
想象一个拥有庞大索引卡系统的图书馆。每张索引卡(文档)只标记了针对每本书(文档)的少量关键词(稀疏向量),而可能有的关键词集很大。这就是稀疏向量为文本实现的功能。
什么是稀疏向量和密集向量?
稀疏向量就像数据界的近藤麻理惠——只保留那些让人心动(或此处指相关性)的东西。
考虑一个简化的例子,有两份文档,每份文档包含200个词。一个密集向量将会有几百个非零值,而一个稀疏向量则可能少得多,比如只有20个非零值。
在这个例子中:我们假设它只从每份文档中选择2个词或标记。
dense = [0.2, 0.3, 0.5, 0.7, ...] # several hundred floats
sparse = [{331: 0.5}, {14136: 0.7}] # 20 key value pairs
数字331和14136映射到词汇表中的特定标记,例如['chocolate', 'icecream']。其余的值为零。这就是它被称为稀疏向量的原因。
标记不总是词语,有时它们可以是子词:['ch', 'ocolate']。
它们在信息检索中至关重要,尤其是在排名和搜索系统中。BM25是一种被Elasticsearch等搜索引擎使用的标准排名函数,它就是例证。BM25计算文档与给定搜索查询的相关性。
BM25的能力是公认的,但它也有其局限性。
BM25完全依赖于文档中词语的频率,并不试图理解词语的含义或上下文重要性。此外,它需要提前计算整个语料库的统计数据,这对大型数据集来说是一个挑战。
稀疏向量利用神经网络的力量来克服这些限制,同时保留查询精确词语和短语的能力。它们擅长处理大型文本数据,这使得它们在现代数据处理中至关重要,并标志着对BM25等传统方法的进步。
理解稀疏向量
稀疏向量是一种表示,其中每个维度对应一个词或子词,这极大地有助于解释文档排名。这种清晰性是稀疏向量在现代搜索和推荐系统中必不可少的原因,它补充了含义丰富的嵌入或密集向量。
来自OpenAI Ada-002或Sentence Transformers等模型的密集向量的每个元素都包含非零值。相比之下,稀疏向量专注于每份文档的相对词权重,大多数值为零。这使得系统更加高效和可解释,尤其是在搜索等文本密集型应用中。
稀疏向量在存在许多稀有关键词或专业术语的领域和场景中表现出色。例如,在医学领域,许多稀有术语不出现在通用词汇表中,因此通用密集向量无法捕捉该领域的细微差别。
| 特征 | 稀疏向量 | 稠密向量 |
|---|---|---|
| 数据表示 | 大多数元素为零 | 所有元素均为非零 |
| 计算效率 | 通常更高,尤其是在涉及零元素的操作中 | 较低,因为操作是在所有元素上执行的 |
| 信息密度 | 密度较低,侧重于关键特征 | 密度很高,捕捉细微关系 |
| 应用示例 | 文本搜索,混合搜索 | RAG,许多通用机器学习任务 |
然而,稀疏向量在哪些方面会失败呢?它们不擅长捕捉词语之间细微的关系。例如,它们无法像密集向量那样很好地捕捉“国王”和“女王”之间的关系。
SPLADE
让我们看看SPLADE,一个创建稀疏向量的优秀方法。我们先看一些数字。越高越好。
| 模型 | MRR@10 (MS MARCO Dev) | 类型 |
|---|---|---|
| BM25 | 0.184 | 稀疏 |
| TCT-ColBERT | 0.359 | 密集 |
| doc2query-T5 链接 | 0.277 | 稀疏 |
| SPLADE | 0.322 | 稀疏 |
| SPLADE-max | 0.340 | 稀疏 |
| SPLADE-doc | 0.322 | 稀疏 |
| DistilSPLADE-max | 0.368 | 稀疏 |
所有数字均来自SPLADEv2。MRR是平均倒数排名,是排名的标准指标。MS MARCO是用于评估段落排名和检索的数据集。
SPLADE作为一种方法非常灵活,可以通过调整正则化旋钮来获得不同的模型。
SPLADE更像是一类模型,而非一个特定的模型:根据正则化强度,我们可以获得具有不同属性和性能的不同模型(从非常稀疏的模型到进行密集查询/文档扩展的模型)。
首先,我们来看看如何创建一个稀疏向量。然后,我们将探讨SPLADE背后的概念。
创建稀疏向量
我们将探讨两种不同的创建稀疏向量的方法。一种是利用专门的文档和查询编码器创建高性能稀疏向量的方法。我们将研究一种更简单的方法——这里我们将对文档和查询使用相同的模型。我们将获得一个包含标记ID及其对应权重(表示一个文档)的样本文本字典。
如果您想跟着操作,这里有一个Colab Notebook,备用链接包含所有代码。
设置
from transformers import AutoModelForMaskedLM, AutoTokenizer
model_id = "naver/splade-cocondenser-ensembledistil"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
text = """Arthur Robert Ashe Jr. (July 10, 1943 – February 6, 1993) was an American professional tennis player. He won three Grand Slam titles in singles and two in doubles."""
计算稀疏向量
import torch
def compute_vector(text):
"""
Computes a vector from logits and attention mask using ReLU, log, and max operations.
"""
tokens = tokenizer(text, return_tensors="pt")
output = model(**tokens)
logits, attention_mask = output.logits, tokens.attention_mask
relu_log = torch.log(1 + torch.relu(logits))
weighted_log = relu_log * attention_mask.unsqueeze(-1)
max_val, _ = torch.max(weighted_log, dim=1)
vec = max_val.squeeze()
return vec, tokens
vec, tokens = compute_vector(text)
print(vec.shape)
您会注意到,根据此分词器,文本中有38个标记。这与向量中的标记数量不同。在TF-IDF中,我们只为这些标记或词语分配权重。在SPLADE中,我们使用这个向量和我们学习到的模型,为词汇表中的所有标记分配权重。
术语扩展和权重
def extract_and_map_sparse_vector(vector, tokenizer):
"""
Extracts non-zero elements from a given vector and maps these elements to their human-readable tokens using a tokenizer. The function creates and returns a sorted dictionary where keys are the tokens corresponding to non-zero elements in the vector, and values are the weights of these elements, sorted in descending order of weights.
This function is useful in NLP tasks where you need to understand the significance of different tokens based on a model's output vector. It first identifies non-zero values in the vector, maps them to tokens, and sorts them by weight for better interpretability.
Args:
vector (torch.Tensor): A PyTorch tensor from which to extract non-zero elements.
tokenizer: The tokenizer used for tokenization in the model, providing the mapping from tokens to indices.
Returns:
dict: A sorted dictionary mapping human-readable tokens to their corresponding non-zero weights.
"""
# Extract indices and values of non-zero elements in the vector
cols = vector.nonzero().squeeze().cpu().tolist()
weights = vector[cols].cpu().tolist()
# Map indices to tokens and create a dictionary
idx2token = {idx: token for token, idx in tokenizer.get_vocab().items()}
token_weight_dict = {
idx2token[idx]: round(weight, 2) for idx, weight in zip(cols, weights)
}
# Sort the dictionary by weights in descending order
sorted_token_weight_dict = {
k: v
for k, v in sorted(
token_weight_dict.items(), key=lambda item: item[1], reverse=True
)
}
return sorted_token_weight_dict
# Usage example
sorted_tokens = extract_and_map_sparse_vector(vec, tokenizer)
sorted_tokens
总共有102个排序后的标记。这已经扩展到包括原始文本中没有的标记。这就是我们接下来要讨论的术语扩展。
这里添加了一些术语:“Berlin”和“founder”——尽管没有提及Arthur的种族(导致Owen在柏林获胜)和他作为Arthur Ashe城市健康研究所创始人的工作。以下是一些权重超过1的顶级sorted_tokens。
{
"ashe": 2.95,
"arthur": 2.61,
"tennis": 2.22,
"robert": 1.74,
"jr": 1.55,
"he": 1.39,
"founder": 1.36,
"doubles": 1.24,
"won": 1.22,
"slam": 1.22,
"died": 1.19,
"singles": 1.1,
"was": 1.07,
"player": 1.06,
"titles": 0.99,
...
}
如果您对使用高性能方法感兴趣,请查看以下模型
SPLADE为何有效:术语扩展
考虑一个查询“太阳能优势”。SPLADE可能会将其扩展为包括“可再生”、“可持续”和“光伏”等术语,这些术语在上下文中相关但未明确提及。这个过程称为术语扩展,它是SPLADE的关键组成部分。
SPLADE学习查询/文档扩展以包含其他相关术语。这是相对于其他稀疏方法的关键优势,因为其他稀疏方法只包含精确的词语,但完全忽略了上下文相关的词语。
这种扩展与我们在构建SPLADE模型时可以控制的因素有着直接关系:通过正则化实现稀疏性。我们用来表示每个文档的标记(BERT词片)的数量。如果我们使用更多的标记,我们可以表示更多的术语,但向量会变得更密集。这个数量通常在每个文档20到200之间。作为参考点,密集BERT向量是768维,OpenAI嵌入是1536维,而稀疏向量是30维。
例如,假设有一个1M文档语料库。假设我们每个文档使用100个稀疏标记ID+权重。相应地,密集BERT向量将是768M浮点数,OpenAI嵌入将是1.536B浮点数,稀疏向量最多是100M整数+100M浮点数。这可能意味着内存使用减少10倍,这对于大型系统来说是一个巨大的胜利。
| 向量类型 | 内存 (GB) |
|---|---|
| 密集BERT向量 | 6.144 |
| OpenAI嵌入 | 12.288 |
| 稀疏向量 | 1.12 |
SPLADE的工作原理:利用BERT
SPLADE利用Transformer架构生成文档和查询的稀疏表示,从而实现高效检索。让我们深入了解这个过程。
Transformer骨干网络的输出 logits 是SPLADE构建的基础输入。Transformer架构可以是BERT这样熟悉的模型。SPLADE不是生成密集的概率分布,而是利用这些 logits 构建稀疏向量——将它们视为标记的精髓,其中每个维度对应于词汇表中的一个术语及其在给定文档或查询上下文中的关联权重。
这种稀疏性至关重要;它反映了典型掩码语言建模任务中的概率分布,但经过调整以提高检索效率,强调那些既
- 上下文相关:能很好地代表文档的术语应赋予更多权重。
- 文档间具有区分性:文档拥有而其他文档不具备的术语应赋予更多权重。
您在标准Transformer模型中期望的标记级分布,现在在SPLADE中被转化为标记级重要性分数。这些分数反映了每个术语在文档或查询上下文中的重要性,引导模型将更多权重分配给那些可能对检索目的更有意义的术语。
由此产生的稀疏向量不仅节省内存,而且经过定制,可在Qdrant等搜索引擎的高维空间中实现精确匹配。
解读 SPLADE
密集向量的一个缺点是它们不可解释,这使得难以理解文档与查询相关的具体原因。
SPLADE的重要性估计可以洞察文档与查询相关的“为什么”。通过阐明哪些标记对检索分数贡献最大,SPLADE在性能的同时提供了一定程度的可解释性,这在神经IR系统领域中是罕见的。对于从事搜索工作的工程师来说,这种透明度是无价的。
SPLADE的已知局限性
池化策略
SPLADE中改用最大池化策略,提升了其在MS MARCO和TREC数据集上的表现。然而,这表明SPLADE基线池化方法存在潜在局限性,暗示SPLADE的性能对池化策略的选择敏感。
文档和查询编码器
使用最大池化但没有查询编码器的SPLADE模型变体达到了与先前SPLADE模型相同的性能水平。这表明查询编码器的必要性存在局限,可能影响模型的效率。
其他稀疏向量方法
SPLADE并不是创建稀疏向量的唯一方法。
本质上,稀疏向量是TF-IDF和BM25的超集,这两种方法是最流行的文本检索方法。换句话说,您可以使用词频和逆文档频率(TF-IDF)创建稀疏向量,以精确再现BM25分数。
此外,来自Sentence Transformers的注意力权重可用于创建稀疏向量。此方法保留了查询精确单词和短语的能力,但避免了SPLADE中使用的查询扩展的计算开销。
我们将在未来的文章中详细介绍这些方法。
利用Qdrant中的稀疏向量实现混合搜索
Qdrant支持稀疏向量的独立索引。这使您可以在同一个集合中同时使用密集向量和稀疏向量。Qdrant中的每个“点”都可以同时拥有密集向量和稀疏向量。
但我们首先来看看如何在Qdrant中使用稀疏向量。
Python 中的实际实现
让我们通过一个示例深入了解Qdrant如何处理稀疏向量。以下是我们将涵盖的内容:
设置 Qdrant 客户端:首先,我们使用 QdrantClient 建立与 Qdrant 的连接。此设置对后续操作至关重要。
创建支持稀疏向量的集合:在 Qdrant 中,集合是向量的容器。在这里,我们创建一个专门设计用于支持稀疏向量的集合。这通过 create_collection 方法完成,在该方法中我们定义稀疏向量的参数,例如设置索引配置。
插入稀疏向量:一旦集合设置完成,我们就可以向其中插入稀疏向量。这包括定义具有其索引和值的稀疏向量,然后将此点 upsert 到集合中。
使用稀疏向量查询:为了执行搜索,我们首先准备一个查询向量。这涉及从查询文本计算向量并提取其索引和值。然后,我们使用这些详细信息构建针对我们集合的查询。
检索和解释结果:搜索操作返回的结果包括匹配文档的 ID、其版本、相似性分数和其他相关详细信息。分数是关键方面,反映了查询与集合中文档之间的相似性。
1. 设置
# Qdrant client setup
client = QdrantClient(":memory:")
# Define collection name
COLLECTION_NAME = "example_collection"
# Insert sparse vector into Qdrant collection
point_id = 1 # Assign a unique ID for the point
2. 创建一个支持稀疏向量的集合
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
index=models.SparseIndexParams(
on_disk=False,
)
)
},
)
3. 插入稀疏向量
这里,我们看到了将稀疏向量插入Qdrant集合的过程。这一步对于构建可在检索过程第一阶段快速检索的数据集至关重要,它利用了稀疏向量的效率。由于这是用于演示目的,我们只插入一个带有稀疏向量而没有密集向量的点。
client.upsert(
collection_name=COLLECTION_NAME,
points=[
models.PointStruct(
id=point_id,
payload={}, # Add any additional payload if necessary
vector={
"text": models.SparseVector(
indices=indices.tolist(), values=values.tolist()
)
},
)
],
)
通过upsert带有稀疏向量的点,我们为快速第一阶段检索准备了数据集,为后续使用密集向量进行详细分析奠定了基础。请注意,我们使用“text”来表示稀疏向量的名称。
熟悉Qdrant API的人会注意到,我们特别注意与现有命名向量API保持一致——这是为了让在现有代码库中使用稀疏向量变得更容易。一如既往,您可以使用应用有效负载过滤器、分片键以及您对Qdrant所期望的其他高级功能。为了方便您,索引和值在upsert之前无需排序。Qdrant将在索引持久化时(例如在磁盘上)对其进行排序。
4. 使用稀疏向量进行查询
我们使用相同的过程来准备查询向量。这包括从查询文本计算向量并提取其索引和值。然后,我们使用这些详细信息构建针对我们集合的查询。
# Preparing a query vector
query_text = "Who was Arthur Ashe?"
query_vec, query_tokens = compute_vector(query_text)
query_vec.shape
query_indices = query_vec.nonzero().numpy().flatten()
query_values = query_vec.detach().numpy()[query_indices]
在此示例中,我们对文档和查询使用相同的模型。这不是必需的,但它是一种更简单的方法。
5. 检索和解释结果
在设置完集合并插入稀疏向量之后,下一个关键步骤是检索和解释结果。此过程涉及执行搜索查询,然后分析返回的结果。
# Searching for similar documents
result = client.search(
collection_name=COLLECTION_NAME,
query_vector=models.NamedSparseVector(
name="text",
vector=models.SparseVector(
indices=query_indices,
values=query_values,
),
),
with_vectors=True,
)
result
在上述代码中,我们使用准备好的稀疏向量查询对我们的集合执行搜索。client.search方法将集合名称和查询向量作为输入。查询向量是使用models.NamedSparseVector构建的,其中包含从查询文本派生的索引和值。这是有效检索相关文档的关键步骤。
ScoredPoint(
id=1,
version=0,
score=3.4292831420898438,
payload={},
vector={
"text": SparseVector(
indices=[2001, 2002, 2010, 2018, 2032, ...],
values=[
1.0660614967346191,
1.391068458557129,
0.8903818726539612,
0.2502821087837219,
...,
],
)
},
)
如上所示,结果是一个ScoredPoint对象,包含检索到的文档ID、其版本、相似性分数和稀疏向量。分数是关键元素,因为它量化了查询和文档之间基于各自向量的相似性。
为了理解这种评分的工作原理,我们使用熟悉的点积方法:
$$\text{Similarity}(\text{Query}, \text{Document}) = \sum_{i \in I} \text{Query}_i \times \text{Document}_i$$
该公式通过将查询向量和文档向量的对应元素相乘并求和这些乘积来计算相似度分数。这种方法对于稀疏向量尤其有效,其中许多元素为零,从而导致计算高效的过程。分数越高,查询和文档之间的相似度越大,使其成为评估检索文档相关性的有价值指标。
混合搜索:结合稀疏向量和密集向量
通过结合来自密集向量和稀疏向量的搜索结果,您可以实现一种既高效又准确的混合搜索。稀疏向量的结果将保证返回所有包含所需关键词的结果,而密集向量将涵盖语义相似的结果。
密集结果和稀疏结果的混合可以直接呈现给用户,或者用作两阶段检索过程的第一阶段。
让我们看看如何在 Qdrant 中进行混合搜索查询。
首先,您需要创建一个同时包含密集向量和稀疏向量的集合
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config={
"text-dense": models.VectorParams(
size=1536, # OpenAI Embeddings
distance=models.Distance.COSINE,
)
},
sparse_vectors_config={
"text-sparse": models.SparseVectorParams(
index=models.SparseIndexParams(
on_disk=False,
)
)
},
)
然后,假设您已插入了密集向量和稀疏向量,您可以将它们一起查询
query_text = "Who was Arthur Ashe?"
# Compute sparse and dense vectors
query_indices, query_values = compute_sparse_vector(query_text)
query_dense_vector = compute_dense_vector(query_text)
client.search_batch(
collection_name=COLLECTION_NAME,
requests=[
models.SearchRequest(
vector=models.NamedVector(
name="text-dense",
vector=query_dense_vector,
),
limit=10,
),
models.SearchRequest(
vector=models.NamedSparseVector(
name="text-sparse",
vector=models.SparseVector(
indices=query_indices,
values=query_values,
),
),
limit=10,
),
],
)
结果将是一对结果列表,一个用于密集向量,一个用于稀疏向量。
有了这些结果,有几种方法可以组合它们
混合或融合
您可以纯粹根据密集向量和稀疏向量的相对分数混合它们的结果。这是一种简单有效的方法,但它没有考虑到结果之间的语义相似性。流行的混合方法包括:
- Reciprocal Ranked Fusion (RRF)
- Relative Score Fusion (RSF)
- Distribution-Based Score Fusion (DBSF)
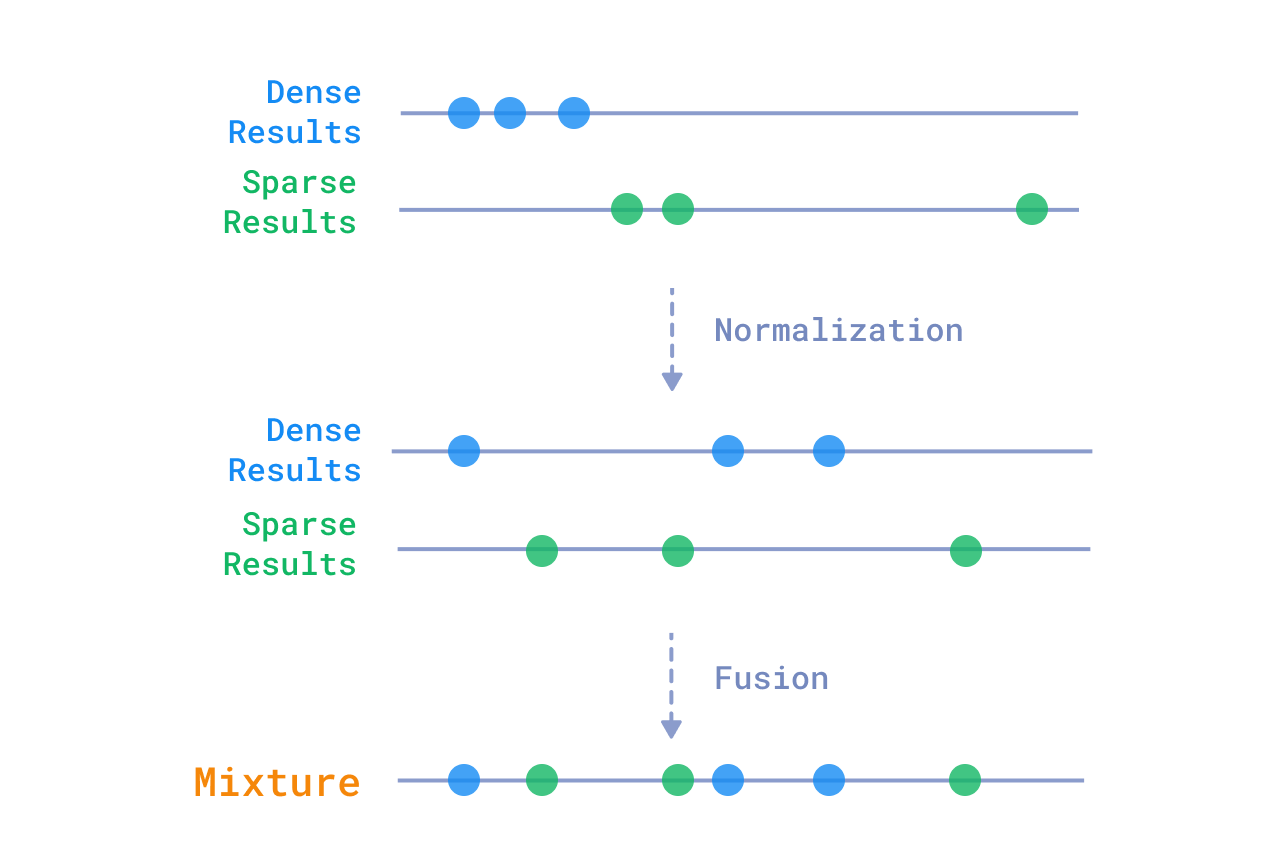
相对分数融合
Ranx是一个用于混合来自不同来源结果的优秀库。
重排序
您可以使用获得的结果作为两阶段检索过程的第一阶段。在第二阶段,您可以使用更复杂的模型,例如交叉编码器或Cohere Rerank等服务,对第一阶段的结果进行重新排序。
就是这样!您已成功使用 Qdrant 实现混合搜索!
其他资源
对于那些想要深入研究的人,这里有关于该主题的顶级论文,其中大部分都提供了代码。
- 问题动机:稀疏超完备词向量表示
- SPLADE v2:用于信息检索的稀疏词汇和扩展模型
- SPLADE:用于第一阶段排名的稀疏词汇和扩展模型
- 后期交互 - ColBERTv2:通过轻量级后期交互实现高效检索
- SparseEmbed:通过上下文嵌入学习稀疏词汇表示以进行检索
为什么只阅读而不亲自动手尝试呢?
我们为您准备了一个易于使用的 Colab,演示如何创建稀疏向量:稀疏向量单编码器演示。运行它,调整它,开始在您的项目中看到奇迹的展开。我们迫不及待地想听听您如何使用它!
结论
好了,各位,我们总结一下。更好的搜索不再是“锦上添花”,而是“颠覆性改变”,Qdrant 可以助您实现这一目标。
有问题吗?我们的Discord社区充满了答案。
如果您喜欢阅读本文,何不订阅我们的新闻简报,以保持领先。
当然,非常感谢我们的读者,是你们推动我们为所有人改进排名。