结合向量搜索和过滤
我们已经讨论了 Qdrant 如何使用HNSW图来高效搜索密集向量。但在实际应用中,你通常会希望使用过滤器来限制搜索。这给图遍历带来了独特的挑战,而 Qdrant 优雅地解决了这些挑战。
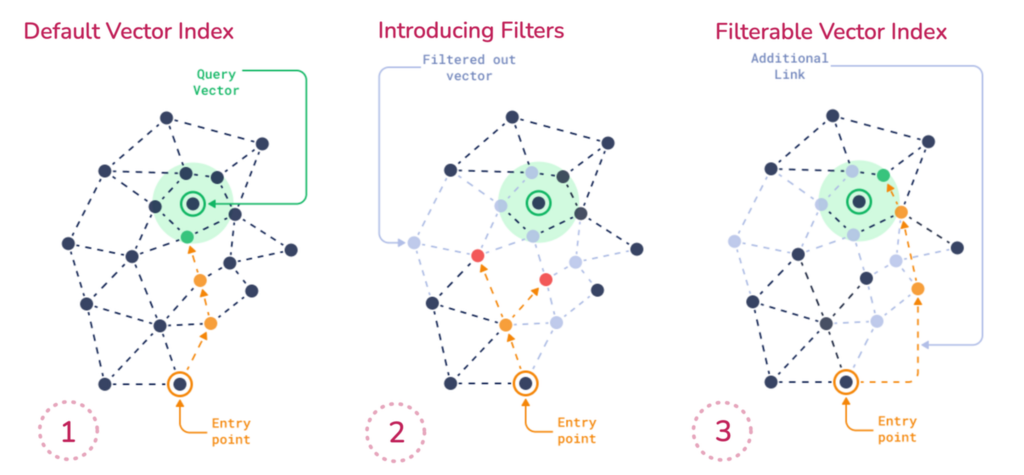
挑战:过滤器破坏了图的连通性
考虑从一个在线商店的商品集合中检索商品,你只想展示价格低于 1000 美元的笔记本电脑。这些价格信息,以及“笔记本电脑”类别,不属于向量的一部分——它们存在于payload中。

当你应用一个像 price < 1000 这样的过滤器时,你实际上是在限制搜索过程中哪些点是合格的。这给图遍历带来了挑战,因为 HNSW 依赖短程和长程边缘来高效探索向量空间。它要求图中的任何点都是可达的。但如果过滤移除了大部分点,搜索路径就会中断。你可能会错过相关的结果——不是因为它们不相似,而是因为在过滤器下它们无法到达。
幼稚的方法及其问题
后过滤
一种方法是最初忽略过滤器:对整个数据集运行搜索,获取最相似的前 K 个向量,然后事后应用过滤器。
问题:你可能会丢弃大部分前 K 个结果。如果满足过滤器的最佳匹配不在前 K 个中,你将无法检索到它。你浪费了计算资源并降低了召回率,因为相关的点从未被检索到。
预过滤
另一种方法是先过滤,然后在过滤后的集合中搜索。
问题:当过滤器过于严格时,它们会碎片化 HNSW 图,破坏连通性并使遍历效率低下或不可能。
Qdrant 的解决方案:可过滤 HNSW
Qdrant 用一种更智能的方法解决了这个问题。我们通过创建额外的边缘来维持过滤条件下的连通性,从而保证 HNSW 图保持连通。Qdrant 为每个 payload 值构建子图,然后将它们合并回完整的图中。
因此,如果你过滤 brand = Apple,Qdrant 已经构建了一个仅包含 Apple 品牌的点的连通子图,遍历在该子集中运行良好。
查询规划器:自适应策略
在查询时,Qdrant 使用查询规划器来确定适当的策略。此规划在每个段中进行,并基于过滤器基数、索引可用性和诸如 full_scan_threshold 之类的阈值。
- 过滤器匹配许多点:Qdrant 执行常规 HNSW 搜索,但在遍历过程中跳过不匹配的节点。这避免了预过滤大型结果集的成本,同时保持搜索快速和近似。
- 过滤器匹配少量点:如果过滤器只匹配集合的一小部分,Qdrant 可能会完全跳过 HNSW,如果这样更快,则回退到简单的全扫描。
Payload 索引:基础层
关键点:Qdrant 默认不索引 payload 字段。你必须明确定义要索引的字段。最佳实践是在上传任何数据之前创建 payload 索引,以便 HNSW 可以构建感知过滤器的链接。如果你在 HNSW 构建后添加 payload 索引,搜索效率可能会降低,直到你重建。要重建,请更改 m 以重新创建每个段的 HNSW,但请记住,在大型集合上重建是计算密集型的。
from qdrant_client import QdrantClient, models
import os
client = QdrantClient(url=os.getenv("QDRANT_URL"), api_key=os.getenv("QDRANT_API_KEY"))
# For Colab:
# from google.colab import userdata
# client = QdrantClient(url=userdata.get("QDRANT_URL"), api_key=userdata.get("QDRANT_API_KEY"))
collection_name = "store"
vector_size = 768
if client.collection_exists(collection_name=collection_name):
client.delete_collection(collection_name=collection_name)
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(
size=vector_size,
distance=models.Distance.COSINE,
),
optimizers_config=models.OptimizersConfigDiff(
indexing_threshold=100,
),
)
# Index frequently filtered fields
client.create_payload_index(
collection_name=collection_name,
field_name="category",
field_schema=models.PayloadSchemaType.KEYWORD,
)
client.create_payload_index(
collection_name=collection_name,
field_name="price",
field_schema=models.PayloadSchemaType.FLOAT,
)
client.create_payload_index(
collection_name=collection_name,
field_name="brand",
field_schema=models.PayloadSchemaType.KEYWORD,
)
添加示例数据
# Upload data
import random
points = []
for i in range(1000):
points.append(
models.PointStruct(
id=i,
vector=[random.random() for _ in range(vector_size)],
payload={
"category": random.choice(["laptop", "phone", "tablet"]),
"price": random.randint(0, 1000),
"brand": random.choice(
["Apple", "Dell", "HP", "Lenovo", "Asus", "Acer", "Samsung"]
),
},
)
)
client.upload_points(
collection_name=collection_name,
points=points,
)
内存注意事项
Payload 索引会消耗额外的内存,因此建议仅索引用于过滤条件的字段。
如果内存有限,请优先索引产生最具体搜索结果的字段。payload 字段值越多样化和粒度化,其索引就越有效。
实际实现
设置可过滤搜索
以下示例说明了如何在实践中执行过滤
# Create filter combining multiple conditions
filter_conditions = models.Filter(
must=[
models.FieldCondition(key="category", match=models.MatchValue(value="laptop")),
models.FieldCondition(key="price", range=models.Range(lte=1000)),
models.FieldCondition(key="brand", match=models.MatchAny(any=["Apple", "Dell", "HP"])),
]
)
query_vector = [random.random() for _ in range(vector_size)]
# Execute filtered search
results = client.query_points(
collection_name=collection_name,
query=query_vector,
query_filter=filter_conditions,
limit=10,
search_params=models.SearchParams(hnsw_ef=128),
)
请参阅文档中的更多内容。
查询规划器决策矩阵
| 过滤器基数 | 策略 | 何时使用 |
|---|---|---|
| 高(许多匹配) | 带节点跳过的 HNSW | 过滤器匹配许多点 |
| 非常低(少量匹配) | 候选者的全扫描 | 微小的结果集 |
性能优化技巧
- 尽早索引:在 HNSW 构建之前创建 payload 索引。
- 索引正确的字段:为所有过滤字段创建 payload 索引。如果内存有限,请优先选择高选择性字段。
- 测试过滤器组合:复杂的多字段过滤器从适当的索引中获益最大。
- 调整阈值:根据你的数据分布和查询模式调整
full_scan_threshold - 测量实际性能:使用你的实际数据和查询模式进行基准测试,以验证规划器决策
关键要点
可过滤 HNSW 不是一个独立的索引机制,它通过根据存储的 payload 值添加额外的边缘来扩展 HNSW 图,以在过滤约束下保持遍历性能。
查询规划器根据过滤器选择性、可用索引和段特性自动选择最佳策略。
Payload 索引对于过滤搜索性能至关重要,特别是对于大型数据集和复杂的过滤条件。
始终使用你的特定数据进行基准测试,以了解规划器的行为并相应地进行优化。
在下一节中,我们将定义一个具有结构化 payload 的集合,配置 payload 索引,并评估不同的 HNSW 参数如何影响过滤搜索性能。
了解更多:可过滤 HNSW 文章