
Qdrant 是目前最快的向量搜索引擎之一,因此在寻找演示功能时,我们想到了制作一个具有完整语义搜索后端的功能,实现“输入即搜索”的搜索框。目前,我们的网站上已经有一个语义/关键词混合搜索功能。但那个是用 Python 编写的,这会带来一些解释器开销。自然而然地,我想看看使用 Rust 能有多快。
由于 Qdrant 本身不进行嵌入,我必须决定一个嵌入模型。之前的版本使用了 SentenceTransformers 包,该包反过来使用了基于 Bert 的 All-MiniLM-L6-V2 模型。这个模型经过了实战检验,能够以较快的速度提供不错的结果,因此我没有在这方面进行实验,而是采用了 ONNX 版本并在服务中运行它。
工作流程如下
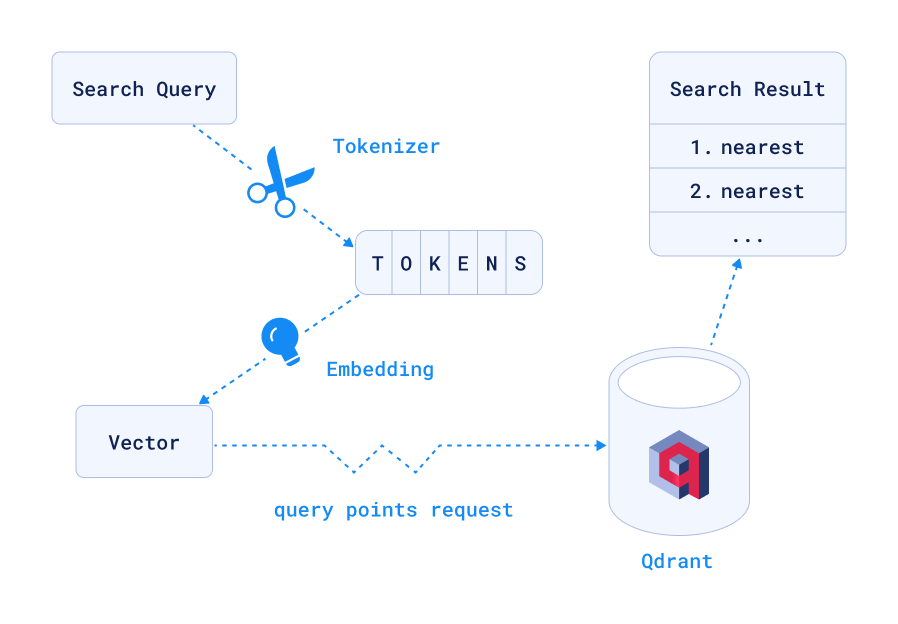
经过分词和嵌入后,这将向 Qdrant 发送一个 /collections/site/points/search POST 请求,并发送以下 JSON
POST collections/site/points/search
{
"vector": [-0.06716014,-0.056464013, ...(382 values omitted)],
"limit": 5,
"with_payload": true,
}
即使避免了网络往返,嵌入仍然需要一些时间。像往常在优化中一样,如果你无法更快地完成工作,一个好的解决方案是完全避免工作(请不要告诉我雇主)。这可以通过预计算常见前缀并为其计算嵌入,然后将它们存储在 prefix_cache 集合中来完成。现在,recommend API 方法无需进行任何嵌入即可找到最佳匹配。目前,我使用短(最多包含 5 个字母)前缀,但我也可以解析日志以获取最常见的搜索词,稍后将其添加到缓存中。
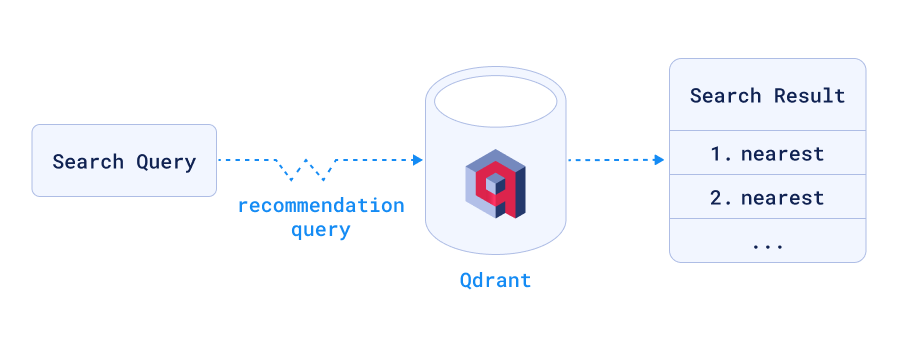
要使其工作,需要设置 prefix_cache 集合,其点将前缀作为 point_id,将嵌入作为 vector,这使我们无需搜索或索引即可进行查找。prefix_to_id 函数目前使用 PointId 的 u64 变体,它可以容纳八个字节,足以满足此用途。如果需要,可以改为将名称编码为 UUID,对输入进行哈希处理。由于我知道所有前缀都在 8 个字节以内,所以我目前决定不这样做。
recommend 端点的工作方式大致与 search_points 相同,但 Qdrant 不搜索向量,而是搜索一个或多个点(您还可以提供负面示例点,搜索引擎会尝试在结果中避免)。它旨在帮助驱动推荐引擎,从而省去了将当前点的向量发送回 Qdrant 以查找更多相似点的往返过程。但是,Qdrant 更进一步,允许我们选择不同的集合来查找点,这使我们可以将 prefix_cache 集合与站点数据分开。因此,在我们的案例中,Qdrant 首先从 prefix_cache 中查找点,获取其向量,然后在 site 集合中搜索该向量,使用缓存中预先计算的嵌入。API 端点期望将以下 JSON POST 到 /collections/site/points/recommend
POST collections/site/points/recommend
{
"positive": [1936024932],
"limit": 5,
"with_payload": true,
"lookup_from": {
"collection": "prefix_cache"
}
}
现在,秉承 Rust 的最佳传统,我拥有了闪电般的语义搜索。
为了演示它,我使用了我们的 Qdrant 文档网站 的页面搜索功能,替换了我们之前的 Python 实现。因此,为了不只是空口无凭,这里有一个基准测试,显示了锻炼不同代码路径的不同查询。
由于操作本身远快于网络,其变幻莫测的特性会淹没大多数可测量的差异,我同时在本地对 Python 和 Rust 服务进行了基准测试。我在同一台配备 16GB RAM 并运行 Linux 的 AMD Ryzen 9 5900HX 上测量了两个版本。该表显示了平均时间和毫秒级的误差范围。我只测量了多达一千个并发请求。在该范围内,没有任何服务显示出更多的请求会减慢速度。我不希望我们的服务遭到 DDOS 攻击,因此我没有在更大负载下进行基准测试。
闲话少说,以下是结果
| 查询长度 | 短 | 长 |
|---|---|---|
| Python 🐍 | 16 ± 4 毫秒 | 16 ± 4 毫秒 |
| Rust 🦀 | 1½ ± ½ 毫秒 | 5 ± 1 毫秒 |
Rust 版本始终优于 Python 版本,即使对于字符很少的查询也能提供语义搜索。如果命中前缀缓存(如短查询长度),语义搜索甚至可以比 Python 版本快十倍以上。总体加速是由于 Rust + Actix Web 相对于 Python + FastAPI(即使它已经表现出色)的相对较低开销,以及使用 ONNX Runtime 而不是 SentenceTransformers 进行嵌入。前缀缓存通过在不进行任何嵌入工作的情况下进行语义搜索,为 Rust 版本提供了真正的提升。
顺便说一句,虽然这里显示的毫秒级差异对于我们的用户来说可能意义相对较小,因为他们的延迟将主要由中间的网络决定,但在输入时,每多一毫秒或少一毫秒都可能影响用户感知。此外,输入即搜索产生的负载是普通搜索的三到五倍,因此服务将面临更多的流量。每个请求所需的时间越少,就能处理越多的请求。
任务完成!但等等,还有更多!
优先精确匹配和标题
为了提高结果质量,Qdrant 可以并行执行多次搜索,然后服务将结果按顺序排列,选取前几个最佳匹配。扩展代码搜索
- 标题中的文本匹配
- 正文(段落或列表)中的文本匹配
- 标题中的语义匹配
- 任何语义匹配
这些按照上述顺序组合在一起,必要时进行去重。
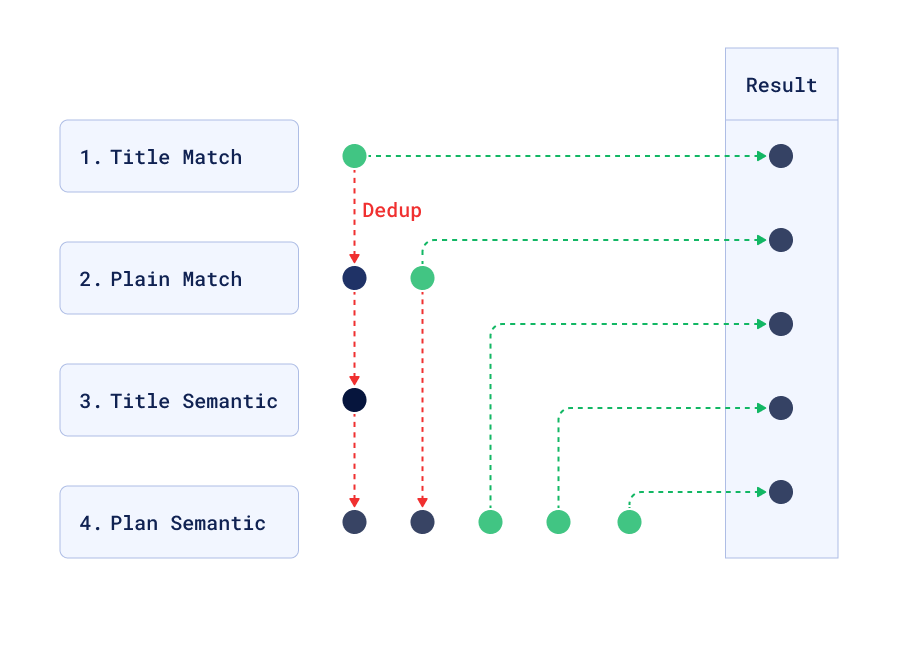
除了发送 search 或 recommend 请求之外,还可以分别发送 search/batch 或 recommend/batch 请求。每个请求都包含一个 "searches" 属性,其中包含任意数量的 search/recommend JSON 请求
POST collections/site/points/search/batch
{
"searches": [
{
"vector": [-0.06716014,-0.056464013, ...],
"filter": {
"must": [
{ "key": "text", "match": { "text": <query> }},
{ "key": "tag", "match": { "any": ["h1", "h2", "h3"] }},
]
}
...,
},
{
"vector": [-0.06716014,-0.056464013, ...],
"filter": {
"must": [ { "key": "body", "match": { "text": <query> }} ]
}
...,
},
{
"vector": [-0.06716014,-0.056464013, ...],
"filter": {
"must": [ { "key": "tag", "match": { "any": ["h1", "h2", "h3"] }} ]
}
...,
},
{
"vector": [-0.06716014,-0.056464013, ...],
...,
},
]
}
由于查询是在批处理请求中完成的,因此没有任何额外的网络开销,计算开销也非常小,但在许多情况下结果会更好。
唯一额外的复杂性是将结果列表扁平化并取前 5 个结果,按点 ID 去重。现在还有一个最终问题:查询可能短到可以走推荐代码路径,但仍不在前缀缓存中。在这种情况下,顺序执行搜索将意味着服务和 Qdrant 实例之间进行两次往返。解决方案是并发启动两个请求,并取第一个成功的非空结果。
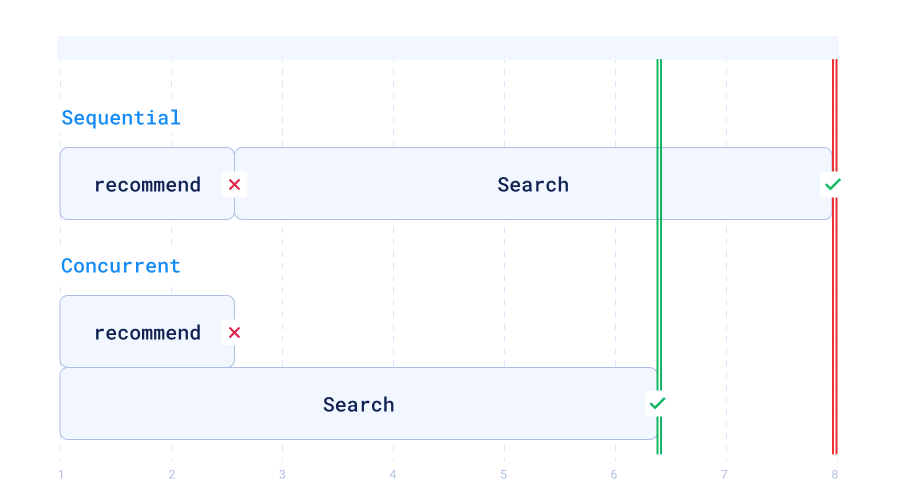
虽然这意味着 Qdrant 向量搜索引擎的负载增加,但这并不是限制因素。在许多情况下,相关数据已在缓存中,因此开销保持在可接受的范围内,并且在前缀缓存未命中情况下的最大延迟明显减少。
代码可在 Qdrant github 上获取
总结一下:Rust 很快,recommend 让我们可以使用预计算的嵌入,批处理请求很棒,而且可以在短短几毫秒内完成语义搜索。