稀疏向量和倒排索引
为基于关键词的搜索和推荐创建并索引稀疏向量表示。
你将学到什么
- 理解稀疏向量表示
- 在 Qdrant 中使用稀疏向量
稀疏向量表示
稀疏向量是高维向量,除了少数几个维度外,其余都填充为零。稀疏向量的每个维度都指向一个特定的对象,其值表示该对象在此稀疏表示中的作用。
让我们考虑一个电影推荐系统
- 每个稀疏向量可以描述一个特定用户的意见。
- 每个维度可以描述一部特定的电影 M_X,其值表示用户对该电影的评分。
M1 M2 M3 M4 M5 M6 M7 M8 M9 M10
User_1: [ 0, 0, 0, 0, 0, 0, 1, 5, 0, 0 ]
User_2: [ 0, 0, 0, 0, 4, 0, 0, 2, 0, 0 ]
比较稀疏表示
比较两个稀疏表示时,你通常会关注它们在相同特征/对象(例如,相同的电影评分)上的一致程度。
在第 1 天(向量搜索基础/距离度量)介绍的点积距离度量,非常适合衡量稀疏表示之间的相似性。它将相应的维度相乘并求和结果。
similarity(User_1, User_2) = 0*0 + ... + 0*4 + ... + 1*0 + 5*2 + ... 0*0 = 10
你会注意到,只有在两个向量中都起作用(两个向量中非零维度)的对象/特征才会影响最终得分。
表示为索引-值对
存储数千个不提供任何信息的零是浪费的。
相反,稀疏向量可以紧凑地存储为其非零条目的(索引,值)对。
以电影为例
[0, 0, 0, 0, 0, 0, 1.0, 2.0, 0, 0]
0 1 2 3 4 5 6 7 8 9
→ [(6, 1.0), (7, 2.0)]
这种表示方式节省空间,并精确地保留了影响稀疏向量相似性的信息。
组织稀疏向量:倒排索引
搜索相似的稀疏向量归结为找到与查询共享非零维度的向量,并乘以相应的值。
在规模化时,扫描每个向量以检查匹配的非零维度太慢。
简单想法:维护一个从维度索引到具有这些非零维度(带相应权重)的向量的映射。在查询时
- 对于每个查询的非零维度,检查该映射条目以收集匹配的向量。
- 仅使用重叠非零索引上的点积对这些候选向量进行评分。
示例
让我们通过一个简单的例子来理解它
我们有 3 篇文档 - 3 个稀疏向量表示
id_1: [(6, 1.0), (12, 2.0)]
id_2: [(1, 0.2), (7, 1.0)]
id_3: [(6, 0.3), (7, 2.0), (12, -0.5)]
提议的映射可能看起来像这样: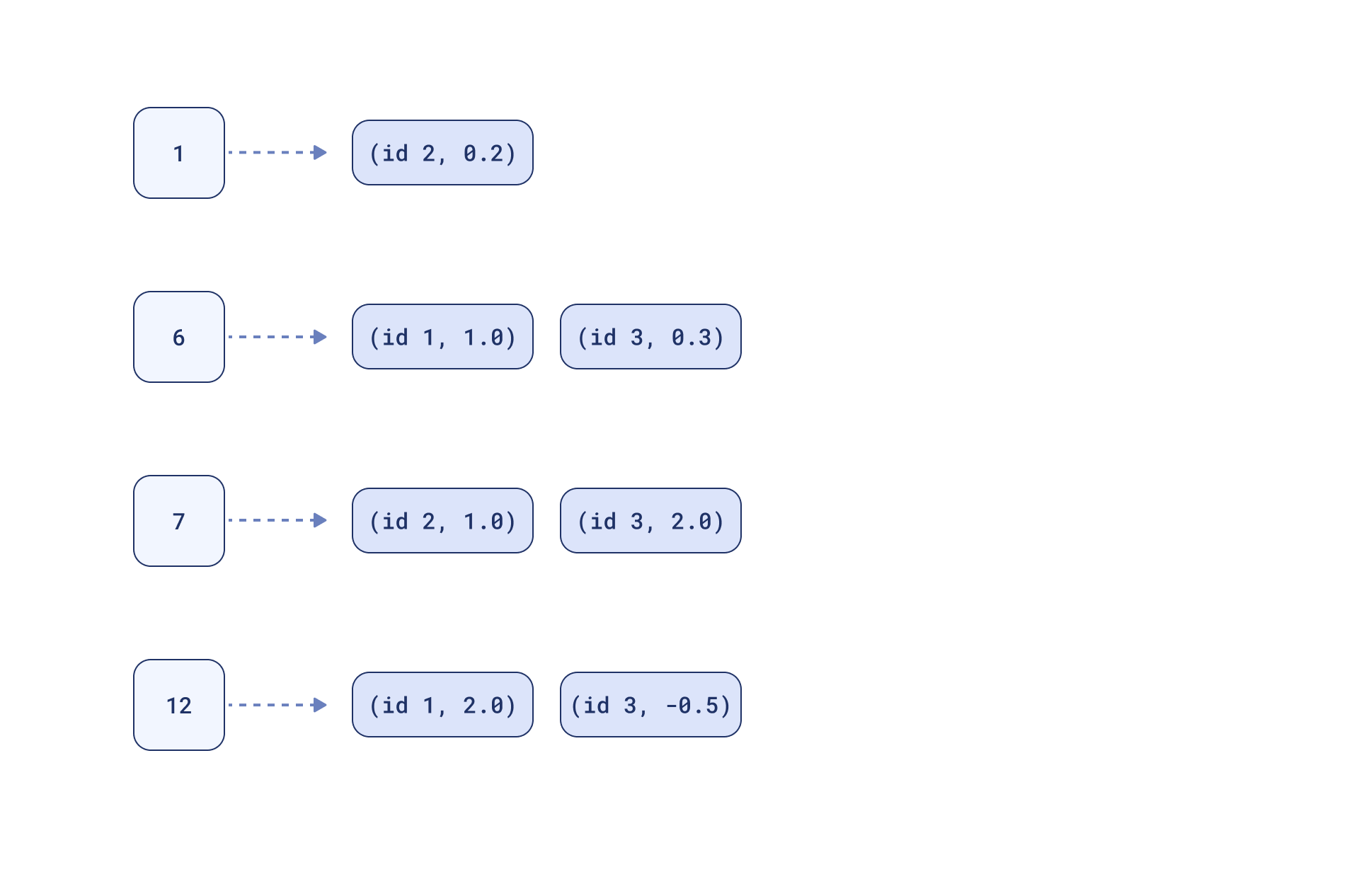
现在,如果我们有一个查询
[(6, 1.0), (7, 2.0)]
搜索将包括在映射中查找6和7并计算重叠部分的得分
id_1: (6: 1.0*1.0) = 1.0
id_2: (7: 2.0*1.0) = 2.0
id_3: (6: 1.0*0.3) + (7: 2.0*2.0) = 0.3 + 4.0 = 4.3
这个简单的映射是倒排索引的精髓,它是一种在检索系统中组织稀疏向量元素的数据结构。它通过将每个非零维度映射到它出现的向量来反转表示。
倒排索引确保稀疏搜索即使在大规模下也能保持精确和快速。
Qdrant 中的稀疏向量
在 Colab 中跟着学习: ![]()
Qdrant 集合中的稀疏向量使用sparse_vectors_config进行配置。
与密集向量配置不同,我们不需要为稀疏向量定义大小或距离度量
- 大小根据稀疏向量中非零元素的数量而变化。
- 非零元素的最大数量(即稀疏向量的大小)受
uint32类型的限制,这意味着 4,294,967,296 个非零元素。
- 非零元素的最大数量(即稀疏向量的大小)受
- 比较稀疏向量的距离度量始终是
点积。
稀疏向量在 Qdrant 中不是默认的(与密集向量不同)。这就是为什么,要配置带有稀疏向量的集合,你总是需要给它们一个名称。
命名向量还允许我们为同一点使用多个向量,例如,一个密集向量和一个稀疏向量。我们将在接下来的关于
混合搜索的视频中详细介绍这一点。
创建带有稀疏向量的集合
# Create collection with a named sparse vector
client.create_collection(
collection_name=<COLLECTION_NAME>,
sparse_vectors_config={
<SPARSE_VECTOR_NAME>: models.SparseVectorParams()
},
)
(可选)调整倒排索引
默认设置经过精心选择,通常能很好地工作;仅当你理解权衡时才进行调整!
参数
full_scan_threshold(int) – 达到此数字(不包括在内),在比较期间将不使用倒排索引(但仍然会构建)。on_disk(bool) – 将倒排索引存储在磁盘上(True)或 RAM 中(False,默认)。datatype– 存储在索引内部的值的精度:uint8|float16|float32(默认)。- 无论
datatype值如何,原始值仍然存储在磁盘上。
- 无论
client.create_collection(
collection_name=<COLLECTION_NAME>,
sparse_vectors_config={
<SPARSE_VECTOR_NAME>: models.SparseVectorParams(
index=models.SparseIndexParams(
full_scan_threshold=0, # compare directly below this size (index still built)
on_disk=False, # keep index in RAM (default False)
datatype=models.VectorStorageDatatype("float32") # precision inside the index
)
)
},
)
在 Qdrant 中存储稀疏向量
Qdrant 中的稀疏向量由以下组成
indices– 非零维度的索引(存储为uint32,因此范围从 0 到 4,294,967,295)。indices在向量内必须是唯一的。
values– 这些非零维度的值(存储为浮点数)。len(indices) == len(values).
client.upsert(
collection_name=<COLLECTION_NAME>,
points=[
models.PointStruct(
id=1,
vector={<SPARSE_VECTOR_NAME>: models.SparseVector(
indices=[1,2,3],
values=[0.2,-0.2,0.2]
)}
),
...
],
)
不要将向量的indices与倒排索引混淆。
indices描述了向量哪些维度是非零的。- 倒排索引是一种数据结构,它将每个维度映射到其中非零的所有向量。
对稀疏向量运行相似性搜索
使用using="sparse_vector"指定要搜索的命名向量。
client.query_points(
collection_name="sparse_vectors_collection",
using=<SPARSE_VECTOR_NAME>,
query=models.SparseVector(indices=[1,3], values=[1,1]),
...
)
稀疏向量的相似性得分是通过仅比较查询和点之间共享的匹配索引来计算的。
关键要点
- 当大多数特征缺失(为零)且你需要精确、特征对齐的匹配时,选择稀疏向量。
它们存储效率高,并且在未来的混合搜索设置中与密集向量配合良好。 - 相似性 = 点积。Qdrant 中稀疏向量的相似性始终通过点积来衡量。
- 稀疏向量组织在倒排索引中(与用于密集向量的HNSW是独立的数据结构)。
Qdrant 中稀疏向量的搜索是精确的,与近似密集向量搜索不同。
下一步
在下一个视频中,我们将使用 Qdrant 中的稀疏向量构建基于关键词的检索。
我们将使用 BM25 并涉及稀疏神经检索,这是一种具有语义理解的基于关键词的检索。这将为你设置混合搜索管道,本天材料的后半部分将涵盖这些内容。