点、向量和负载
理解 Qdrant 的核心数据模型对于构建有效的向量搜索应用程序至关重要。本课程将建立您在整个课程中使用的精确技术词汇和概念。
点:核心实体
点是 Qdrant 操作的中心实体。一个点是一个由三个组件组成的记录
- 唯一 ID(64 位无符号整数或 UUID)
- 向量(稠密、稀疏或多向量)
- 可选有效载荷(元数据)
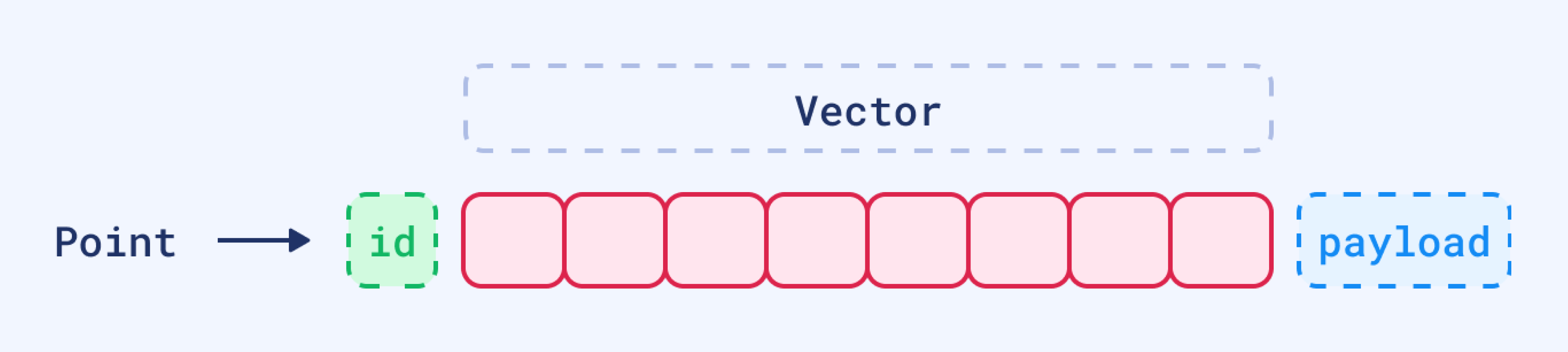
如果未提供 ID,Qdrant 客户端将自动将其生成为随机 UUID。
Qdrant 中的向量类型
Qdrant 支持不同类型的向量,以提供各种数据探索和搜索方法。
稠密向量
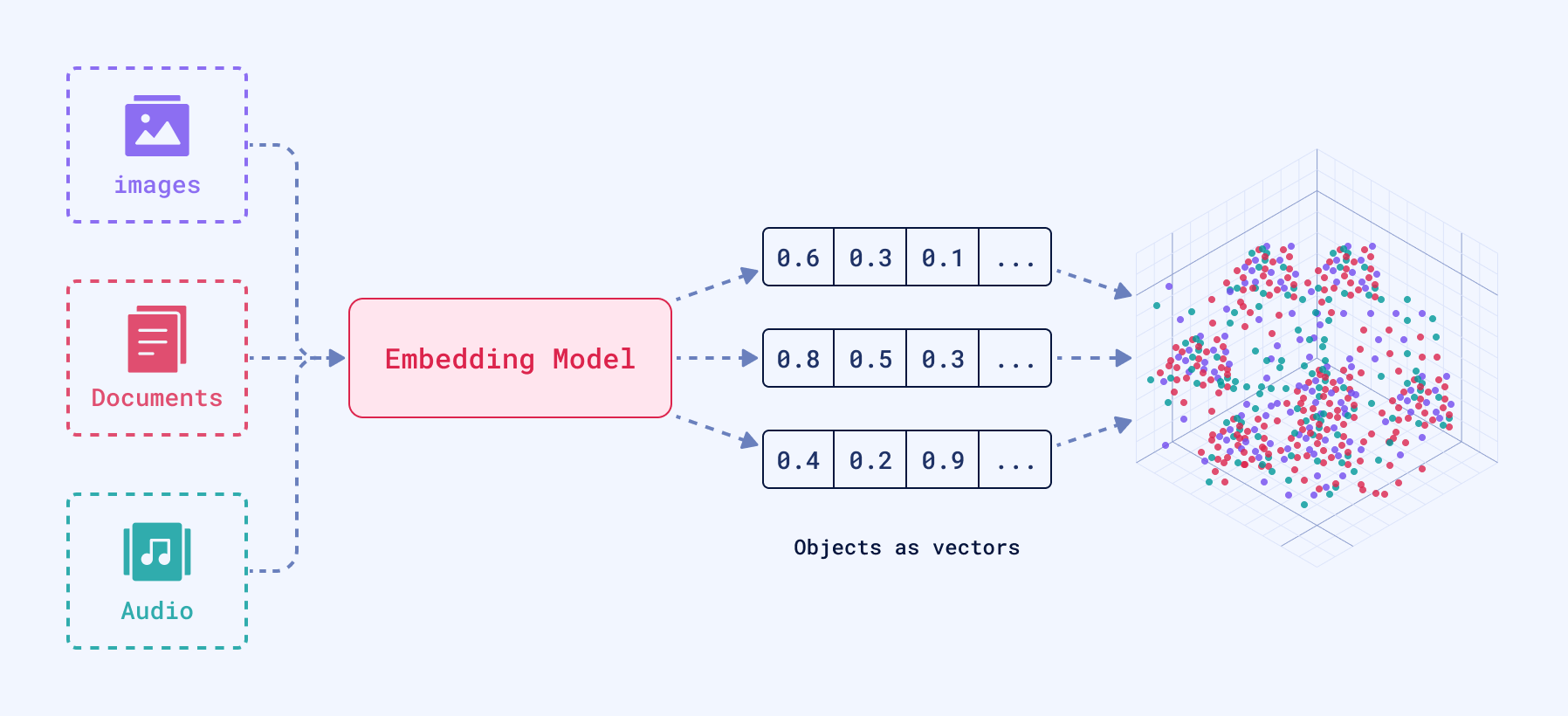
每个向量的核心是一组数字,它们共同构成了多维空间中数据的表示。
稠密向量是向量搜索中使用的典型向量表示,由大多数嵌入模型生成,并捕获数据中固有的模式或关系。这就是为什么在指代这些模型的输出时,“嵌入”一词经常与“向量”互换使用。
嵌入由神经网络生成,用于捕获数据中复杂的关联和语义。这些嵌入表示为高维空间中的向量,然后可以高效地存储在向量搜索引擎中并进行搜索。
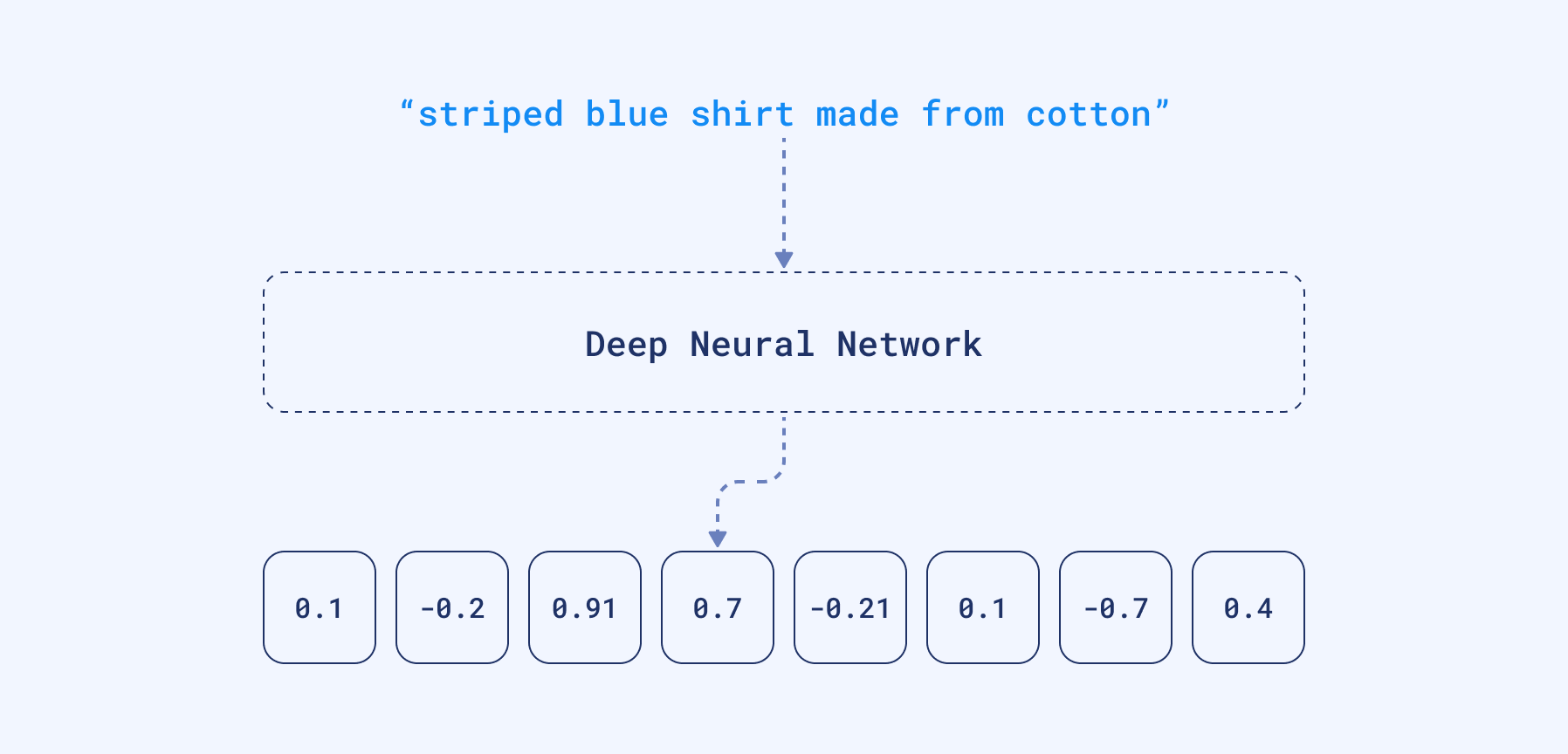
例如,要表示文本数据,嵌入将封装语言的细微差别,例如其维度内的语义和上下文。
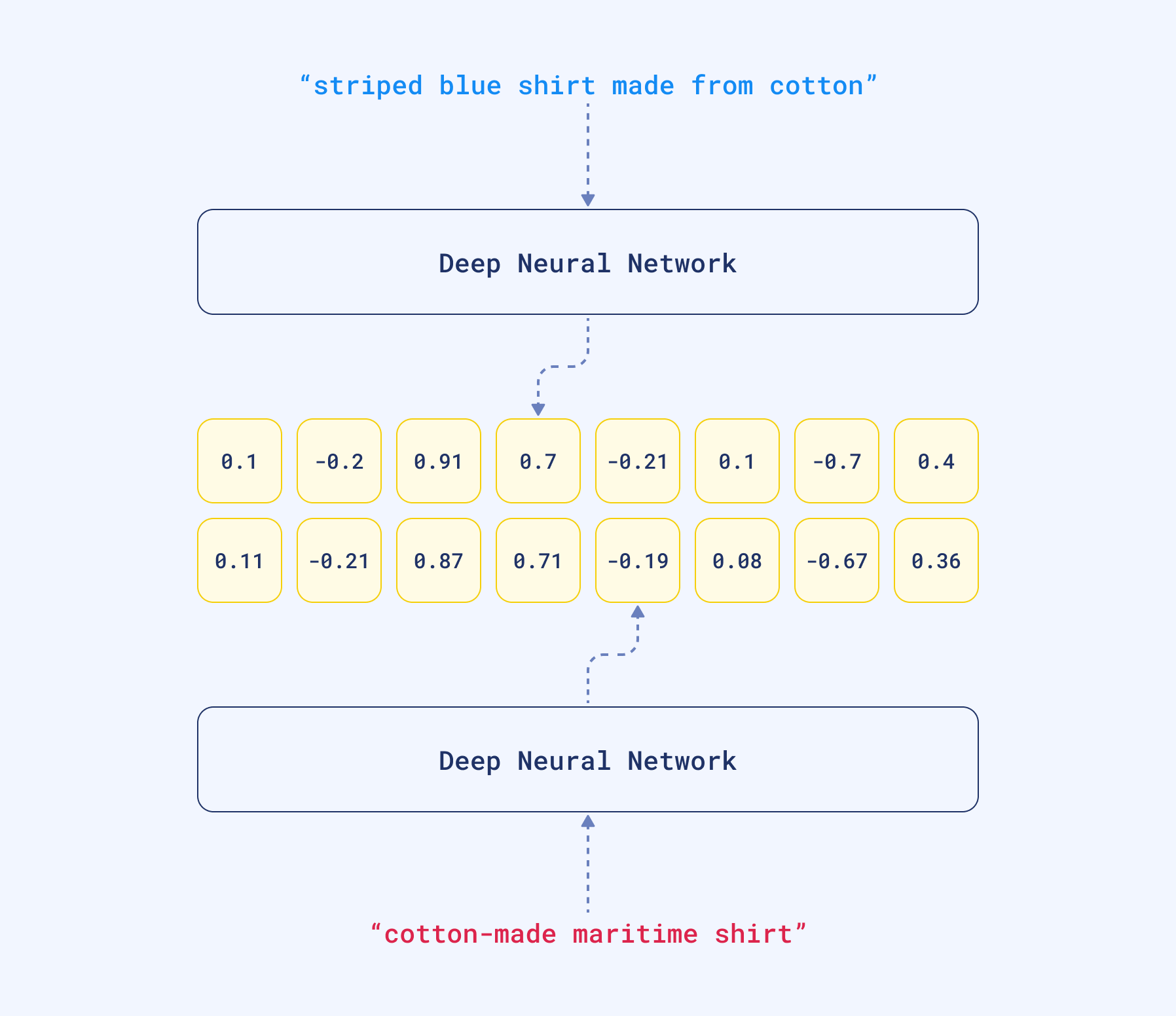
因此,当比较两个相似的句子时,它们的嵌入将非常相似,因为它们具有相似的语言元素。
稀疏向量
在数学上与稠密向量相同,但包含许多零。它们使用优化的存储表示,并且形状与稠密向量不同。
表示: 稀疏向量表示为(索引,值)对的列表
- 索引:非零值的整数位置
- 值:浮点数
示例
# Dense vector: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 2.0, 0.0, 0.0]
# Sparse representation: [(6, 1.0), (7, 2.0)]
# Qdrant JSON format:
{
"indices": [6, 7],
"values": [1.0, 2.0]
}
indices 和 values 数组必须大小相同,并且所有 indices 必须是唯一的。
无需按索引对稀疏表示进行排序,因为 Qdrant 将在内部执行此操作,同时保持每个索引与其值之间的正确链接。
我们将在第 3 天介绍更多关于稀疏向量的内容。如果您想提前阅读相关主题,可以在此处找到更多文档。
多向量
虽然大多数模型为每个输入生成一个向量,但像晚期交互模型(例如 ColBERT)这样的高级技术会生成一组向量,通常每个 token 一个。Qdrant 的多向量允许您将整个矩阵存储在一个点上。
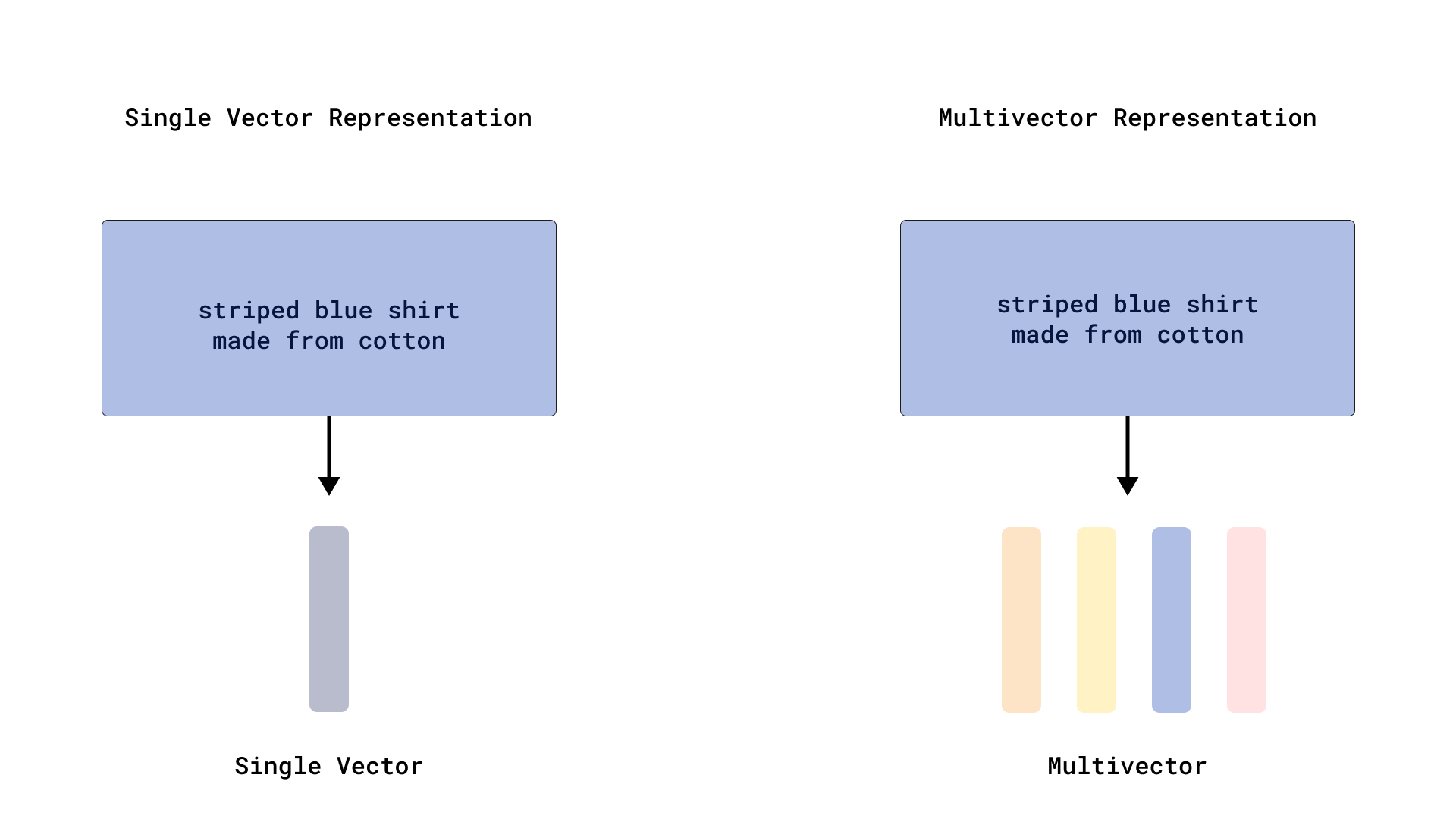
结构
- 每组可变数量的向量(多向量行)
- 每个单独向量的固定大小(多向量列)
示例
大小为 4 的多向量
"vector": [
[-0.013, 0.020, -0.007, -0.111],
[-0.030, -0.055, 0.001, 0.072],
[-0.041, 0.014, -0.032, -0.062],
# ...
]
用例
- 同一对象从不同角度的多个嵌入,相同的有效载荷
- 为每个文本token或图像patch输出向量的晚期交互模型(例如 ColBERT)。
- 每个数据点需要多个相关向量的任何场景
命名向量
我们了解到 Qdrant 中有三种类型的向量结构:稠密、稀疏和多向量。
也可以将任何类型和结构的多个嵌入附加到单个点。Qdrant 使用命名向量来处理不同的向量空间。可以在集合创建期间定义单独的命名向量空间并独立管理。
要使用命名向量创建集合,您需要为每个向量空间指定配置
集合创建
from qdrant_client import QdrantClient, models
import os
client = QdrantClient(url=os.getenv("QDRANT_URL"), api_key=os.getenv("QDRANT_API_KEY"))
# For Colab:
# from google.colab import userdata
# client = QdrantClient(url=userdata.get("QDRANT_URL"), api_key=userdata.get("QDRANT_API_KEY"))
client.create_collection(
collection_name="{collection_name}",
vectors_config={
"image": models.VectorParams(size=4, distance=models.Distance.DOT),
"text": models.VectorParams(size=5, distance=models.Distance.COSINE),
},
sparse_vectors_config={"text-sparse": models.SparseVectorParams()},
)
点插入
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
vector={
"image": [0.9, 0.1, 0.1, 0.2],
"text": [0.4, 0.7, 0.1, 0.8, 0.1],
"text-sparse": {
"indices": [1, 3, 5, 7],
"values": [0.1, 0.2, 0.3, 0.4],
},
},
),
],
)
PUT /collections/{collection_name}/points?wait=true
{
"points": [
{
"id": 1,
"vector": {
"image": [0.9, 0.1, 0.1, 0.2],
"text": [0.4, 0.7, 0.1, 0.8, 0.1],
"text-sparse": {
"indices": [1, 3, 5, 7],
"values": [0.1, 0.2, 0.3, 0.4]
}
}
}
]
}
client.upsert("{collection_name}", {
points: [
{
id: 1,
vector: {
image: [0.9, 0.1, 0.1, 0.2],
text: [0.4, 0.7, 0.1, 0.8, 0.1],
text_sparse: {
indices: [1, 3, 5, 7],
values: [0.1, 0.2, 0.3, 0.4]
}
},
},
],
});
use qdrant_client::qdrant::{
NamedVectors, PointStruct, UpsertPointsBuilder, Vector,
};
use qdrant_client::Payload;
client
.upsert_points(
UpsertPointsBuilder::new(
"{collection_name}",
vec![PointStruct::new(
1,
NamedVectors::default()
.add_vector("text", Vector::new_dense(vec![0.4, 0.7, 0.1, 0.8, 0.1]))
.add_vector("image", Vector::new_dense(vec![0.9, 0.1, 0.1, 0.2]))
.add_vector(
"text-sparse",
Vector::new_sparse(vec![1, 3, 5, 7], vec![0.1, 0.2, 0.3, 0.4]),
),
Payload::default(),
)],
)
.wait(true),
)
.await?;
import java.util.List;
import java.util.Map;
import static io.qdrant.client.PointIdFactory.id;
import static io.qdrant.client.VectorFactory.vector;
import static io.qdrant.client.VectorsFactory.namedVectors;
import io.qdrant.client.grpc.Points.PointStruct;
client
.upsertAsync(
"{collection_name}",
List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(
namedVectors(
Map.of(
"image",
vector(List.of(0.9f, 0.1f, 0.1f, 0.2f)),
"text",
vector(List.of(0.4f, 0.7f, 0.1f, 0.8f, 0.1f)),
"text-sparse",
vector(List.of(0.1f, 0.2f, 0.3f, 0.4f), List.of(1, 3, 5, 7)))))
.build()))
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
await client.UpsertAsync(
collectionName: "{collection_name}",
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new Dictionary<string, Vector>
{
["image"] = new() {
Data = {0.9f, 0.1f, 0.1f, 0.2f}
},
["text"] = new() {
Data = {0.4f, 0.7f, 0.1f, 0.8f, 0.1f}
},
["text-sparse"] = ([0.1f, 0.2f, 0.3f, 0.4f], [1, 3, 5, 7]),
}
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client.Upsert(context.Background(), &qdrant.UpsertPoints{
CollectionName: "{collection_name}",
Points: []*qdrant.PointStruct{
{
Id: qdrant.NewIDNum(1),
Vectors: qdrant.NewVectorsMap(map[string]*qdrant.Vector{
"image": qdrant.NewVector(0.9, 0.1, 0.1, 0.2),
"text": qdrant.NewVector(0.4, 0.7, 0.1, 0.8, 0.1),
"text-sparse": qdrant.NewVectorSparse(
[]uint32{1, 3, 5, 7},
[]float32{0.1, 0.2, 0.3, 0.4}),
}),
},
},
})
向量维度
稠密向量是语义搜索和机器学习应用中最常见的类型。向量维度直接影响搜索效率、内存消耗和检索准确性。
更高的维度捕获更多细节,但存储和计算成本更高。选择平衡了准确性和性能:较小的维度(384-512)最快但细节较少;中等范围(768-1536)提供平衡的准确性和速度;更高的维度(3072+)提供最大细节但需要更多存储空间。
常见模型维度
以下是一些常见的开源和商业模型及其维度
| 模型 | 维度 | 用例 |
|---|---|---|
all-MiniLM-L6-v2 | 384 | 快速、轻量级语义搜索。非常适合原型设计。 |
BAAI/bge-base-en-v1.5 | 768 | 高质量、通用嵌入。RAG 的强大基线。 |
OpenAI text-embedding-3-small | 1536 | 高质量商业模型。非常适合生产语义搜索。 |
OpenAI text-embedding-3-large | 3072 | 最大细节商业模型。适用于大规模、高精度 RAG。 |
内存影响:一个 1536 维的 Float32 向量需要 6KB。将其扩展到 1M 个向量,您需要 6GB 内存。3072 维向量使需求加倍。
常见嵌入源
选择正确的嵌入源是一个关键决策,需要平衡成本、性能和准确性。以下是三种主要方法。
1. 本地优化:Qdrant 的 FastEmbed
FastEmbed 是 Qdrant 优化的嵌入解决方案,专为本地、高速生成而设计,具有最小依赖项。它使用量化模型权重和 ONNX Runtime 提供低延迟、CPU 友好的嵌入生成,使其比传统的基于 PyTorch 的模型快 50%,同时保持有竞争力的准确性。
独立使用的默认模型 BAAI/bge-small-en-v1.5 重量轻,约 67MB,而许多 Hugging Face 模型则超过 300MB。虽然 qdrant-client 集成允许您指定任何兼容模型,但使用默认模型是快速入门的好方法。
from qdrant_client import QdrantClient
from fastembed import TextEmbedding
# This example uses FastEmbed's default model for embedding generation
embedding_model = TextEmbedding()
vector = embedding_model.embed("Qdrant is a vector search engine")
当您需要以下情况时,选择 FastEmbed
- 用于隐私敏感应用程序的本地执行。
- 没有 PyTorch 等繁重依赖项的高速 CPU 推理。
- 与 Qdrant 紧密集成、可扩展、低成本的嵌入生成解决方案。
2. 托管和集成:云提供商
云提供商通过第三方 API 或直接集成到 Qdrant 中提供托管嵌入生成。
- Qdrant 云推理: 我们自己的托管服务,直接在您的 Qdrant 云集群中生成嵌入。这消除了与外部 API 调用相关的网络延迟并简化了您的基础设施,因为您将原始文本或图像发送到 Qdrant,并通过单个请求获得搜索结果。
- 第三方 API: 来自 OpenAI 和 Anthropic 等提供商的商业 API 提供最先进的模型。权衡是网络延迟和基于使用量的成本。
当您满足以下条件时,选择基于云的方法
- 优先考虑易用性,并希望卸载模型管理和基础设施扩展。
- 需要访问最新的商业模型,设置最少。
- 可以接受 API 成本和延迟以获得高质量嵌入。
3. 本地可定制:开源模型
像 Sentence Transformers 这样的库让您可以访问 Hugging Face Hub 上的数千个开源模型。这种方法提供了最大的灵活性和控制力。
流行模型包括
all-MiniLM-L6-v2(384 维,快速)BAAI/bge-base-en-v1.5(768 维,平衡)intfloat/e5-large-v2(1024 维,高性能)
这些模型在您自己的硬件(CPU 或 GPU)上本地运行,但需要管理 PyTorch 或 TensorFlow 等依赖项。
当您满足以下条件时,选择开源模型
- 需要根据您的领域特定数据微调模型。
- 需要完全控制模型架构和部署环境。
- 拥有可用的 GPU 资源来加速大型模型的推理。
嵌入比较
| 特征 | FastEmbed | 云提供商(包括 Qdrant 推理) | 开源模型 |
|---|---|---|---|
| 执行 | 本地(CPU/GPU) | 云 API | 本地(CPU/GPU) |
| 速度 | 针对低延迟 CPU 推理进行了优化 | API 延迟(外部)或接近零(Qdrant) | 因模型和硬件而异 |
| 控制 | 高 | 低 | 最大(微调、架构) |
| 最适合 | Qdrant 原生、轻量级、快速 CPU | 易用性、托管扩展 | 领域特定定制、完全控制 |
有效载荷(元数据)
虽然向量捕获数据的本质,但有效载荷包含用于过滤和细化的结构化元数据。这种组合使得可以将向量的语义相关性与有效载荷的业务逻辑相结合。
有效载荷可以存储文本数据(描述、标签、类别)、数值(日期、价格、评分)和复杂结构(嵌套对象、数组)。例如,在搜索狗图像时,向量会查找视觉上相似的图像,而有效载荷过滤器则将结果缩小到在过去一年内拍摄、标记为“度假”或满足特定评分标准的图像。
了解更多:有效载荷文档
有效载荷类型
Qdrant 支持多种有效载荷数据类型,每种类型都针对不同的过滤条件进行了优化。使用正确的类型对于性能和内存效率至关重要。
| 类型 | 描述 | 示例 |
|---|---|---|
关键字 | 用于精确字符串匹配(例如,标签、类别、ID)。 | category: "electronics" |
整数 | 用于数值过滤的 64 位带符号整数。 | stock_count: 120 |
浮点数 | 用于价格、评分等的 64 位浮点数。 | price: 19.99 |
布尔值 | 真/假值。 | in_stock: true |
地理位置 | 经度/纬度对,用于基于位置的查询。 | location: { "lon": 13.4050, "lat": 52.5200 } |
日期时间 | RFC 3339 格式的时间戳,用于基于时间的过滤。 | created_at: "2024-03-10T12:00:00Z" |
UUID | 一种用于存储和匹配 UUID 的内存高效类型。 | user_id: "550e8400-e29b-41d4-a716-446655440000" |
数据结构
上述任何类型都可以存储在更复杂的结构中
数组: 字段可以包含相同类型的多个值。如果数组中至少有一个值满足条件,则过滤器将成功。
- 示例:
tags: ["vegan", "organic", "gluten-free"]
- 示例:
嵌套对象: 有效载荷可以是任意 JSON 对象,允许您存储结构化数据。您可以使用点表示法过滤嵌套字段(例如,
user.address.city)。- 示例:
user: {"id": 123, "name": "Alice"}
- 示例:
过滤逻辑:构建复杂查询
Qdrant 的过滤系统使用逻辑子句,这些子句可以递归嵌套以创建复杂的查询逻辑。可以将它们视为表达复杂业务需求的构建块。
逻辑子句
- 必须:所有条件都必须满足(AND 逻辑)
- 应该:至少一个条件必须满足(OR 逻辑)
- 不应:所有条件都不应满足(NOT 逻辑)
这些子句结合起来表达复杂需求。例如,查找“200 美元以下的电子产品或 4 星以上评分的书籍”变为
models.Filter(
should=[
models.Filter(must=[
models.FieldCondition(key="category", match=models.MatchValue(value="electronics")),
models.FieldCondition(key="price", range=models.Range(lt=200))
]),
models.Filter(must=[
models.FieldCondition(key="category", match=models.MatchValue(value="books")),
models.FieldCondition(key="rating", range=models.Range(gte=4.0))
])
]
)
条件类型:精确控制
除了基本的逻辑子句之外,Qdrant 还提供了丰富的条件类型,用于过滤不同类型的数据。这些条件允许您构建精确的查询,以匹配您的应用程序需求。
以下是一些最常见的条件类型
| 条件类型 | 用例 | 示例 |
|---|---|---|
匹配 (Match) | 用于关键字、数字或布尔值的精确值匹配。 | category: "electronics" |
范围 | 用于数值或日期时间边界过滤。 | price > 100.0 |
地理位置 | 用于使用半径或边界框进行基于位置的过滤。 | location within 5km of Berlin |
全文 | 用于在文本字段中搜索特定单词或短语。 | description contains "machine learning" |
嵌套 | 用于查询对象数组内部。 | reviews where rating > 4 and verified = true |
过滤功能参考
| 筛选器类型 | 描述 | 查询示例 |
|---|---|---|
| 匹配 (Match) | 精确值 | "match": {"value": "electronics"} |
| 匹配任意 (Match Any) | OR 条件 | "match": {"any": ["red", "blue"]} |
| 匹配排除 (Match Except) | NOT IN 条件 | "match": {"except": ["banned"]} |
| 范围 | 数值范围 | "range": {"gte": 50, "lte": 200} |
| 日期时间范围 (Datetime Range) | 基于时间的过滤 | "range": {"gt": "2023-01-01T00:00:00Z"} |
| 全文 | 子字符串匹配 | "match": {"text": "amazing service"} |
| 地理空间 | 基于位置 | "geo_radius": {"center": {...}, "radius": 10000} |
| 嵌套 | 数组对象过滤 | "nested": {"key": "reviews", "filter": {...}} |
| 有 ID | 特定 ID | "has_id": [1, 5, 10] |
| 是否为空 (Is Empty) | 缺少字段 | "is_empty": {"key": "discount"} |
| 是否为 Null (Is Null) | 空值 | "is_null": {"key": "field"} |
| 值计数 | 数组长度 | "values_count": {"gt": 2} |
高级过滤:嵌套对象
对于像对象数组这样的复杂数据结构,Qdrant 提供嵌套过滤,确保条件在单个数组元素内而不是跨所有元素进行评估。
考虑一个有多个评论的产品
{
"id": 1,
"product": "Laptop",
"reviews": [
{"user": "alice", "rating": 5, "verified": true},
{"user": "bob", "rating": 3, "verified": false}
]
}
查找带有已验证 5 星评论的产品(两个条件都必须适用于同一评论)
models.Filter(
must=[
models.NestedCondition(
nested=models.Nested(
key="reviews",
filter=models.Filter(must=[
models.FieldCondition(key="rating", match=models.MatchValue(value=5)),
models.FieldCondition(key="verified", match=models.MatchValue(value=True))
])
)
)
]
)
如果没有嵌套过滤,Qdrant 将匹配任何评论具有 5 星评级 AND 任何评论已验证的产品 - 可能是不同的评论。
性能优化
为了最大限度地提高过滤性能,为经常过滤的字段创建有效载荷索引。Qdrant 会根据过滤器基数和可用索引自动优化查询执行。
# Index frequently filtered fields
client.create_payload_index(
collection_name="{collection_name}",
field_name="category",
field_schema=models.PayloadSchemaType.KEYWORD,
)
# For multi-tenant applications, mark tenant fields
client.create_payload_index(
collection_name="{collection_name}",
field_name="tenant_id",
field_schema=models.KeywordIndexParams(type="keyword", is_tenant=True),
)
当过滤器具有高度选择性时,Qdrant 的查询规划器可能会完全绕过向量索引,并使用有效载荷索引以获得更快的结果。
有关全面的过滤示例和高级用法模式,请参阅过滤文档和向量搜索过滤完整指南。
关键要点
理解 Qdrant 的数据模型可以帮助您构建复杂的搜索应用程序。点将唯一 ID、向量和元数据结合到一个灵活的基础中。多种向量类型(稠密、稀疏、多向量)支持不同的用例,而命名向量允许每个点有多个向量空间。维度选择平衡了准确性和性能,各种嵌入源提供了速度、准确性和部署要求的不同权衡。最后,有效载荷支持丰富的过滤和结构化元数据以及向量搜索。
这个基础为您接下来将学习的高级主题做好了准备:距离度量、分块策略以及构建真实的搜索系统。