
效率释放:标量量化的力量
高维向量嵌入可能是内存密集型的,尤其是在处理包含数百万个向量的大型数据集时。当我们扩展规模时,内存占用确实开始成为一个问题。存储单个数字的数据类型的简单选择会影响甚至数十亿个数字,并可能使内存需求变得疯狂。类型精度越高,表示数字的准确性就越高。向量越准确,距离计算就越精确。但当你需要订购越来越多的内存时,这些优势就不再奏效了。
Qdrant 选择 float32 作为存储嵌入数字的默认类型。因此,单个数字需要 4 字节内存,而 512 维向量占用 2 KB。这只是用于存储向量的内存。还有 HNSW 图的开销,因此根据经验法则,我们用以下公式估算内存大小
memory_size = 1.5 * number_of_vectors * vector_dimension * 4 bytes
虽然 Qdrant 提供了各种选项来将部分数据存储在磁盘上,但从 1.1.0 版本开始,您还可以通过压缩嵌入来优化内存。我们已经实现了标量量化机制!事实证明,它不仅对内存有积极影响,而且对性能也有积极影响。
标量量化
标量量化是一种数据压缩技术,它将浮点值转换为整数。在 Qdrant 的情况下,float32 会转换为 int8,因此单个数字需要减少 75% 的内存。但这并非简单的四舍五入!这是一个使转换部分可逆的过程,因此我们也可以将整数还原为浮点数,但会损失少量精度。
理论背景
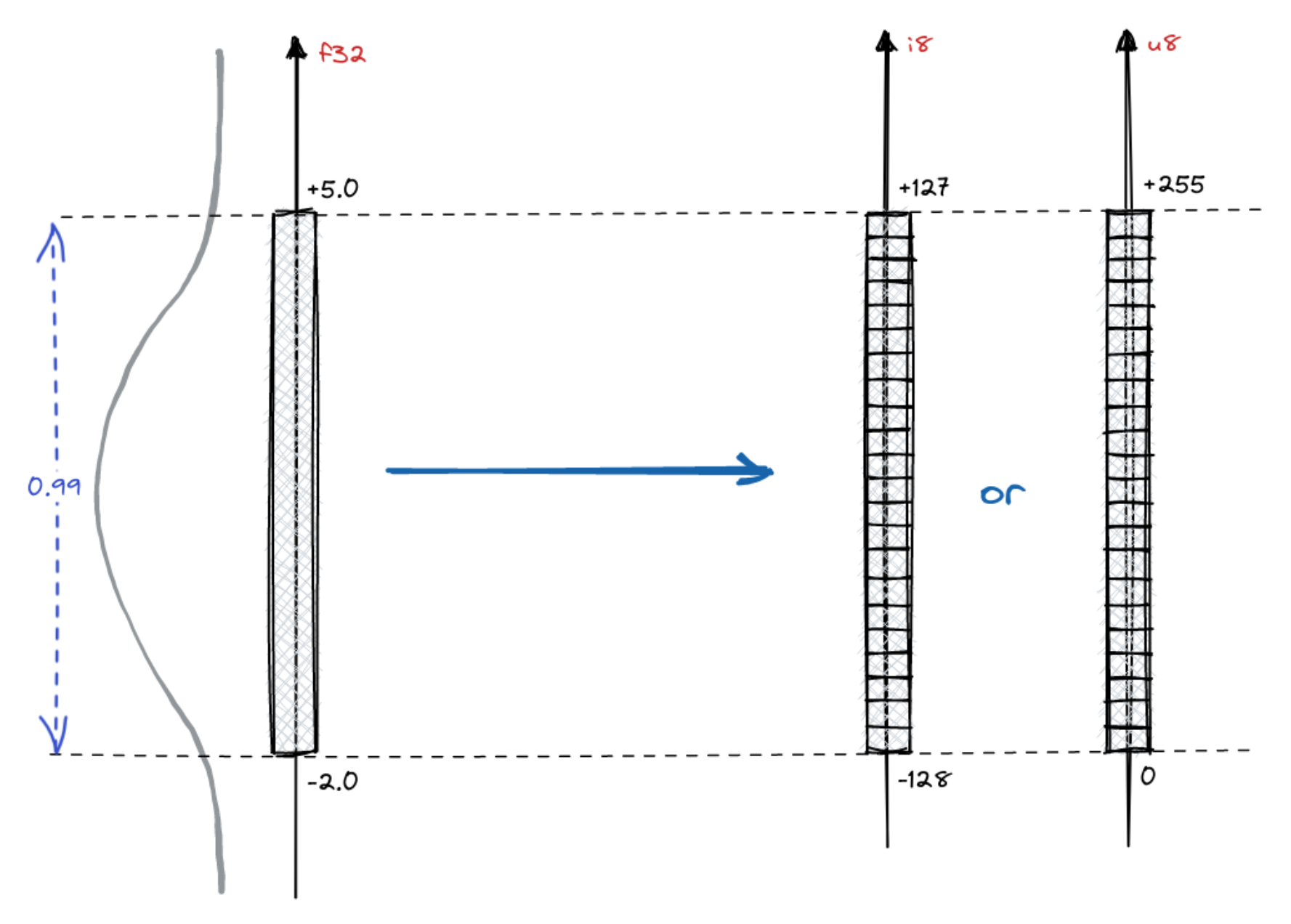
假设我们有一个 float32 向量集合,并用 f32 表示单个值。实际上,神经嵌入不会覆盖浮点数所表示的整个范围,而是一个小的子范围。由于我们知道所有其他向量,我们可以建立所有数字的一些统计数据。例如,值的分布通常是正态的

我们的例子表明,99% 的值来自 [-2.0, 5.0] 范围。转换为 int8 肯定会损失一些精度,因此我们更倾向于将表示精度保持在 99% 最可能值的范围内,而忽略异常值的精度。范围宽度可能有不同的选择,实际上,可以是 [0, 1] 范围内的任何值,其中 0 表示空范围,1 将保留所有值。这是名为 quantile 的过程的一个超参数。0.95 或 0.99 的值通常是合理的选择,但一般来说 quantile ∈ [0, 1]。
转换为整数
我们来谈谈转换为 int8。整数也有一组有限的可以表示的值。在一个字节内,它们可以表示多达 256 个不同的值,范围可以是 [-128, 127] 或 [0, 255]。
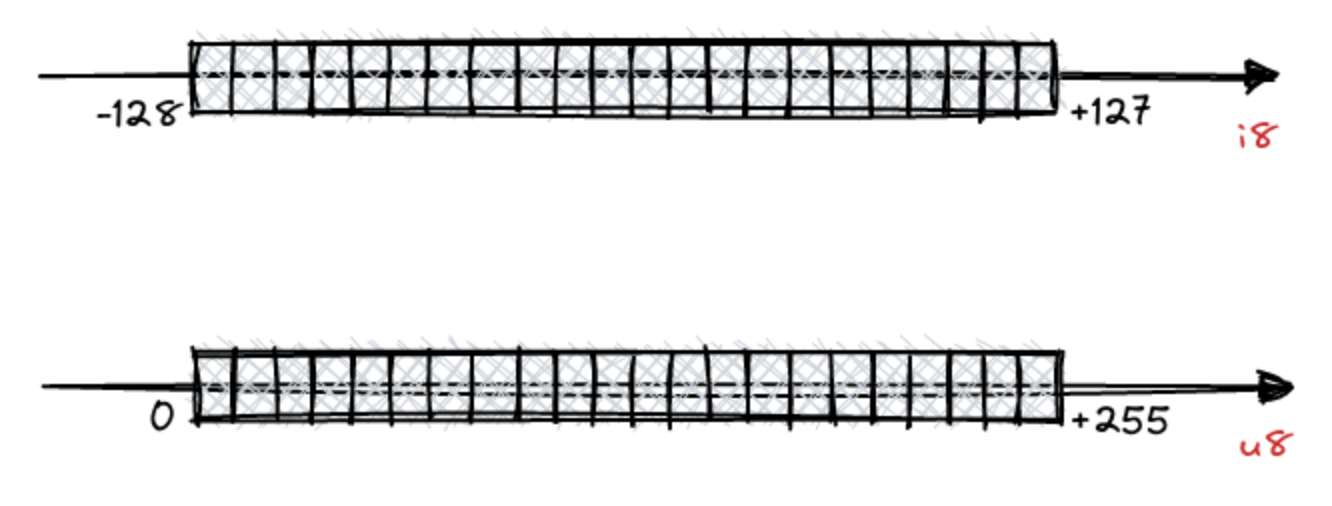
由于我们对可能由 f32 表示的数字设置了一些边界,并且 i8 具有一些自然边界,因此在两个范围之间转换值的过程非常自然
$$ f32 = \alpha \times i8 + offset $$
$$ i8 = \frac{f32 - offset}{\alpha} $$
参数 $ \alpha $ 和 $ offset $ 必须为给定的一组向量计算,但通过将 f32 和 i8 所表示范围的最小值和最大值代入即可轻松得出。
对于无符号 int8,它将如下所示
$$ \begin{equation} \begin{cases} -2 = \alpha \times 0 + offset \\ 5 = \alpha \times 255 + offset \end{cases} \end{equation} $$
在有符号 int8 的情况下,我们只需更改表示范围边界
$$ \begin{equation} \begin{cases} -2 = \alpha \times (-128) + offset \\ 5 = \alpha \times 127 + offset \end{cases} \end{equation} $$
对于任何一组向量值,我们都可以简单地计算 $ \alpha $ 和 $ offset $,并且这些值必须与集合一起存储,以实现类型之间的转换。
距离计算
我们并非为了压缩内存而将向量存储在由 int8 而非 float32 表示的集合中。但这些坐标在计算向量之间的距离时会被使用。点积和余弦距离都需要将两个向量的对应坐标相乘,因此这是我们经常对 float32 执行的操作。如果我们将转换为 int8,它将是这样的
$$ f32 \times f32’ = $$ $$ = (\alpha \times i8 + offset) \times (\alpha \times i8’ + offset) = $$ $$ = \alpha^{2} \times i8 \times i8’ + \underbrace{offset \times \alpha \times i8’ + offset \times \alpha \times i8 + offset^{2}}_\text{pre-compute} $$
第一个项,$ \alpha^{2} \times i8 \times i8’ $ 在测量距离时必须计算,因为它取决于两个向量。然而,第二项和第三项(分别为 $ offset \times \alpha \times i8’ $ 和 $ offset \times \alpha \times i8 $)仅取决于单个向量,并且可以为每个向量预计算并保留。最后一项,$ offset^{2} $ 不取决于任何值,因此甚至可以计算一次并重用。
如果我们需要计算所有项来测量距离,性能甚至可能比不进行转换时更差。但由于我们可以预计算大部分项,事情变得更简单了。事实证明,标量量化不仅对内存使用有积极影响,而且对性能也有积极影响。像往常一样,我们进行了一些基准测试来支持这一说法!
基准测试
我们只是使用了与我们发布的所有其他基准测试相同的方法。选择了 Arxiv-titles-384-angular-no-filters 和 Gist-960 数据集来比较未量化和量化向量。结果总结在表格中
Arxiv-titles-384-angular-no-filters
| ef = 128 | ef = 256 | ef = 512 | |||||
|---|---|---|---|---|---|---|---|
| 上传和索引时间 | 平均搜索精度 | 平均搜索时间 | 平均搜索精度 | 平均搜索时间 | 平均搜索精度 | 平均搜索时间 | |
| 未量化向量 | 649 秒 | 0.989 | 0.0094 | 0.994 | 0.0932 | 0.996 | 0.161 |
| 标量量化 | 496 秒 | 0.986 | 0.0037 | 0.993 | 0.060 | 0.996 | 0.115 |
| 差异 | -23.57% | -0.3% | -60.64% | -0.1% | -35.62% | 0% | -28.57% |
搜索精度略有下降,但延迟显著改善。除非您追求尽可能高的精度,否则您不会注意到搜索质量的差异。
Gist-960
| ef = 128 | ef = 256 | ef = 512 | |||||
|---|---|---|---|---|---|---|---|
| 上传和索引时间 | 平均搜索精度 | 平均搜索时间 | 平均搜索精度 | 平均搜索时间 | 平均搜索精度 | 平均搜索时间 | |
| 未量化向量 | 452 | 0.802 | 0.077 | 0.887 | 0.135 | 0.941 | 0.231 |
| 标量量化 | 312 | 0.802 | 0.043 | 0.888 | 0.077 | 0.941 | 0.135 |
| 差异 | -30.79% | 0% | -44,16% | +0.11% | -42.96% | 0% | -41,56% |
在所有情况下,搜索精度下降可忽略不计,但我们在搜索时仍能保持至少 28.57% 的延迟降低,甚至高达 60.64%。根据经验法则,向量维度越高,精度损失越小。
过采样和重排序
Qdrant 架构的一个独特之处是能够在单个查询中结合量化向量和原始向量的搜索。这实现了速度、准确性和内存使用的最佳组合。
Qdrant 存储原始向量,因此可以在量化空间中进行邻居搜索后,使用原始向量对 top-k 结果进行重排序。这显然对性能有一定影响,但为了衡量其影响大小,我们在不同的搜索场景中进行了比较。我们使用了一台带有非常慢的网络挂载磁盘的机器,并测试了以下不同允许内存量的场景
| 设置 | 每秒请求数 (RPS) | 精度 |
|---|---|---|
| 4.5GB 内存 | 600 | 0.99 |
| 4.5GB 内存 + 标量量化 + 重排序 | 1000 | 0.989 |
另一组具有更严格的内存限制
| 设置 | 每秒请求数 (RPS) | 精度 |
|---|---|---|
| 2GB 内存 | 2 | 0.99 |
| 2GB 内存 + 标量量化 + 重排序 | 30 | 0.989 |
| 2GB 内存 + 标量量化 + 不重排序 | 1200 | 0.974 |
在这些实验中,吞吐量主要由磁盘读取次数决定,而量化通过允许更多向量在 RAM 中有效地减少了磁盘读取次数。阅读有关 Qdrant 中磁盘存储以及我们如何衡量其性能的更多信息,请参阅我们的文章:服务一百万向量所需的最小 RAM。
禁用重排序的标量量化机制进一步推动了低端机器的极限。似乎处理大量请求不需要昂贵的设置,如果您能接受搜索精度的小幅下降。
访问最佳实践
Qdrant 关于标量量化的文档是一个很好的资源,它描述了不同的场景和策略,以实现高达 4 倍的内存占用降低,甚至高达 2 倍的性能提升。