
一个问题阐述得好,就解决了一半。
这句话在生活中和信息检索中都同样适用。
如果查询语句表述得当,检索相关文档就变得轻而易举。然而,在现实中,大多数用户难以精确定义他们所寻找的内容。
虽然用户可能难以制定完美的请求——尤其是在不熟悉的领域——但他们可以轻易判断检索到的答案是否相关。
相关性是检索系统强大的反馈机制,可以迭代地根据用户兴趣优化结果。
2025年,随着社交媒体充斥着每日的AI突破,信息检索似乎已经解决,智能体可以根据相关性评估迭代调整它们的搜索查询。
当然,有一个问题:这些模型仍然依赖于检索系统(尽管每天都有人预言RAG的消亡,但它尚未消亡)。它们只接收由一个更简单、更便宜的检索器提供的少量排名靠前的结果。因此,引导式检索的成功仍然主要取决于检索系统本身。
所以,我们应该找到一种有效且高效的方法,将相关性反馈直接整合到检索系统中。本文将探讨研究文献中提出的方法,并尝试回答以下问题:
如果搜索中的相关性反馈被广泛研究并被誉为有效,为什么它实际上没有被专门的向量搜索解决方案所采用?
拆解相关性反馈
业界和学术界倾向于在这里和那里重复造轮子。所以,我们首先花了一些时间研究和分类不同的方法——以防有什么我们可以直接插入Qdrant的。由此产生的分类法并非一成不变,但我们旨在使其有用。
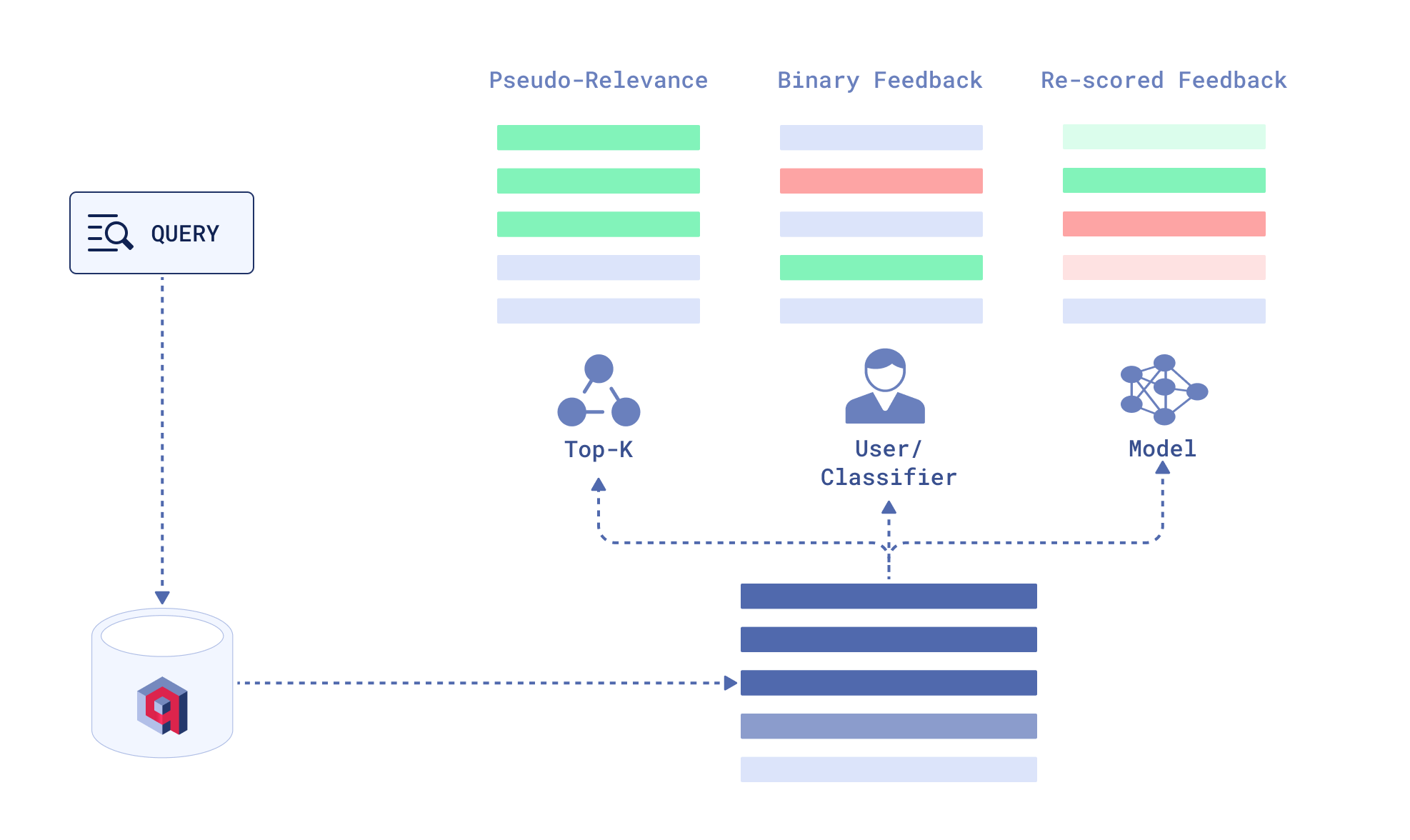
相关性反馈的类型
伪相关性反馈 (PRF)
伪相关性反馈从初始检索结果中获取排名靠前的文档,并将它们视为相关。这种方法可能看起来很幼稚,但它在词法检索中提供了显著的性能提升,同时计算成本相对较低。
二元相关性反馈
收集反馈最直接的方法是直接询问用户文档是否相关。这种方法主要有两个限制:
首先,用户出了名的不愿提供反馈。你知道 Google 曾经在搜索结果上有一个点赞/点踩机制,但后来取消了,因为几乎没有人使用它吗?
其次,即使用户愿意提供反馈,初始检索结果中也可能没有相关的文档。在这种情况下,用户无法提供有意义的信号。
我们可以不问用户,而是要求一个智能模型提供二元相关性判断,但这会限制其生成细粒度判断的潜力。
重新评分的相关性反馈
我们还可以应用更复杂的方法,从排名靠前的文档中提取相关性反馈——机器学习模型可以为每个文档提供一个相关性分数。
这里明显的担忧是双重的:
- 自动化判断者能多准确地确定相关性(或不相关性)?
- 它的成本效益如何?毕竟,你不能指望GPT-4o为每个用户查询重新排序数千个文档——除非你非常富有。
尽管如此,当无法获得明确的二元反馈时,自动重新评分的反馈可能是一种可扩展的改进搜索方式。
问题已经解决了吗?
通过研究资料,我们原本以为会发现其他内容,却意外发现第一个相关性反馈研究可以追溯到 六十年前。在神经搜索泡沫中,人们很容易忘记词法(基于词项)检索已经存在了几十年。自然地,该领域的研究有足够的时间发展。
神经搜索——又称 向量搜索——大约在5年前在业界获得关注。因此,针对向量的相关性反馈技术可能仍处于早期阶段,有待生产级验证和行业采纳。
作为一款 专用向量搜索引擎,我们希望成为这些采用者。我们的重点是神经搜索,但词法和神经检索的方法都值得探索,因为跨领域研究总是富有洞察力,有可能将一个领域成熟的方法应用到另一个领域。
我们发现了一些适用于神经搜索解决方案的有趣方法,并额外揭示了基于神经搜索的相关性反馈方法中的一个空白。敬请关注,我们将分享我们的发现!
解决问题的两种方法
检索可以分解为三个主要组成部分:
- 查询
- 文档
- 它们之间的相似性评分。
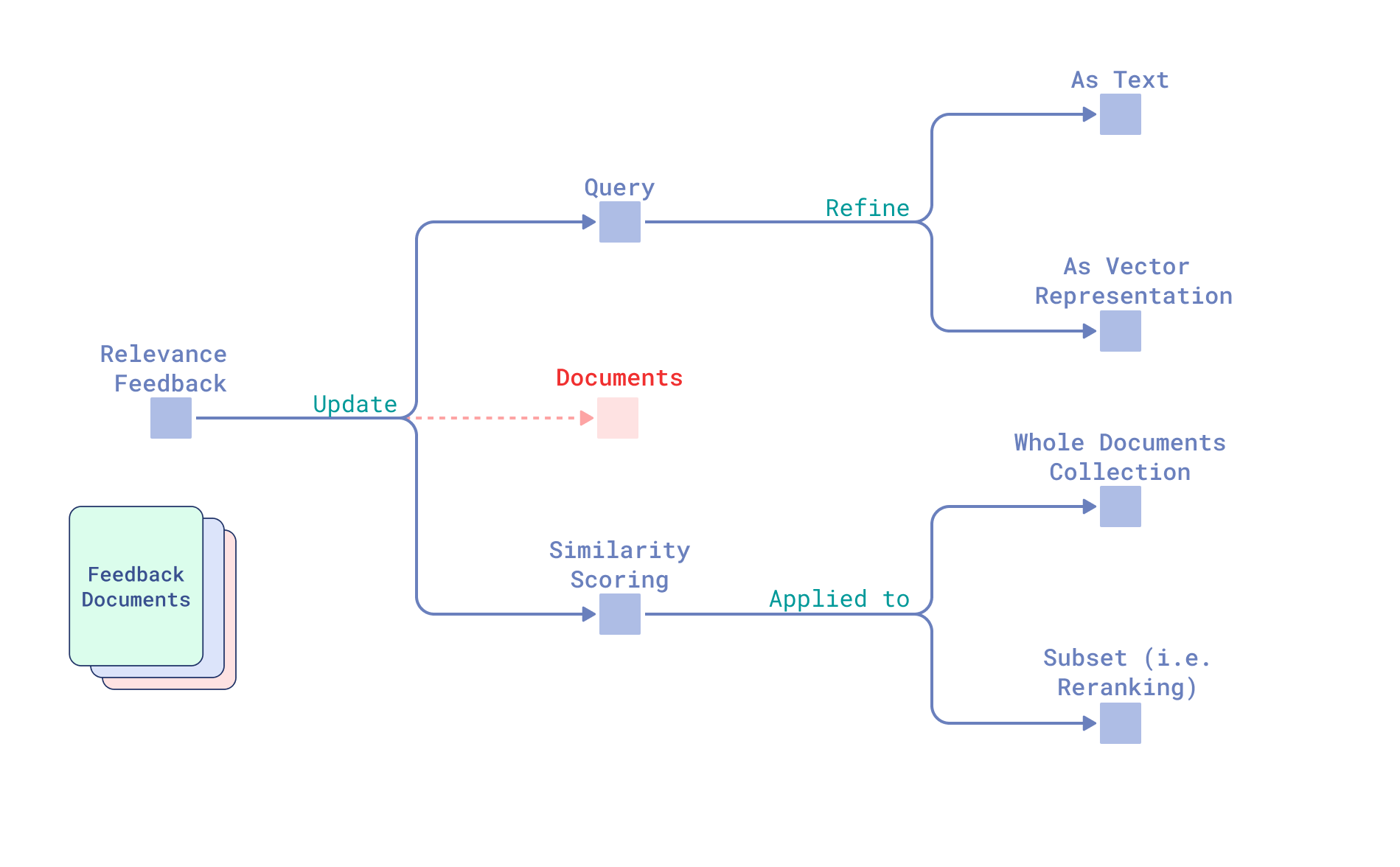
研究领域分类概述
查询的制定是一个主观过程——它可以有无限种配置,使得文档的相关性在查询制定并提交给系统之前是不可预测的。
因此,为了适应相关性反馈而调整文档(或搜索索引)将需要按请求进行动态更改,考虑到现代检索系统存储数十亿文档,这是不切实际的。
因此,将相关性反馈整合到搜索中的方法分为两类:优化查询和优化查询与文档之间的相似性评分函数。
查询优化
基于相关性反馈优化查询有几种方法。总体而言,我们更倾向于区分两种方法:将查询修改为文本和修改查询的向量表示。
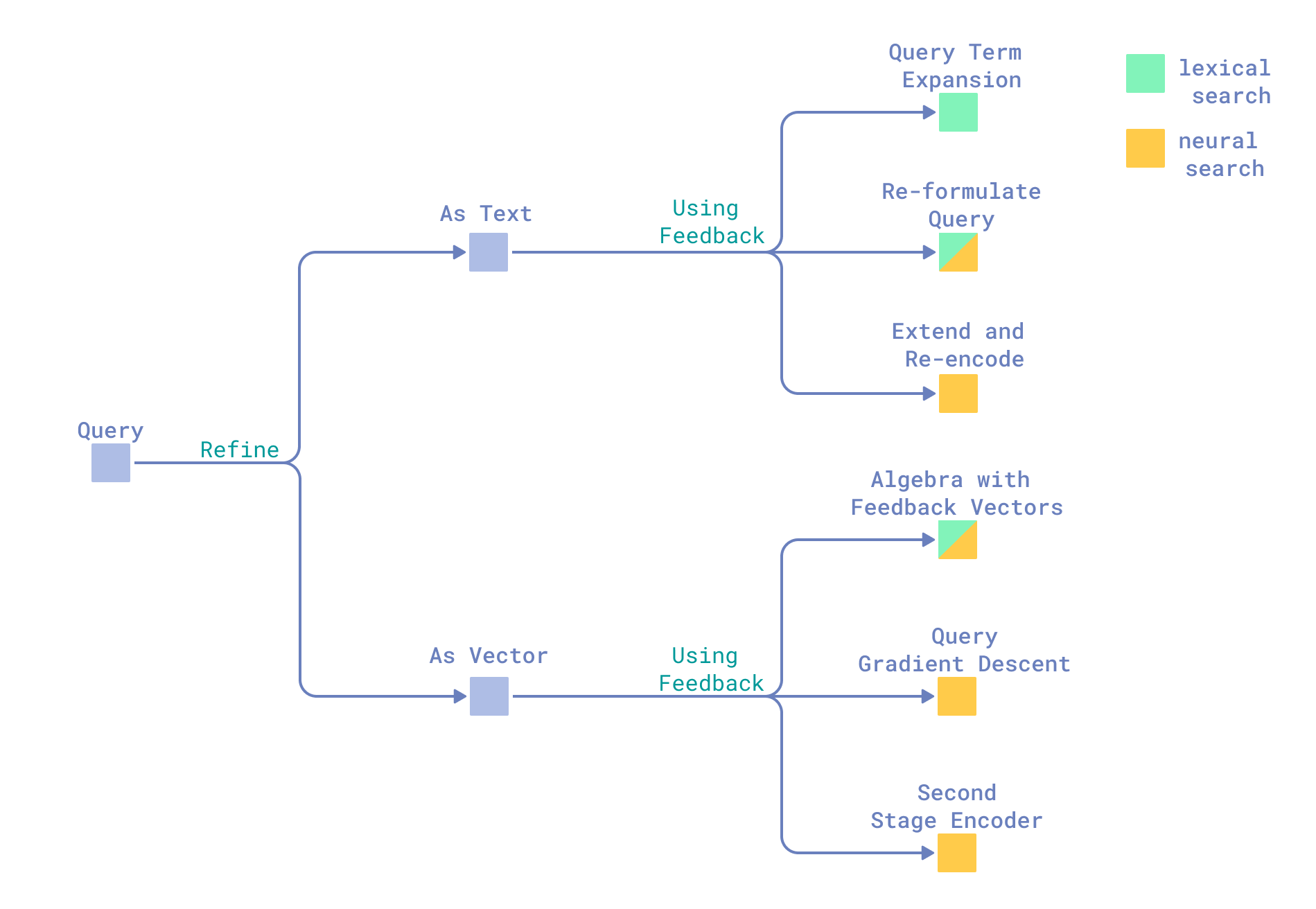
将相关性反馈整合到查询中
查询作为文本
在基于词项的检索中,改进查询的直观方法是用相关词项扩展它。这类似于发现搜索中的“啊哈,原来是这个名字”阶段。
在本世纪深度学习时代之前,扩展词项主要通过统计或概率模型选择。其思想是:
- 要么从(伪)相关文档中提取最频繁的词项;
- 要么是最具体的(例如,根据IDF);
- 要么是最有可能的(根据相关性集合最可能出现在查询中的)。
当时众所周知的方法来自于 相关性模型家族,其中用于扩展的词项是根据它们在伪相关文档中的概率(词项出现的频率)以及给定这些伪相关文档的查询词项的可能性——这些伪相关文档与查询的匹配程度来选择的。
最著名的模型 RM3——将扩展词项的概率与它们在查询中的概率进行插值——在过去几年的论文中仍然作为词项检索的(显著不错的)基线出现,通常作为 anserini 的一部分。
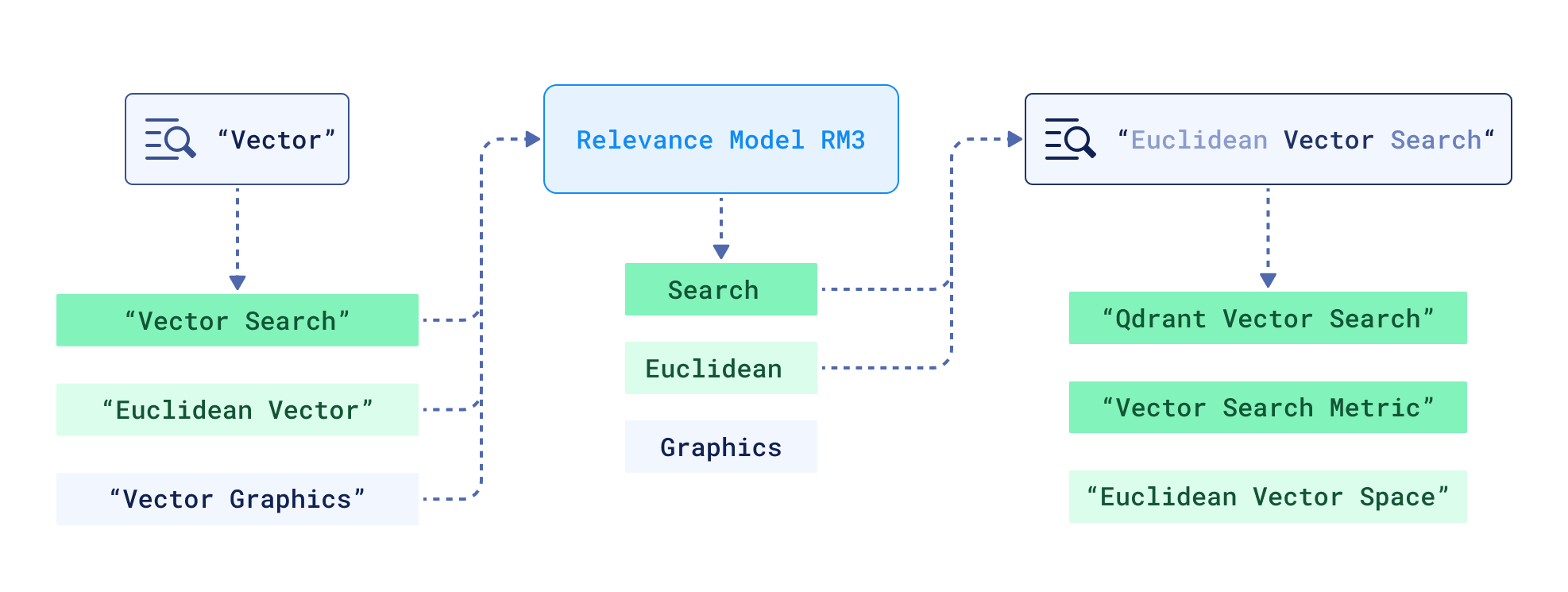
简化查询扩展
随着时间接近现代机器学习时代,多项 研究开始声称,这些传统的查询扩展方法不如其应有的效果。
从基于手工特征的简单分类器开始,这一趋势自然地导致了著名的 BERT (Bidirectional encoder representations from transformers) 的使用。例如,BERT-QE(Query Expansion)的作者提出了这个方案:
- 从经过微调的BERT重排序器中获取伪相关性反馈(约10个文档);
- 将这些伪相关文档分块(约100个词),并使用相同的重排序器对查询-块相关性进行评分;
- 使用最相关的块扩展查询;
- 使用扩展后的查询和重排序器对1000个文档进行重排序。
这种方法在实验中显著优于BM25 + RM3基线(NDCG@20提高了11%)。然而,它所需的计算量比仅使用BERT进行重排序高出11.01倍,并且仅用BERT对1000个文档进行重排序就需要大约9秒。
查询词项扩展理论上也适用于神经检索。新的词项可能会使查询向量更接近所需文档的向量。然而,这种方法并不能保证成功。神经搜索完全依赖于嵌入,而这些嵌入的生成方式——因此,查询和文档向量的相似程度——在很大程度上取决于模型的训练。
如果查询优化是由在同一向量空间中操作的模型完成的,那么它肯定会奏效,这通常需要离线训练检索器。目标是扩展查询编码器输入,使其也包含反馈文档,从而生成一个调整后的查询嵌入。例如 ANCE-PRF 和 ColBERT-PRF——ANCE 和 ColBERT 的微调扩展。
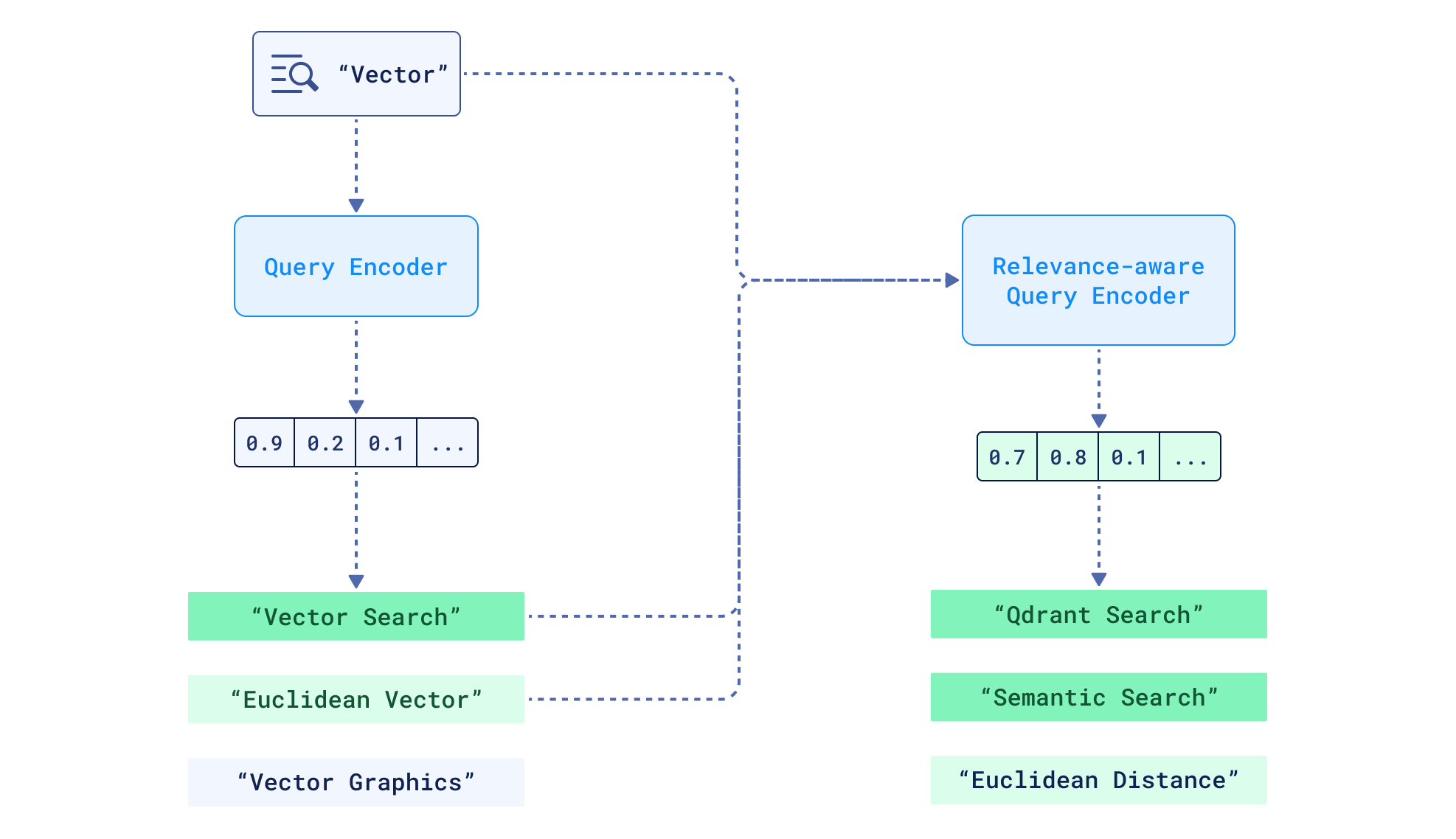
生成一个新的感知相关性的查询向量
你最可能不熟悉这些模型的原因——它们在工业界中的缺失——是因为它们的训练本身就是高昂的前期成本,即使已经“付出”了,这些模型 在泛化方面仍存在困难,在域外任务(它们在训练期间未见过的数据集)上表现不佳。此外,在生产环境中(注意力机制的计算复杂度与输入长度的平方成正比),将冗长的输入(查询+文档)喂给基于注意力的模型不是一个好做法,因为时间和金钱是关键的决策因素。
或者,可以直接跳过一步——直接处理向量。
查询作为向量
与其修改初始查询,更具可扩展性的方法是直接调整查询向量。它很容易跨模态应用,适用于词法检索和神经检索。
尽管向量搜索近年来已成为一种趋势,但其核心原理在该领域已存在数十年。例如,Rocchio于1965年用于其相关性反馈实验的SMART检索系统,就操作于文本的词袋向量表示上。
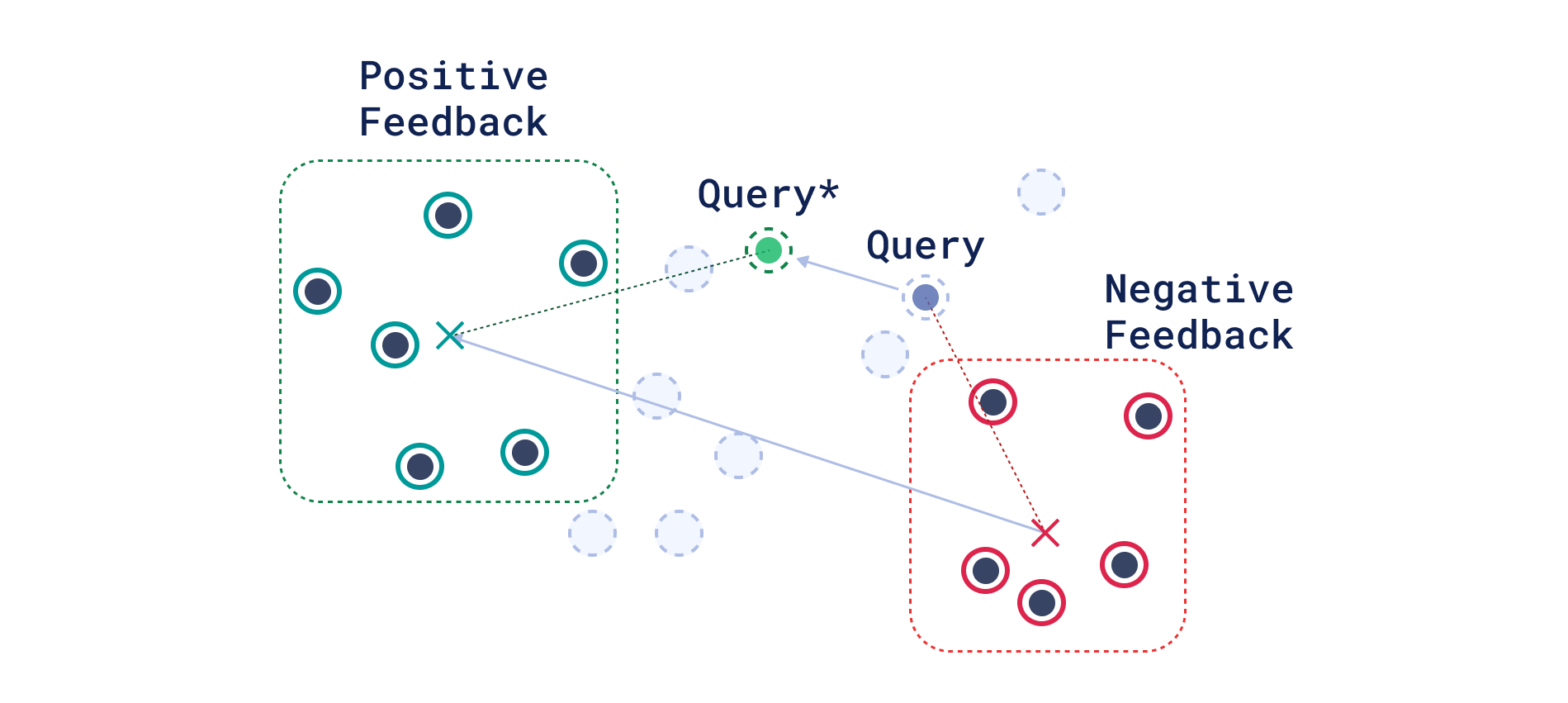
Rocchio的相关性反馈方法
Rocchio 的想法——通过添加相关文档和非相关文档质心之间的差异来更新查询向量——似乎很好地转化到现代基于双编码器的密集检索系统中。研究人员似乎也同意这一点:2022年的一项研究表明,密集检索中 Rocchio 方法的参数化版本 持续将Recall@1000提高1-5%,同时将查询处理时间保持在适合生产的水平——约170毫秒。
然而,Rocchio 方法在密集检索版本中的参数(质心和查询权重)必须针对每个数据集进行调整,理想情况下,还要针对每个请求进行调整。
基于梯度下降的方法
高效即时地进行调整的方法仍是一个悬而未决的问题,直到引入了基于梯度下降的 Rocchio 方法泛化:Test-Time Optimization of Query Representations (TOUR)。TOUR通过多次检索和重新排序迭代(检索→重新排序→梯度下降步骤)来调整查询向量,并由重新排序器的相关性判断进行引导。
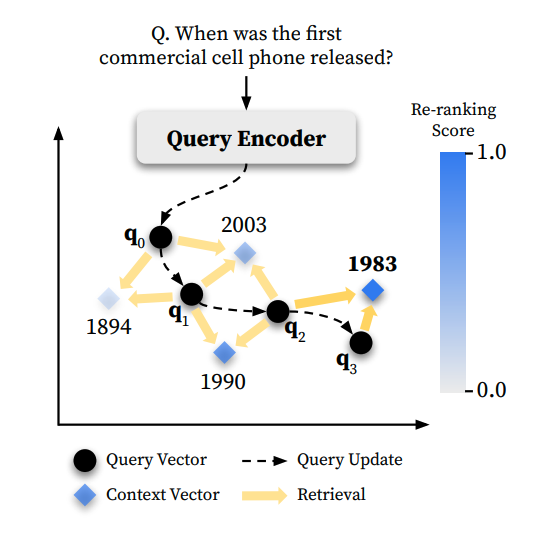
TOUR 基于伪相关性反馈迭代优化初始查询表示的概述。
图片改编自 Sung 等人,2023年,《Optimizing Test-Time Query Representations for Dense Retrieval》
梯度下降查询优化方法的下一个迭代——ReFit——在2024年提出了一种比 TOUR 更轻量、对生产更友好的替代方案,将检索→重排序→梯度下降序列限制为仅一次迭代。检索器的查询向量通过匹配(通过 Kullback–Leibler散度)检索器和交叉编码器在反馈文档上的相似性分数分布来更新。ReFit 独立于模型和语言,并稳定地将Recall@100指标提高2-3%。
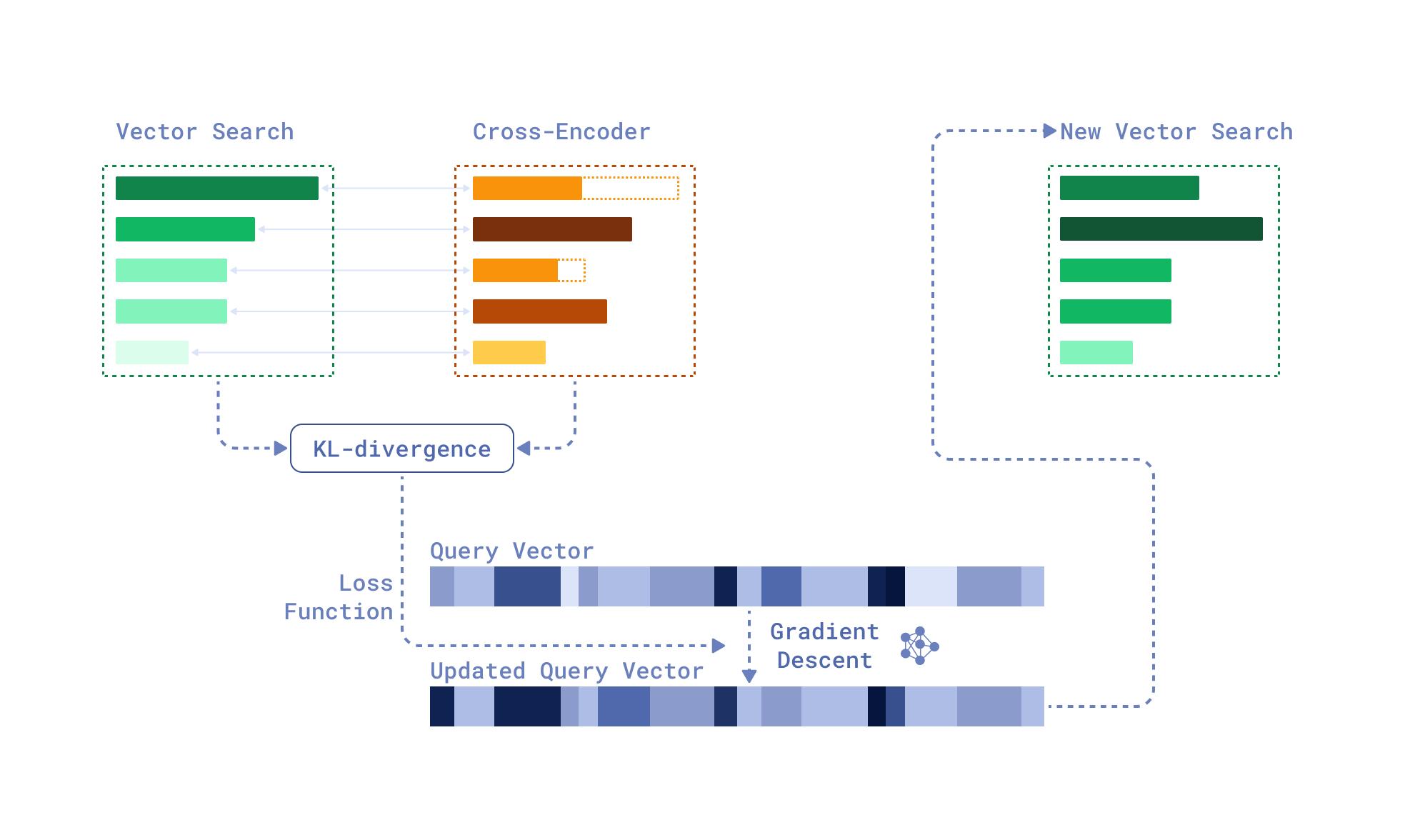
ReFit 概述,一种基于梯度下降的查询优化方法
基于梯度下降的方法似乎是一种生产可行的选择,可以替代微调检索器(从重排序器中提取)。事实上,它不需要提前训练,并且与任何重排序模型兼容。
然而,这些方法中固有的几个局限性阻碍了其在行业中的广泛采用。
基于梯度下降的方法修改查询向量的元素,就好像它们是模型参数一样;因此,它们需要大量的反馈文档才能收敛到稳定的解决方案。
最重要的是,基于梯度下降的方法对超参数的选择很敏感,导致查询漂移,即查询可能会完全偏离用户的意图。
相似性评分
在相似性评分中整合相关性反馈
另一系列方法是围绕着将相关性反馈直接整合到相似性评分函数中的思想而构建的。这在某些情况下可能是理想的,即我们希望保留原始查询意图,但仍根据相关性反馈调整相似性分数。
在词法检索中,这可以很简单,就是提升与被判断为相关的文档共享更多词项的文档。
其神经搜索对应物是一种 基于 k 近邻的方法,它通过添加候选文档与所有已知相关示例之间的相似度总和来调整查询-文档相似度分数。该技术显著提升了 NDCG@20 约 5.6 个百分点,但需要明确标记(由用户)的反馈文档才能有效。
在实验中,基于knn的方法被视为一个重排序器。在所有其他论文中,我们也发现基于相关性反馈调整相似度分数都集中在 重排序 上——即训练或微调重排序器使其感知相关性反馈。通常,实验包括交叉编码器,尽管 简单的分类器也是一个选项。这些方法通常涉及对初始搜索中检索到的更广泛的文档集进行重新评分,并由较小的排名靠前子集的反馈进行引导。这本身并不是相似度匹配函数的调整,而是相似度评分模型的调整。
方法通常分为两类:
- 离线训练重排序器,在推理时将相关性反馈作为额外输入摄入,如这里所示——再次,基于注意力的模型和冗长的输入:一个生产上的致命组合。
- 微调重排序器,利用第一阶段检索的相关性反馈,如 Baumgärtner 等人所做,针对每条查询,在2k个k={2, 4, 8}反馈文档上微调小型交叉编码器的偏置参数。
这里最大的限制是,这些基于重排序器的方法无法检索到初始搜索结果之外的相关文档,而且在生产环境中对数千个文档使用重排序器是不可行的——成本太高。理想情况下,为了避免这种情况,应该在第二次检索迭代中直接使用更新了相关性反馈的相似性评分函数。然而,在我们所遇到的每篇研究论文中,检索系统都被视为黑盒——摄取查询,返回结果,不提供内置机制来修改评分。
那么,有哪些启示呢?
伪相关性反馈(PRF)已知能提高词法检索器的效果。几种基于PRF的方法——主要是基于查询词项扩展的方法——已成功集成到传统检索系统中。同时,在神经(向量)搜索专用解决方案中,尚未有已知的行业采纳的类似方法;神经搜索兼容方法仍停留在研究论文中。
我们在研究该领域时注意到一个空白,即研究人员无法直接访问检索系统,这迫使他们围绕黑盒式的检索预言机设计封装。这对于查询调整方法来说是足够的,但对于相似性评分函数调整则不然。
也许相关性反馈方法没有进入神经搜索系统是因为一些微不足道的原因——比如没有人有时间找到成本和效率之间的正确平衡。
要在生产环境中实现它,意味着要进行实验、构建接口和调整架构。简而言之,它需要看起来值得。与二维向量数学不同,高维向量空间绝非直观。维度诅咒是真实存在的。查询漂移也是。即使在理论上完美的方法,在实践中也可能无效。
一个现实世界的解决方案应该简单。也许比基于规则的方法聪明一点点,但仍然实用。它不应该需要微调数千个参数或向Transformer模型输入冗长的文本段落。为了使其有效,它需要直接集成到检索系统本身。