
嵌入是输入数据语义的数值机器学习表示。它们将复杂的、高维的数据(如文本、图像或音频)的含义捕获到向量中,使算法能够更有效地处理和分析数据。
你知道当你刷社交媒体时,内容感觉就像为你量身定制一样吗?有你关心的新闻,接着是一个关于你最喜欢的技术栈的完美教程,然后是一个让你笑到喷鼻子的表情包。
或者YouTube如何推荐你最终喜欢的视频?这些视频来自你从未听过的创作者,而且你甚至没有给YouTube发消息说明你理想的内容偏好。
这就是嵌入的神奇之处。
这些是**深度学习模型**分析你在网上的互动数据的结果。包括你的点赞、分享、评论、搜索、你停留的内容类型,甚至是你决定跳过的内容。它还允许算法预测你未来可能会喜欢的内容。
相同的嵌入可以用于搜索、广告和其他功能,创造高度个性化的用户体验。
它们使高维数据更容易管理。这减少了存储需求,提高了计算效率,并使得海量**非结构化**数据变得有意义。
为什么使用向量嵌入?
自然语言的**细微差别**或图像、声音或用户交互的大数据集中隐藏的**意义**很难放入表格中。传统的关系型数据库无法有效地查询当前使用和产生的大多数类型的数据,使得这些信息的**检索**非常有限。
在嵌入空间中,同义词倾向于出现在相似的上下文中,并最终拥有相似的嵌入。这个空间是一个足够聪明的系统,能够理解“pretty”和“attractive”是同类词,而无需被明确告知。
这就是神奇之处。
向量嵌入的核心在于语义。它们采纳了“词语的意义由其伴随的词语决定”的想法,并将其应用于大规模场景。

这种能力对于创建搜索系统、推荐引擎、检索增强生成(RAG)以及任何受益于对内容深入理解的应用至关重要。
嵌入是如何工作的?
嵌入是通过神经网络创建的。它们将复杂的关系和语义捕获到密集向量中,这些向量更适合机器学习和数据处理应用。然后,它们可以将这些向量投影到适当的**高维**空间中,特别是向量数据库。
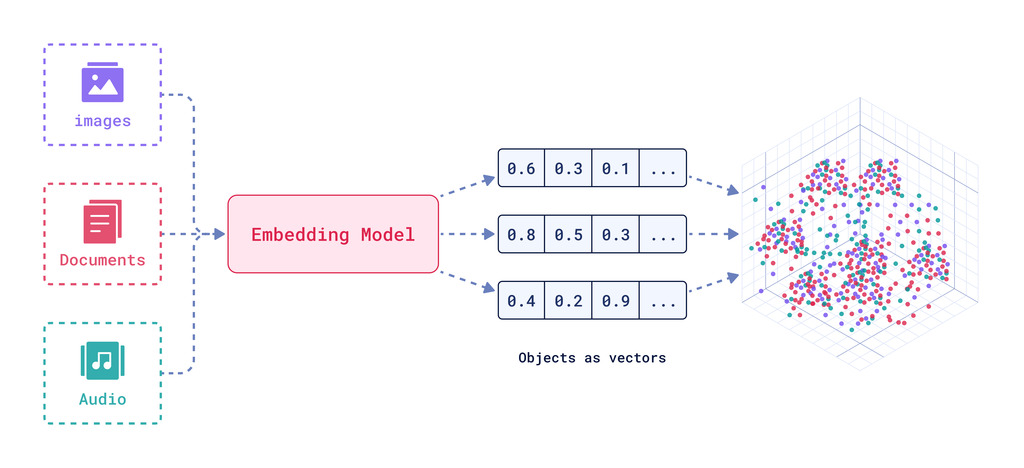
数据点的意义由其在向量空间中的**位置**隐式定义。向量存储后,我们可以利用它们的空间属性进行最近邻搜索。这些搜索根据项目在这个空间中的接近程度来检索语义相似的项目。
向量表示的质量决定了性能。最适合你的嵌入模型取决于你的用例。
创建向量嵌入
嵌入将人类语言的复杂性转化为计算机可以理解的格式。它使用神经网络为输入数据分配**数值**,使得相似的数据具有相似的值。
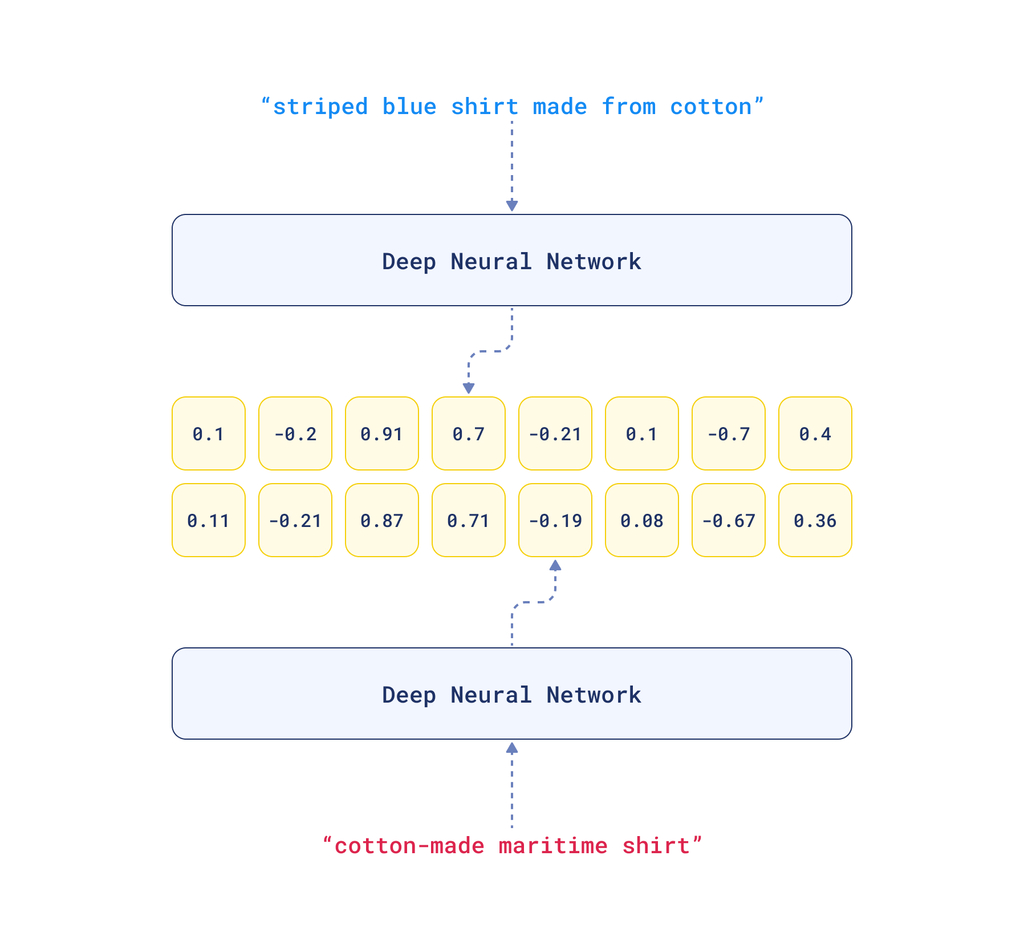
例如,如果我想让我的计算机理解“right”这个词,我可以给它分配一个数值,比如1.3。所以当我的计算机看到1.3时,它就知道是“right”这个词。
现在我想让我的计算机理解“right”这个词的上下文。我可以使用一个二维向量,比如[1.3, 0.8],来表示“right”。第一个数值1.3仍然标识“right”这个词,但第二个数值0.8指定了上下文。
我们可以引入更多的维度来捕获更多的细微差别。例如,第三个维度可以表示词语的正式程度,第四个维度可以表示其情感含义(积极、中立、消极),等等。
这一概念的演变导致了Word2Vec和GloVe等嵌入模型的发展。它们学习理解词语出现的上下文,为每个词生成高维向量,捕获远更复杂的属性。
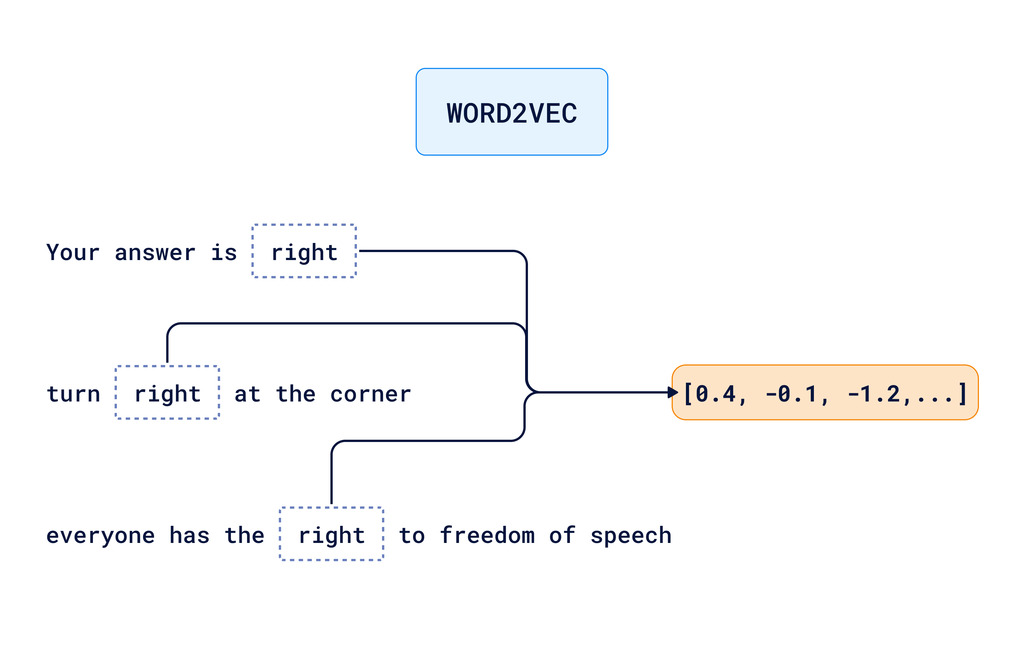
然而,这些模型仍然存在局限性。它们根据词语在文本中的用法为每个词生成一个单独的向量。这意味着“right”这个词的所有细微差别都被糅合到一个向量表示中。这对于计算机来说,信息不足以完全理解上下文。
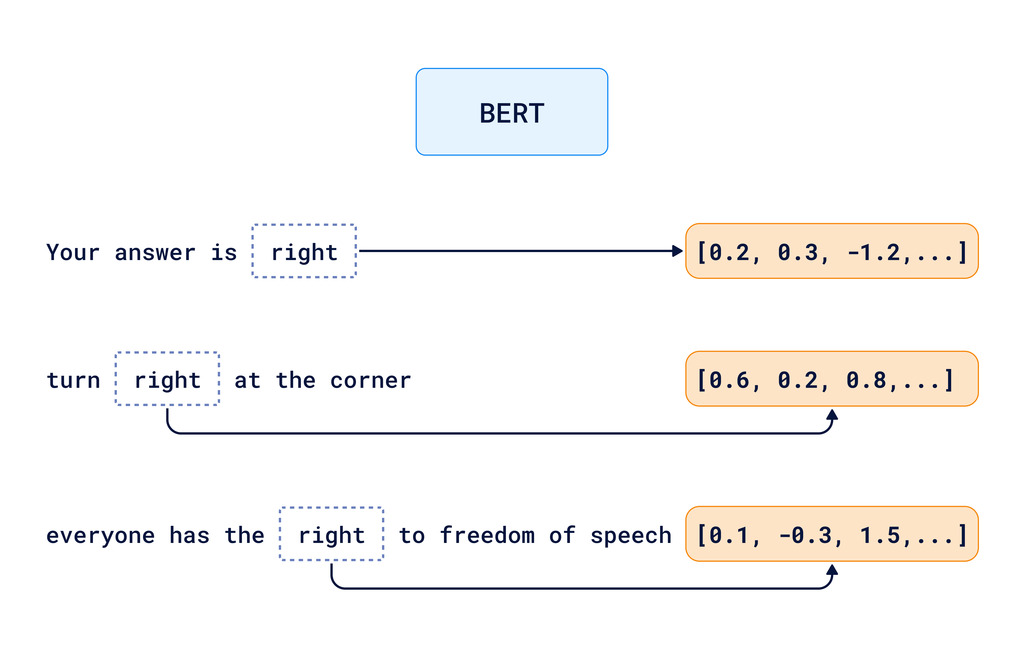
那么,我们如何帮助计算机理解语言在不同上下文中的细微差别呢?换句话说,我们如何区分以下情况:
- “你的答案是正确的”
- “在角落向右转”
- “每个人都有言论自由的权利”
这些句子都使用了“right”这个词,但含义不同。
更先进的模型,如BERT和GPT,使用基于Transformer 架构的深度学习模型,这有助于计算机考虑词语的完整上下文。这些模型关注整个上下文。模型理解词语在其**周围**的特定用法,然后为每种用法创建不同的嵌入。
但是,这种理解和解释过程在实践中是如何工作的呢?例如,想想这个术语:“亲生物设计”(biophilic design)。为了生成它的嵌入,Transformer 架构可以使用以下上下文:
- “亲生物设计将自然元素融入建筑规划。”
- “具有亲生物设计元素的办公室报告员工福祉更高。”
- “…植物生命、自然光和水景是亲生物设计的关键方面。”
然后它将这些上下文与已知的建筑和设计原则进行比较
- “可持续设计优先考虑环境和谐。”
- “人机工程学空间提升用户舒适度和健康。”
模型为“亲生物设计”创建了一个向量嵌入,该嵌入概括了将自然元素整合到人造环境中的概念。并增强了属性,突出了这种整合与它对健康、福祉和环境可持续性的积极影响之间的关联。
与嵌入 API 集成
为你的用例选择合适的嵌入模型对于你的应用性能至关重要。Qdrant 通过提供与精选的最佳嵌入 API 的无缝集成,使其变得更容易,包括Cohere、Gemini、Jina Embeddings、OpenAI、Aleph Alpha、Fastembed 和AWS Bedrock。
如果你正在寻找 NLP 和快速原型开发,包括语言翻译、问答和文本生成,OpenAI 是一个很好的选择。Gemini 非常适合图像搜索、重复检测和聚类任务。
Fastembed,我们将在下面的示例中使用它,旨在提高效率和速度,非常适合需要低延迟响应的应用,例如自动完成和即时内容推荐。
在未来的文章中,我们计划更深入地探讨如何根据性能、成本、集成便捷性和可扩展性来选择最佳模型。
使用 Fastembed 创建神经网络搜索服务
现在你已经熟悉了向量嵌入的核心概念,何不开始构建你自己的神经网络搜索服务呢?
本教程将指导你如何基于startups-list.com上的公司描述,实际应用 Qdrant 进行文档管理。从嵌入数据、将其与 Qdrant 的向量数据库集成、构建搜索 API,到最后使用 FastAPI 部署你的解决方案。
在在线演示中查看这个项目的最终版本是什么样子。
告诉我们你正在用嵌入构建什么!加入我们的Discord社区并分享你的项目!