
什么是 MUVERA 嵌入?
在许多基准测试中,多向量表示优于单向量嵌入。你可能很想立即使用它们,但有一个问题:它们的搜索速度较慢。传统的向量搜索结构,如HNSW,针对使用余弦相似度等简单指标检索单个查询向量的最近邻进行了优化。这些索引不适用于多向量检索策略,例如 MaxSim。在 MaxSim 中,查询和文档都由多个向量表示,最终分数通过所有交叉配对的最大相似度计算得出。MaxSim 本质上是不对称和非度量的,因此 HNSW 可能会帮助我们找到给定查询词元最接近的文档词元,但这并不意味着整个文档是查询的最佳匹配。
MUVERA 嵌入,由 Google Research 引入,旨在解决这个问题。其理念是创建一个近似多向量表示的单个向量。这个单向量可以用于使用传统向量搜索方法进行快速初始检索,然后多向量表示可以用于对顶部结果进行重排序。这种方法结合了单向量搜索的速度和多向量检索的准确性。当应用于一小组候选对象而不是整个数据集时,使用多向量表示进行重排序会快得多。
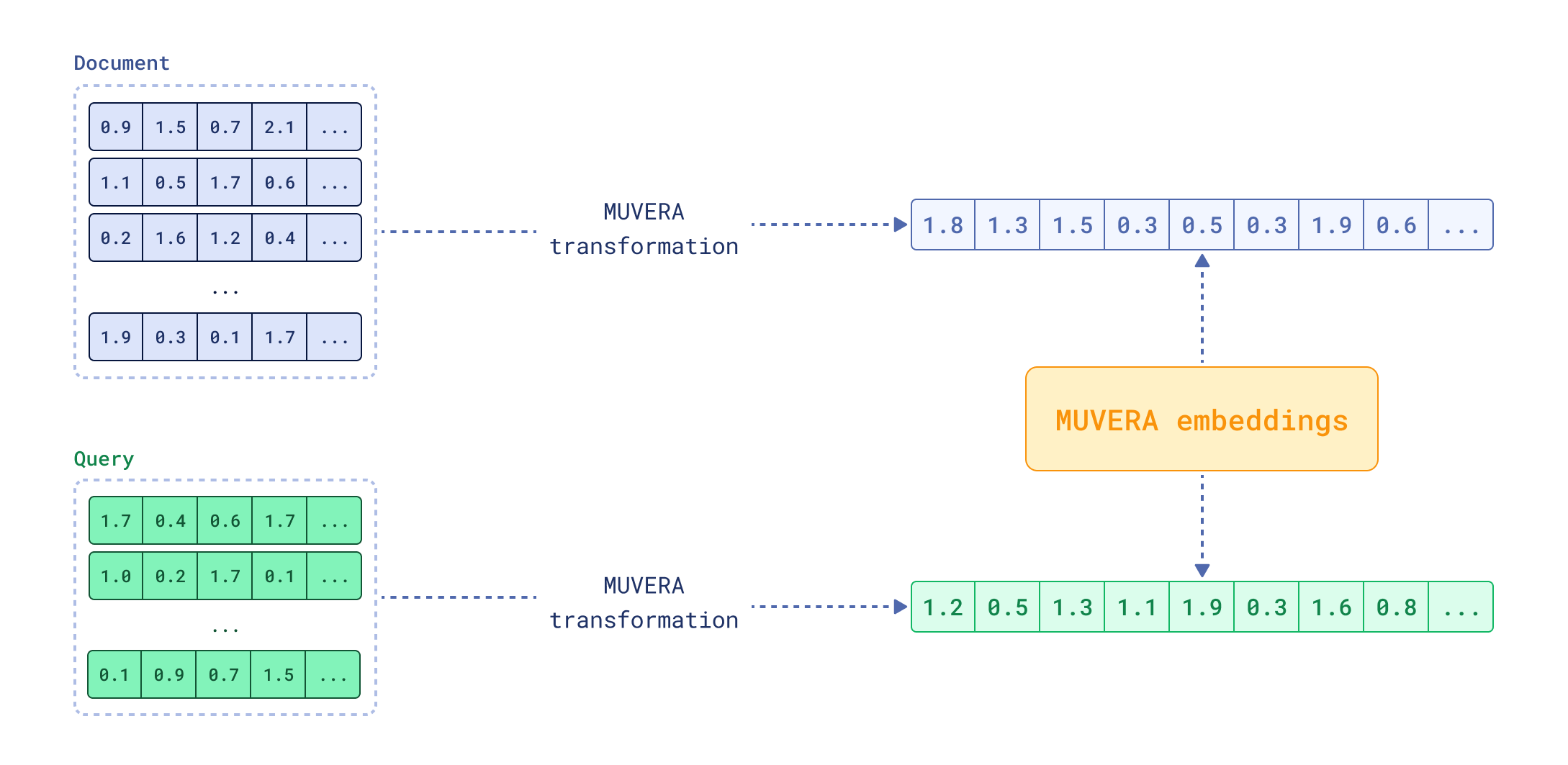
FastEmbed 0.7.2 引入了对 MUVERA 嵌入的支持,本文将详细解释这一概念。
MUVERA 嵌入是如何创建的
MUVERA (Multi-Vector Retrieval Algorithm) 将可变长度的向量序列转换为固定维度的表示。由于输入中向量的数量在文档和查询之间是变化的,甚至在不同文档之间也可能不同,我们需要一种通用的方法来以固定大小的格式表示它们。对词元的向量空间进行聚类,并使用创建的聚类将单个多向量表示投影到较低维空间,有助于实现这一点。MUVERA 论文的作者建议使用称为 SimHash 的局部敏感哈希 (LSH) 技术。
参数词汇表
有几个参数控制 MUVERA 嵌入的创建过程,为了避免混淆,这里对它们进行快速定义
dim:原始多向量表示中单个词元向量的维度,取决于所使用的模型k_sim:SimHash 中使用的随机超平面数量,它决定了聚类数量为2^k_simdim_proj:随机投影后投影向量的维度r_reps:SimHash 投影和随机投影过程的独立重复次数
用于聚类的 SimHash 投影
SimHash 是一种 LSH 技术,它使用随机超平面将输入向量哈希到二进制代码中。在第一步中,此方法从标准正态分布中选择 k_sim 个随机超平面(法向量)。这些超平面将向量空间划分为 2^k_sim 个区域,因为每个向量都可以位于每个超平面的任一侧。以下是 k_sim=3 时这种空间划分可能的样子
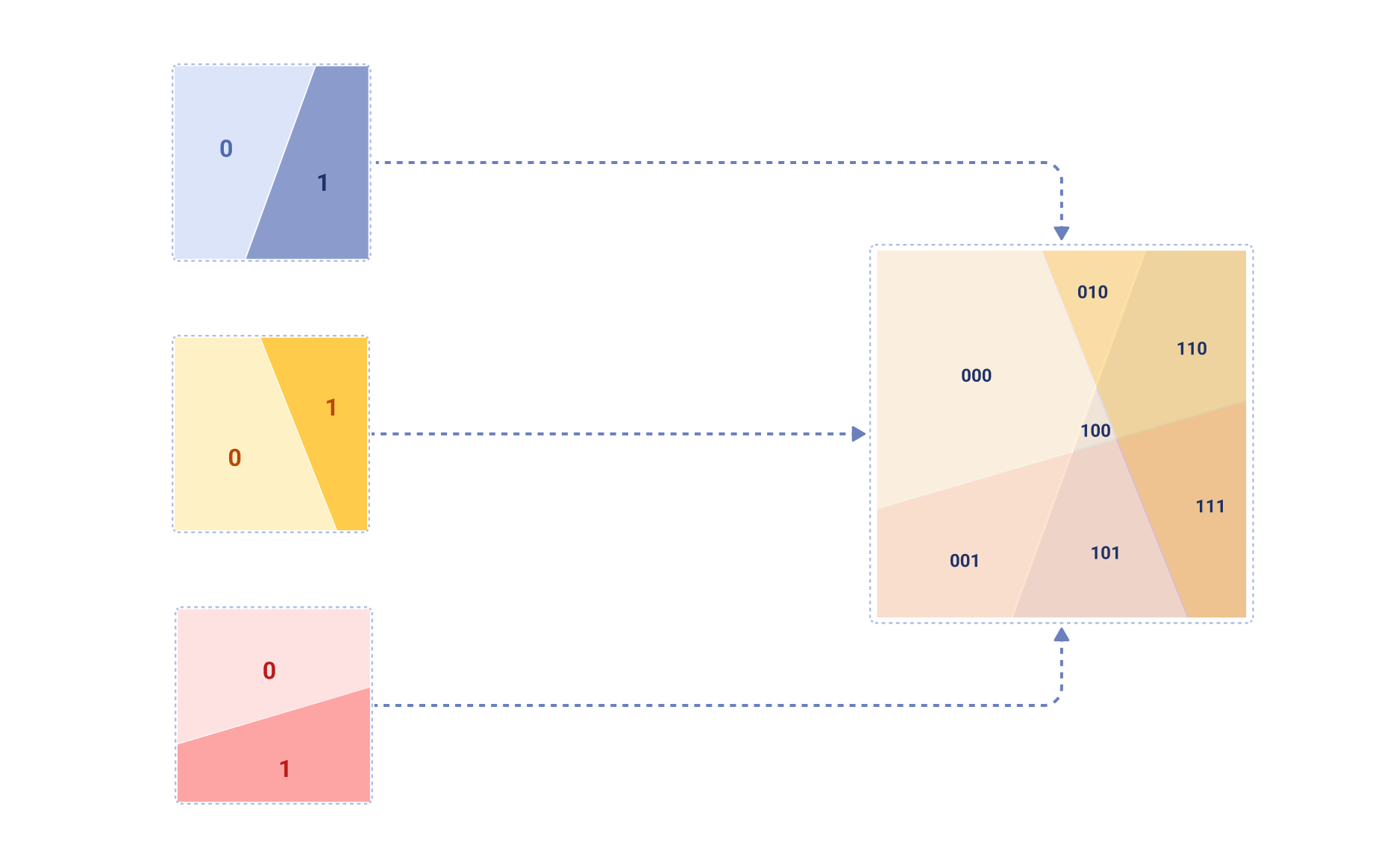
现在,根据每个词元向量落在每个超平面的哪一侧,将其分配到这些区域之一。这是通过计算输入向量与每个超平面法向量的点积,并取每个结果的符号来完成的。由于我们的每个区域都可以表示为长度为 k_sim 的二进制字符串(其中每个位表示向量位于超平面的哪一侧),我们可以将此二进制字符串解释为整数以获取聚类 ID。
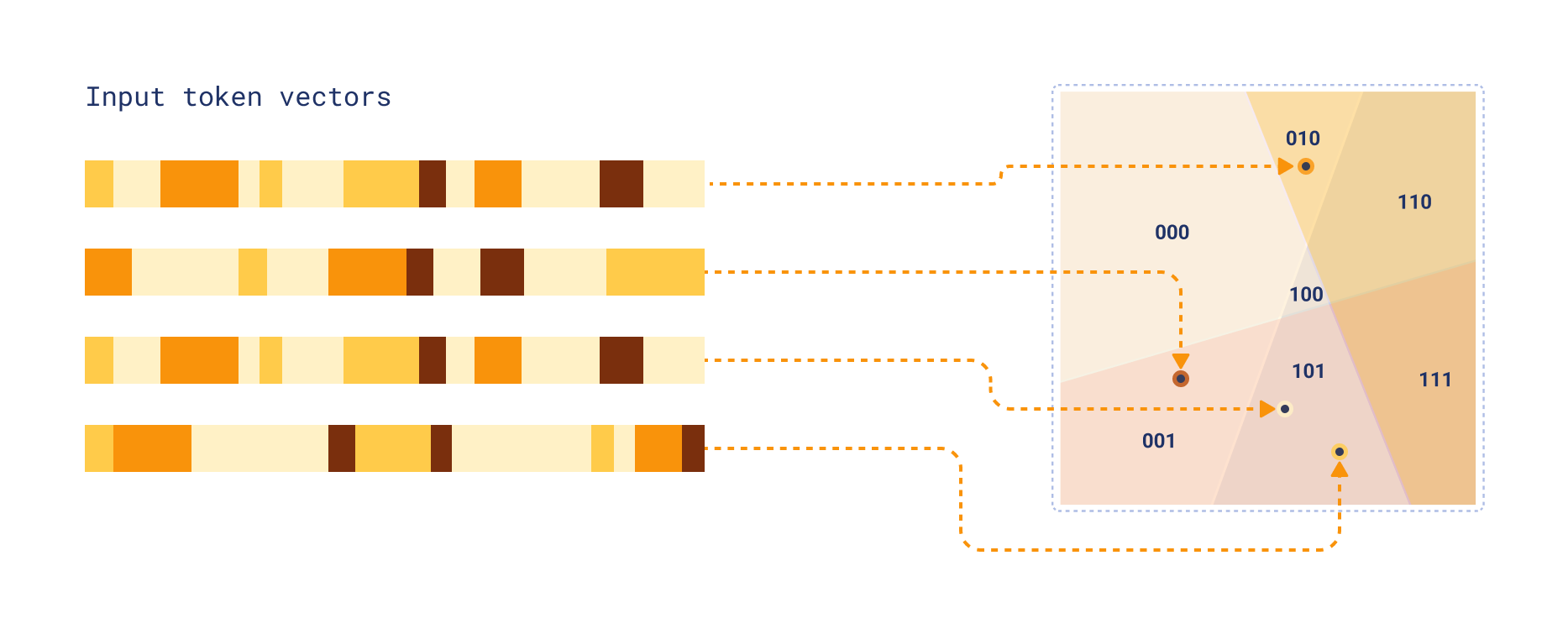
固定维度编码 (FDE) 创建
一旦所有输入向量都分配到聚类中,我们就可以聚合属于每个聚类的向量。这个过程对于文档和查询略有不同。在两种情况下,我们都会得到一个具有相同维度的固定维度向量,但计算这些向量的方式有所不同。
文档聚类
一旦我们将所有文档词元向量分配到聚类中,我们通过对每个聚类中的所有向量求平均来计算聚类质心。这为每个聚类提供了一个代表向量。如果一个聚类最终为空(即没有向量被分配到它),我们使用最近的非空聚类的向量来填充它。聚类之间的距离由它们的聚类 ID 之间的汉明距离决定。
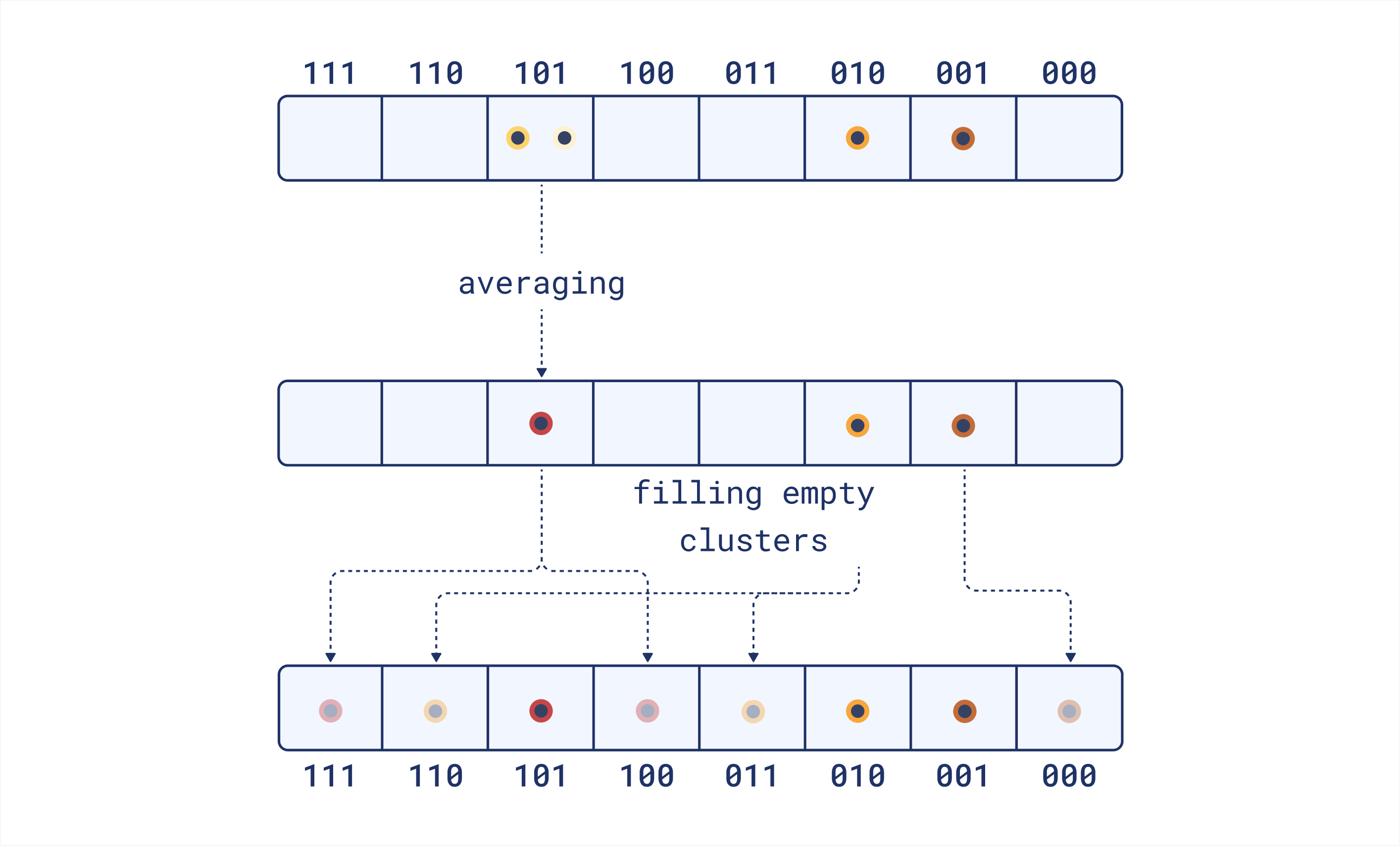
结果我们得到 2^k_sim 个向量,每个向量都是 dim 维的。
查询聚类
查询处理略有不同。我们不是计算每个聚类的平均向量,而是计算每个聚类中所有向量的和。这意味着对于分配了更多向量的聚类,生成的向量将具有更大的幅度。这个想法是它保留了查询词元的自然分布,这对于检索可能是有益的。与文档不同,我们不为查询填充空聚类。查询通常比文档短,因此一些聚类为空的可能性更大。填充它们可能会引入噪声并扭曲表示,因为每个词元都会多次贡献于点积。
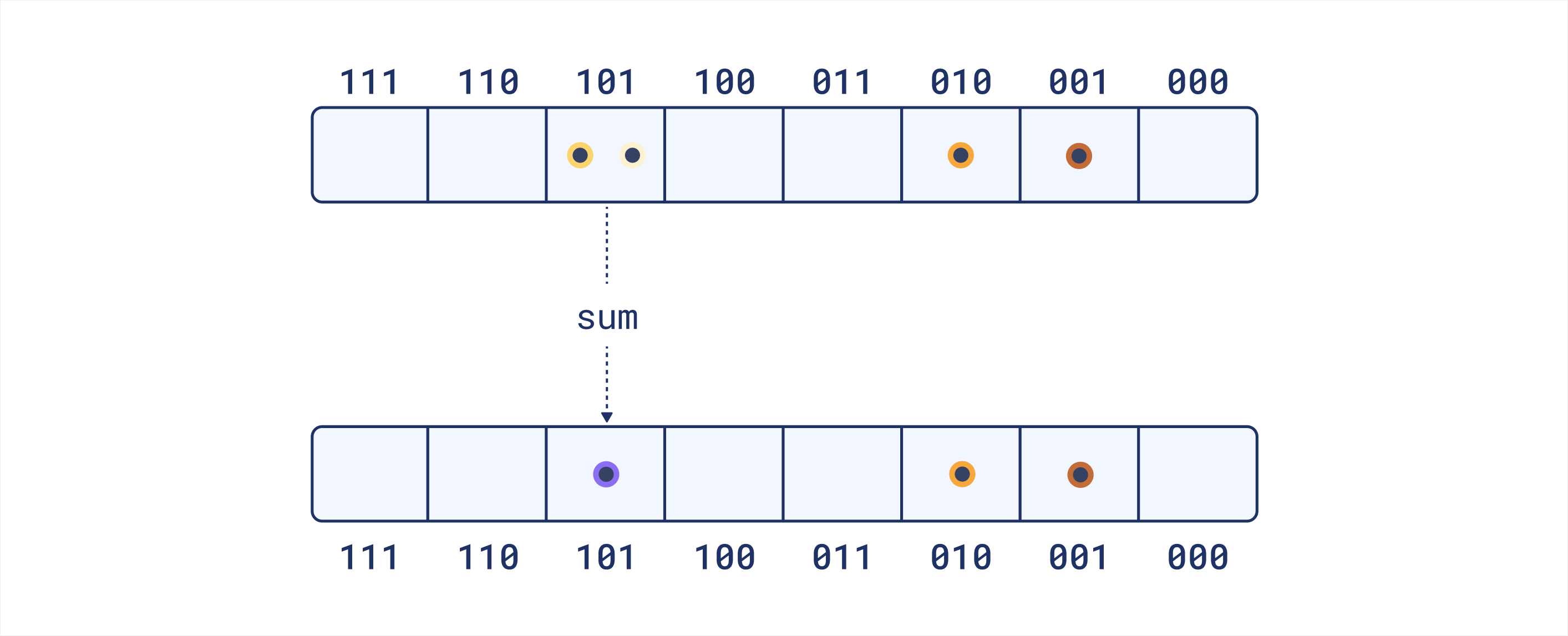
同样,我们得到 2^k_sim 个大小为 dim 的向量。因为我们不填充空聚类,所以其中一些向量可能是零向量。
通过随机投影进行降维
该论文报告了 k_sim 值为 4 和 5 的实验结果。实际上,这意味着分别有 16 或 32 个聚类。如果原始词元向量的维度为 128,则生成的 FDE 的维度将为 16 * 128 = 2048 或 32 * 128 = 4096。然而,单个 SimHash 投影仅使用 4 或 5 个超平面可能无法捕获足够的输入向量信息。为了提高 FDE 的质量,作者建议通过独立的 SimHash 投影重复该过程多次并连接结果。实际上,如果 r_reps=20 次重复,我们将得到大小为 20 * 16 * 128 = 40960 或 20 * 32 * 128 = 81920 的 FDE,这相当大,可能会显著降低单向量搜索的速度。因此,作者建议应用随机投影来降低每个 FDE 的维度。这包括将每个聚类向量乘以一个由 {-1, +1} 组成的随机矩阵,并应用一个 1/√(dim_proj) 的缩放因子。这个矩阵的形状为 (dim, dim_proj),其中 dim_proj 是投影向量所需的维度。生成的 FDE 的大小将为 r_reps * 2^k_sim * dim_proj。
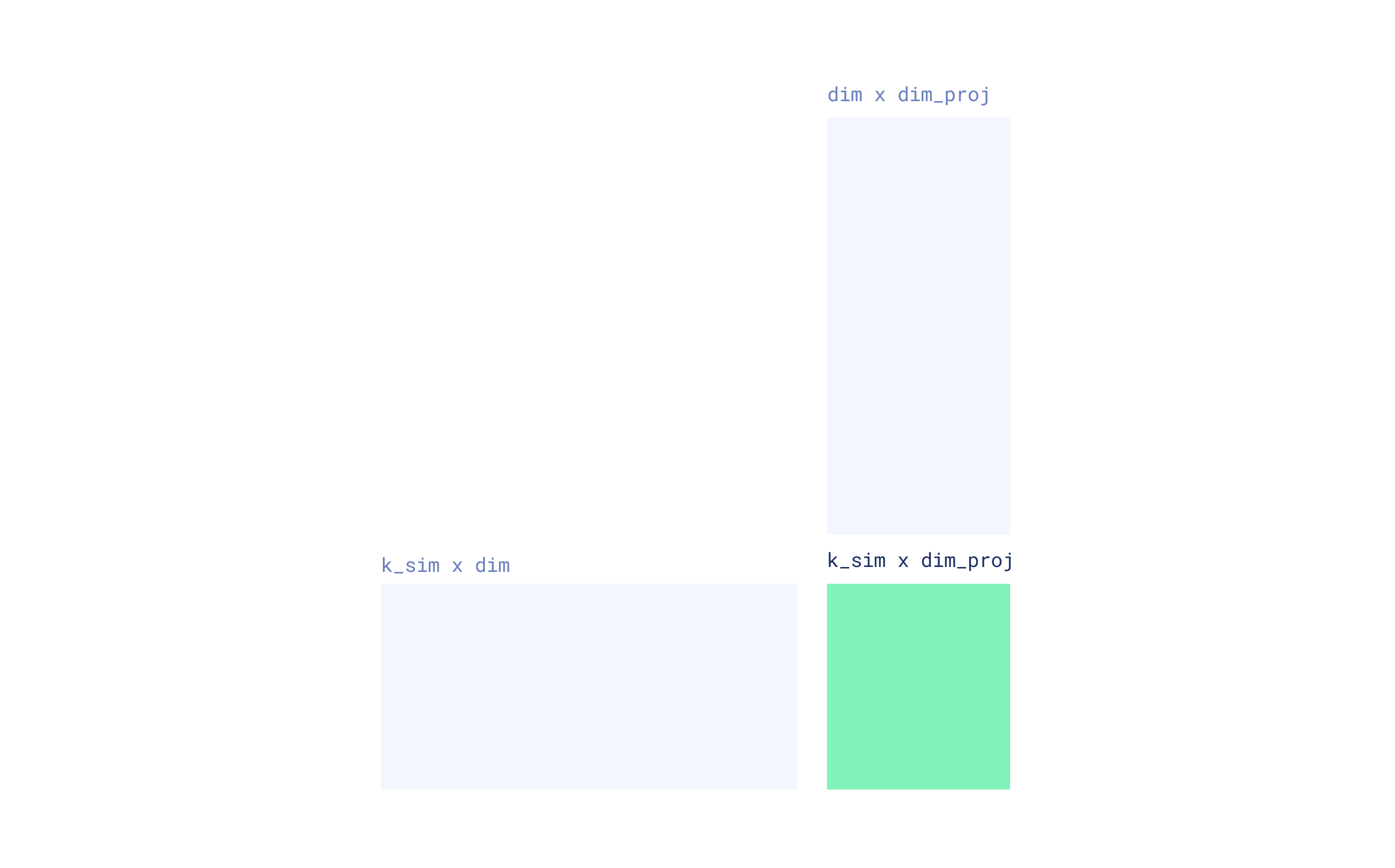
然后将所有重复的结果连接起来形成最终的 FDE。这种重复有助于创建更鲁棒的表示,更好地近似原始多向量嵌入。
最终随机投影
原始论文建议对最终的 FDE 应用额外的随机投影,以进一步降低其维度。这是一个可选步骤,如果生成的 FDE 仍然太大,可以使用它。这个最终投影使用另一个由 {-1, +1} 组成的随机矩阵将 FDE 投影到所需的较低维度。
实际考虑
MUVERA 嵌入似乎是一种很有前途的方法,可以提高多向量检索的效率。论文建议将其用作初始检索步骤,然后使用原始多向量表示进行重排序。这种方法需要同时存储 MUVERA 嵌入和原始多向量表示,这会增加存储需求。
请注意,MUVERA 嵌入可能比你习惯的传统嵌入模型生成的单个密集向量大得多。例如,使用 k_sim=6(64 个聚类)、dim_proj=32 和 r_reps=20 以及 128 维词元向量会导致大小为 20 * 64 * 32 = 40960 的 FDE。这明显大于典型的单向量嵌入,后者最多只有几千维。MUVERA 嵌入尺寸的增加可能会影响存储和检索效率,因此在决定使用它们时考虑这些因素很重要。
对搜索性能的影响
为了评估 MUVERA 嵌入的有效性,我们使用 ColBERTv2 模型在 BeIR nfcorpus 数据集上对三种不同方法进行了基准测试。MUVERA 配置使用了以下参数:k_sim=5、dim_proj=16 和 r_reps=20
| 方法 | NDCG@1 | NDCG@5 | NDCG@10 |
|---|---|---|---|
| 全多向量(ColBERT) | 0.478 | 0.387 | 0.347 |
| 仅 MUVERA | 0.319 | 0.267 | 0.242 |
| MUVERA + 重排序 | 0.475 | 0.383 | 0.343 |
结果表明,仅 MUVERA 搜索以牺牲一些准确性来换取速度,实现了全多向量性能的约 70%。然而,使用 MUVERA 进行初始检索,然后进行多向量重排序,几乎恢复了所有原始性能,同时在初始搜索阶段保持了效率优势。
当你考虑到搜索延迟的改进时,这变得尤其有趣。在我们的基准测试中,我们观察到显著的速度提升
| 方法 | 平均搜索时间(秒) |
|---|---|
| 全多向量(ColBERT) | 1.27 |
| 仅 MUVERA | 0.15 |
| MUVERA + 重排序 | 0.18 |
仅 MUVERA 搜索比全多向量搜索快约 8 倍,而带有重排序的混合方法仍然实现了约 7 倍的速度提升,同时保持了几乎相同的搜索质量。
FastEmbed 中的 MUVERA
FastEmbed 提供后期交互文本 (ColBERT) 和多模态 (ColPali) 嵌入。0.7.2 版本引入了对 MUVERA 嵌入的支持,它与任何多向量表示兼容,并可作为后处理步骤使用。
import numpy as np
from fastembed import LateInteractionTextEmbedding
from fastembed.postprocess import Muvera
# Create a multi-vector model (ColBERT in this case) and then wrap it with MUVERA
model = LateInteractionTextEmbedding(model_name="colbert-ir/colbertv2.0")
muvera = Muvera.from_multivector_model(
model=model,
k_sim=6,
dim_proj=32,
r_reps=20
)
# Create embeddings of the sample text and then process them with MUVERA
embeddings = np.array(list(model.embed(["sample text"])))
fde = muvera.process_document(embeddings[0])
立即试用
如果你已经在使用多向量检索,升级到 FastEmbed 0.7.2+ 将解锁 MUVERA 7 倍的速度提升,同时保持几乎相同的搜索质量。如果你一直想尝试多向量检索,但又因性能问题或复杂性而却步,现在是开始的最佳时机。MUVERA 消除了这些传统障碍,使高级检索技术可用于生产环境并实用。只需使用 pip install --upgrade fastembed 升级你的 FastEmbed 安装,即可从多向量搜索的强大功能中获益,而无需承担传统的速度损失。