
扩展您的机器学习设置:Qdrant 中多租户和自定义分片的力量
我们每天都在 Discord 支持频道 上看到有关多租户和分布式部署的话题。这表明许多用户正寻求将 Qdrant 与其机器学习设置的其他部分一同扩展。
无论您是构建银行欺诈检测系统、用于电商的 RAG,还是为联邦政府提供服务——您都需要利用多租户架构来扩展您的产品。在 SaaS 和企业应用领域,这种设置是常态。它将显著提升您的应用性能并降低托管成本。
Qdrant 的多租户与自定义分片
我们为此开发了两个主要功能。您现在可以扩展单个 Qdrant 集群并支持全球所有客户。 在多租户模式下,每个客户的数据完全隔离,只能由其自己访问。有时,如果数据对位置敏感,Qdrant 还提供了按区域或其他标准划分集群的选项,以进一步保护客户访问。这称为自定义分片。
结合这两个功能将产生一种高效分区的架构,进一步利用了单个 Qdrant 集群的便利性。本文将简要解释其优势,并展示如何开始使用这两个功能。
一个集合,多个租户
使用 Qdrant 时,您可以将所有数据批量写入到单个集合中,然后通过向量的 payload(载荷)对其进行分区。这意味着所有用户都在利用单个 Qdrant 集群的能力,但他们的数据在集合内仍然是隔离的。让我们看一个包含两个租户的集合:
图 1: 每个向量都被分配了一个特定的 payload,表示它属于哪个租户。这就是大量不同租户如何共享一个 Qdrant 集合的方式。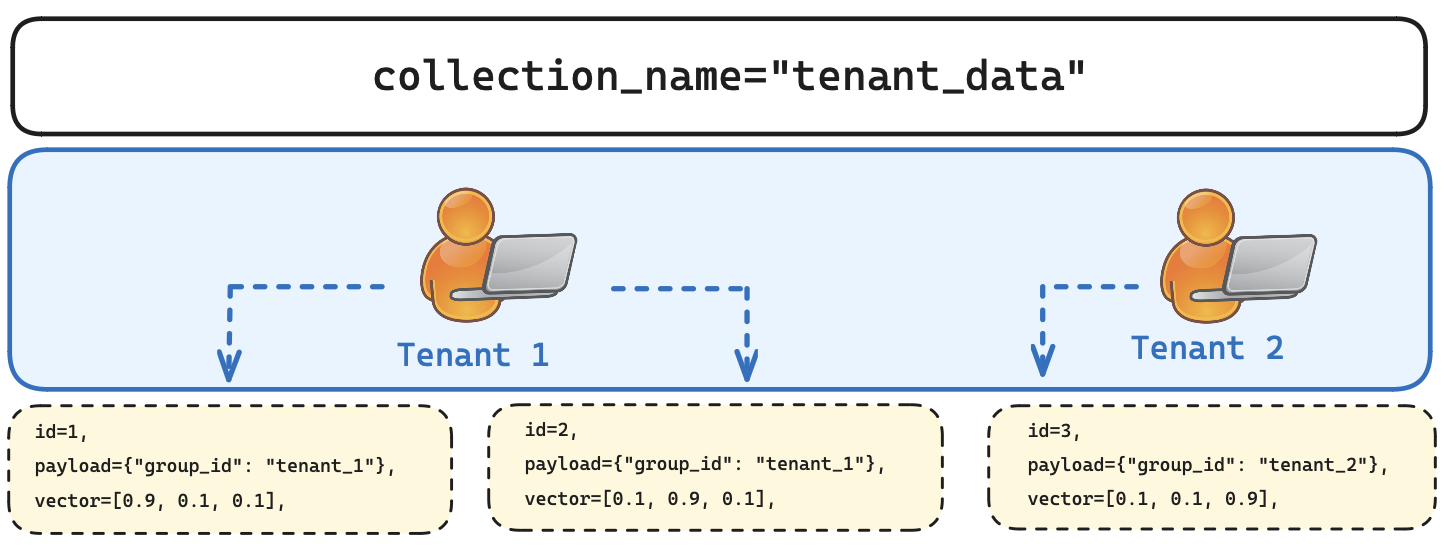
Qdrant 旨在擅长在单个集合中处理大量租户。只有当您的数据不均匀或用户向量是由不同的嵌入模型创建时,才应该创建多个集合。创建过多集合可能会导致资源开销并产生依赖性。这会增加成本并影响整体性能。
分片您的数据库
使用 Qdrant,您还可以为每个向量单独指定一个分片。如果您想控制数据在集群中的存放位置,此功能非常有用。例如,一组向量可以分配到其自己节点上的一个分片,而另一组则可以位于完全不同的节点上。
在向量搜索过程中,您的操作将只触及实际需要的分片子集。在大规模部署中,这可以显著提高那些不需要扫描整个集合的操作的性能。
这也适用于反向操作。无论何时您搜索内容,都可以指定一个或多个分片,Qdrant 将知道在哪里找到它们。它将避免向集群中的所有机器请求结果。这将最大限度地减少开销并最大化性能。
常见用例
此功能的一个明确用例是管理多租户集合,其中每个租户(无论是用户还是组织)都被假定为独立的,因此他们的数据可以存储在单独的分片中。分片解决了基于区域的数据放置问题,某些数据需要保留在特定位置。然而,要做到这一点,您需要在节点之间移动分片。
图 2: 用户可以在同一集合内批量写入和查询与其相关的分片。区域分片有助于避免跨大陆流量。
自定义分片还为您提供了对其他用例的精确控制。基于时间的数据放置意味着数据流可以索引代表最新更新的分片。如果您按日期组织分片,则可以很好地控制检索数据的时效性。这对于社交媒体平台很重要,因为它们高度依赖时间敏感数据。
在我进一步讲解之前……我的用户数据有多安全?
Qdrant 在设计上提供了三个级别的隔离。我们最初引入了基于集合的隔离,但您的扩展设置必须超越这一级别。在此场景中,您将利用基于 payload(载荷)的隔离(来自多租户)和基于资源的隔离(来自分片)。最终目标是拥有一个单一集合,您可以在其中更精确地操作和自定义集群内部的分片放置,并避免任何类型的开销。下图显示了您的数据在两层隔离安排中的布局。
图 3: 用户可以基于两个过滤器查询集合:group_id 和单独的 shard_key_selector。这为您的数据提供了两个额外的隔离级别。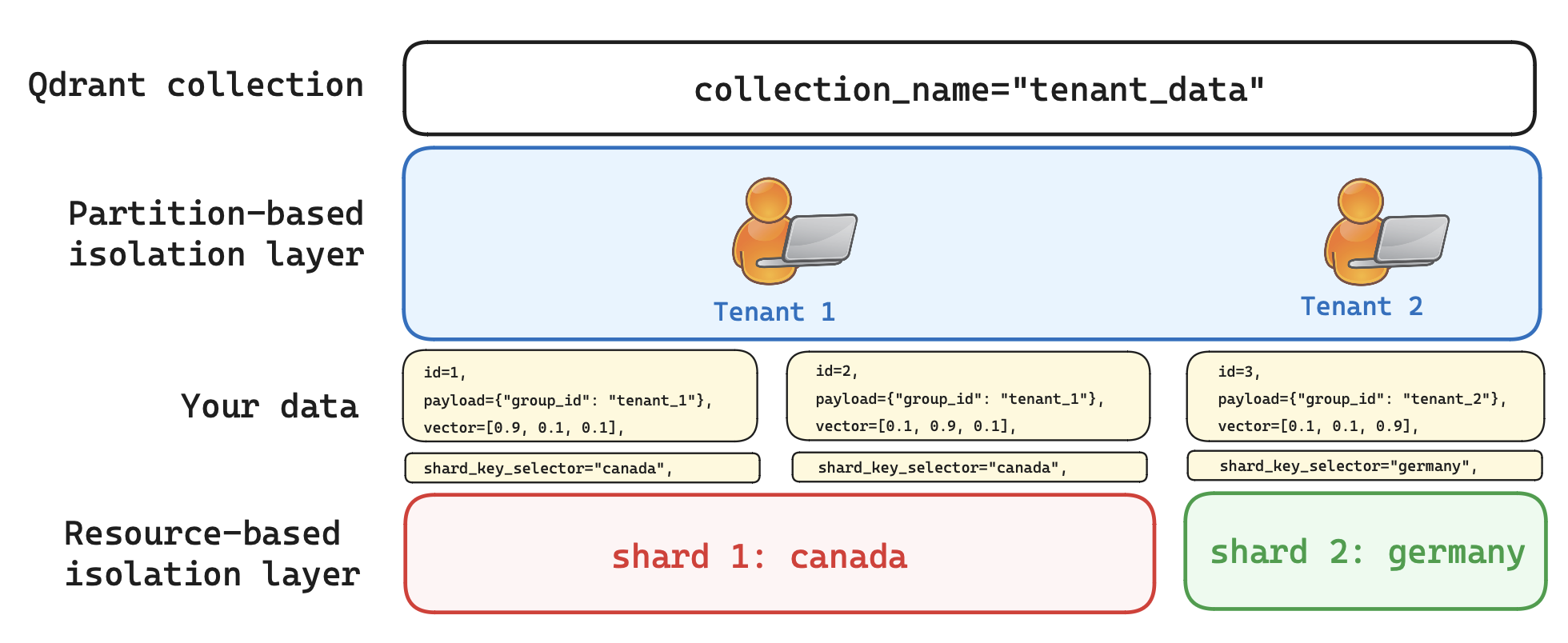
为单个集合创建自定义分片
创建集合时,您需要配置用户自定义分片。这使您可以控制数据的分片放置位置,以便操作仅触及实际需要的分片子集。在大型集群中,这可以显著提高操作性能,因为您无需遍历整个集合来检索数据。
client.create_collection(
collection_name="{tenant_data}",
shard_number=2,
sharding_method=models.ShardingMethod.CUSTOM,
# ... other collection parameters
)
client.create_shard_key("{tenant_data}", "canada")
client.create_shard_key("{tenant_data}", "germany")
在此示例中,您的集群分布在德国和加拿大。在国际数据传输方面,加拿大和德国的法律有所不同。假设您正在创建一个支持医疗保健行业的 RAG 应用。出于合规目的,您的加拿大客户数据必须与您的德国客户数据明确分开。
尽管属于同一集合,每个分片的数据与其他分片是隔离的,并且可以按此方式检索。有关分片和检索的更多示例,请查阅分布式部署文档和Qdrant 客户端规范。
为用户配置多租户设置
让我们继续并开始添加数据。当您将向量批量写入新集合时,可以为每个向量添加一个 group_id 字段。如果您这样做,Qdrant 将为每个向量分配到其相应的组。
此外,现在可以将每个向量分配到一个分片。您可以为每个向量指定 shard_key_selector。在此示例中,您将属于 tenant_1 的数据批量写入加拿大区域。
client.upsert(
collection_name="{tenant_data}",
points=[
models.PointStruct(
id=1,
payload={"group_id": "tenant_1"},
vector=[0.9, 0.1, 0.1],
),
models.PointStruct(
id=2,
payload={"group_id": "tenant_1"},
vector=[0.1, 0.9, 0.1],
),
],
shard_key_selector="canada",
)
请记住,每个 group_id 的数据是隔离的。在下面的示例中,tenant_1 的向量与 tenant_2 的向量是分开存放的。第一个租户将能够访问他们在集群加拿大区域的数据。然而,如下所示,tenant_2 可能只能检索托管在德国的信息。
client.upsert(
collection_name="{tenant_data}",
points=[
models.PointStruct(
id=3,
payload={"group_id": "tenant_2"},
vector=[0.1, 0.1, 0.9],
),
],
shard_key_selector="germany",
)
通过过滤器检索数据
当您指定数据检索条件时,访问控制设置就完成了。搜索向量时,您需要使用 query_filter 和 group_id 来过滤每个用户的向量。
client.search(
collection_name="{tenant_data}",
query_filter=models.Filter(
must=[
models.FieldCondition(
key="group_id",
match=models.MatchValue(
value="tenant_1",
),
),
]
),
query_vector=[0.1, 0.1, 0.9],
limit=10,
)
性能考量
如果您以这种方式添加大量数据,索引速度可能会成为瓶颈,因为每个用户的向量都会被索引到同一个集合中。为了避免此瓶颈,可以考虑绕过整个集合的全局向量索引构建,而仅为单个组构建索引。
通过采用此策略,Qdrant 将为每个用户独立地索引向量,从而显著加快处理速度。
要实现此方法,您应该
- 将 HNSW 配置中的
payload_m设置为一个非零值,例如 16。 - 将 hnsw 配置中的
m设置为 0。这将禁用为整个集合构建全局索引。
from qdrant_client import QdrantClient, models
client = QdrantClient("localhost", port=6333)
client.create_collection(
collection_name="{tenant_data}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
hnsw_config=models.HnswConfigDiff(
payload_m=16,
m=0,
),
)
- 为
group_id字段创建关键字 payload 索引。
client.create_payload_index(
collection_name="{tenant_data}",
field_name="group_id",
field_schema=models.PayloadSchemaType.KEYWORD,
)
注意:请记住,全局请求(不带
group_id过滤器)会较慢,因为它们需要扫描所有组才能找到最近邻。
探索 Qdrant 中的多租户和自定义分片,实现可扩展解决方案
Qdrant 已准备好为您的机器学习项目支持大规模架构。如果您想了解我们的向量数据库是否适合您,请尝试快速入门教程或阅读我们的文档和教程。
要启动免费的 Qdrant 实例,请注册Qdrant Cloud - 无需绑定信用卡。
在我们的Discord社区中获得支持或分享想法。在这里,我们讨论向量搜索理论,发布示例和演示,并讨论向量数据库设置。