演示:使用稀疏向量进行关键词搜索
使用稀疏向量进行基于关键词的文本检索。
你将学到什么
- 稀疏向量与基于关键词检索的联系
- 在 Qdrant 中使用 BM25
- 稀疏神经检索
- 在 Qdrant 中使用 SPLADE++
文本编码
在稀疏向量中,每个非零维度都代表一个对象,该对象对所表示的项目扮演特定角色。当我们处理文本时,这些对象的自然选择是词语。
语料库是一个有限的文本集,可以从中收集所有独特的词语并形成词汇表。词汇表中的词语可以排序和枚举,这为我们提供了稀疏向量的索引。
词袋模型
考虑一个英文杂货店商品描述数据集。农产品词汇表可以是英语中相对较小的一个子集,按“apple”到“zesty”的顺序排列并相应枚举。
Vocabulary indices (illustrative):
"cheese" -> 101
"grated" -> 151
"hard" -> 190
"mac" -> 20
"and" -> 501
使用词汇表索引,我们可以将每个描述表示为(索引, 值)对的稀疏向量。
该值可以是词频 (TF)。
词频 (TF) 某个词语在文本中出现的次数。
描述:
磨碎的硬奶酪
稀疏向量[(101, 1.0), (151, 1.0), (190, 1.0)]描述:
通心粉和奶酪
稀疏向量[(20, 1.0), (101, 1.0), (501, 1.0)](注意词语
cheese共享索引101)重复词语的较长描述:
四种奶酪披萨献给奶酪爱好者
稀疏向量[(101, 2.0), (130, 1.0), (131, 1.0), (490, 1.0), (705, 1.0)]
这些表示被称为词袋模型:词语像装在袋子里一样放入稀疏向量,不保留顺序,但计算其出现次数。
稀疏文本检索的理念
如果文本被表示为稀疏向量,它们的相似度可以用点积计算。
Similarity("Grated hard cheese", "Mac and cheese") = 1.0 * 1.0 = 1.0
Similarity("Grated hard cheese", "four cheese pizza for cheese lovers")
= 1.0 * 2.0 = 2.0
这已经暗示了基于关键词的检索系统的理念。我们可以将所有文档编码为稀疏向量,并根据与查询的相似度进行检索和排名。
TF-IDF
然而,在检索中,我们关心文档与查询之间的相关性。
与查询关键词匹配的文档可能与查询相关,但并非所有关键词都如此,有些关键词比其他关键词更重要。
IDF
有些关键词在许多文档中都很常见(例如,杂货店商品描述数据集中像tasty或fresh这样的形容词)。其他则稀有且更具特异性(例如,gorgonzola,mozarella)。
在杂货语料库中,关键词mozarella比tasty更重要,因为它更稀有。
这种重要性可以通过逆文档频率来表达。
逆文档频率 (IDF)
一个语料库级别的统计量,表示有多少文档包含某个词项。词项越稀有,其 IDF 越高。
TF-IDF 加权
让我们通过将其词项频率(TF)乘以其语料库级别 IDF 来增强每个文档的词袋表示。
"Grated hard cheese" =
[(101, TF("cheese") * IDF("cheese")),
(151, TF("grated") * IDF("grated")),
(190, TF("hard") * IDF("hard"))]
相似度然后考虑全局词项重要性
Similarity("cheese for pizza", "Grated hard cheese")
= 1.0 * TF("cheese") * IDF("cheese")
TF-IDF是一种简单、统计的基于关键词的文本检索模型。
Qdrant 中的 IDF
计算和维护语料库中每个词项的 IDF 可能会很麻烦。
Qdrant 维护稀疏向量的集合级别IDF,并在评分时为您应用它。
在集合配置中启用IDF 修饰符
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"modifier": "idf"
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
modifier=models.Modifier.IDF,
),
},
)
import { QdrantClient, Schemas } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"text": {
modifier: "idf"
}
}
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, Modifier, SparseVectorParamsBuilder, SparseVectorsConfigBuilder,
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("https://:6334").build()?;
let mut sparse_vectors_config = SparseVectorsConfigBuilder::default();
sparse_vectors_config.add_named_vector_params(
"text",
SparseVectorParamsBuilder::default().modifier(Modifier::Idf),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(sparse_vectors_config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Modifier;
import io.qdrant.client.grpc.Collections.SparseVectorConfig;
import io.qdrant.client.grpc.Collections.SparseVectorParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
SparseVectorConfig.newBuilder()
.putMap("text", SparseVectorParams.newBuilder().setModifier(Modifier.Idf).build()))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("text", new SparseVectorParams {
Modifier = Modifier.Idf,
})
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
SparseVectorsConfig: qdrant.NewSparseVectorsConfig(
map[string]*qdrant.SparseVectorParams{
"text": {
Modifier: qdrant.Modifier_Idf.Enum(),
},
}),
})
在检索过程中,Qdrant 在计算相似度得分时会为每个关键词应用 IDF 组件。
最佳匹配 25 (BM25)
TF-IDF模型已经提供了关键词在文本中作用的良好统计近似。它没有考虑的是文档长度会影响这些文档中使用词语的重要性。
TF-IDF 会仅仅因为文档有更多的词语而奖励更长的文档。
信息检索领域非常著名的公式,最佳匹配 25 (BM25),对 TF-IDF 模型进行了几项调整,以在评分中包含文档长度。
BM25 公式
对于查询 (Q) 和文档 (D)
$$ \mathrm{BM25}(Q, D) =\ \sum_{i=1}^{N} \mathrm{IDF}(q_i)
\frac{\mathrm{TF}(q_i, D)(k_1 + 1)} {\mathrm{TF}(q_i, D) + k_1\left(1 - b + b \cdot \frac{|D|}{\mathrm{avg}_{\text{corpus}}(|D|)}\right)} $$
我们已经介绍了它的大部分组件
TF(q_i, D): 查询词q_i在文档D中的词频。IDF(q_i):q_i的逆文档频率 (Qdrant 可以计算和维护这个值)。
控制文档长度归一化和 TF 饱和度的附加参数
k_1: 控制 TF 饱和度(查询词在文档中额外出现如何强烈地增加得分)。b: 控制文档长度归一化,平衡|D|与语料库平均值avg_corpus(|D|)。
为了设计基于 BM25 的稀疏向量检索,上述文档的 TF-IDF 表示应更新为 BM25 参数。
让我们看看如何在 Qdrant 中实际使用 BM25 检索器。
Qdrant 中的 BM25
在 Colab 中跟随: ![]()
BM25 公式可以表示如下
$$ \text{BM25}(Q, D) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \mathrm{function}\left(\mathrm{TF}(q_i, D), k_1, b, |D|, \mathrm{avg}_{\text{corpus}}|D|\right) $$
Qdrant 提供了在服务器端计算 IDF 的工具。
在 Qdrant 中使用任何包含 IDF 的检索公式(例如 BM25)时,我们不再需要在稀疏文档表示中包含 IDF 组件。IDF 组件将由 Qdrant 在计算相似度得分时自动应用。
为 BM25 稀疏向量创建集合
client.create_collection(
collection_name=<COLLECTION_NAME>,
sparse_vectors_config={
"bm25_sparse_vector": models.SparseVectorParams(
modifier=models.Modifier.IDF #Inverse Document Frequency
),
},
)
一旦启用,IDF 将在集合级别维护。
创建并插入基于 BM25 的稀疏向量
这将给我们留下文档词语的以下值
$$ \text{BM25}(d_i) = \mathrm{function}\left(\mathrm{TF}(d_i, D), k_1, b, |D|, \mathrm{avg}_{\text{corpus}}|D|\right) $$
FastEmbed Qdrant 库提供了一种生成这些基于 BM25 公式稀疏表示的方法。
更新: 自 Qdrant 1.15.2 版本发布以来,BM25 稀疏向量的转换直接在 Qdrant 中进行,适用于所有支持的 Qdrant 客户端。
从接口上看,它与我们在此处展示的 FastEmbed 本地推理看起来相同。
从实现上看,转换为稀疏表示也是相同的。
Qdrant 和 FastEmbed 之间的集成允许您在将文档索引到 Qdrant 时简单地传递文本和 BM25 公式参数。稀疏向量的转换在幕后进行。
当使用 FastEmbed(或自 1.15.2 以来由 Qdrant)生成的基于 BM25 的稀疏表示时,不要忘记启用
IDF修饰符,因为它们有意排除了此组件。
grocery_items_descriptions = [
"Grated hard cheese",
...
]
#Estimating the average length of documents in the corpus
avg_document_length = sum(len(description.split()) for description in grocery_items_descriptions) / len(grocery_items_descriptions)
client.upsert(
collection_name=<COLLECTION_NAME>,
points=[
models.PointStruct(
id=i,
payload={"text": description},
vector={
"bm25_sparse_vector": models.Document(
text=description,
model="Qdrant/bm25",
options={"avg_len": avg_document_length} #To pass BM25 parameters, here we're using default k & b for the BM25 formula
)
},
) for i, description in enumerate(grocery_items_descriptions)
],
)
FastEmbed (Qdrant) 中的 BM25:实现细节
语料库平均长度
Qdrant 和 FastEmbed 不会计算 $\mathrm{avg}_{\text{corpus}}|D|$(语料库中的平均文档长度)。您必须估计并提供此值作为 BM25 参数。
FastEmbed (Qdrant) 中的默认 BM25 参数
k = 1.2b = 0.75
文本处理管道
FastEmbed (Qdrant) 使用Snowball 词干提取器将词语还原为词根或基本形式,并应用特定语言的停用词列表(例如,英语中的and,or)以减少词汇量并提高检索质量。
如果您将 BM25 与 Qdrant(自 1.15.2 版本发布以来)一起使用,您可以自定义停用词列表。
使用 BM25 和 Qdrant 进行词汇检索
现在让我们在 Qdrant 中测试基于 BM25 的词汇搜索。
假设我们正在搜索词语“cheese”——这是我们的查询。
client.query_points(
collection_name=<COLLECTION_NAME>,
using="bm25_sparse_vector",
limit=3,
query=models.Document(
text="cheese",
model="Qdrant/bm25"
),
with_vectors=True,
)
让我们分解一下这个查询以及上一步中索引到 Qdrant 的文档发生了什么。
步骤 1
对于查询中不是目标语言停用词的每个关键词(在我们的例子中是英语,而“cheese”不是停用词)
- FastEmbed (Qdrant) 提取词语的词干(词根/基本形式)。
"cheese"变成"chees"
- 然后将词干映射到词汇表中相应的索引。
"chees"->1496964506
步骤 2
Qdrant 在上一个视频中介绍的倒排索引中查找此关键词索引(1496964506)。
对于每个包含关键词"cheese"的文档(通过倒排索引找到),我们都有 FastEmbed (Qdrant) 预先计算并存储的该特定文档中"cheese"的 BM25 评分
$$ \mathrm{function}\left(\mathrm{TF}(\text{“cheese”}, D), k_1, b, |D|, \mathrm{avg}_{\text{corpus}}|D|\right) $$
步骤 3
Qdrant 将此文档特定分数乘以关键词"cheese"在整个语料库中计算的IDF
$$ \text{IDF}(\text{“cheese”}) \cdot \mathrm{function}\left(\mathrm{TF}(\text{“cheese”}, D), k_1, b, |D|, \mathrm{avg}_{\text{corpus}}|D|\right) $$
步骤 4
查询与文档之间的最终相似度得分是所有匹配关键词得分的总和
$$ \text{BM25}(\text{“cheese”}, D) = \sum_{i=1}^{1} \text{IDF}(\text{“cheese”}) \cdot \mathrm{function}\left(\mathrm{TF}(\text{“cheese”}, D), k_1, b, |D|, \mathrm{avg}_{\text{corpus}}|D|\right) $$
稀疏神经检索
现在让我们探讨一种使基于关键词的检索语义感知的方法:稀疏神经检索。
“语义感知”是什么意思
词袋模型方法在不保留词序的情况下构建稀疏文本表示。它计算词项,但不建模哪些词语出现在哪些词语旁边,即上下文。然而,词语的含义很大程度上由其上下文决定。
示例 #1: 考虑 "I want some hard-to-get cheese" 和 "I want to get some hard cheese"。这两个句子使用相同的词语,但由于词序不同,对词语 cheese 赋予了不同的含义。
依赖于独立于其他词语计算的词语统计的传统检索器无法捕捉这种上下文中的含义,这会影响相关性。
示例 #2: 作为人类,我们知道"A not soft cheese" 在含义上更接近 "hard cheese" 而不是 "soft cheese"。
BM25 缺乏这种语义感知。
密集检索似乎是完美的解决方案,但在许多领域,基于关键词的搜索具有吸引力,因为它可解释、精确且召回率不高。问题变为:我们如何在保留精确匹配的同时使其具有含义感知能力?
一种常见的模式是使用 BM25 进行检索,然后使用理解上下文的模型对匹配的文档进行重新排序。然而,对所有候选文档进行重新排序可能成本很高。更有效的方法是让检索器本身从一开始就具有语义感知能力。
稀疏神经检索的理念
我们不应该仅仅基于语料库统计数据来分配词语权重,而是可以使用那些已经显示出能够捕捉词语在上下文中含义的机器学习模型。
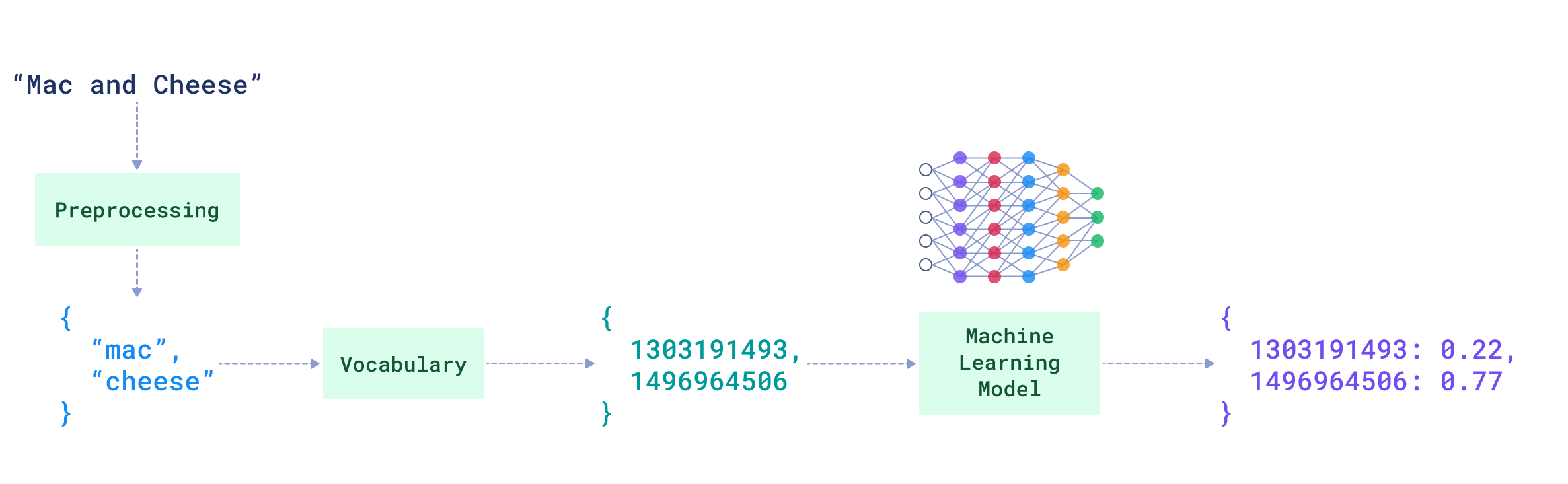
实际上,稀疏神经检索器的作者通常从密集编码器开始,并将其改编以生成稀疏文本表示:形状类似于词袋模型,但其权重由机器学习模型生成。
如果您对细节感兴趣,可以查阅文章“现代稀疏神经检索:从理论到实践”。
在现代稀疏神经检索领域,最著名和常用的模型可能是稀疏词汇和扩展模型,简称 SPLADE。
SPLADE:稀疏词汇和扩展模型
SPLADE(Sparse Lexical and Expansion Model)使用基于 Transformer 的双向编码器表示(BERT)作为基础,因此开箱即用主要适用于英语检索。
SPLADE 不仅尝试编码文本中已有的关键词的含义;它还使用上下文合适的词语来扩展文档和查询。
查询扩展示例
Q: "cheese" → ["cheese", "dairy", "food", "dish", …]
文档扩展示例
D: "Mac and cheese" → ["mac", "cheese", "restaurant", "brand", …]
这解决了当语义相关的文本使用不同词语时的词汇不匹配问题(例如,hard grated cheese vs. parmesan)。
Qdrant 和 FastEmbed 的集成让您轻松使用 SPLADE 家族的最新模型之一,SPLADE++。
Qdrant 中的 SPLADE++
在 Colab 中跟随: ![]()
为使用 SPLADE++ 的稀疏神经检索创建集合
SPLADE 模型不依赖于像 IDF 这样的语料库级别统计数据来估计词语相关性。相反,它们根据词项在编码文本中的交互作用,在稀疏表示中生成词项权重。
请注意,与基于 BM25 的检索不同,我们此处不配置逆文档频率 (IDF) 修改器。
client.create_collection(
collection_name=<COLLECTION_NAME>,
sparse_vectors_config={
"splade_sparse_vector": models.SparseVectorParams(),
},
)
使用 FastEmbed 创建并插入 SPLADE++ 稀疏向量
FastEmbed 库提供了 SPLADE++;它是 SPLADE 家族中的最新模型之一。
更新: 自 Qdrant Cloud Inference 发布以来,您可以将 SPLADE++ 嵌入推理从本地执行(如本笔记本中所示)转移到 Qdrant Cloud,从而减少延迟并集中资源使用。
因此,这一步看起来与在 Qdrant 中使用 BM25 大致相同。
grocery_items_descriptions = [
"Grated hard cheese",
"White crusty bread roll",
"Mac and cheese"
]
client.upsert(
collection_name=<COLLECTION_NAME>,
points=[
models.PointStruct(
id=i,
payload={"text": description},
vector={
"splade_sparse_vector": models.Document( #to run FastEmbed under the hood
text=description,
model="prithivida/Splade_PP_en_v1"
)
},
) for i, description in enumerate(grocery_items_descriptions)
],
)
然而,在底层,将文档转换为稀疏表示的过程却大相径庭。
文档到 SPLADE++ 稀疏表示
SPLADE 模型生成由 SPLADE 分词器产生的标记组成的稀疏文本表示。
分词器将文本分解为更小的单元,称为标记,这些标记构成模型的词汇表。根据分词器的不同,这些标记可以是单词、子词,甚至是字符。
SPLADE 模型在固定的30,522 个标记词汇表上运行。
文本到标记
每个文档首先被分词,然后将生成的标记映射到模型词汇表中相应的索引。
这些索引随后用于最终的稀疏表示。
您可以在分词器演练场中探索此过程,选择自定义分词器并输入Qdrant/Splade_PP_en_v1。例如,“cheese”映射到标记索引8808,而“mac”映射到6097。
加权标记
现在,以标记索引表示的文本通过 SPLADE 模型进行处理。
SPLADE 通过添加上下文相关的标记来扩展输入,并同时为最终稀疏表示中的每个标记分配一个权重,该权重反映其在文本中的作用。
例如,“mac and cheese”将扩展为:“mac and cheese dairy apple dish & variety brand food made , foods difference eat restaurant or”,从而产生一个包含17 个非零值的 SPLADE 生成的稀疏表示。
如果您想尝试 SPLADE 的扩展行为,请查看我们关于在 FastEmbed 中使用 SPLADE的文档。它包含一个实用函数,用于将 SPLADE++ 稀疏表示解码回带有相应权重的标记。
使用 SPLADE++ 和 Qdrant 进行稀疏神经检索
现在让我们看看 SPLADE++ 在解决词汇不匹配问题方面的实际应用。
client.query_points(
collection_name=<COLLECTION_NAME>,
using="splade_sparse_vector",
limit=3,
query=models.Document(
text="parmesan",
model="prithivida/Splade_PP_en_v1"
),
with_vectors=True,
)
SPLADE 将查询“parmesan”扩展为 10 多个额外的标记,使其能够匹配并排名(在索引时也已扩展的)“grated hard cheese”作为最佳匹配,即使“parmesan”没有出现在我们数据集中的任何文档中。
超越 SPLADE
SPLADE 模型是稀疏神经检索的有力选择,但它们也有局限性
标记与单词粒度。 SPLADE 在标记(子词片段)上操作,这对于用户以完整单词思考的关键词导向检索来说不太方便。
"Parmesan" -> "par" "##mes" "##an" "Grated" -> "gr" "##ated"这使得精确的关键词推理和可解释性变得更加困难。
扩展权衡。 查询/文档扩展提高了召回率,但可能使向量更重,结果更难解释。例如,SPLADE++ 可能会将像
Mac and cheese这样的文档与不相关的标记(例如apple)一起扩展,从而使解释复杂化。D: "Mac and cheese" → ["mac", "cheese", "restaurant", "brand", "apple", …]
Qdrant 的稀疏神经检索器
我们一直在探索稀疏神经检索作为一种有前途的方法,适用于关键词匹配有用,但 BM25 等传统方法由于缺乏语义理解而力不从心的领域。
我们开发并开源了两种自定义稀疏神经检索器,它们都建立在 BM25 公式之上。
您可以在以下文章中找到所有详细信息:BM42 稀疏神经检索器和miniCOIL 稀疏神经检索器。
这两种模型都可以与 FastEmbed 和 Qdrant 结合使用,就像我们在本教程中演示 BM25 和 SPLADE++ 的方式一样。
- BM42 的 FastEmbed 句柄:
Qdrant/bm42-all-minilm-l6-v2-attentions - miniCOIL 的 FastEmbed 句柄:
Qdrant/minicoil-v1(此处有详细指南“如何使用 miniCOIL”)
关键要点
- Qdrant 提供用于词汇(基于关键词)检索的稀疏向量。
- Qdrant 在服务器端计算逆文档频率 (IDF)(BM25 的一部分)。在配置稀疏向量集合时启用它。
- 自 1.15.2 版本以来,Qdrant 支持原生转换为 BM25 稀疏表示。
- 稀疏神经检索是基于关键词的检索,它考虑词语在上下文中的含义。
- Qdrant 已开源了自己的稀疏神经检索器(例如,miniCOIL)。
- 在选择稀疏检索器时,无论是词汇型(例如 BM25)还是神经型(例如 SPLADE++、miniCOIL),请在您的数据上进行实验以找到最适合的。
下一步
稀疏检索,即使采用神经加权,当语义相似的内容以非常不同的方式表达时,也存在局限性。密集检索擅长发现并自然地弥合词汇不匹配。
两种方法互补
- 稀疏:精确、轻量、可解释。
- 密集:灵活、擅长探索和发现。
将它们结合起来就产生了混合搜索。请参阅下一节,了解如何配置和使用混合检索。