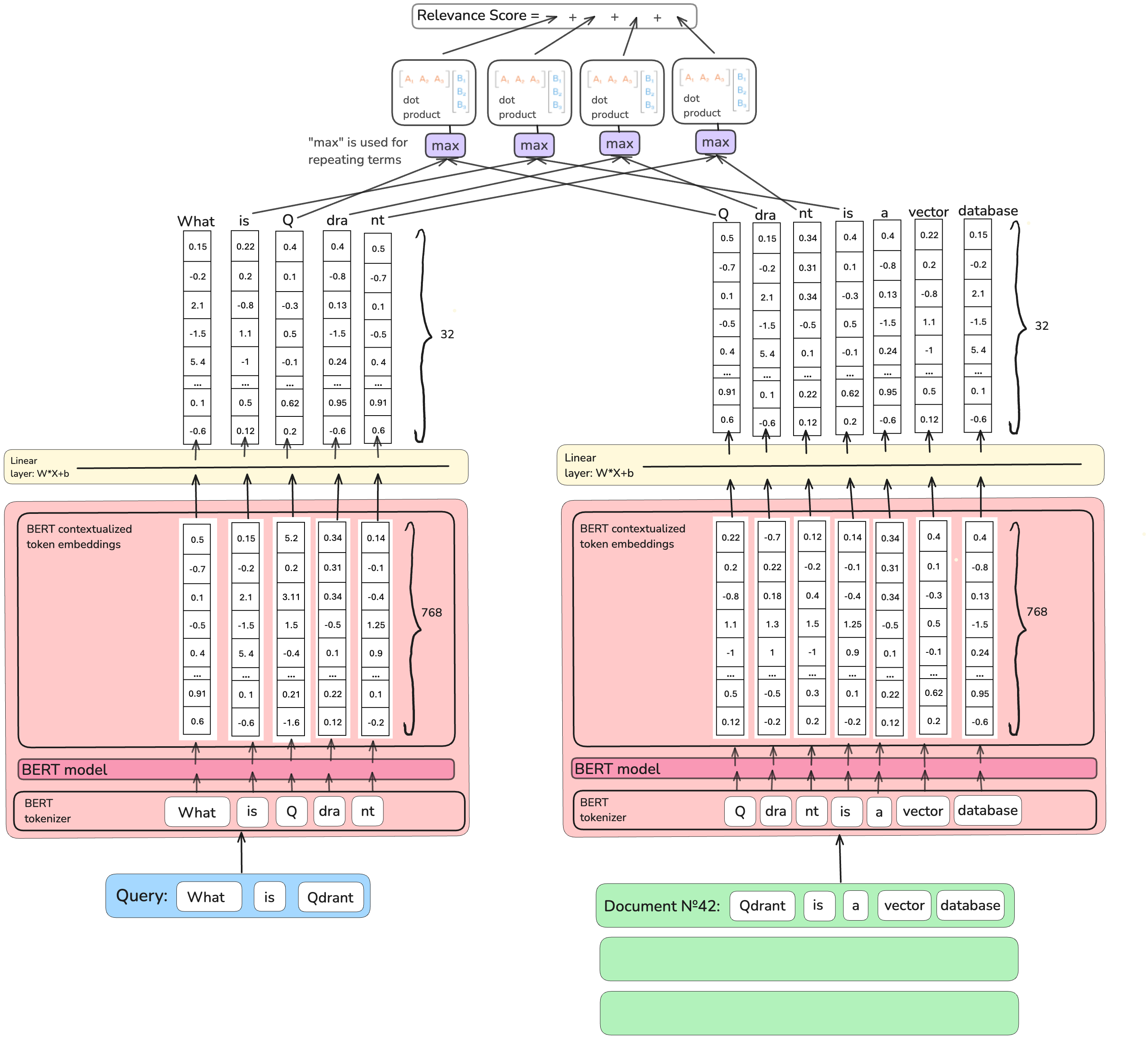
如果一个值不足以表示词的重要性分数,我们可以用向量形式描述词的重要性!上下文倒排列表 (COIL) 模型的作者正是基于这个想法。他们没有将768维BERT的上下文嵌入压缩成一个值,而是通过类似的“相关性”训练目标将其下投影到32维。此外,为了不遗漏任何细节,他们还将查询词编码为向量。
对于表示查询token的每个向量,COIL在文档中找到相同token的最近匹配(使用最大点积)向量。因此,例如,如果我们正在搜索“Revolut 银行 <金融机构>”,而数据库中的文档有句子“Vivid 银行 <金融机构> 搬到了阿姆斯特尔河 <河流> 的岸边”,在两个“银行”中,第一个与查询中的“银行”的点积值会更大,并且将计入最终分数。文档的最终相关性分数是匹配的查询词分数的总和。
为什么COIL不是一个完美的解决方案? 这种定义重要性分数的方式捕捉了更深层的语义;更多的含义伴随着更多的值来描述它。然而,为每个词存储32维向量要昂贵得多,并且倒排索引无法直接与这种架构一起工作。
回归本源
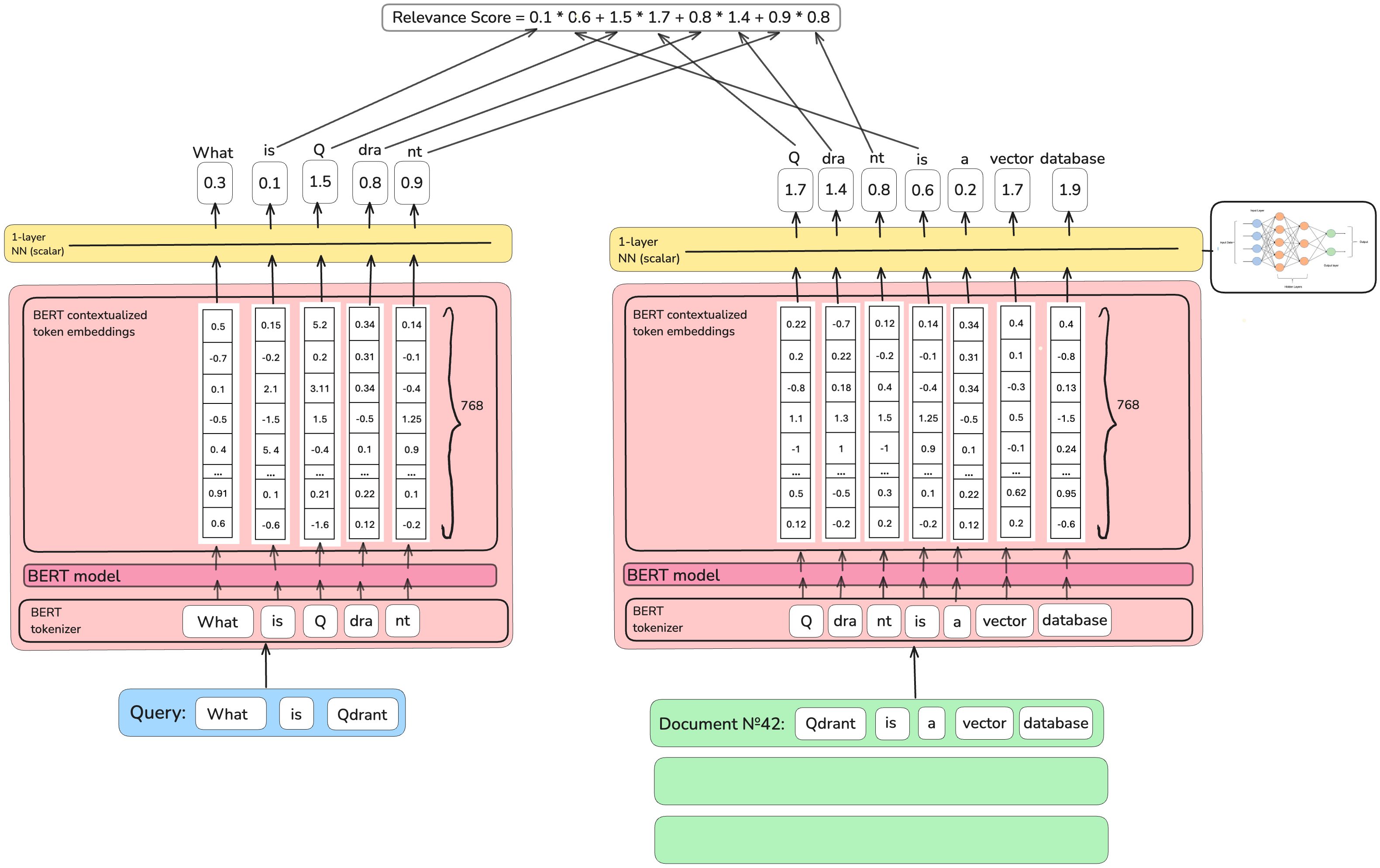 由COIL作者作为后续开发的
由COIL作者作为后续开发的通用上下文倒排列表 (UniCOIL) 回归到产生标量值作为重要性分数,而不是向量,同时保留了COIL所有其他设计决策。
它优化了资源消耗,但与COIL架构相关的深层语义理解再次丢失。
我们解决词汇不匹配问题了吗?
在基于精确匹配的检索中,无论预测词重要性的方法多么复杂,我们都无法匹配那些不包含查询词的相关文档。如果您在食谱书中搜索“pizza”,您将找不到“Margherita”。
解决这个问题的一种方法是通过所谓的文档扩展。让我们附加那些可能出现在搜索此文档的潜在查询中的词。因此,“Margherita”文档变成了“Margherita pizza”。现在,对“pizza”的精确匹配将奏效!
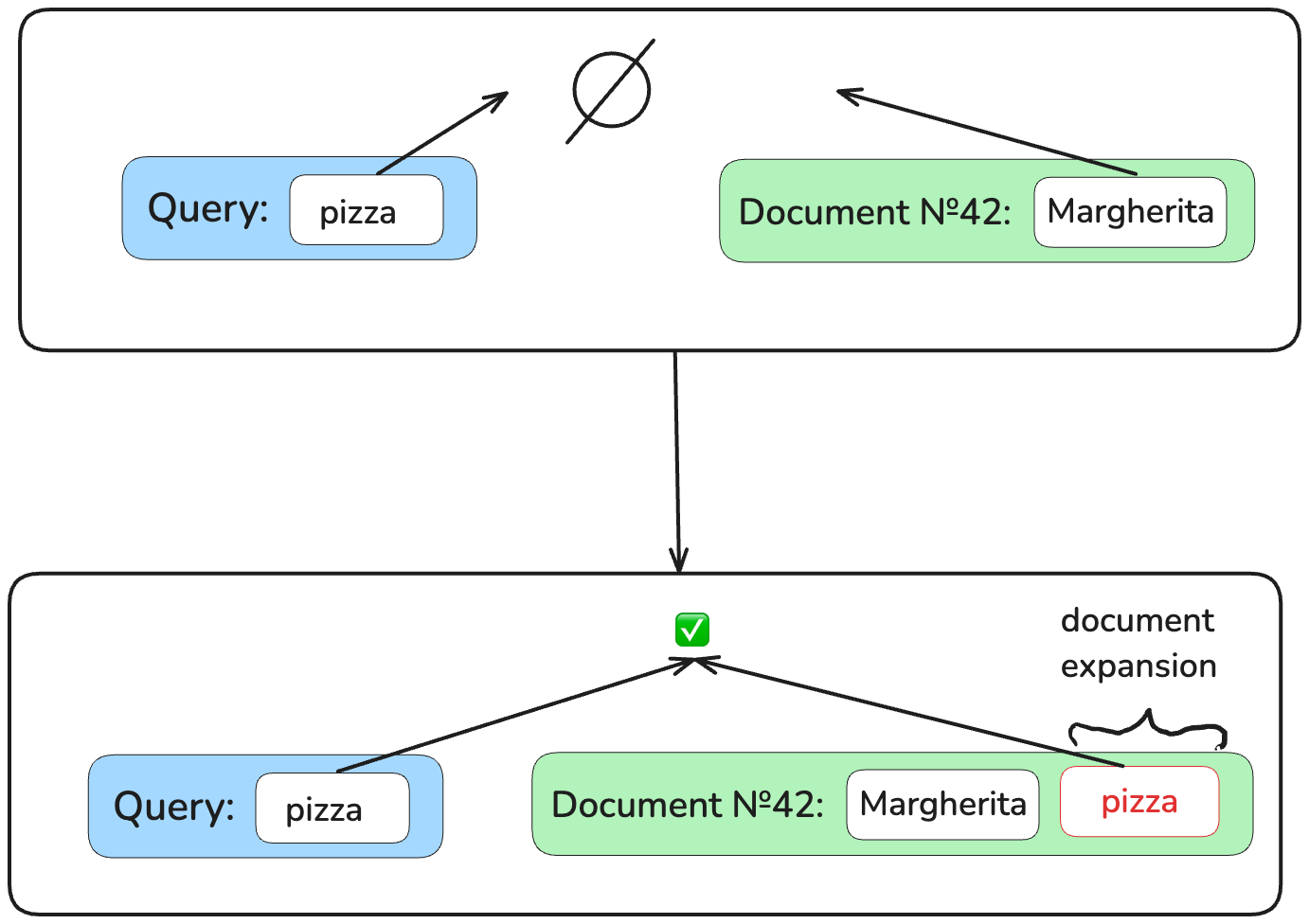
稀疏神经网络检索中使用的文档扩展有两种类型:外部(一个模型负责扩展,另一个模型负责检索)和内部(所有操作由单个模型完成)。
外部文档扩展
外部文档扩展使用生成模型(Mistral 7B、Chat-GPT和Claude都是生成模型,根据输入文本生成词)在将文档转换为稀疏表示并应用精确匹配方法之前,生成对文档的补充。
使用docT5query进行外部文档扩展

docT5query 是最常用的文档扩展模型。它基于Text-to-Text Transfer Transformer (T5) 模型,该模型经过训练,可以为给定文档生成前k个可能的查询。这些预测的短查询(最多约50-60个词)可能包含重复,因此如果检索器考虑词频,它也会对词频做出贡献。
docT5query扩展的问题是推理时间非常长,与任何生成模型一样:它每次运行只能生成一个token,并且会消耗相当一部分资源。
使用词独立似然模型(TILDE)进行外部文档扩展
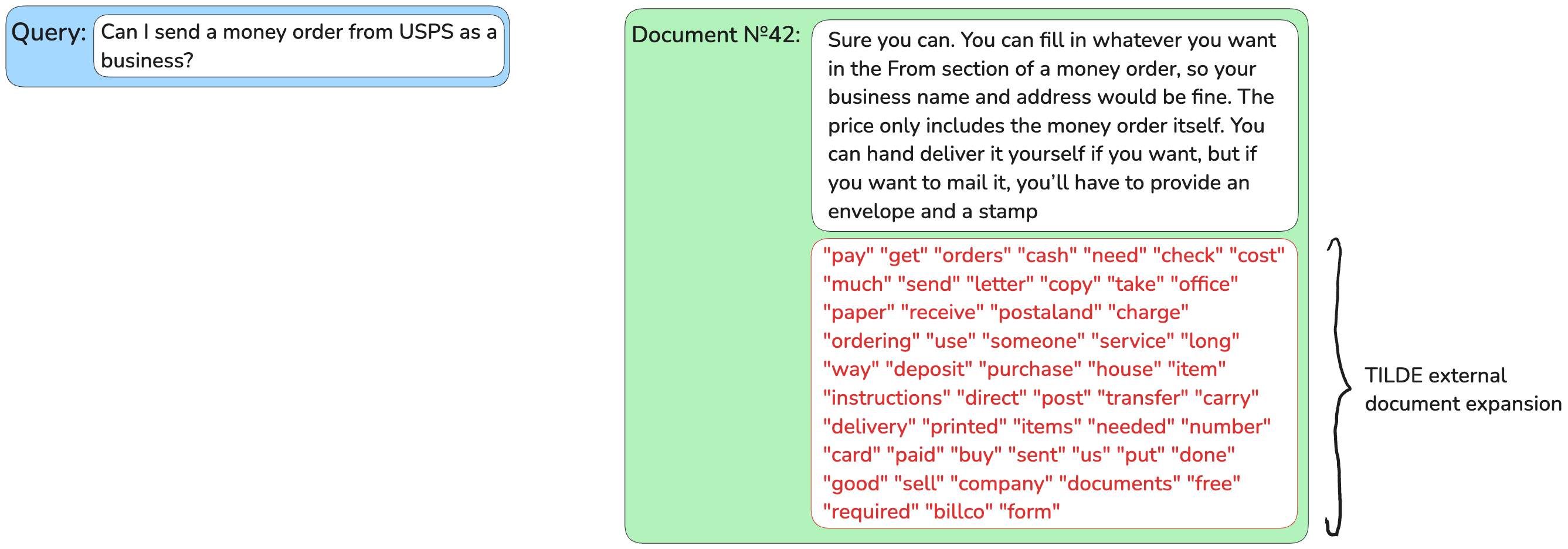
词独立似然模型(TILDE)是一种外部扩展方法,与docT5query相比,它将段落扩展时间减少了98%。它基于文本中的词相互独立(就像我们在说话时插入词语而不注意它们的顺序),这允许文档扩展的并行化。
TILDE不是预测查询,而是预测阅读一段文本后最可能出现的词(查询似然范式)。TILDE根据文档文本获取BERT词汇表中所有token的概率分布,并将其中前k个不重复的token附加到文档中。
外部文档扩展的问题: 外部文档扩展在许多生产场景中可能不可行,因为没有足够的时间或计算资源来扩展您想要存储在数据库中的每个文档,然后额外进行检索器所需的所有计算。为了解决这个问题,开发了一代模型,它们一次性完成所有操作,从而“内部”扩展文档。
内部文档扩展
假设我们不关心查询词的上下文,因此我们可以将它们视为独立的词,我们以随机顺序组合它们以获得结果。然后,对于文档中的每个上下文词,我们可以自由地预先计算该词如何影响我们词汇表中的每个词。
对于每个文档,都会创建一个词汇表长度的向量。为了填充此向量,对于词汇表中的每个词,都会检查任何文档词对其的影响是否足够大以考虑它。否则,文档向量中词汇表中该词的分数将为零。例如,通过对“pizza Margherita”文档在50,000个最常用英语词汇上预计算向量,对于这个由两个词组成的短文档,我们将得到一个50,000维的零向量,其中非零值将用于“pizza”、“pizzeria”、“flower”、“woman”、“girl”、“Margherita”、“cocktail”和“pizzaiolo”。
具有内部文档扩展的稀疏神经网络检索器
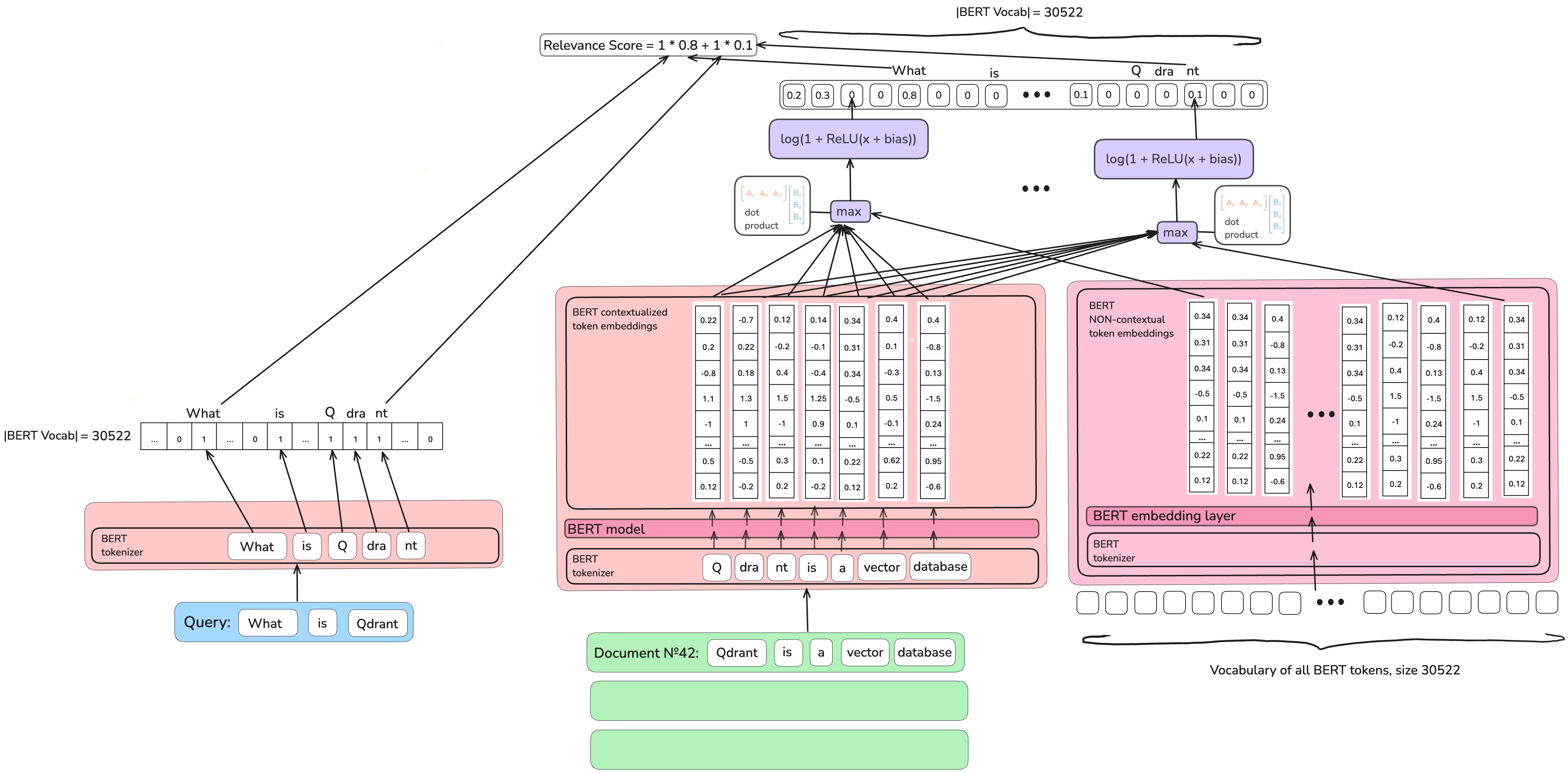
稀疏Transformer匹配(SPARTA)模型的作者使用BERT模型和BERT词汇表(约30,000个token)。对于BERT词汇表中的每个token,他们找到它与文档中上下文token之间的最大点积,并学习一个可观(非零)效应的阈值。然后,在推理时,唯一要做的就是将该文档中查询token的所有分数相加。
为什么SPARTA不是一个完美的解决方案? 在MS MARCO数据集上训练的许多稀疏神经网络检索器,包括SPARTA,在MS MARCO测试数据上显示出良好的结果,但当涉及到泛化(处理其他数据)时,它们可能比BM25表现更差。
现代稀疏神经网络检索的最新技术
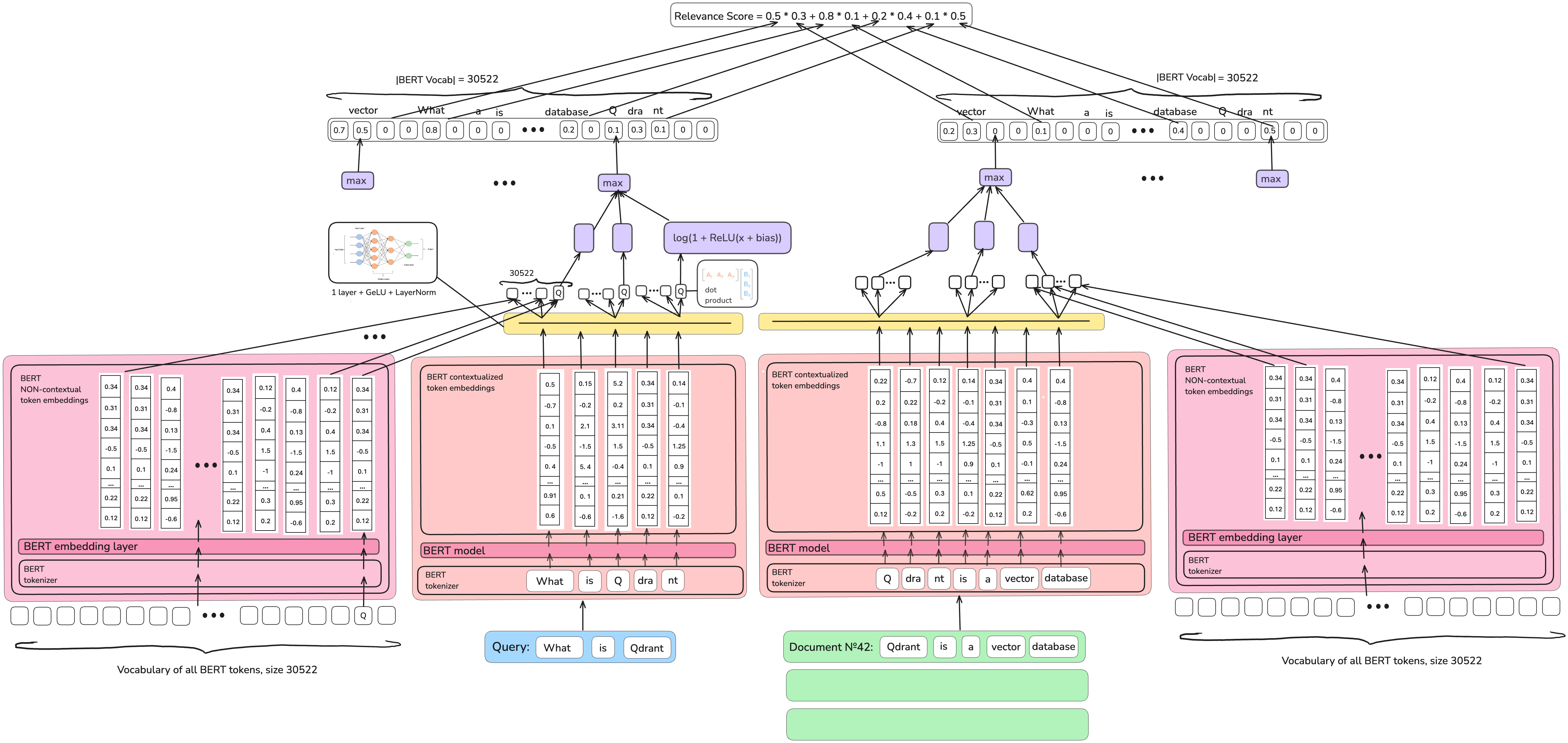
稀疏词汇和扩展模型(SPLADE)系列模型的作者将密集模型训练技巧添加到了内部文档扩展的思想中,这使得检索质量显著提高。
- SPARTA模型在结构上不够稀疏,因此SPLADE系列模型的作者引入了显式稀疏正则化,以防止模型产生过多的非零值。
- SPARTA模型大多直接使用BERT模型,没有额外的神经网络来捕捉信息检索问题的特异性,因此SPLADE模型在BERT之上引入了一个可训练的神经网络,并采用特定的架构选择,使其完美地适应任务。
- SPLADE系列模型,最后,使用知识蒸馏,即从一个更大(因此慢得多,不那么适合生产任务)的模型中学习如何预测良好的表示。
SPLADE系列模型的最新版本之一是SPLADE++。
与SPARTA模型不同,SPLADE++在推理时不仅扩展文档,还扩展查询。我们将在下一节中演示这一点。
Qdrant 中的 SPLADE++
在 Qdrant 中,您可以使用我们轻量级嵌入库 FastEmbed 轻松使用 SPLADE++。
设置
安装FastEmbed。
pip install fastembed
导入FastEmbed支持的稀疏文本嵌入模型。
from fastembed import SparseTextEmbedding
您可以列出目前支持的所有稀疏文本嵌入模型。
SparseTextEmbedding.list_supported_models()
支持模型列表的输出
[{'model': 'prithivida/Splade_PP_en_v1',
'vocab_size': 30522,
'description': 'Independent Implementation of SPLADE++ Model for English',
'size_in_GB': 0.532,
'sources': {'hf': 'Qdrant/SPLADE_PP_en_v1'},
'model_file': 'model.onnx'},
{'model': 'prithvida/Splade_PP_en_v1',
'vocab_size': 30522,
'description': 'Independent Implementation of SPLADE++ Model for English',
'size_in_GB': 0.532,
'sources': {'hf': 'Qdrant/SPLADE_PP_en_v1'},
'model_file': 'model.onnx'},
{'model': 'Qdrant/bm42-all-minilm-l6-v2-attentions',
'vocab_size': 30522,
'description': 'Light sparse embedding model, which assigns an importance score to each token in the text',
'size_in_GB': 0.09,
'sources': {'hf': 'Qdrant/all_miniLM_L6_v2_with_attentions'},
'model_file': 'model.onnx',
'additional_files': ['stopwords.txt'],
'requires_idf': True},
{'model': 'Qdrant/bm25',
'description': 'BM25 as sparse embeddings meant to be used with Qdrant',
'size_in_GB': 0.01,
'sources': {'hf': 'Qdrant/bm25'},
'model_file': 'mock.file',
'additional_files': ['arabic.txt',
'azerbaijani.txt',
'basque.txt',
'bengali.txt',
'catalan.txt',
'chinese.txt',
'danish.txt',
'dutch.txt',
'english.txt',
'finnish.txt',
'french.txt',
'german.txt',
'greek.txt',
'hebrew.txt',
'hinglish.txt',
'hungarian.txt',
'indonesian.txt',
'italian.txt',
'kazakh.txt',
'nepali.txt',
'norwegian.txt',
'portuguese.txt',
'romanian.txt',
'russian.txt',
'slovene.txt',
'spanish.txt',
'swedish.txt',
'tajik.txt',
'turkish.txt'],
'requires_idf': True}]
加载SPLADE++。
sparse_model_name = "prithivida/Splade_PP_en_v1"
sparse_model = SparseTextEmbedding(model_name=sparse_model_name)
模型文件将被获取并下载,并显示进度。
嵌入数据
我们将使用一个玩具电影描述数据集。
电影描述数据集
descriptions = ["In 1431, Jeanne d'Arc is placed on trial on charges of heresy. The ecclesiastical jurists attempt to force Jeanne to recant her claims of holy visions.",
"A film projectionist longs to be a detective, and puts his meagre skills to work when he is framed by a rival for stealing his girlfriend's father's pocketwatch.",
"A group of high-end professional thieves start to feel the heat from the LAPD when they unknowingly leave a clue at their latest heist.",
"A petty thief with an utter resemblance to a samurai warlord is hired as the lord's double. When the warlord later dies the thief is forced to take up arms in his place.",
"A young boy named Kubo must locate a magical suit of armour worn by his late father in order to defeat a vengeful spirit from the past.",
"A biopic detailing the 2 decades that Punjabi Sikh revolutionary Udham Singh spent planning the assassination of the man responsible for the Jallianwala Bagh massacre.",
"When a machine that allows therapists to enter their patients' dreams is stolen, all hell breaks loose. Only a young female therapist, Paprika, can stop it.",
"An ordinary word processor has the worst night of his life after he agrees to visit a girl in Soho whom he met that evening at a coffee shop.",
"A story that revolves around drug abuse in the affluent north Indian State of Punjab and how the youth there have succumbed to it en-masse resulting in a socio-economic decline.",
"A world-weary political journalist picks up the story of a woman's search for her son, who was taken away from her decades ago after she became pregnant and was forced to live in a convent.",
"Concurrent theatrical ending of the TV series Neon Genesis Evangelion (1995).",
"During World War II, a rebellious U.S. Army Major is assigned a dozen convicted murderers to train and lead them into a mass assassination mission of German officers.",
"The toys are mistakenly delivered to a day-care center instead of the attic right before Andy leaves for college, and it's up to Woody to convince the other toys that they weren't abandoned and to return home.",
"A soldier fighting aliens gets to relive the same day over and over again, the day restarting every time he dies.",
"After two male musicians witness a mob hit, they flee the state in an all-female band disguised as women, but further complications set in.",
"Exiled into the dangerous forest by her wicked stepmother, a princess is rescued by seven dwarf miners who make her part of their household.",
"A renegade reporter trailing a young runaway heiress for a big story joins her on a bus heading from Florida to New York, and they end up stuck with each other when the bus leaves them behind at one of the stops.",
"Story of 40-man Turkish task force who must defend a relay station.",
"Spinal Tap, one of England's loudest bands, is chronicled by film director Marty DiBergi on what proves to be a fateful tour.",
"Oskar, an overlooked and bullied boy, finds love and revenge through Eli, a beautiful but peculiar girl."]
使用SPLADE++嵌入电影描述。
sparse_descriptions = list(sparse_model.embed(descriptions))
您可以查看 SPLADE++ 在 Qdrant 中生成的稀疏向量是什么样子。
sparse_descriptions[0]
它被存储为BERT token的索引(权重非零)和这些权重的值。
SparseEmbedding(
values=array([1.57449973, 0.90787691, ..., 1.21796167, 1.1321187]),
indices=array([ 1040, 2001, ..., 28667, 29137])
)
将嵌入上传到Qdrant
安装qdrant-client
pip install qdrant-client
Qdrant 客户端具有简单的内存模式,允许您在本地小数据量上进行实验。此外,您还可以使用 Qdrant Cloud 中的免费层集群进行实验。
from qdrant_client import QdrantClient, models
qdrant_client = QdrantClient(":memory:") # Qdrant is running from RAM.
现在,让我们创建一个集合,用于上传我们的稀疏 SPLADE++ 嵌入。
为此,我们将使用Qdrant中支持的稀疏向量表示。
qdrant_client.create_collection(
collection_name="movies",
vectors_config={},
sparse_vectors_config={
"film_description": models.SparseVectorParams(),
},
)
为了使这个集合易于阅读,我们将电影元数据(名称、描述和电影长度)与嵌入一起保存。
电影元数据
metadata = [{"movie_name": "The Passion of Joan of Arc", "movie_watch_time_min": 114, "movie_description": "In 1431, Jeanne d'Arc is placed on trial on charges of heresy. The ecclesiastical jurists attempt to force Jeanne to recant her claims of holy visions."},
{"movie_name": "Sherlock Jr.", "movie_watch_time_min": 45, "movie_description": "A film projectionist longs to be a detective, and puts his meagre skills to work when he is framed by a rival for stealing his girlfriend's father's pocketwatch."},
{"movie_name": "Heat", "movie_watch_time_min": 170, "movie_description": "A group of high-end professional thieves start to feel the heat from the LAPD when they unknowingly leave a clue at their latest heist."},
{"movie_name": "Kagemusha", "movie_watch_time_min": 162, "movie_description": "A petty thief with an utter resemblance to a samurai warlord is hired as the lord's double. When the warlord later dies the thief is forced to take up arms in his place."},
{"movie_name": "Kubo and the Two Strings", "movie_watch_time_min": 101, "movie_description": "A young boy named Kubo must locate a magical suit of armour worn by his late father in order to defeat a vengeful spirit from the past."},
{"movie_name": "Sardar Udham", "movie_watch_time_min": 164, "movie_description": "A biopic detailing the 2 decades that Punjabi Sikh revolutionary Udham Singh spent planning the assassination of the man responsible for the Jallianwala Bagh massacre."},
{"movie_name": "Paprika", "movie_watch_time_min": 90, "movie_description": "When a machine that allows therapists to enter their patients' dreams is stolen, all hell breaks loose. Only a young female therapist, Paprika, can stop it."},
{"movie_name": "After Hours", "movie_watch_time_min": 97, "movie_description": "An ordinary word processor has the worst night of his life after he agrees to visit a girl in Soho whom he met that evening at a coffee shop."},
{"movie_name": "Udta Punjab", "movie_watch_time_min": 148, "movie_description": "A story that revolves around drug abuse in the affluent north Indian State of Punjab and how the youth there have succumbed to it en-masse resulting in a socio-economic decline."},
{"movie_name": "Philomena", "movie_watch_time_min": 98, "movie_description": "A world-weary political journalist picks up the story of a woman's search for her son, who was taken away from her decades ago after she became pregnant and was forced to live in a convent."},
{"movie_name": "Neon Genesis Evangelion: The End of Evangelion", "movie_watch_time_min": 87, "movie_description": "Concurrent theatrical ending of the TV series Neon Genesis Evangelion (1995)."},
{"movie_name": "The Dirty Dozen", "movie_watch_time_min": 150, "movie_description": "During World War II, a rebellious U.S. Army Major is assigned a dozen convicted murderers to train and lead them into a mass assassination mission of German officers."},
{"movie_name": "Toy Story 3", "movie_watch_time_min": 103, "movie_description": "The toys are mistakenly delivered to a day-care center instead of the attic right before Andy leaves for college, and it's up to Woody to convince the other toys that they weren't abandoned and to return home."},
{"movie_name": "Edge of Tomorrow", "movie_watch_time_min": 113, "movie_description": "A soldier fighting aliens gets to relive the same day over and over again, the day restarting every time he dies."},
{"movie_name": "Some Like It Hot", "movie_watch_time_min": 121, "movie_description": "After two male musicians witness a mob hit, they flee the state in an all-female band disguised as women, but further complications set in."},
{"movie_name": "Snow White and the Seven Dwarfs", "movie_watch_time_min": 83, "movie_description": "Exiled into the dangerous forest by her wicked stepmother, a princess is rescued by seven dwarf miners who make her part of their household."},
{"movie_name": "It Happened One Night", "movie_watch_time_min": 105, "movie_description": "A renegade reporter trailing a young runaway heiress for a big story joins her on a bus heading from Florida to New York, and they end up stuck with each other when the bus leaves them behind at one of the stops."},
{"movie_name": "Nefes: Vatan Sagolsun", "movie_watch_time_min": 128, "movie_description": "Story of 40-man Turkish task force who must defend a relay station."},
{"movie_name": "This Is Spinal Tap", "movie_watch_time_min": 82, "movie_description": "Spinal Tap, one of England's loudest bands, is chronicled by film director Marty DiBergi on what proves to be a fateful tour."},
{"movie_name": "Let the Right One In", "movie_watch_time_min": 114, "movie_description": "Oskar, an overlooked and bullied boy, finds love and revenge through Eli, a beautiful but peculiar girl."}]
将嵌入的描述与电影元数据上传到集合中。
qdrant_client.upsert(
collection_name="movies",
points=[
models.PointStruct(
id=idx,
payload=metadata[idx],
vector={
"film_description": models.SparseVector(
indices=vector.indices,
values=vector.values
)
},
)
for idx, vector in enumerate(sparse_descriptions)
],
)
隐式生成稀疏向量(点击展开)
qdrant_client.upsert(
collection_name="movies",
points=[
models.PointStruct(
id=idx,
payload=metadata[idx],
vector={
"film_description": models.Document(
text=description, model=sparse_model_name
)
},
)
for idx, description in enumerate(descriptions)
],
)
查询
让我们查询我们的集合!
query_embedding = list(sparse_model.embed("A movie about music"))[0]
response = qdrant_client.query_points(
collection_name="movies",
query=models.SparseVector(indices=query_embedding.indices, values=query_embedding.values),
using="film_description",
limit=1,
with_vectors=True,
with_payload=True
)
print(response)
隐式生成稀疏向量(点击展开)
response = qdrant_client.query_points(
collection_name="movies",
query=models.Document(text="A movie about music", model=sparse_model_name),
using="film_description",
limit=1,
with_vectors=True,
with_payload=True,
)
print(response)
输出看起来像这样
points=[ScoredPoint(
id=18,
version=0,
score=9.6779785,
payload={
'movie_name': 'This Is Spinal Tap',
'movie_watch_time_min': 82,
'movie_description': "Spinal Tap, one of England's loudest bands,
is chronicled by film director Marty DiBergi on what proves to be a fateful tour."
},
vector={
'film_description': SparseVector(
indices=[1010, 2001, ..., 25316, 25517],
values=[0.49717945, 0.19760133, ..., 1.2124698, 0.58689135])
},
shard_key=None,
order_value=None
)]
如您所见,查询与找到的电影的描述中没有重叠的词,尽管答案符合查询,而且我们正在使用精确匹配。
这要归功于SPLADE++对查询和文档进行的内部扩展。
SPLADE++的内部扩展
让我们检查SPLADE++是如何扩展查询和我们得到的答案文档的。
为此,我们需要使用HuggingFace库Tokenizers。有了它,我们将能够将SPLADE++使用的词汇表中的索引解码回人类可读的格式。
首先我们需要安装这个库。
pip install tokenizers
然后,让我们编写一个函数,它将解码SPLADE++稀疏嵌入并返回SPLADE++用于编码输入的词。
我们希望根据SPLADE++分配的权重(影响力分数)以降序返回它们。
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained('Qdrant/SPLADE_PP_en_v1')
def get_tokens_and_weights(sparse_embedding, tokenizer):
token_weight_dict = {}
for i in range(len(sparse_embedding.indices)):
token = tokenizer.decode([sparse_embedding.indices[i]])
weight = sparse_embedding.values[i]
token_weight_dict[token] = weight
# Sort the dictionary by weights
token_weight_dict = dict(sorted(token_weight_dict.items(), key=lambda item: item[1], reverse=True))
return token_weight_dict
首先,我们将函数应用于查询。
query_embedding = list(sparse_model.embed("A movie about music"))[0]
print(get_tokens_and_weights(query_embedding, tokenizer))
SPLADE++就是这样扩展查询的
{
"music": 2.764289617538452,
"movie": 2.674748420715332,
"film": 2.3489091396331787,
"musical": 2.276120901107788,
"about": 2.124547004699707,
"movies": 1.3825485706329346,
"song": 1.2893378734588623,
"genre": 0.9066758751869202,
"songs": 0.8926399946212769,
"a": 0.8900706768035889,
"musicians": 0.5638002157211304,
"sound": 0.49310919642448425,
"musician": 0.46415239572525024,
"drama": 0.462990403175354,
"tv": 0.4398191571235657,
"book": 0.38950803875923157,
"documentary": 0.3758136034011841,
"hollywood": 0.29099565744400024,
"story": 0.2697228491306305,
"nature": 0.25306591391563416,
"concerning": 0.205053448677063,
"game": 0.1546829640865326,
"rock": 0.11775632947683334,
"definition": 0.08842901140451431,
"love": 0.08636035025119781,
"soundtrack": 0.06807517260313034,
"religion": 0.053535860031843185,
"filmed": 0.025964470580220222,
"sounds": 0.0004048719711136073
}
然后,我们对答案应用我们的函数。
query_embedding = list(sparse_model.embed("A movie about music"))[0]
response = qdrant_client.query_points(
collection_name="movies",
query=models.SparseVector(indices=query_embedding.indices, values=query_embedding.values),
using="film_description",
limit=1,
with_vectors=True,
with_payload=True
)
print(get_tokens_and_weights(response.points[0].vector['film_description'], tokenizer))
隐式生成稀疏向量(点击展开)
response = qdrant_client.query_points(
collection_name="movies",
query=models.Document(text="A movie about music", model=sparse_model_name),
using="film_description",
limit=1,
with_vectors=True,
with_payload=True,
)
print(get_tokens_and_weights(response.points[0].vector["film_description"], tokenizer))
SPLADE++就是这样扩展答案的。
{'spinal': 2.6548674, 'tap': 2.534881, 'marty': 2.223297, '##berg': 2.0402722,
'##ful': 2.0030282, 'fate': 1.935915, 'loud': 1.8381964, 'spine': 1.7507898,
'di': 1.6161551, 'bands': 1.5897619, 'band': 1.589473, 'uk': 1.5385966, 'tour': 1.4758654,
'chronicle': 1.4577943, 'director': 1.4423795, 'england': 1.4301306, '##est': 1.3025658,
'taps': 1.2124698, 'film': 1.1069428, '##berger': 1.1044296, 'tapping': 1.0424755, 'best': 1.0327196,
'louder': 0.9229055, 'music': 0.9056678, 'directors': 0.8887502, 'movie': 0.870712, 'directing': 0.8396196,
'sound': 0.83609974, 'genre': 0.803052, 'dave': 0.80212915, 'wrote': 0.7849579, 'hottest': 0.7594193, 'filmed': 0.750105,
'english': 0.72807616, 'who': 0.69502294, 'tours': 0.6833075, 'club': 0.6375339, 'vertebrae': 0.58689135, 'chronicles': 0.57296354,
'dance': 0.57278687, 'song': 0.50987065, ',': 0.49717945, 'british': 0.4971719, 'writer': 0.495709, 'directed': 0.4875775,
'cork': 0.475757, '##i': 0.47122696, '##band': 0.46837863, 'most': 0.44112885, '##liest': 0.44084555, 'destiny': 0.4264851,
'prove': 0.41789067, 'is': 0.40306947, 'famous': 0.40230379, 'hop': 0.3897451, 'noise': 0.38770816, '##iest': 0.3737782,
'comedy': 0.36903998, 'sport': 0.35883865, 'quiet': 0.3552795, 'detail': 0.3397654, 'fastest': 0.30345848, 'filmmaker': 0.3013101,
'festival': 0.28146765, '##st': 0.28040633, 'tram': 0.27373192, 'well': 0.2599603, 'documentary': 0.24368097, 'beat': 0.22953634,
'direction': 0.22925079, 'hardest': 0.22293334, 'strongest': 0.2018861, 'was': 0.19760133, 'oldest': 0.19532987,
'byron': 0.19360808, 'worst': 0.18397793, 'touring': 0.17598206, 'rock': 0.17319143, 'clubs': 0.16090117,
'popular': 0.15969758, 'toured': 0.15917331, 'trick': 0.1530599, 'celebrity': 0.14458777, 'musical': 0.13888633,
'filming': 0.1363699, 'culture': 0.13616633, 'groups': 0.1340591, 'ski': 0.13049376, 'venue': 0.12992987,
'style': 0.12853126, 'history': 0.12696269, 'massage': 0.11969914, 'theatre': 0.11673525, 'sounds': 0.108338095,
'visit': 0.10516077, 'editing': 0.078659914, 'death': 0.066746496, 'massachusetts': 0.055702563, 'stuart': 0.0447934,
'romantic': 0.041140396, 'pamela': 0.03561337, 'what': 0.016409796, 'smallest': 0.010815808, 'orchestra': 0.0020691194}
由于扩展,查询和文档在“music”、“film”、“sounds”等词上存在重叠,因此精确匹配奏效。
关键点:何时选择稀疏神经网络模型进行检索
稀疏神经网络检索有意义
在关键词匹配至关重要但BM25不足以进行初始检索的领域,语义匹配(例如,同义词、同音异义词)增加了显著的价值。这在医学、学术、法律和电子商务等领域尤其如此,其中品牌名称和序列号起着关键作用。密集检索器往往返回许多误报,而稀疏神经网络检索有助于缩小这些误报。
稀疏神经网络检索是扩展的宝贵选择,尤其是在处理大型数据集时。它利用倒排索引进行精确匹配,根据数据性质,速度可以很快。
如果您正在使用传统的检索系统,稀疏神经网络检索与它们兼容并有助于弥合语义鸿沟。