
向量相似性:释放超越传统搜索的数据洞察
在使用非结构化数据时,开发者们有众所周知的传统首选解决方案
- 全文搜索:当您需要查找包含特定单词或短语的文档时。
- 向量搜索:当您需要查找与给定查询在语义上相似的文档时。
有时人们会混淆这两种方法,因此向量相似性可能看起来只是全文搜索的延伸。然而,在本文中,我们将探索一些有前途的新技术,这些技术可以扩展非结构化数据的使用场景,并证明向量相似性创建了自己的数据探索工具栈。
什么是向量相似性搜索?
向量相似性提供了一系列强大的功能,远远超出了传统全文搜索引擎所提供的功能。从不相似性搜索到多样性和推荐,这些方法可以扩展向量的应用范围。
向量数据库专为存储和处理海量向量而设计,是实现这些新技术的首选,并允许用户充分利用他们的数据。
向量相似性搜索与全文搜索
虽然这两种方法在功能上存在交叉,但它们各自也拥有独特的广阔功能领域。例如,精确短语匹配和结果计数是全文搜索的固有功能,而向量相似性对此类操作的支持有限。另一方面,向量相似性可以轻松实现文本对图像或反向的跨模态检索,这对于全文搜索来说是不可能实现的。
这种期望上的不匹配有时可能会导致混淆。试图将向量相似性用作全文搜索可能会导致一系列挫折,从响应时间慢到搜索结果差,再到功能受限。结果是,他们只获得了向量相似性益处的一小部分。
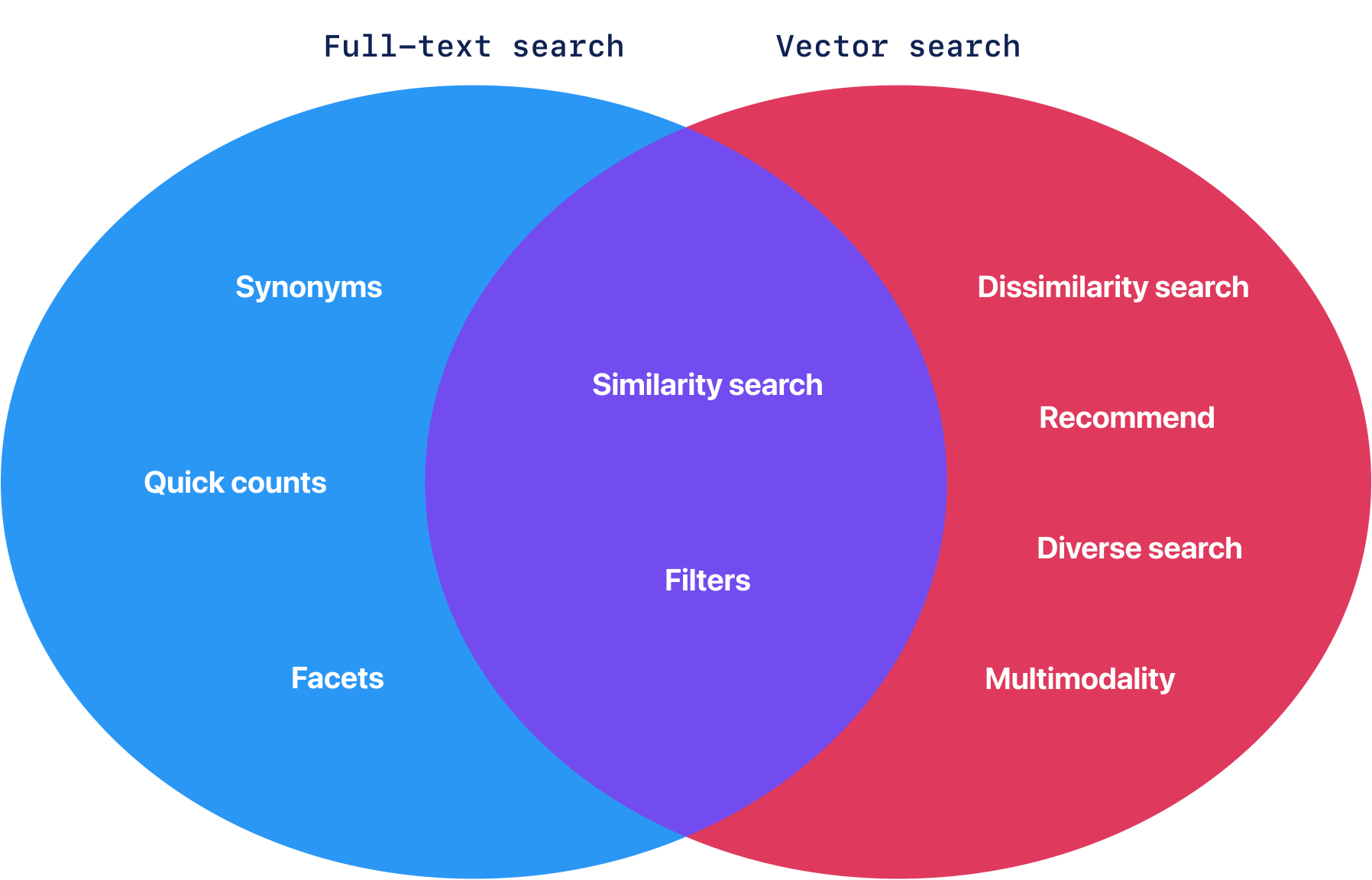
全文搜索和向量相似性功能重叠
下面我们将探讨为什么向量相似性栈值得拥有新的接口和设计模式,这将释放这项技术的全部潜力,同时它仍然可以与全文搜索结合使用。
与相似性交互的新方式
拥有非结构化数据的向量表示,可以解锁与之交互的新方式。例如,它可以用于测量单词之间的语义相似性,根据它们的含义对单词或文档进行聚类,查找相关图像,甚至生成新文本。然而,这些交互可以超越查找它们的最近邻(kNN)。
除了传统的 kNN 搜索之外,还有其他几种可以利用向量表示的技术。这些包括不相似性搜索、多样性搜索、推荐和发现功能。
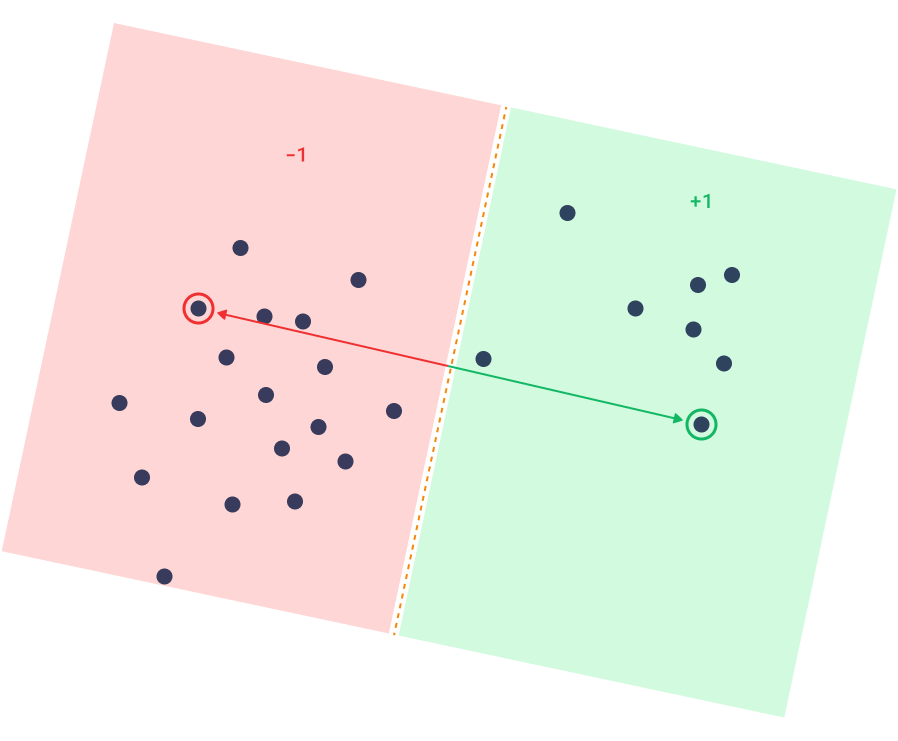
不相似性搜索
不相似性(或最远)搜索是最近邻搜索之后最直接的概念,这在传统全文搜索中无法重现。它旨在在集合中找到最不相似或最远的文档。
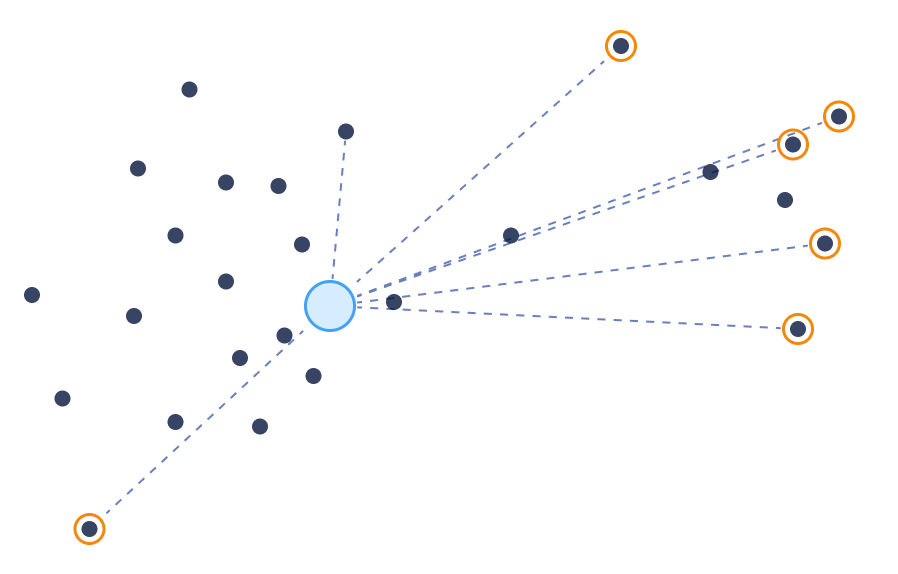
不相似性搜索
与全文匹配不同,向量相似性可以比较任意一对文档(或点)并分配相似性分数。它不依赖于关键词或其他元数据。通过向量相似性,我们可以通过将搜索目标从最大化相似性反转为最小化相似性来轻松实现不相似性搜索。
不相似性搜索可以在以前任何其他搜索都无法使用的领域中找到项目。让我们看几个例子。
案例:错误标注检测
例如,我们有一个家具数据集,我们将项目分类为它们是什么类型的家具:桌子、椅子、灯具等。为了确保我们的目录准确,我们可以使用不相似性搜索来突出显示最有可能被错误标注的项目。
为此,我们只需要使用类别标题本身的嵌入作为查询来搜索最不相似的项目。这可能过于宽泛,因此,通过将其与过滤器——Qdrant 的超能力——结合,我们可以将搜索范围缩小到特定类别。

错误标注检测
此搜索的输出可以由更复杂的模型或人工监督进行进一步处理,以检测实际的错误标注。
案例:异常值检测
在某些情况下,我们可能甚至没有标签,但仍然可以尝试检测数据集中的异常。不相似性搜索也可以用于此目的。
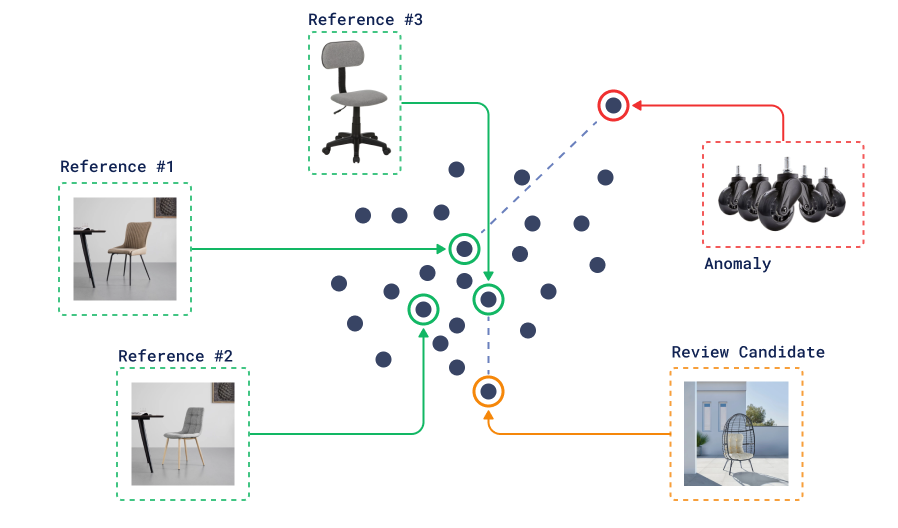
异常检测
我们唯一需要的是一堆我们认为是“正常”的参考点。然后我们可以搜索与此参考集最不相似的点,并将它们用作进一步分析的候选点。
多样性搜索
即使没有提供向量输入,(不)相似性也可以改善数据集中的整体项目选择。
天真的方法是进行随机抽样。然而,除非我们的数据集具有均匀分布,否则这种抽样的结果可能会偏向于更频繁的项目类型。

随机抽样的例子
相似性信息可以增加这些结果的多样性,并使首次概览更具吸引力。这对于用户尚不清楚他们在寻找什么并想要探索数据集时特别有用。

基于相似性的抽样示例
向量相似性的强大之处在于能够比较任意两个点,这使得在没有任何标注工作的情况下实现集合的多样化选择成为可能。通过最大化响应中所有点之间的距离,我们可以拥有一个将按顺序输出不相似结果的算法。
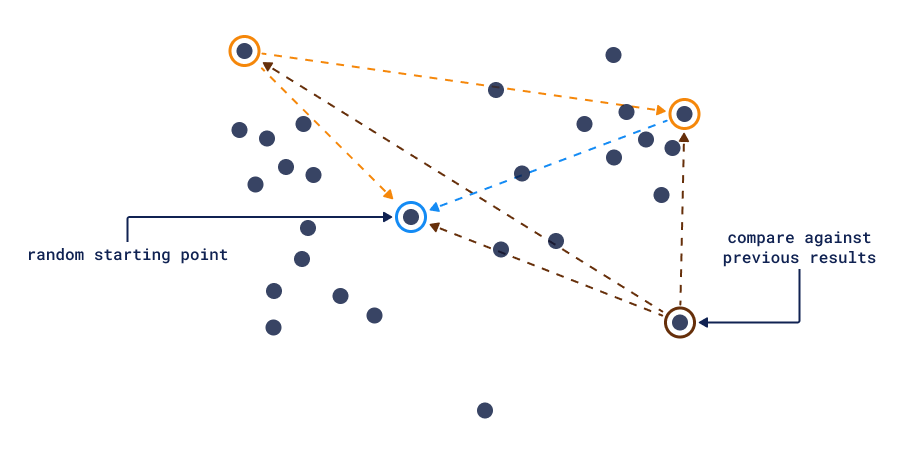
多样性搜索
行业中已经使用了一些形式的多样性抽样,并被称为最大边缘相关性(MMR)。像这样的技术是为了增强通用搜索 API 上的相似性而开发的。然而,仍然有新的想法的空间,特别是在多样性检索方面。通过利用更先进的向量原生引擎,有可能将用例提升到新的水平并获得更好的结果。
向量相似性推荐
向量相似性可以超越单个查询向量。它可以结合多个正向和负向示例以实现更准确的检索。在向量数据库中构建推荐 API 可以利用将已存储的向量作为查询的一部分,通过指定点 ID。这样做,我们可以跳过查询时神经网络推理,使推荐搜索更快。
有多种方法可以使用向量实现推荐。
向量特征推荐
第一种方法是获取所有正向和负向示例并将它们平均以创建一个单一的查询向量。在这种技术中,正向向量中更重要的分量被负向分量抵消,结果向量是正向示例中存在但负向示例中不存在的所有特征的组合。
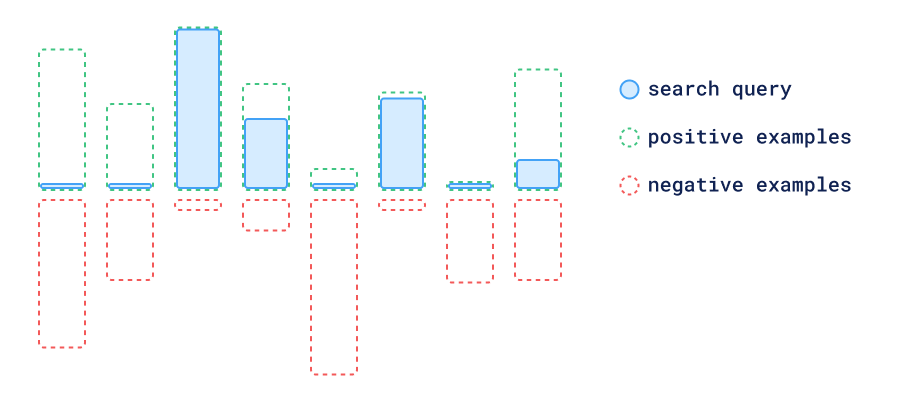
基于向量特征的推荐
这种方法已经在 Qdrant 中实现,虽然当向量被假定为每个维度代表某种数据特征时,它的效果很好,但有时距离是判断正负例的更好工具。
相对距离推荐
另一种方法是使用负向示例到候选对象的距离来帮助它们创建排除区域。在这种技术中,我们在正向示例附近执行搜索,同时排除那些距离负向示例比距离正向示例更近的点。
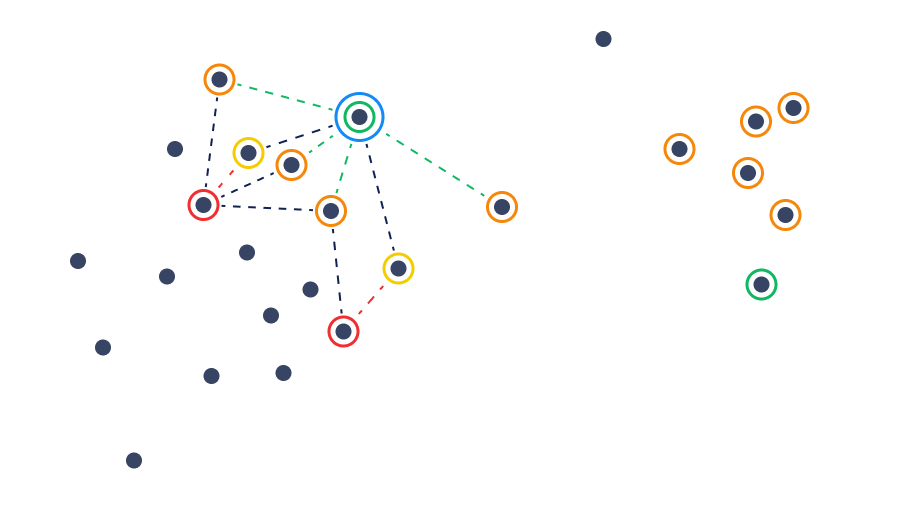
相对距离推荐
这两种方法的主要用例——当然——是获取用户交互的历史记录,并基于此推荐新项目。
发现
在许多探索场景中,期望的目的地是事先未知的。在这种情况下,搜索过程可以包括多个步骤,每个步骤都会提供更多信息以指导搜索朝着正确的方向进行。
为了更直观地了解实现此方法的可能方式,让我们首先看看相似性模型是如何训练的
用于训练相似性模型最著名的损失函数是三元组损失。在这种损失中,模型通过拟合 3 个对象的相对相似性信息进行训练:锚点、正例和负例。
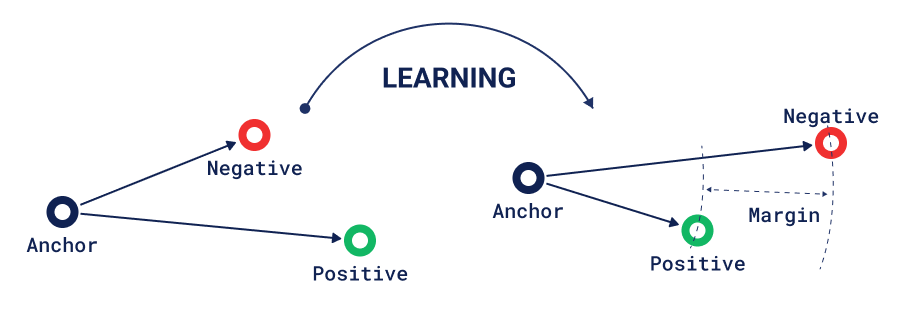
三元组损失
使用相同的机制,我们可以从另一方面来看待训练过程。给定一个训练好的模型,用户可以提供正向和负向示例,然后发现过程的目标是在存储的向量集合中找到合适的锚点。
反向三元组损失
可以提供多个正向-负向对,以使发现过程更准确。值得一提的是,就像神经网络训练一样,数据集可能包含噪声和一部分矛盾信息,因此发现过程应该能够容忍此类数据缺陷。
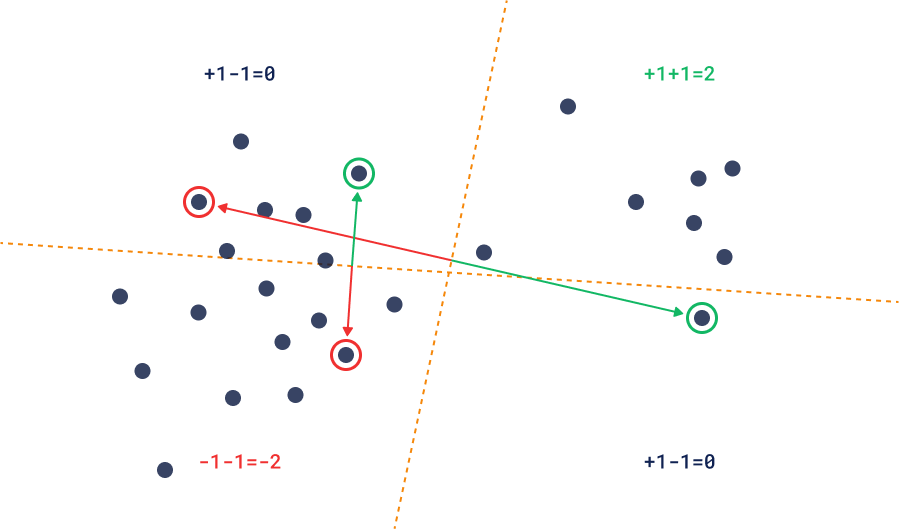
样本对
此方法与推荐方法之间的重要区别在于,发现方法中的正向-负向对并不假设最终结果应该接近正向,它只假设它应该比负向更接近。
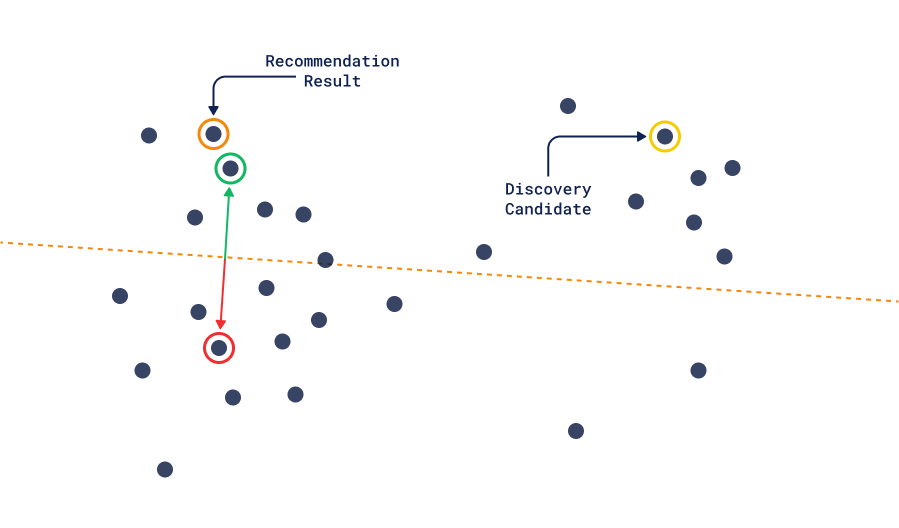
发现与推荐
结合过滤或相似性搜索,发现对提供的额外上下文信息可以用作重新排序因子。
向量数据库的新 API 栈
当您将向量相似性功能引入文本搜索引擎时,您会扩展其功能。然而,反过来则不然,因为向量相似性作为一个概念比某些针对特定任务的全文搜索实现要宽泛得多。
向量数据库,引入了内置的全文功能,必须做出一些妥协
- 选择特定的全文搜索变体。
- 要么牺牲 API 一致性,要么将向量相似性功能限制为仅基本的 kNN 搜索。
- 给系统引入额外的复杂性。
Qdrant 相反,将向量相似性置于其 API 和架构的核心,从而使我们能够迈向新的向量原生操作栈。我们相信这是向量数据库的未来,我们很高兴看到这些技术将解锁哪些新的用例。
主要收获
- 向量相似性提供了超越传统全文搜索的先进数据探索工具,包括不相似性搜索、多样性抽样和推荐系统。
- 向量相似性的实际应用包括通过错误标注检测和异常识别来提高数据质量。
- 通过利用高级搜索技术、为用户提供直观的数据探索和改进决策过程,实现了增强的用户体验。
准备好释放数据的全部潜力了吗?免费试用演示,探索向量相似性如何彻底改变您的数据洞察力并推动更明智的决策。