
在当今快节奏、信息丰富的世界中,AI 正在彻底改变知识管理。在组织内部捕获、分发和有效利用知识的系统过程是 AI 今天提供卓越价值的领域之一。
当利用检索增强生成 (RAG) 时,AI 驱动的知识管理的潜力会增加。RAG 是一种方法,它使 LLM 能够访问来自知识存储(如向量数据库)的庞大、多样化的事实信息库。
这个过程增强了生成文本的准确性、相关性和可靠性,从而减轻了有时与传统 LLM 相关的错误、不正确或无意义结果的风险。这种方法不仅确保答案与上下文相关,而且是最新、最准确的,反映了最新的见解和可用数据。
虽然 RAG 增强了传统 LLM 解决方案的准确性、相关性和可靠性,但评估策略可以进一步帮助团队确保他们的 AI 产品达到这些成功基准。
本次实验的相关工具
在本文中,我们将分解一个 RAG 优化工作流实验,该实验表明评估对于构建成功的 RAG 策略至关重要。我们将在此实验中使用 Qdrant 和 Quotient。
Qdrant 是一个向量数据库和向量相似性搜索引擎,旨在高效存储和检索高维向量。由于 Qdrant 提供高效的索引和搜索功能,因此它非常适合实现 RAG 解决方案,在这些解决方案中,从超大型数据集中快速准确地检索相关信息至关重要。Qdrant 还提供了大量附加功能,例如量化、多向量支持和多租户。
除了 Qdrant,我们还将使用 Quotient,它提供了一种无缝评估 RAG 实现的方法,从而加速和改进实验过程。
Quotient 是一个平台,为 AI 开发人员提供工具来构建评估框架并对他们的产品进行实验。评估是团队发现其应用程序的缺点并提高关键基准(如忠实度和语义相似性)性能的方式。迭代是构建创新 AI 产品以向最终用户交付价值的关键。
💡 本练习的配套笔记本可在 GitHub 上找到,以供将来参考。
主要发现总结
- 不相关性和幻觉:当检索到的文档不相关时(表现为块相关性和上下文相关性得分较低),模型容易生成不准确或虚构的信息。
- 优化文档检索:通过检索更多的文档并减小块大小,我们观察到模型性能有所改善。
- 自适应检索需求:某些查询可能需要访问更多文档。实施基于查询进行调整的动态检索策略可以提高准确性。
- 模型和提示变化的影响:语言模型或所用提示的改变会显著影响生成响应的质量,这表明微调这些元素可以优化性能。
让我们带您了解我们是如何得出这些发现的!
构建 RAG 管道
要评估 RAG 管道,我们首先必须构建一个 RAG 管道。为了简单起见,本文中我们构建了一个朴素 RAG。当然还有其他版本的 RAG
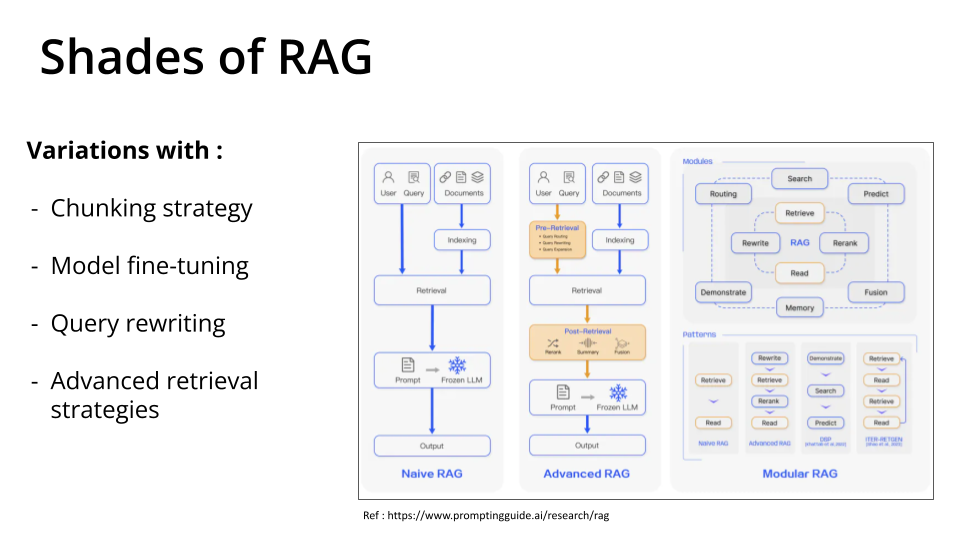
下图描述了我们如何利用RAG 评估框架来评估 RAG 应用程序的质量。
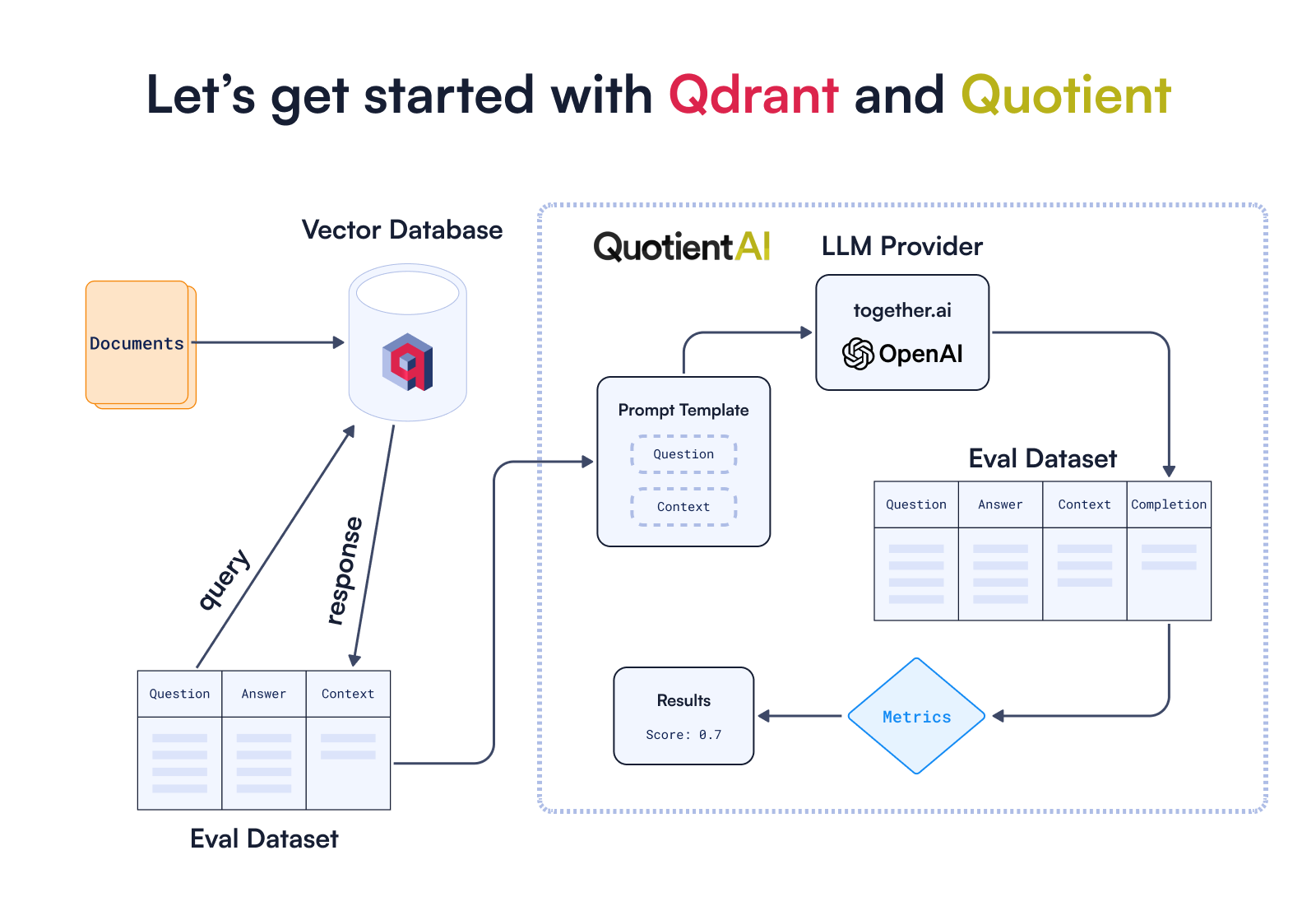
我们将使用 Qdrant 的文档和预先准备好的hugging face 数据集来构建一个 RAG 应用程序。然后,我们将评估我们的 RAG 应用程序回答关于 Qdrant 的问题的能力。
为了准备我们的知识库,我们将使用 Qdrant,它可以通过以下 3 种不同方式利用
client = qdrant_client.QdrantClient(
os.environ.get("QDRANT_URL"),
api_key=os.environ.get("QDRANT_API_KEY"),
)
我们将使用Qdrant Cloud,因此最好将QDRANT_URL和QDRANT_API_KEY作为环境变量提供,以便更轻松地访问。
接下来,我们需要将集合名称定义为
COLLECTION_NAME = "qdrant-docs-quotient"
在这种情况下,我们可能需要根据我们进行的实验创建不同的集合。
为了帮助我们在整个实验中无缝创建嵌入,我们将使用 Qdrant 自己的嵌入库Fastembed,它支持许多不同的模型,包括密集和稀疏向量模型。
在实现 RAG 之前,我们需要准备数据并在 Qdrant 中建立索引。
这涉及使用合适的编码器(例如,句子转换器)将文本数据转换为向量,并将这些向量存储在 Qdrant 中以供检索。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LangchainDocument
## Load the dataset with qdrant documentation
dataset = load_dataset("atitaarora/qdrant_doc", split="train")
## Dataset to langchain document
langchain_docs = [
LangchainDocument(page_content=doc["text"], metadata={"source": doc["source"]})
for doc in dataset
]
len(langchain_docs)
#Outputs
#240
您可以如下预览数据集中的文档
## Here's an example of what a document in our dataset looks like
print(dataset[100]['text'])
评估数据集
为了衡量 RAG 设置的质量,我们需要一个具有代表性的评估数据集。此数据集应包含实际问题和预期答案。
此外,包含您的 RAG 管道旨在检索信息的预期上下文将是有益的。
我们将使用一个预构建评估数据集。
如果您正在努力为您的用例构建评估数据集,您可以使用您的文档和此笔记本中描述的一些技术。
构建 RAG 管道
我们建立 RAG 管道所需的数据预处理参数,并根据指定标准配置 Qdrant 向量数据库。
正在考虑的关键参数是
- 块大小
- 块重叠
- 嵌入模型
- 检索到的文档数量(检索窗口)
在 Qdrant 中摄取数据后,我们继续检索与每个查询相关的文档。然后,这些文档无缝集成到我们的评估数据集中,丰富了指定上下文列中的上下文信息,以实现评估方面。
接下来我们定义方法来处理在我们的 RAG 管道评估期间向 Qdrant 添加文档的后勤工作
import uuid
from qdrant_client import models
def add_documents(client, collection_name, chunk_size, chunk_overlap, embedding_model_name):
"""
This function adds documents to the desired Qdrant collection given the specified RAG parameters.
"""
## Processing each document with desired TEXT_SPLITTER_ALGO, CHUNK_SIZE, CHUNK_OVERLAP
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
add_start_index=True,
separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = []
for doc in langchain_docs:
docs_processed += text_splitter.split_documents([doc])
## Processing documents to be encoded by Fastembed
docs_contents = []
docs_metadatas = []
for doc in docs_processed:
if hasattr(doc, 'page_content') and hasattr(doc, 'metadata'):
docs_contents.append(doc.page_content)
docs_metadatas.append(doc.metadata)
else:
# Handle the case where attributes are missing
print("Warning: Some documents do not have 'page_content' or 'metadata' attributes.")
print("processed: ", len(docs_processed))
print("content: ", len(docs_contents))
print("metadata: ", len(docs_metadatas))
if not client.collection_exists(collection_name):
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(size=384, distance=models.Distance.COSINE),
)
client.upsert(
collection_name=collection_name,
points=[
models.PointStruct(
id=uuid.uuid4().hex,
vector=models.Document(text=content, model=embedding_model_name),
payload={"metadata": metadata, "document": content},
)
for metadata, content in zip(docs_metadatas, docs_contents)
],
)
以及从 Qdrant 检索文档。
def get_documents(collection_name, query, num_documents=3):
"""
This function retrieves the desired number of documents from the Qdrant collection given a query.
It returns a list of the retrieved documents.
"""
search_results = client.query_points(
collection_name=collection_name,
query=models.Document(text=query, model=embedding_model_name),
limit=num_documents,
).points
results = [r.payload["document"] for r in search_results]
return results
设置 Quotient
您将需要一个帐户登录,您可以通过在Quotient 网站上请求访问来获得。一旦您拥有帐户,您可以通过运行quotient authenticate CLI 命令来创建 API 密钥。
获得 API 密钥后,请务必将其设置为名为QUOTIENT_API_KEY的环境变量
# Import QuotientAI client and connect to QuotientAI
from quotientai.client import QuotientClient
from quotientai.utils import show_job_progress
# IMPORTANT: be sure to set your API key as an environment variable called QUOTIENT_API_KEY
# You will need this set before running the code below. You may also uncomment the following line and insert your API key:
# os.environ['QUOTIENT_API_KEY'] = "YOUR_API_KEY"
quotient = QuotientClient()
QuotientAI 提供了一种将RAG 评估无缝集成到您的应用程序中的方法。在这里,我们将了解如何使用它来评估基于从 Qdrant 向量数据库检索到的知识而由 LLM 生成的文本。
检索到最相似的文档并填充context列后,我们可以将评估数据集提交给 Quotient 并执行评估作业。要运行作业,您只需要评估数据集和recipe。
配方是提示模板和指定 LLM 的组合。
Quotient 在整个实验过程中协调评估运行并处理版本控制和资产管理。
在评估我们的 RAG 解决方案之前,确定我们的优化目标至关重要。
在Qdrant 文档问答的背景下,我们的重点不仅限于提供有用的答案。确保没有任何不准确或误导性信息至关重要。
换句话说,我们希望最大限度地减少 LLM 输出中的幻觉。
为了进行评估,我们将考虑以下指标,重点关注忠实度
- 上下文相关性
- 块相关性
- 忠实度
- ROUGE-L
- BERT 句子相似度
- BERTScore
评估实践
下面的函数将评估数据集作为输入,该数据集在这种情况下包含问题及其对应的答案。它根据数据集中的问题检索相关文档,并用 Qdrant 的这些信息填充上下文字段。然后将准备好的数据集提交给 QuotientAI 以评估所选指标。评估完成后,该函数显示评估指标的聚合统计数据,然后显示汇总的评估结果。
def run_eval(eval_df, collection_name, recipe_id, num_docs=3, path="eval_dataset_qdrant_questions.csv"):
"""
This function evaluates the performance of a complete RAG pipeline on a given evaluation dataset.
Given an evaluation dataset (containing questions and ground truth answers),
this function retrieves relevant documents, populates the context field, and submits the dataset to QuotientAI for evaluation.
Once the evaluation is complete, aggregated statistics on the evaluation metrics are displayed.
The evaluation results are returned as a pandas dataframe.
"""
# Add context to each question by retrieving relevant documents
eval_df['documents'] = eval_df.apply(lambda x: get_documents(collection_name=collection_name,
query=x['input_text'],
num_documents=num_docs), axis=1)
eval_df['context'] = eval_df.apply(lambda x: "\n".join(x['documents']), axis=1)
# Now we'll save the eval_df to a CSV
eval_df.to_csv(path, index=False)
# Upload the eval dataset to QuotientAI
dataset = quotient.create_dataset(
file_path=path,
name="qdrant-questions-eval-v1",
)
# Create a new task for the dataset
task = quotient.create_task(
dataset_id=dataset['id'],
name='qdrant-questions-qa-v1',
task_type='question_answering'
)
# Run a job to evaluate the model
job = quotient.create_job(
task_id=task['id'],
recipe_id=recipe_id,
num_fewshot_examples=0,
limit=500,
metric_ids=[5, 7, 8, 11, 12, 13, 50],
)
# Show the progress of the job
show_job_progress(quotient, job['id'])
# Once the job is complete, we can get our results
data = quotient.get_eval_results(job_id=job['id'])
# Add the results to a pandas dataframe to get statistics on performance
df = pd.json_normalize(data, "results")
df_stats = df[df.columns[df.columns.str.contains("metric|completion_time")]]
df.columns = df.columns.str.replace("metric.", "")
df_stats.columns = df_stats.columns.str.replace("metric.", "")
metrics = {
'completion_time_ms':'Completion Time (ms)',
'chunk_relevance': 'Chunk Relevance',
'selfcheckgpt_nli_relevance':"Context Relevance",
'selfcheckgpt_nli':"Faithfulness",
'rougeL_fmeasure':"ROUGE-L",
'bert_score_f1':"BERTScore",
'bert_sentence_similarity': "BERT Sentence Similarity",
'completion_verbosity':"Completion Verbosity",
'verbosity_ratio':"Verbosity Ratio",}
df = df.rename(columns=metrics)
df_stats = df_stats.rename(columns=metrics)
display(df_stats[metrics.values()].describe())
return df
main_metrics = [
'Context Relevance',
'Chunk Relevance',
'Faithfulness',
'ROUGE-L',
'BERT Sentence Similarity',
'BERTScore',
]
实验
我们的方法植根于这样一种信念,即改进在探索和发现的环境中蓬勃发展。通过系统地测试和调整 RAG 管道的各个组件,我们旨在逐步增强其能力和性能。
在下一节中,我们将深入探讨实验过程的细节,概述进行的具体实验和获得的见解。
实验 1 - 基线
参数
- 嵌入模型:
bge-small-en - 块大小:
512 - 块重叠:
64 - 检索到的文档数量(检索窗口):
3 - LLM:
Mistral-7B-Instruct
我们将根据上述配置处理文档,并使用前面介绍的add_documents方法将其摄取到 Qdrant 中
#experiment1 - base config
chunk_size = 512
chunk_overlap = 64
embedding_model_name = "BAAI/bge-small-en"
num_docs = 3
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
add_documents(client,
collection_name=COLLECTION_NAME,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
embedding_model_name=embedding_model_name)
#Outputs
#processed: 4504
#content: 4504
#metadata: 4504
请注意COLLECTION_NAME,它有助于我们根据进行的实验分离和识别我们的集合。
为了进行评估,接下来我们创建evaluation recipe
# Create a recipe for the generator model and prompt template
recipe_mistral = quotient.create_recipe(
model_id=10,
prompt_template_id=1,
name='mistral-7b-instruct-qa-with-rag',
description='Mistral-7b-instruct using a prompt template that includes context.'
)
recipe_mistral
#Outputs recipe JSON with the used prompt template
#'prompt_template': {'id': 1,
# 'name': 'Default Question Answering Template',
# 'variables': '["input_text","context"]',
# 'created_at': '2023-12-21T22:01:54.632367',
# 'template_string': 'Question: {input_text}\\n\\nContext: {context}\\n\\nAnswer:',
# 'owner_profile_id': None}
要获取现有配方的列表,您只需运行
quotient.list_recipes()
请注意,配方模板是一个最简单的提示,它使用评估模板中的Question、从 Qdrant 检索到的文档块中的Context和管道生成的Answer。
开始评估
# Kick off an evaluation job
experiment_1 = run_eval(eval_df,
collection_name=COLLECTION_NAME,
recipe_id=recipe_mistral['id'],
num_docs=num_docs,
path=f"{COLLECTION_NAME}_{num_docs}_mistral.csv")
这可能需要几分钟(取决于评估数据集的大小!)
我们可以如下查看我们第一个(基线)实验的结果
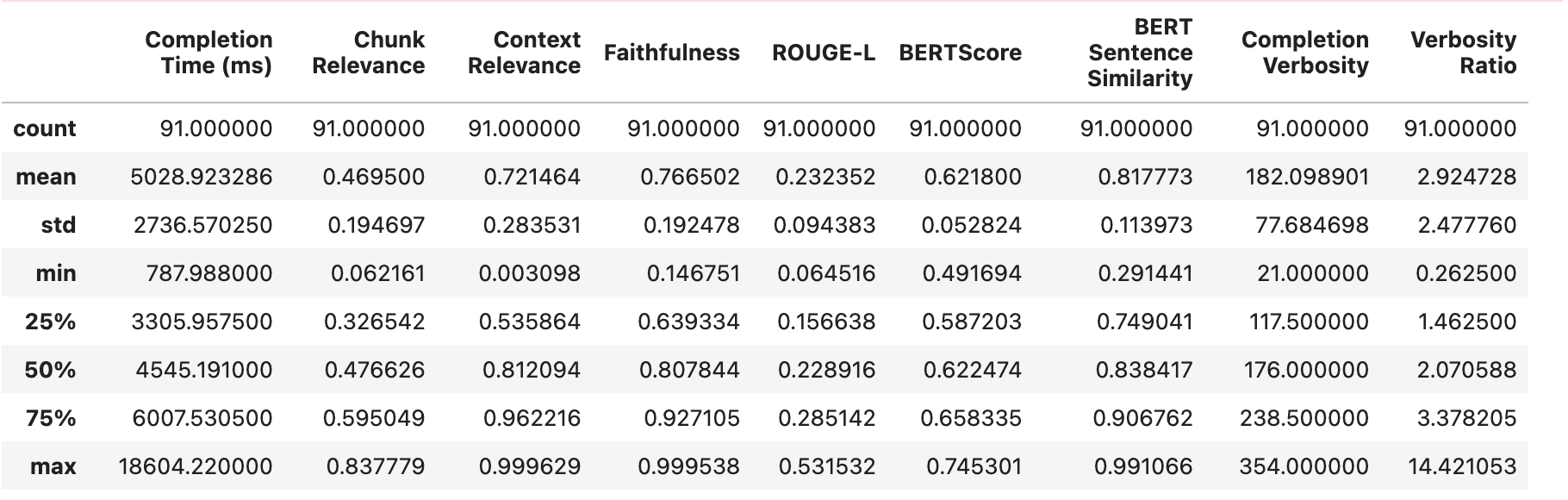
请注意,我们有一个非常低的平均块相关性,并且块相关性和上下文相关性的标准偏差都非常大。
让我们看看一些表现较差且忠实度较差的数据点
with pd.option_context('display.max_colwidth', 0):
display(experiment_1[['content.input_text', 'content.answer','content.documents','Chunk Relevance','Context Relevance','Faithfulness']
].sort_values(by='Faithfulness').head(2))

在检索到的文档不相关(块相关性和上下文相关性都较低)的情况下,模型也表现出倾向于幻觉和生成低质量响应。
检索到的文本质量直接影响 LLM 生成答案的质量。因此,我们的重点将放在通过调整分块参数来增强 RAG 设置。
实验 2 - 调整块参数
在保持所有其他参数不变的情况下,我们改变了块大小和块重叠,以查看我们是否可以改进结果。
参数
- 嵌入模型:
bge-small-en - 块大小:
1024 - 块重叠:
128 - 检索到的文档数量(检索窗口):
3 - LLM:
Mistral-7B-Instruct
我们将使用上述更新的参数重新处理数据
## for iteration 2 - lets modify chunk configuration
## We will start with creating seperate collection to store vectors
chunk_size = 1024
chunk_overlap = 128
embedding_model_name = "BAAI/bge-small-en"
num_docs = 3
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
add_documents(client,
collection_name=COLLECTION_NAME,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
embedding_model_name=embedding_model_name)
#Outputs
#processed: 2152
#content: 2152
#metadata: 2152
接着运行评估
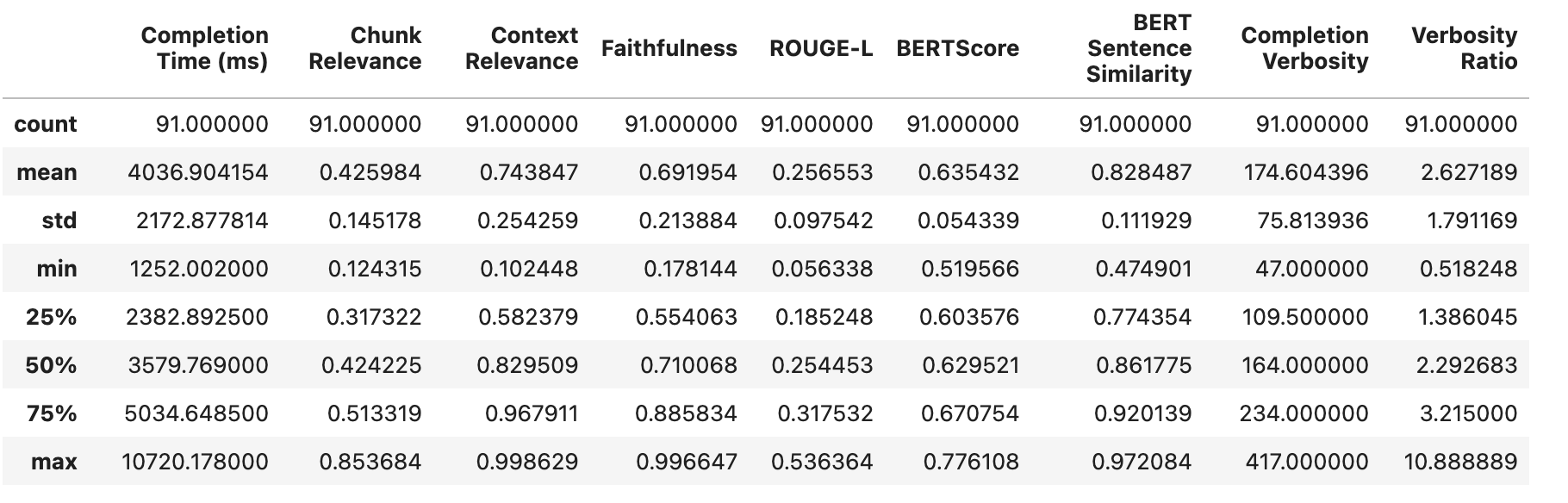
并将其与实验 1 的结果进行比较:
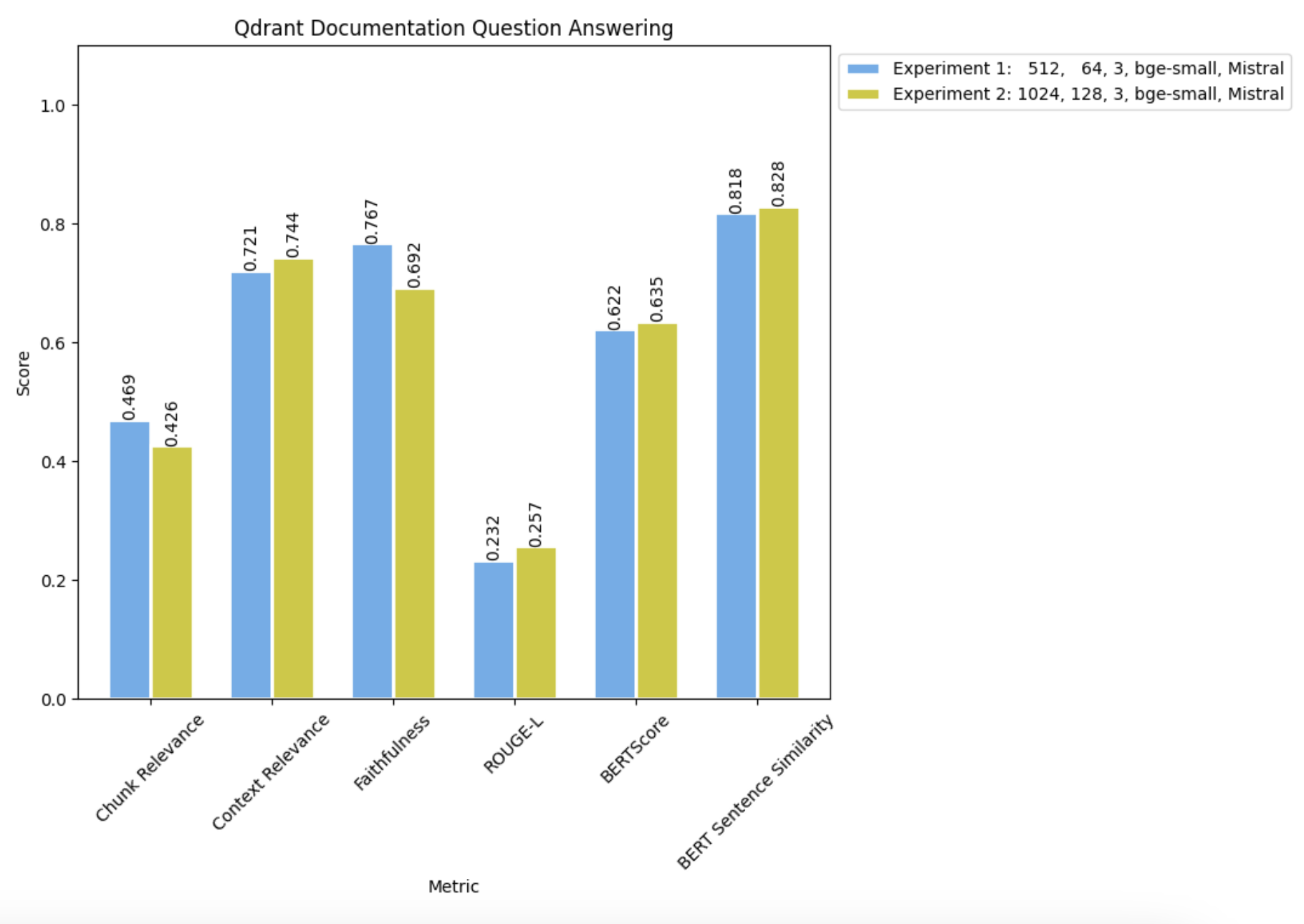
我们观察到随着块大小的增加,我们的 LLM 完成指标(包括 BERT 句子相似度、BERTScore、ROUGE-L 和知识 F1)略有提升。然而,值得注意的是,忠实度显著下降,这是我们主要旨在优化的指标。
此外,上下文相关性有所增加,表明 RAG 管道检索了更多解决查询所需的相关信息。尽管如此,块相关性却大幅下降,这意味着检索到的文档中只有一小部分包含回答问题所需的有用信息。
上下文相关性上升与块相关性下降之间的相关性表明,使用较小的块大小检索更多文档可能会产生更好的结果。
实验 3 - 增加检索到的文档数量(检索窗口)
这次,我们使用与实验 1相同的 RAG 设置,但将检索到的文档数量从3增加到5。
参数
- 嵌入模型:
bge-small-en - 块大小:
512 - 块重叠:
64 - 检索到的文档数量(检索窗口):
5 - LLM:
Mistral-7B-Instruct
我们可以使用实验 1 的集合,并使用修改后的num_docs参数运行评估,如下所示
#collection name from Experiment 1
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
#running eval for experiment 3
experiment_3 = run_eval(eval_df,
collection_name=COLLECTION_NAME,
recipe_id=recipe_mistral['id'],
num_docs=num_docs,
path=f"{COLLECTION_NAME}_{num_docs}_mistral.csv")
观察结果如下
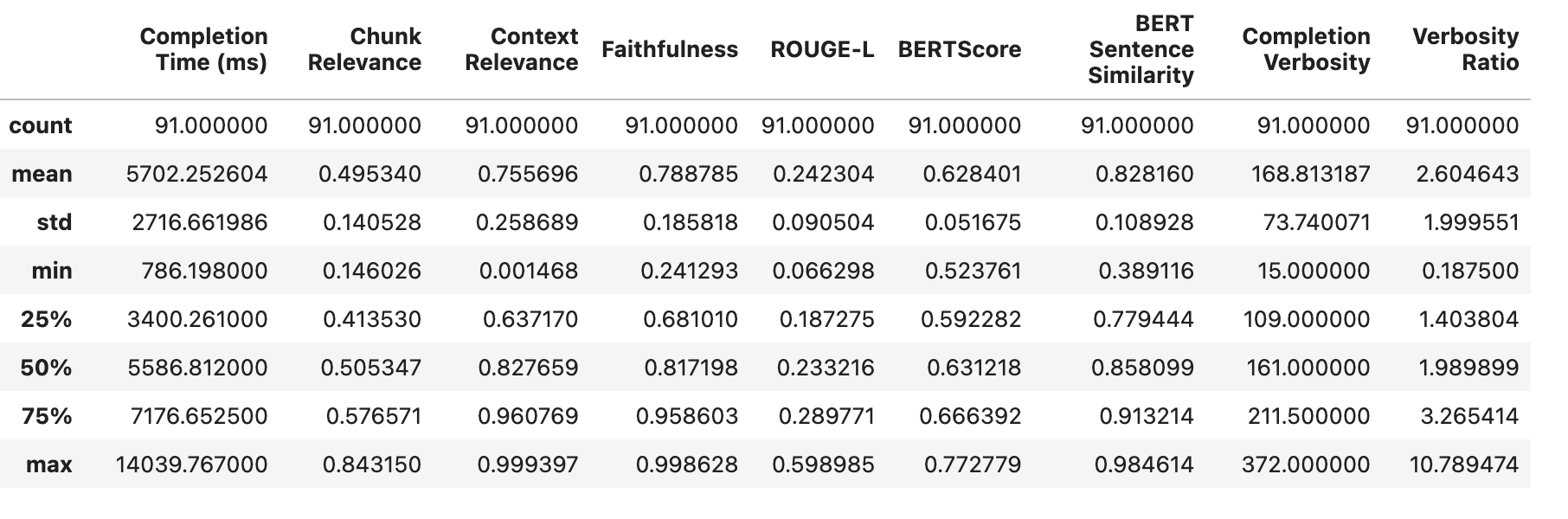
与实验 1 和 2 的结果进行比较
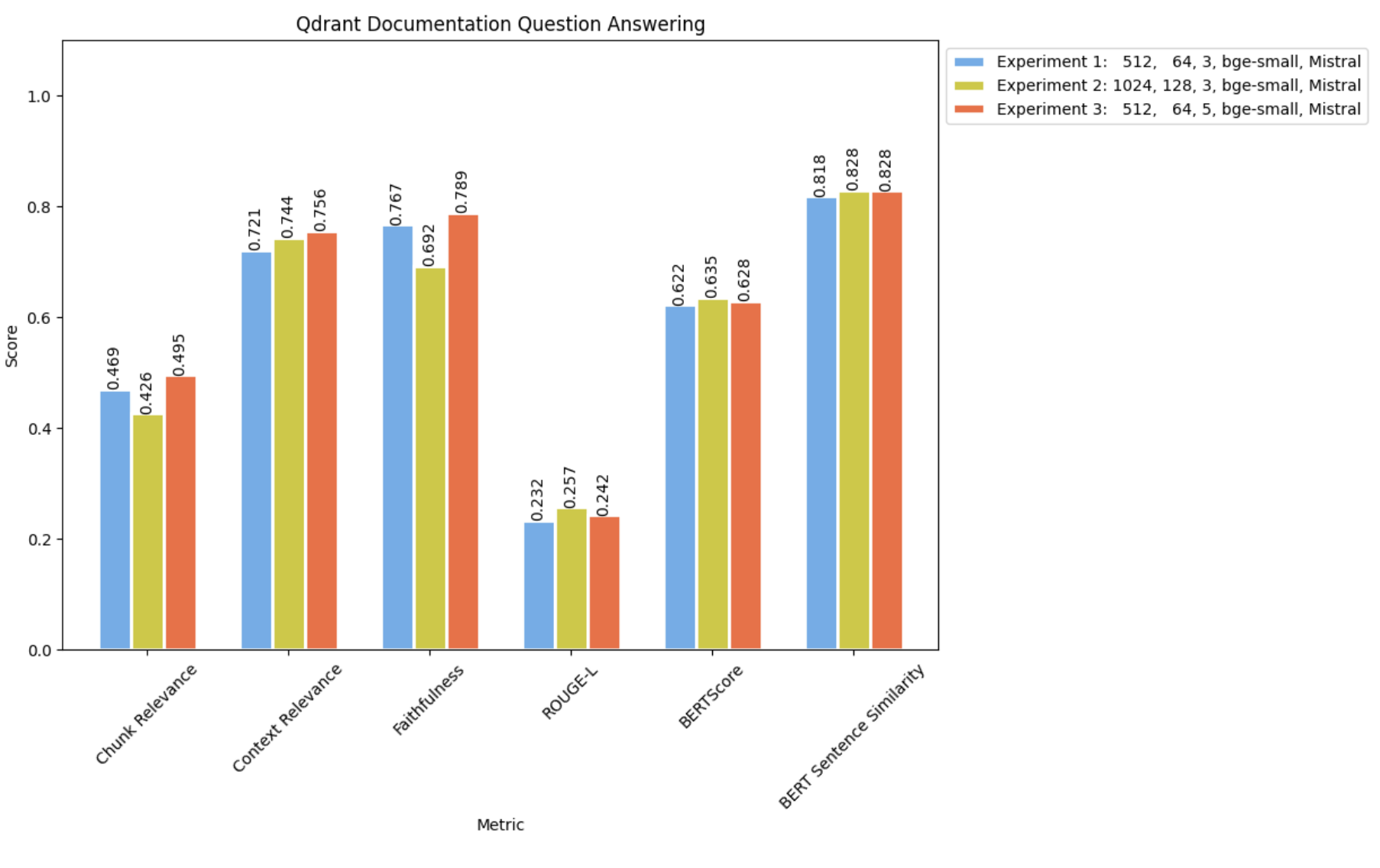
正如预期的那样,采用较小的块大小同时检索更多文档,导致实现了最高的上下文相关性和块相关性。此外,它还产生了最好的(尽管微不足道)忠实度分数,表明不准确或幻觉的发生率降低。
看起来我们已经很好地掌握了分块参数,但值得测试另一个嵌入模型,看看我们是否能获得更好的结果。
实验 4 - 更改嵌入模型
让我们尝试使用 MiniLM 进行此实验 ****参数
- 嵌入模型:
MiniLM-L6-v2 - 块大小:
512 - 块重叠:
64 - 检索到的文档数量(检索窗口):
5 - LLM:
Mistral-7B-Instruct
我们需要为这个实验创建另一个集合
#experiment-4
chunk_size=512
chunk_overlap=64
embedding_model_name="sentence-transformers/all-MiniLM-L6-v2"
num_docs=5
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
add_documents(client,
collection_name=COLLECTION_NAME,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
embedding_model_name=embedding_model_name)
#Outputs
#processed: 4504
#content: 4504
#metadata: 4504
我们将观察我们的评估结果,如下所示
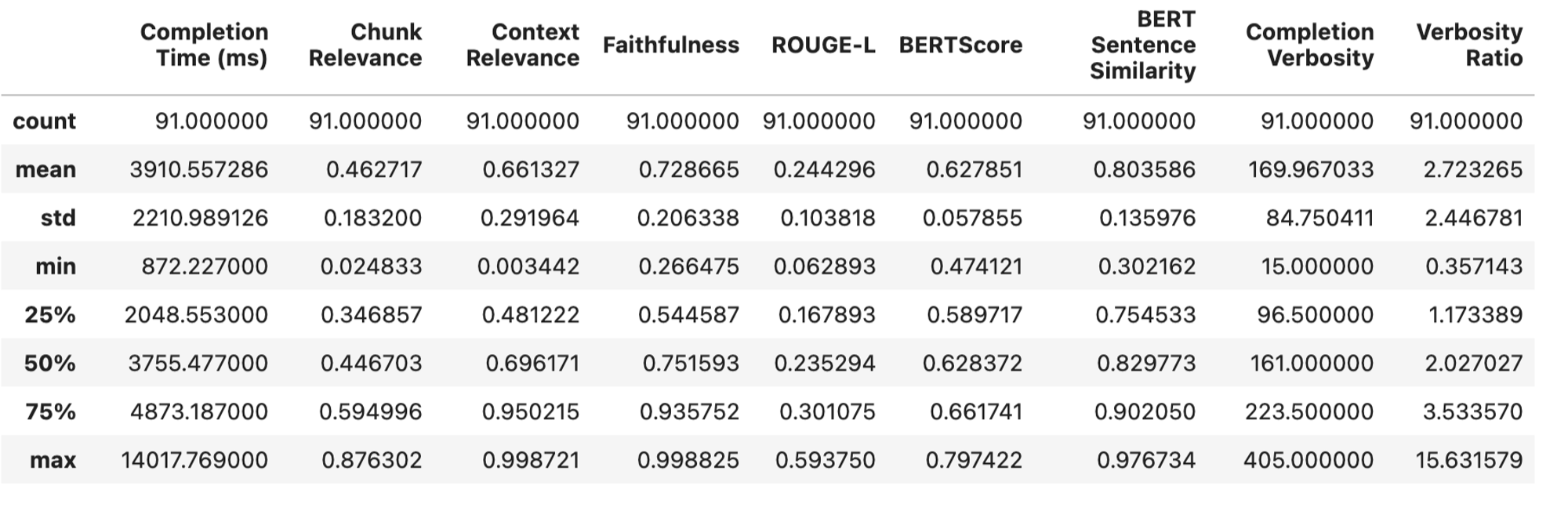
将其与我们之前的实验进行比较
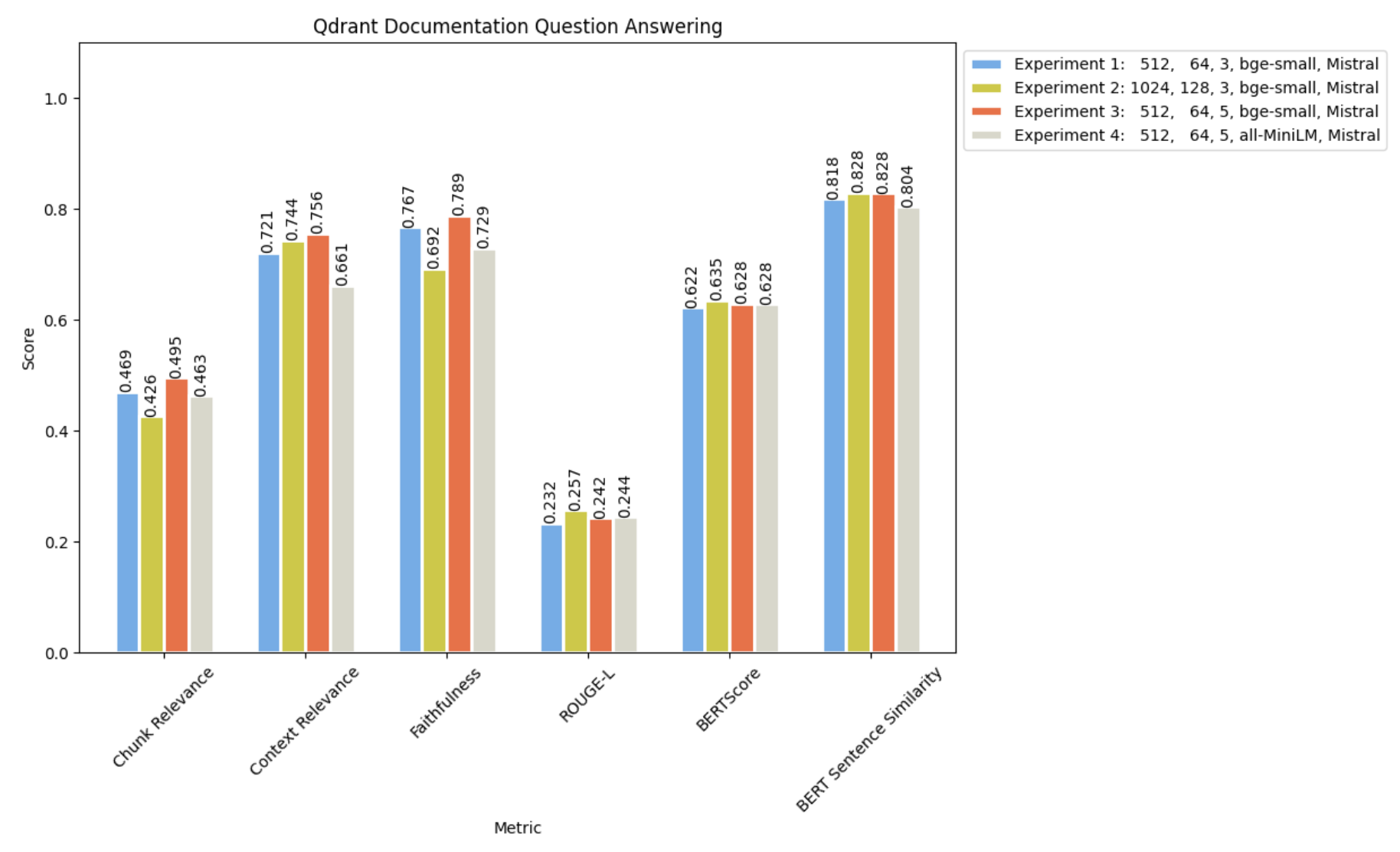
看来bge-small在捕获 Qdrant 文档的语义细微差别方面更胜一筹。
到目前为止,我们的实验只关注 RAG 管道的检索方面。现在,让我们在保留实验 3 中确定的最佳参数的同时,探索更改生成方面或 LLM。
实验 5 - 更改 LLM
参数
- 嵌入模型:
bge-small-en - 块大小:
512 - 块重叠:
64 - 检索到的文档数量(检索窗口):
5 - LLM:
GPT-3.5-turbo
为此,我们可以重新利用实验 3 的集合,同时评估使用带有 GPT-3.5-turbo 模型的新配方。
#collection name from Experiment 3
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
# We have to create a recipe using the same prompt template and GPT-3.5-turbo
recipe_gpt = quotient.create_recipe(
model_id=5,
prompt_template_id=1,
name='gpt3.5-qa-with-rag-recipe-v1',
description='GPT-3.5 using a prompt template that includes context.'
)
recipe_gpt
#Outputs
#{'id': 495,
# 'name': 'gpt3.5-qa-with-rag-recipe-v1',
# 'description': 'GPT-3.5 using a prompt template that includes context.',
# 'model_id': 5,
# 'prompt_template_id': 1,
# 'created_at': '2024-05-03T12:14:58.779585',
# 'owner_profile_id': 34,
# 'system_prompt_id': None,
# 'prompt_template': {'id': 1,
# 'name': 'Default Question Answering Template',
# 'variables': '["input_text","context"]',
# 'created_at': '2023-12-21T22:01:54.632367',
# 'template_string': 'Question: {input_text}\\n\\nContext: {context}\\n\\nAnswer:',
# 'owner_profile_id': None},
# 'model': {'id': 5,
# 'name': 'gpt-3.5-turbo',
# 'endpoint': 'https://api.openai.com/v1/chat/completions',
# 'revision': 'placeholder',
# 'created_at': '2024-02-06T17:01:21.408454',
# 'model_type': 'OpenAI',
# 'description': 'Returns a maximum of 4K output tokens.',
# 'owner_profile_id': None,
# 'external_model_config_id': None,
# 'instruction_template_cls': 'NoneType'}}
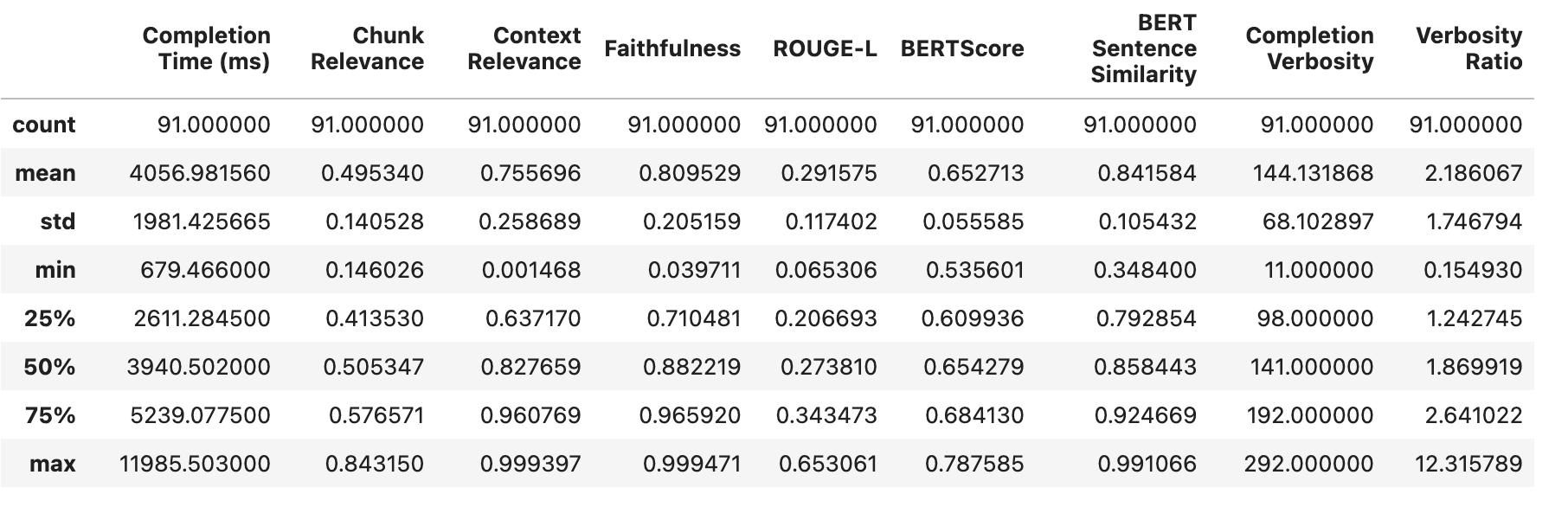
运行评估结果如下
experiment_5 = run_eval(eval_df,
collection_name=COLLECTION_NAME,
recipe_id=recipe_gpt['id'],
num_docs=num_docs,
path=f"{COLLECTION_NAME}_{num_docs}_gpt.csv")
我们观察到
并比较所有 5 个实验结果如下
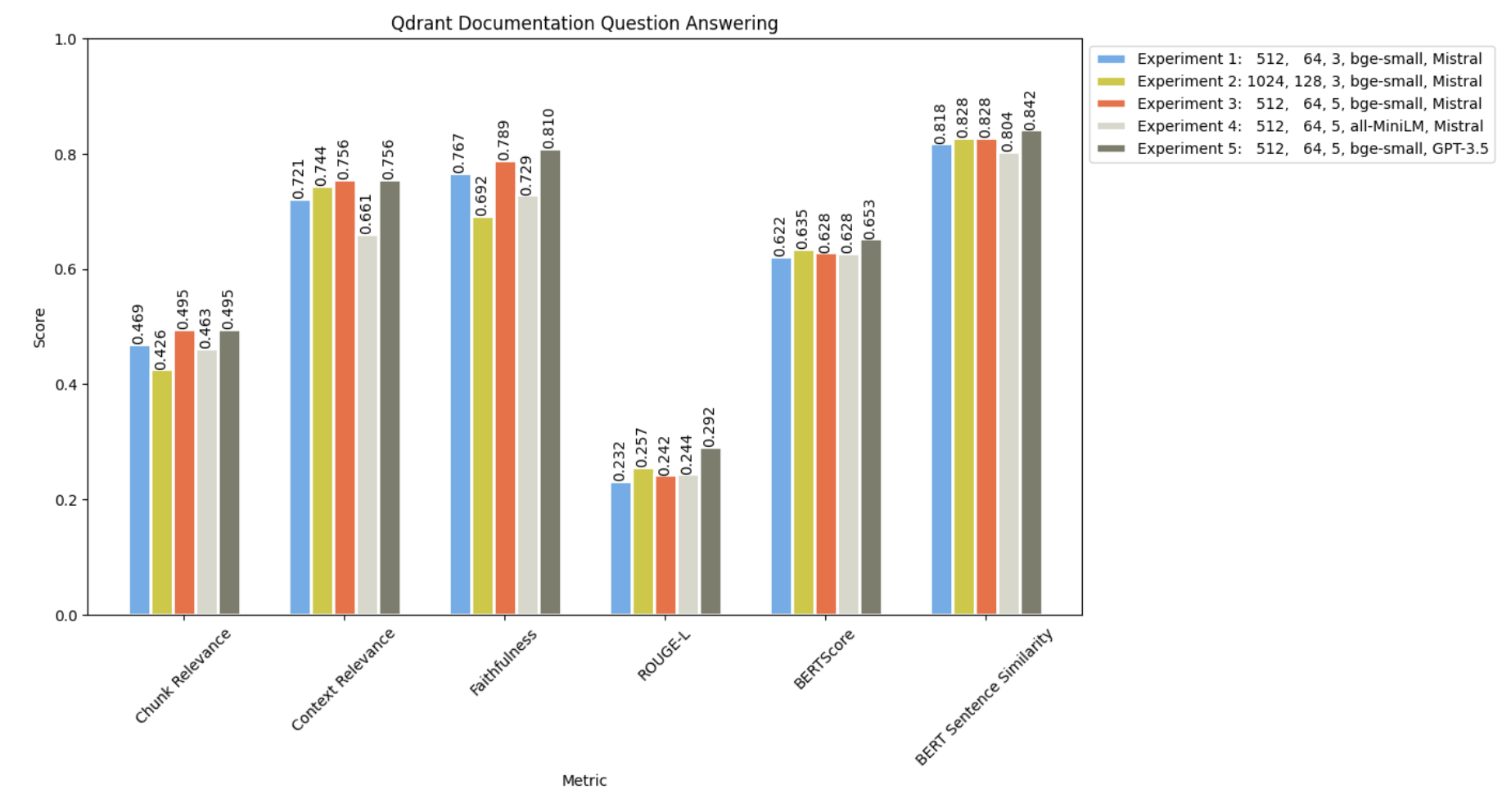
GPT-3.5 在所有指标上都超越了 Mistral-7B!值得注意的是,实验 5 表现出最低的幻觉发生率。
结论
让我们看看上面所有 5 个实验的结果
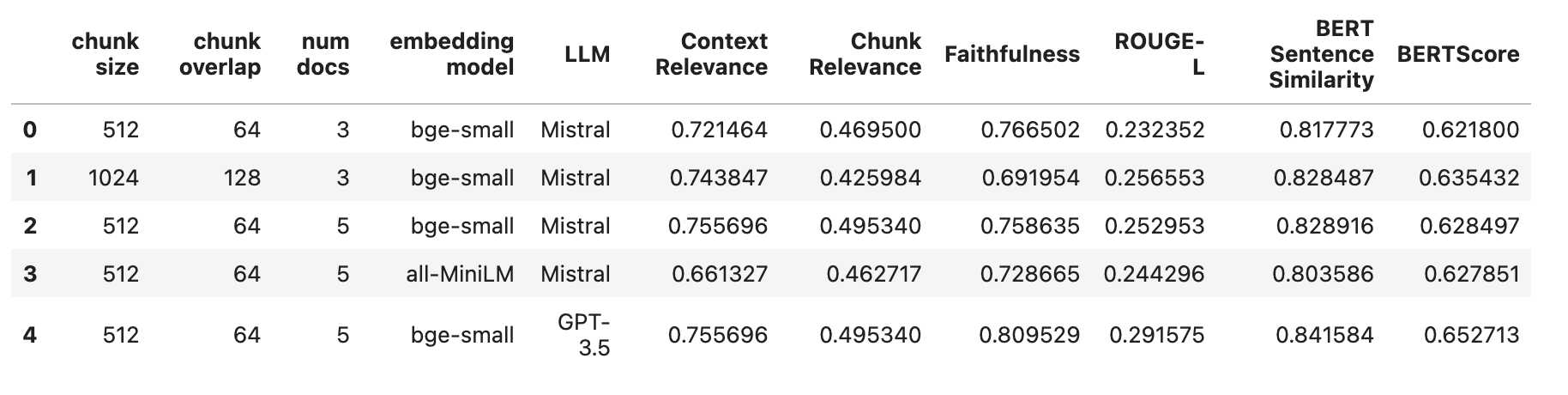
我们在改进 RAG 的检索性能方面仍有很长的路要走,迄今为止我们普遍较差的结果就表明了这一点。探索替代嵌入模型或不同的检索策略可能有助于解决此问题。
上下文相关性的显著变化表明,某些问题可能需要检索比其他问题更多的文档。因此,研究动态检索策略可能是有益的。
此外,RAG 的生成方面仍需持续探索。修改 LLM 或提示可以显著影响响应的整体质量。
这个迭代过程展示了从头开始,持续评估和实验调整如何才能开发出增强的 RAG 系统。
在 YouTube 上观看此研讨会
本文的研讨会版本可在 YouTube 上观看。使用我们的GitHub 笔记本进行操作。