HNSW索引基础
至此,你已经了解了向量搜索如何使用余弦相似度、点积或欧几里得距离来检索与查询最接近的向量。这在大规模情况下是如何实现的呢?
为什么向量搜索需要索引
向量搜索的挑战
你可能会想,Qdrant 是否为每个查询都计算了集合中每个向量的距离。这种方法被称为暴力搜索,技术上可行,但在处理数百万或数十亿个向量时,每次查询都会太慢。
幸运的是,Qdrant 使用 HNSW — Hierarchical Navigable Small World(分层可导航小世界) 加速了搜索。
图书馆类比
要理解 HNSW,想象一下你走进一个拥有数百万本书的图书馆,根据内容的简要描述寻找一本书。如果所有的书都随机堆放,你将不得不一本一本地检查每本书,以找到最符合你描述的那一本——这就是暴力搜索。虽然最终会成功,但会花费很长时间。
但图书馆的组织方式并非如此。它们的结构自然地引导你到正确的区域。你走进图书馆,在顶层选择你的书是属于小说区还是非小说区。然后,你通过类型(历史、科学或传记)缩小范围。之后,你移到更具体的子类别或按字母顺序排列,直到找到你的书所在的精确书架。
HNSW 的工作原理
图结构
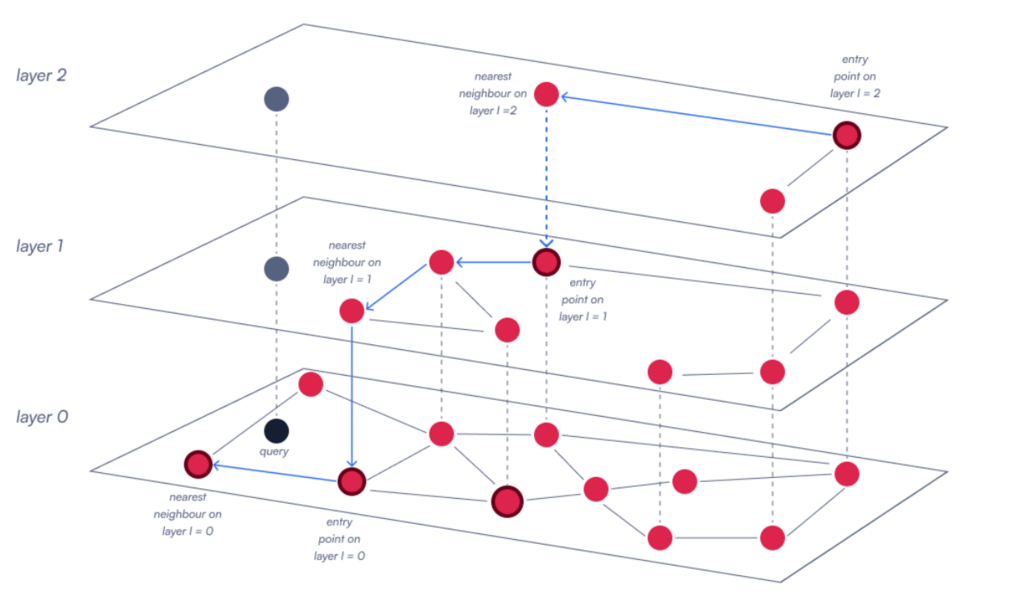
HNSW 的工作原理类似,它构建了一个多层图,其中每个向量都是一个节点。其思想是该图具有分层结构,顶层包含数量较少、连接广泛的节点,而每个下层都包含更多节点,连接也越来越具体。
搜索过程
当执行查询时,HNSW 从顶层的入口点开始,向下遍历图,逐步从更广泛的连接移动到更精确的连接。在每一层,算法都会探索当前节点最近的邻居,以确定最佳前进路径。它继续这个过程,随着层级的下降而细化搜索,直到达到最低层,在那里选择最终的最近邻居。
通过这种方式,Qdrant 避免了暴力搜索,并能在大规模数据集上快速缩小搜索空间。
配置 HNSW
我们可以根据用例需求微调 HNSW 图的构建方式,以平衡搜索速度、准确性、内存使用和索引时间。Qdrant 允许你通过三个关键参数控制 HNSW 索引的行为:m、hnsw_ef 和 ef_construct。
图连接性:m
m 参数控制图中每个节点的最大连接数。
- 较高的
m值:会生成一个更密集的图,其中每个向量连接到更多的邻居,从而提高搜索准确性,因为图具有更多的遍历路径,不太可能遗漏相关向量。然而,这也增加了内存使用和索引时间,因为必须维护更多的连接。 - 较低的
m值:使图更稀疏,减少内存并加快插入速度。但是,搜索可能会变得不那么准确,因为可用于遍历的路径较少。 - 典型值:介于 8 到 64 之间
from qdrant_client.models import HnswConfig
# Example m values
fast_config = HnswConfig(m=8, ef_construct=100, full_scan_threshold=10000) # Lower recall, less memory, faster build
balanced_config = HnswConfig(m=16, ef_construct=100, full_scan_threshold=10000) # Default - good balance
accurate_config = HnswConfig(m=32, ef_construct=100, full_scan_threshold=10000) # Better recall, more memory, slower build
构建彻底性:ef_construct
ef_construct 参数控制在插入新向量时检查的候选数量。
- 较高的
ef_construct值:意味着评估更多的邻居,从而生成一个更全面、更准确的图。然而,这也使索引过程更慢、计算量更大。 - 较低的
ef_construct值:加快了插入过程,但图最终可能会产生不太优化的连接,这会影响搜索准确性。 - 常见范围:介于 100 到 500 之间。复杂数据可能需要更高的值来保持可靠的连接。
# Example ef_construct values
fast_build = HnswConfig(m=16, ef_construct=100, full_scan_threshold=10000) # Default - Faster indexing, lower quality
balanced_build = HnswConfig(m=16, ef_construct=200, full_scan_threshold=10000) # Good balance
quality_build = HnswConfig(m=16, ef_construct=400, full_scan_threshold=10000) # Slower indexing, higher quality
搜索彻底性:hnsw_ef
hnsw_ef 参数确定在搜索查询期间评估的候选数量。
- 较高的
hnsw_ef值:由于算法探索了更大的邻域,因此可以获得更准确的搜索结果。但是,它们也增加了查询时间,因为处理了更多的节点。 - 较低的
hnsw_ef值:加快了搜索速度,但由于考虑的候选向量较少,因此可能会降低准确性。 - 典型范围:50-200+,具体取决于延迟目标。
from qdrant_client.models import SearchParams
# hnsw_ef is set at search time, not build time
fast_search = SearchParams(hnsw_ef=32) # Very fast, lower recall
balanced_search = SearchParams(hnsw_ef=128) # Default - good balance
accurate_search = SearchParams(hnsw_ef=256) # Higher recall, slower
参数摘要
| 参数 | 目的 | 效果 |
|---|---|---|
| m | 每个节点的链接数 | 提高召回率;使用更多 RAM 和构建时间 |
| ef_construct | 插入时检查的候选数量 | 提高图质量;减慢索引速度 |
| hnsw_ef | 搜索时检查的候选数量 | 提高召回率;减慢查询速度 |
选择设置
针对不同工作负载进行优化
- 高速检索:降低
m和hnsw_ef;将ef_construct设置为刚好足以获得可接受的召回率。 - 最大召回率:提高
m、hnsw_ef和ef_construct,并接受较慢的查询和构建。 - 内存紧张:降低
m;保持ef_construct足够高以避免不良链接。
内存与索引行为
某些向量可能会保持未索引状态,具体取决于优化器设置,例如当未索引部分低于 indexing_threshold (kB) 时。
小型集合或低维向量可能根本不会触发 HNSW 索引。在这种情况下,在索引变得有益之前,会使用全扫描搜索(暴力搜索)代替。
HNSW 实践
为什么它快速且可扩展
亚线性搜索扩展:与 O(N) 暴力搜索不同,HNSW 搜索的增长大致与向量数量成对数关系。这使得百万级数据集的搜索时间从数分钟缩短到数毫秒。
过滤感知:Qdrant 通过过滤感知索引 (Filterable HNSW) 扩展了 HNSW,允许在结构化条件下进行快速搜索。这避免了按元数据过滤时耗时的全扫描。
大规模使用:
- 支持实时更新,同时保持高召回率
- 适用于语义搜索和推荐系统
- 从数千个向量扩展到数十亿个向量
实际配置示例
from qdrant_client import QdrantClient, models
import os
client = QdrantClient(url=os.getenv("QDRANT_URL"), api_key=os.getenv("QDRANT_API_KEY"))
# For Colab:
# from google.colab import userdata
# client = QdrantClient(url=userdata.get("QDRANT_URL"), api_key=userdata.get("QDRANT_API_KEY"))
# Production configuration
client.create_collection(
collection_name="production_vectors",
vectors_config=models.VectorParams(
size=768,
distance=models.Distance.COSINE,
hnsw_config=models.HnswConfigDiff(
m=16, # Balanced connections (default)
ef_construct=200, # Good build quality (default)
full_scan_threshold=10000, # Use brute force below this size (default)
),
),
)
# Development / testing: faster builds
client.create_collection(
collection_name="dev_vectors",
vectors_config=models.VectorParams(
size=384,
distance=models.Distance.COSINE,
hnsw_config=models.HnswConfigDiff(
m=8, # Fewer connections
ef_construct=100, # Faster builds
full_scan_threshold=10000, # Use brute force below this size (default)
),
),
)
性能基准测试
让我们测试一下性能。首先,我们将一些玩具数据上传到一个新集合中。
import time
from qdrant_client import QdrantClient, models
import os
client = QdrantClient(url=os.getenv("QDRANT_URL"), api_key=os.getenv("QDRANT_API_KEY"))
# For Colab:
# from google.colab import userdata
# client = QdrantClient(url=userdata.get("QDRANT_URL"), api_key=userdata.get("QDRANT_API_KEY"))
collection_name = "my_collection"
if client.collection_exists(collection_name=collection_name):
client.delete_collection(collection_name=collection_name)
# Development / testing: faster builds
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(
size=4,
distance=models.Distance.COSINE,
hnsw_config=models.HnswConfigDiff(
m=8, # Fewer connections
ef_construct=100, # Faster builds
full_scan_threshold=100, # Use brute force below this size (default)
),
),
optimizers_config=models.OptimizersConfigDiff(
indexing_threshold=100, # Use brute force below this size (default)
),
)
# upload data
import random
points = []
for i in range(20000):
points.append(
models.PointStruct(id=i, vector=[random.random() for _ in range(4)], payload={})
)
client.upload_points(
collection_name=collection_name,
points=points,
)
搜索性能
这个简单的本地基准测试仅作为玩具示例,因为它没有考虑其他因素,例如网络速度。
def benchmark_search_performance(collection_name, test_queries, ef_values):
"""Compare latency across hnsw_ef values"""
results = {}
for hnsw_ef in ef_values:
start_time = time.time()
for query in test_queries:
client.query_points(
collection_name=collection_name,
query=query,
limit=10,
search_params=models.SearchParams(hnsw_ef=hnsw_ef),
)
avg_time = (time.time() - start_time) / len(test_queries)
results[hnsw_ef] = avg_time
print(f"hnsw_ef={hnsw_ef}: {avg_time:.3f}s per query")
return results
# Test different hnsw_ef values
test_queries = [
[30, 60, 90, 120],
[150, 180, 210, 240],
[270, 300, 330, 360],
[390, 420, 450, 480],
[510, 540, 570, 600],
]
ef_values = [32, 64, 128, 256]
performance = benchmark_search_performance(collection_name, test_queries, ef_values)
检查性能和索引使用
使用 get_collection 检查你的集合。它返回集合的当前统计信息和配置,例如 points_count、indexed_vectors_count 或 hnsw_config。它还列出了你创建的有效负载索引的 payload_schema。
要查看你的数据是否实际已索引,你需要检查两件事:已索引向量的数量和集合的状态。如果 indexed_vectors_count 很低,则索引可能尚未完成。更重要的是,你应该检查集合的 status。YELLOW 状态表示优化(索引)仍在进行中,而 GREEN 状态则确认已完成并准备好实现最佳性能。
如果查询感觉很慢,请检查
- 过滤字段是否具有 有效负载索引。
- 是否在构建 HNSW 图之前设置了有效负载索引,并设置了
m>0。 - 是否在构建 HNSW 图之前设置了有效负载索引(HNSW 图的构建在你从
m = 0切换到m > 0时开始)。 hnsw_config.full_scan_threshold是否太高。
# Inspect collection status
info = client.get_collection(collection_name)
vectors_per_point = 1 # set per your vectors_config
vectors_count = info.points_count * vectors_per_point
print(f"Collection status: {info.status}")
print(f"Total points: {info.points_count}")
print(f"Indexed vectors: {info.indexed_vectors_count}")
if vectors_count:
proportion_unindexed = 1 - (info.indexed_vectors_count / vectors_count)
else:
proportion_unindexed = 0
print(f"Proportion unindexed: {proportion_unindexed:.2%}")
if info.status == models.CollectionStatus.GREEN:
print("\n✅ Collection is indexed and ready!")
elif info.status == models.CollectionStatus.YELLOW:
print("\n⚠️ Collection is still being indexed (optimizing).")
else:
print(f"\n❌ Collection status is {info.status}.")
何时不使用 HNSW
小型集合
对于向量少于 10,000 个的集合,暴力搜索通常比构建 HNSW 更快,并且使用的 RAM 更少。
精确搜索要求
HNSW 是近似的。如果你需要精确结果,请使用暴力搜索。
极端内存限制
对于非常紧张的 RAM 预算,请考虑以下解决方案:
- 降低
m:HNSW 使用的额外内存与m × vectors_count成比例。 - 向量量化 (VQ)
- 标量量化 (SQ) 通常可将 RAM 削减约 4 倍。
- 二进制量化 (BQ) 将每个维度压缩到 1 位,可大幅削减 RAM。
- 磁盘存储:将向量和 HNSW 索引的
on_disk=true设置为使用内存映射文件,其中只有最常访问的向量才会被缓存到 RAM 中。 - 禁用 HNSW 进行重排嵌入:这很有用,因为重排向量(例如多向量)很大。
关键要点
- HNSW:将 O(N) 扫描减少到大致 O(log N) 图搜索
m:控制图密度——更多连接提高了准确性,但使用了更多内存ef_construct:影响图质量——更高的值创建更精细的图,但需要更长的构建时间hnsw_ef:控制搜索彻底性——在查询时进行调整,以达到你所需的速度/准确性权衡indexed_vectors_count:跟踪以确认 HNSW 索引
下一步
现在你已经了解 HNSW 如何使向量搜索快速且可扩展。接下来,我们将使用 Qdrant 的过滤感知 HNSW 将快速搜索与复杂过滤器结合起来。
了解更多:Qdrant 文档中的 HNSW
准备好看看 HNSW 如何处理实际过滤场景了吗?让我们继续!