
您想在您的网站或在线应用程序中插入一个语义搜索功能吗?现在您可以做到这一点——而且无需花费任何金钱!在本示例中,您将学习如何为自己的非商业目的创建一个免费的原型搜索引擎。
所需工具
- Rust 工具链
- cargo lambda (通过包管理器安装,下载二进制文件或
cargo install cargo-lambda) - AWS CLI
- Qdrant 实例(提供免费套餐)
- 您选择的嵌入提供商服务(请参阅我们的嵌入文档。您或许可以从 AI Grant 获得积分,Cohere 也提供速率受限的非商业免费套餐)
- AWS Lambda 账户(提供12个月免费套餐)
您将构建什么
您将把嵌入提供商和 Qdrant 实例结合到一个简洁的语义搜索中,从一个小的 Lambda 函数调用这两个服务。
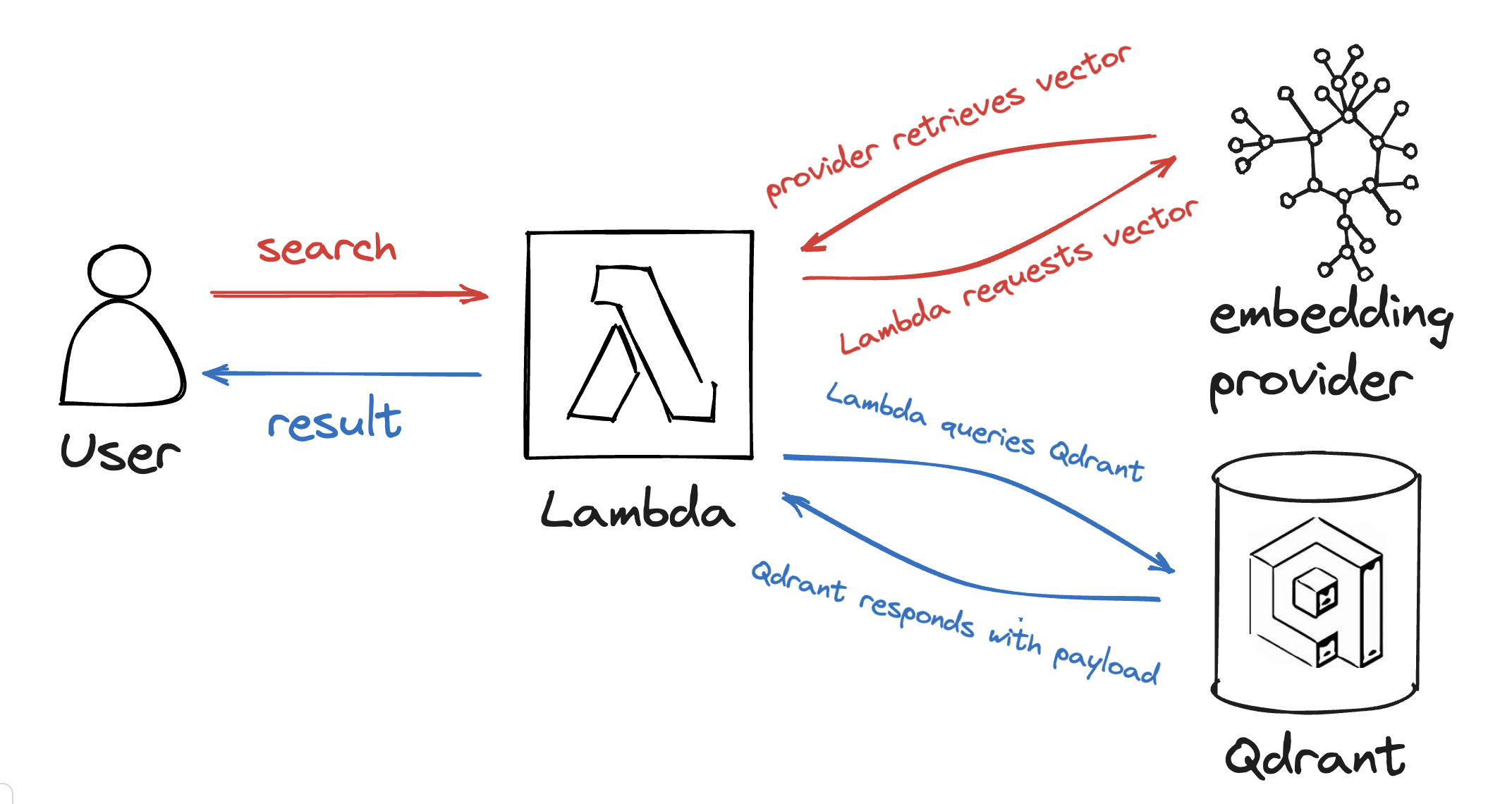
现在让我们看看在连接它们之前如何使用每个组件。
Rust 和 cargo-lambda
您希望您的函数快速、精简且安全,因此使用 Rust 是理所当然的选择。为了将 Rust 代码编译用于 Lambda 函数,cargo-lambda 子命令应运而生。cargo-lambda 可以将您的 Rust 代码打包成一个 zip 文件,AWS Lambda 随后可以在一个精简的 provided.al2 运行时上部署该文件。
要与 AWS Lambda 交互,您需要在 Cargo.toml 中包含以下依赖项的 Rust 项目
[dependencies]
tokio = { version = "1", features = ["macros"] }
lambda_http = { version = "0.8", default-features = false, features = ["apigw_http"] }
lambda_runtime = "0.8"
这为您提供了一个接口,包含一个启动 Lambda 运行时的入口点和一种注册 HTTP 调用处理程序的方式。将以下代码片段放入 src/helloworld.rs 中
use lambda_http::{run, service_fn, Body, Error, Request, RequestExt, Response};
/// This is your callback function for responding to requests at your URL
async fn function_handler(_req: Request) -> Result<Response<Body>, Error> {
Response::from_text("Hello, Lambda!")
}
#[tokio::main]
async fn main() {
run(service_fn(function_handler)).await
}
您还可以使用闭包将其他参数绑定到您的函数处理程序(service_fn 调用将变为 service_fn(|req| function_handler(req, ...)))。此外,如果您想从请求中提取参数,可以使用 Request 方法(例如 query_string_parameters 或 query_string_parameters_ref)。
将以下内容添加到您的 Cargo.toml 中以定义二进制文件
[[bin]]
name = "helloworld"
path = "src/helloworld.rs"
在 AWS 方面,您需要设置一个 Lambda 和 IAM 角色以供您的函数使用。

选择您的函数名称,选择“在 Amazon Linux 2 上提供您自己的引导程序”。架构方面,使用 arm64。您还将激活一个函数 URL。在这里,您可以选择通过 IAM 保护它,或者保持开放,但请注意,开放的端点任何人都可以访问,如果流量过大,可能会产生费用。
默认情况下,这将创建一个基本角色。要查找该角色,您可以进入函数概述
点击“▸ 函数概述”标题旁边的“信息”链接,然后选择左侧的“权限”选项卡。
您将在“执行角色”下方直接找到“角色名称”。记下它以备后用。

要测试您的“Hello, Lambda”服务是否正常工作,您可以编译并上传该函数
$ export LAMBDA_FUNCTION_NAME=hello
$ export LAMBDA_ROLE=<role name from lambda web ui>
$ export LAMBDA_REGION=us-east-1
$ cargo lambda build --release --arm --bin helloworld --output-format zip
Downloaded libc v0.2.137
# [..] output omitted for brevity
Finished release [optimized] target(s) in 1m 27s
$ # Delete the old empty definition
$ aws lambda delete-function-url-config --region $LAMBDA_REGION --function-name $LAMBDA_FUNCTION_NAME
$ aws lambda delete-function --region $LAMBDA_REGION --function-name $LAMBDA_FUNCTION_NAME
$ # Upload the function
$ aws lambda create-function --function-name $LAMBDA_FUNCTION_NAME \
--handler bootstrap \
--architectures arm64 \
--zip-file fileb://./target/lambda/helloworld/bootstrap.zip \
--runtime provided.al2 \
--region $LAMBDA_REGION \
--role $LAMBDA_ROLE \
--tracing-config Mode=Active
$ # Add the function URL
$ aws lambda add-permission \
--function-name $LAMBDA_FUNCTION_NAME \
--action lambda:InvokeFunctionUrl \
--principal "*" \
--function-url-auth-type "NONE" \
--region $LAMBDA_REGION \
--statement-id url
$ # Here for simplicity unauthenticated URL access. Beware!
$ aws lambda create-function-url-config \
--function-name $LAMBDA_FUNCTION_NAME \
--region $LAMBDA_REGION \
--cors "AllowOrigins=*,AllowMethods=*,AllowHeaders=*" \
--auth-type NONE
现在您可以访问您的“函数概述”并点击函数 URL。您应该会看到类似以下内容
Hello, Lambda!
干得漂亮!您已经使用 Rust 设置了一个 Lambda 函数。接下来是下一个工具。
嵌入
大多数提供商都提供一个简单的 HTTPS GET 或 POST 接口,您可以使用 API 密钥,该密钥必须在认证头中提供。如果您将此用于非商业目的,Cohere 的限速试用密钥只需点击几下即可获得。访问他们的欢迎页面,注册后即可进入仪表板,其中有一个“API 密钥”菜单项,将带您进入以下页面:Cohere 仪表板
{kind=link}
从那里您可以点击 API 密钥旁边的 ⎘ 符号将其复制到剪贴板。不要将您的 API 密钥放入代码中!相反,从您可以在 lambda 环境中设置的环境变量中读取它。这可以避免意外地将您的密钥放入公共仓库中。现在您所需要做的就是一些代码来获取嵌入。首先,您需要使用 reqwest 扩展您的依赖项,并添加 anyhow 以简化错误处理
anyhow = "1.0"
reqwest = { version = "0.11.18", default-features = false, features = ["json", "rustls-tls"] }
serde = "1.0"
现在,给定上述 API 密钥,您可以进行调用以获取嵌入向量
use anyhow::Result;
use serde::Deserialize;
use reqwest::Client;
#[derive(Deserialize)]
struct CohereResponse { outputs: Vec<Vec<f32>> }
pub async fn embed(client: &Client, text: &str, api_key: &str) -> Result<Vec<Vec<f32>>> {
let CohereResponse { outputs } = client
.post("https://api.cohere.ai/embed")
.header("Authorization", &format!("Bearer {api_key}"))
.header("Content-Type", "application/json")
.header("Cohere-Version", "2021-11-08")
.body(format!("{{\"text\":[\"{text}\"],\"model\":\"small\"}}"))
.send()
.await?
.json()
.await?;
Ok(outputs)
}
请注意,如果文本超出输入维度,这可能会返回多个向量。Cohere 的 small 模型有 1024 个输出维度。
其他提供商也有类似的接口。请查阅我们的嵌入文档以获取更多信息。看到了吗,获取嵌入的代码是如此之少?
在此过程中,最好编写一个小型测试来检查嵌入是否正常工作以及向量是否具有预期大小
#[tokio::test]
async fn check_embedding() {
// ignore this test if API_KEY isn't set
let Ok(api_key) = &std::env::var("API_KEY") else { return; }
let embedding = crate::embed("What is semantic search?", api_key).unwrap()[0];
// Cohere's `small` model has 1024 output dimensions.
assert_eq!(1024, embedding.len());
}
在设置 API_KEY 环境变量的同时运行此代码,以检查嵌入是否正常工作。
Qdrant 搜索
现在您已经有了嵌入,是时候将它们放入您的 Qdrant 中了。您当然可以使用 curl 或 python 来设置您的集合并上传点,但是由于您已经拥有 Rust,包括一些获取嵌入的代码,您可以继续使用 Rust,并将 qdrant-client 加入其中。
use anyhow::Result;
use qdrant_client::prelude::*;
use qdrant_client::qdrant::{VectorsConfig, VectorParams};
use qdrant_client::qdrant::vectors_config::Config;
use std::collections::HashMap;
fn setup<'i>(
embed_client: &reqwest::Client,
embed_api_key: &str,
qdrant_url: &str,
api_key: Option<&str>,
collection_name: &str,
data: impl Iterator<Item = (&'i str, HashMap<String, Value>)>,
) -> Result<()> {
let mut config = QdrantClientConfig::from_url(qdrant_url);
config.api_key = api_key;
let client = QdrantClient::new(Some(config))?;
// create the collections
if !client.has_collection(collection_name).await? {
client
.create_collection(&CreateCollection {
collection_name: collection_name.into(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: 1024, // output dimensions from above
distance: Distance::Cosine as i32,
..Default::default()
})),
}),
..Default::default()
})
.await?;
}
let mut id_counter = 0_u64;
let points = data.map(|(text, payload)| {
let id = std::mem::replace(&mut id_counter, *id_counter + 1);
let vectors = Some(embed(embed_client, text, embed_api_key).unwrap());
PointStruct { id, vectors, payload }
}).collect();
client.upsert_points(collection_name, points, None).await?;
Ok(())
}
根据您是否想高效地过滤数据,您还可以添加一些索引。为简洁起见,我在此省略了。此外,这并没有实现分块(将数据拆分成多个请求进行插入,从而避免超时错误)。
添加一个合适的 main 方法,您就可以运行此代码来插入点(或者直接使用示例中的二进制文件)。请务必在 qdrant_url 中包含端口。
现在您已经插入了点,可以通过嵌入进行搜索
use anyhow::Result;
use qdrant_client::prelude::*;
pub async fn search(
text: &str,
collection_name: String,
client: &Client,
api_key: &str,
qdrant: &QdrantClient,
) -> Result<Vec<ScoredPoint>> {
Ok(qdrant.search_points(&SearchPoints {
collection_name,
limit: 5, // use what fits your use case here
with_payload: Some(true.into()),
vector: embed(client, text, api_key)?,
..Default::default()
}).await?.result)
}
您还可以通过在 SearchPoints 中添加一个 filter: ... 字段进行过滤,并且您可能希望进一步处理结果,但示例代码已经完成了这些,因此如果您需要此功能,请随时从那里开始。
将它们组合在一起
现在您已经拥有所有部件,是时候将它们连接起来了。将上述代码片段复制并连接起来留作读者的练习。
您会想稍微扩展一下 main 方法,在开始时连接一次客户端,还要从环境中获取 API 密钥,这样您就不需要将它们编译到代码中。为此,您可以从 Rust 代码中通过 std::env::var(_) 获取它们,并从 AWS 控制台设置环境。
$ export QDRANT_URI=<qour Qdrant instance URI including port>
$ export QDRANT_API_KEY=<your Qdrant API key>
$ export COHERE_API_KEY=<your Cohere API key>
$ export COLLECTION_NAME=site-cohere
$ aws lambda update-function-configuration \
--function-name $LAMBDA_FUNCTION_NAME \
--environment "Variables={QDRANT_URI=$QDRANT_URI,\
QDRANT_API_KEY=$QDRANT_API_KEY,COHERE_API_KEY=${COHERE_API_KEY},\
COLLECTION_NAME=${COLLECTION_NAME}"`
无论如何,您最终会得到一个命令行程序来插入数据,以及一个 Lambda 函数。前者可以只是 cargo run 来设置集合。对于后者,您可以再次调用 cargo lambda 和 AWS 控制台
$ export LAMBDA_FUNCTION_NAME=search
$ export LAMBDA_REGION=us-east-1
$ cargo lambda build --release --arm --output-format zip
Downloaded libc v0.2.137
# [..] output omitted for brevity
Finished release [optimized] target(s) in 1m 27s
$ # Update the function
$ aws lambda update-function-code --function-name $LAMBDA_FUNCTION_NAME \
--zip-file fileb://./target/lambda/page-search/bootstrap.zip \
--region $LAMBDA_REGION
讨论
Lambda 的工作方式是,一旦 URL 被调用,它就会启动您的函数,因此除非实际使用,否则它们不需要保持计算资源就绪。这意味着第一次调用将承受大约 1-2 秒的加载函数延迟,后续调用会更快解决。当然,调用嵌入提供商和 Qdrant 也会有延迟。另一方面,免费套餐不收取任何费用,所以您得到的与您支付的完全匹配。对于许多用例,在一两秒内获得结果是可接受的。
Rust 最大限度地减少了函数的开销,无论是在文件大小还是运行时方面。使用嵌入服务意味着您无需关心细节。知道 URL、API 密钥和嵌入大小就足够了。最后,Lambda 和 Qdrant 都提供免费套餐,嵌入提供商也提供免费积分,唯一的成本是您设置所有内容所需的时间。谁能拒绝免费呢?