
RAG已死?向量数据库在AI效率和向量搜索中的作用
当Anthropic推出10万个token的上下文窗口时,他们说:“向量搜索已死。大型语言模型(LLMs)将变得越来越准确,不再需要RAG。”
谷歌的Gemini 1.5现在提供了1000万个token的上下文窗口。他们的支持论文声称解决了准确性问题,即使在使用Greg Kamradt的NIAH方法论时也是如此。
一切都结束了。RAG(检索增强生成)现在肯定已经完全过时了。对吗?
不。
更大的上下文窗口绝不是解决方案。我再说一遍。绝不是。它们需要更多的计算资源,并导致更慢的处理时间。
社区已经在对Gemini 1.5进行压力测试

这并不令人意外。LLMs需要大量的计算和内存才能运行。引用Grant的话,单独运行这样一个模型“每生成一个完成,就会耗尽一个小煤矿”。此外,谁会等待30秒的响应呢?
上下文填充不是解决方案
依赖上下文成本高昂,并且在实际应用中并不能提高响应质量。基于向量搜索的检索提供了更高的精度。
如果您完全依赖LLM来完善检索和精度,那么您就做错了。
大上下文窗口使得难以集中于相关信息。这增加了其响应中出现错误或幻觉的风险。
谷歌发现Gemini 1.5在较短上下文长度下比GPT-4显著更准确,并且“在接近100万个token时召回率略有下降”。召回率仍然低于0.8。
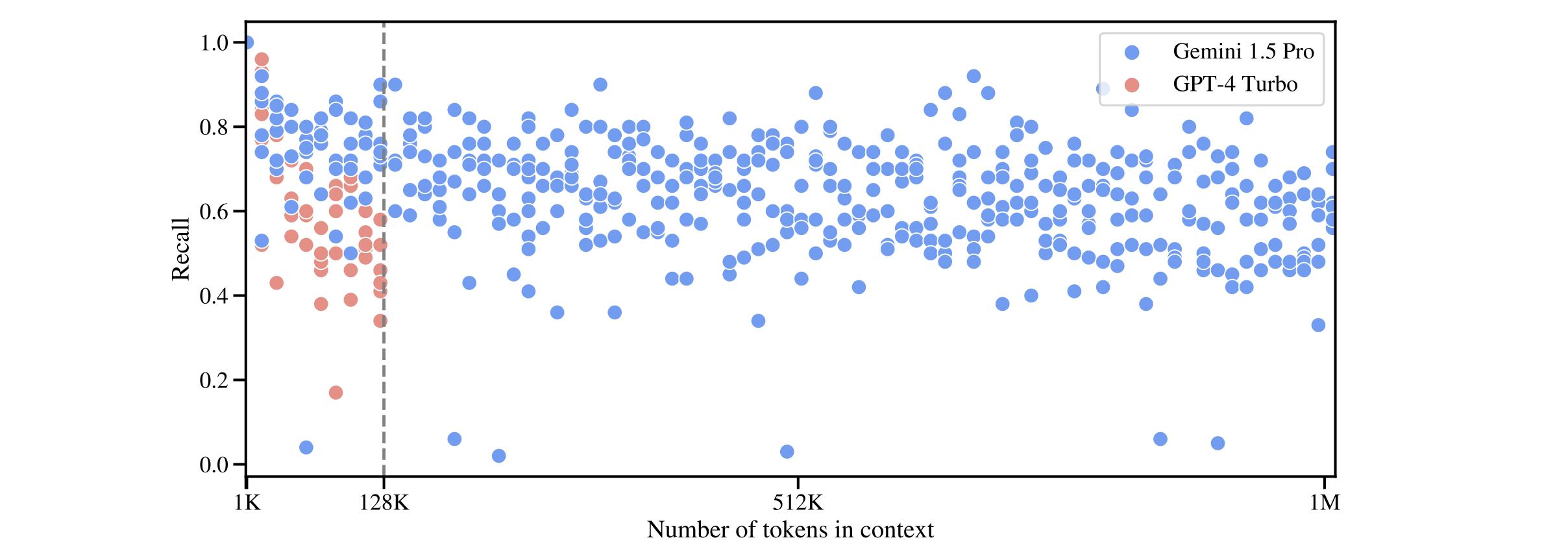
我们认为60-80%还不够好。LLM可能在其上下文窗口中检索到足够多的相关事实,但它仍然会丢失多达40%的可用信息。
向量搜索的全部意义在于通过高效地选择应用程序生成最佳响应所需的信息来规避这个过程。向量数据库保持计算负载低,查询响应快。您根本不需要等待LLM。
Qdrant的基准测试结果强烈支持准确性和效率。我们建议您在决定LLM是否足够之前考虑它们。查看我们的开源基准测试报告并自己尝试这些测试。
复合系统中的向量搜索
人工智能的未来在于精心的系统工程。根据Zaharia等人的研究,Databricks的结果发现“60%的LLM应用程序使用某种形式的RAG,而30%使用多步链。”
即使是Gemini 1.5也证明了复杂策略的必要性。在查看谷歌的MMLU基准测试时,该模型被调用了32次才达到90.0%的准确率。这表明即使是基本的复合安排也优于单一模型。
作为检索系统,向量数据库完美契合复合系统的需求。将它们引入您的设计为LLMs的卓越应用开辟了可能性。它之所以卓越,是因为它更快、更准确,并且运行成本更低。
RAG的关键优势在于它允许LLM从最新的内部和外部知识源中获取实时信息,使其更具动态性,并能适应新信息。——Oliver Molander,IMAGINAI首席执行官
Qdrant可扩展到企业RAG场景
人们仍然不理解向量数据库的经济效益。为什么大型企业AI系统需要像Qdrant这样的独立向量数据库?在我们看来,这是最重要的问题。让我们假设LLMs完全不再受到上下文阈值的困扰。
这一切将花费多少钱?
如果您在企业环境中运行RAG解决方案,拥有数PB的私有数据,您的计算账单将是难以想象的。假设每1000个输入token花费1美分(这是当前GPT-4 Turbo的定价)。无论您做什么,每深入10万个token,您将花费1美元。
那是一个问题一美元。
根据我们的估计,向量搜索查询至少比LLMs进行的查询便宜1亿倍。
相反,向量数据库唯一的前期投资是索引(这需要更多的计算)。此步骤之后,其他一切都轻而易举。一旦设置好,Qdrant可以通过多租户和分片等功能轻松扩展。这使您可以扩大对向量检索过程的依赖,并最大限度地减少对计算密集型LLMs的使用。作为一种优化措施,Qdrant是无可替代的。
HuggingFace的Julien Simon说得最好
RAG不是有限上下文大小的权宜之计。对于关键任务的企业用例,RAG是一种利用高价值、专有公司知识的方式,这些知识永远不会在用于LLM训练的公共数据集中找到。目前,索引和查询这些知识的最佳位置是某种向量索引。此外,RAG将LLM降级为写作助手。由于内置知识变得不那么重要,一个不错的7B小型开源模型通常可以以巨大通用模型一小部分的成本完成任务。
使用Qdrant的向量数据库获得卓越的准确性
随着LLMs继续需要巨大的计算能力,用户将需要利用向量搜索和RAG。
我们的客户每天都在提醒我们这一事实。作为一款产品,我们的向量数据库具有高度可扩展性和业务友好性。我们战略性地开发我们的功能,以遵循我们公司的Unix哲学。
我们希望Qdrant保持紧凑、高效和目的明确。这个目的是让我们的客户能够根据自己的需求随意使用它。
当大型企业将其生成式AI投入生产时,他们需要在控制成本的同时,保持尽可能最佳的响应质量。Qdrant拥有向量搜索解决方案,可以做到这一点。彻底改变您的向量搜索能力,并从Qdrant演示开始。