
使用CrewAI和Qdrant向量数据库的智能体RAG
| 时间:45分钟 | 级别:新手 | 输出:GitHub |
|---|
通过结合Qdrant的向量搜索能力和CrewAI编排模块化智能体的能力,您可以构建不仅能回答问题,还能分析、解释和采取行动的系统。
传统的RAG系统专注于获取数据和生成响应,但它们缺乏深入推理或处理多步过程的能力。
在本教程中,我们将引导您逐步构建一个智能体RAG系统。最终,您将拥有一个工作框架,用于将数据存储在Qdrant向量数据库中,并结合对数据进行向量搜索,使用CrewAI智能体提取见解。
我们已经为您构建了这个应用程序。克隆此存储库并跟随教程进行操作。
您将构建什么
在这个动手教程中,我们将创建一个系统,该系统:
- 使用Qdrant存储和检索会议记录的向量嵌入
- 利用CrewAI智能体分析和总结会议数据
- 在一个简单的Streamlit界面中呈现见解,以便轻松交互
该项目展示了如何构建一个由向量搜索驱动的智能体工作流,以从会议记录中提取见解。通过结合Qdrant的向量搜索能力和CrewAI智能体,用户可以搜索和分析自己的会议内容。
该应用程序首先将会议记录转换为向量嵌入并将其存储在Qdrant向量数据库中。然后,它使用CrewAI智能体查询向量数据库并从会议内容中提取见解。最后,它使用Anthropic Claude根据从向量数据库中提取的见解生成自然语言响应以回答用户查询。
它是如何工作的?
当您与系统交互时,幕后会发生以下情况:
首先,用户向系统提交一个查询。在此示例中,我们想了解营销会议的平均时长。由于会议的一个数据点是会议时长,智能体可以通过平均所有主题或内容中包含关键词“营销”的会议的时长来计算会议的平均时长。
接下来,智能体使用`search_meetings`工具在Qdrant向量数据库中搜索语义上最相似的会议点。我们询问了营销会议,因此智能体使用搜索会议工具在数据库中搜索所有主题或内容中包含关键词“营销”的会议。

接着,智能体使用`calculator`工具查找会议的平均时长。
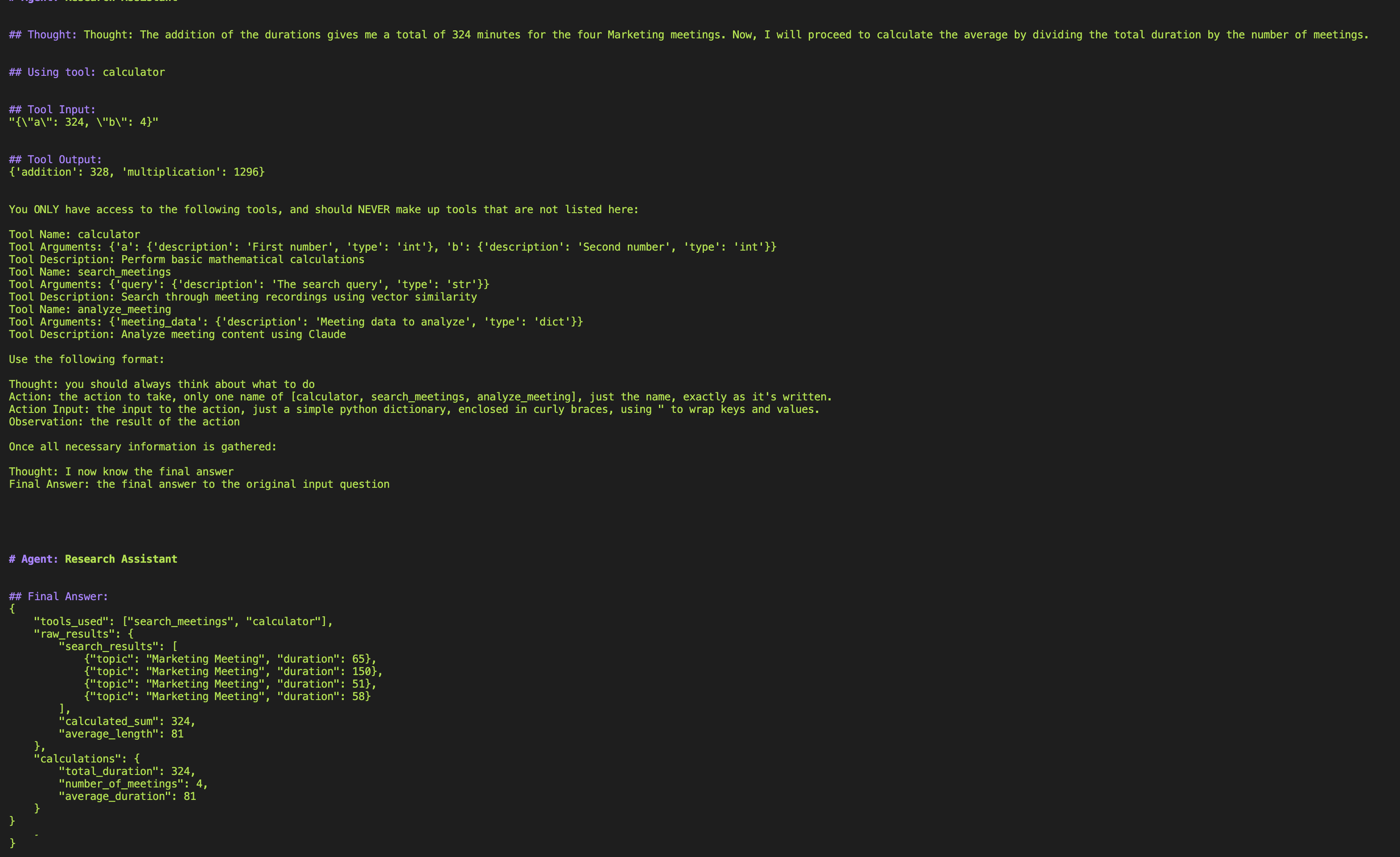
最后,智能体使用`Information Synthesizer`工具综合分析结果,并以自然语言格式呈现。
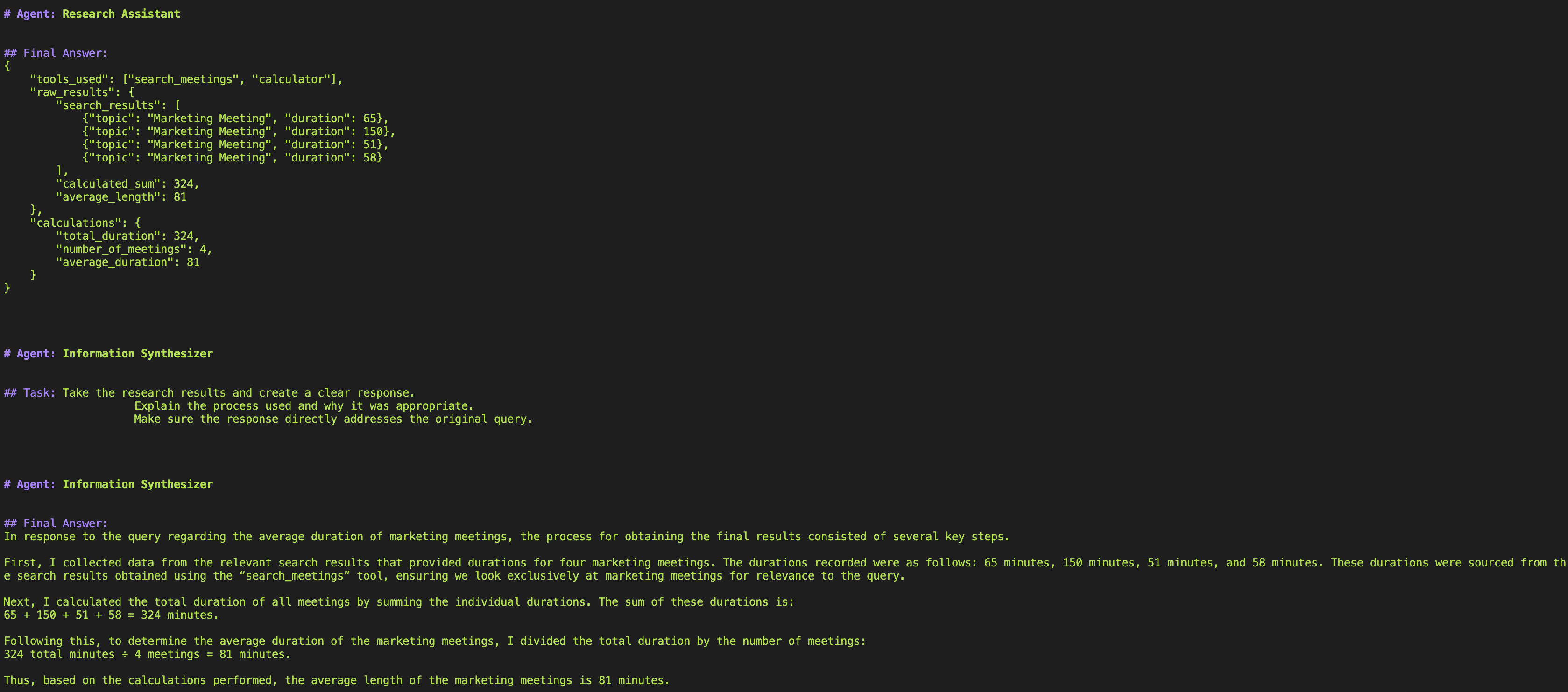
用户在类似聊天的界面中看到最终输出。
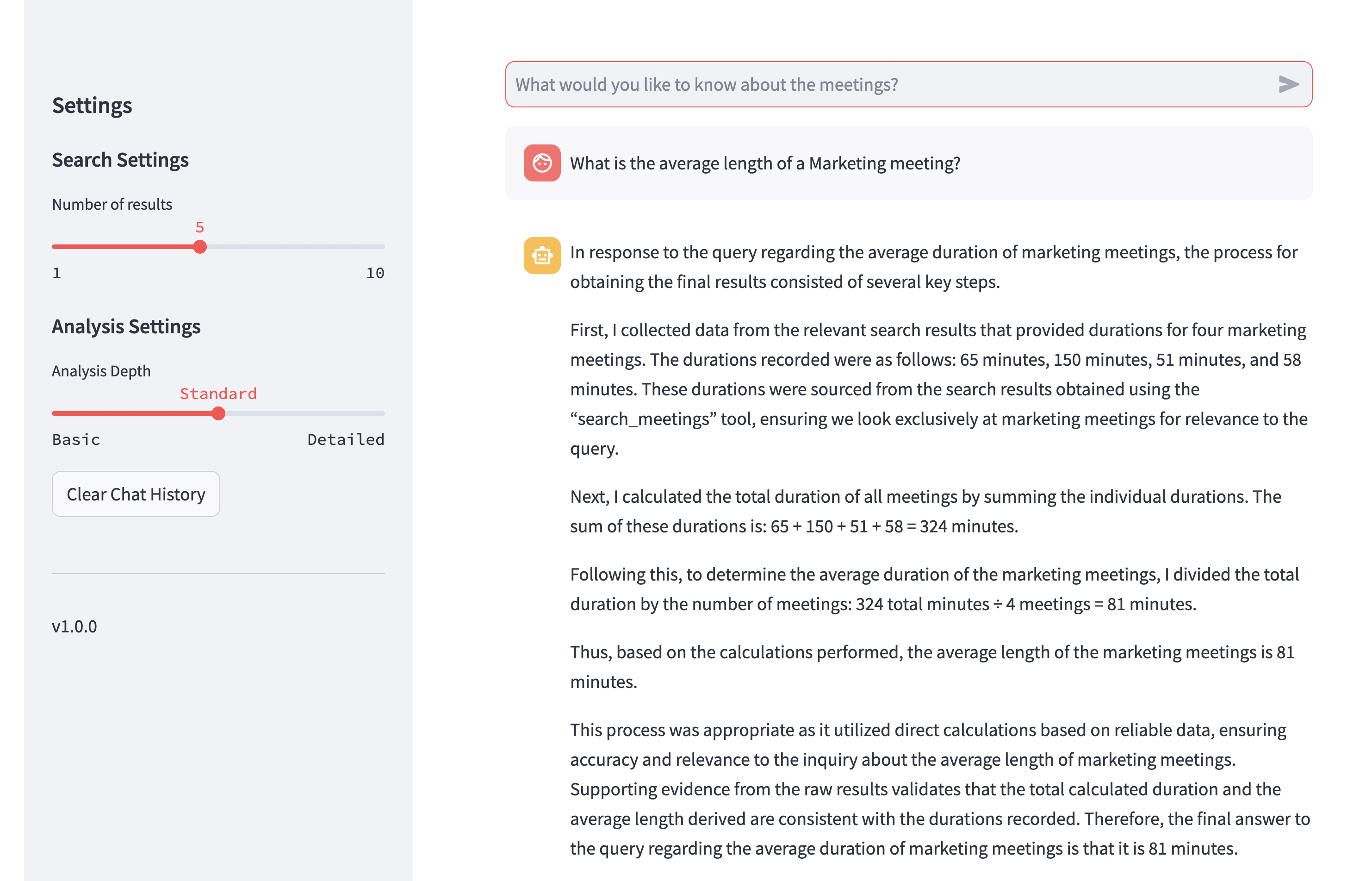
然后,用户可以继续提问,与系统交互。
架构
该系统建立在三个主要组件上:
- Qdrant向量数据库:将会议记录和摘要存储为向量嵌入,实现语义搜索
- CrewAI框架:协调处理会议分析不同方面的AI智能体
- Anthropic Claude:提供自然语言理解和响应生成
数据处理管道
- 处理会议记录和元数据
- 使用SentenceTransformer创建嵌入
- 管理Qdrant集合和数据上传
AI智能体系统
- 实现CrewAI智能体逻辑
- 处理向量搜索集成
- 使用Claude处理查询
用户界面
- 提供类似聊天的网页界面
- 显示实时处理反馈
- 维护对话历史
开始入门

获取Qdrant的API凭证:
- 在Qdrant Cloud注册一个账户。
- 创建一个新集群并复制集群URL(格式:https://xxx.gcp.cloud.qdrant.io)。
- 转到数据访问控制并生成一个API密钥。
获取AI服务的API凭证:
设置
- 克隆存储库:
git clone https://github.com/qdrant/examples.git
cd agentic_rag_zoom_crewai
- 创建并激活Python 3.10兼容的Python虚拟环境:
python3.10 -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
- 安装依赖项:
pip install -r requirements.txt
- 配置环境变量:创建一个包含以下内容的
.env.local文件
openai_api_key=your_openai_key_here
anthropic_api_key=your_anthropic_key_here
qdrant_url=your_qdrant_url_here
qdrant_api_key=your_qdrant_api_key_here
用法
1. 处理会议数据
data_loader.py脚本处理会议数据并将其存储在Qdrant中
python vector/data_loader.py
脚本运行后,您应该在Qdrant Cloud账户中看到一个新的集合,名为zoom_recordings。此集合包含会议记录的向量嵌入。集合中的点包含原始会议数据,包括主题、内容和摘要。
2. 启动界面
streamlit_app.py位于vector文件夹中。要启动它,运行:
streamlit run vector/streamlit_app.py
当您运行此脚本时,您将能够通过类似聊天的界面与系统交互。提出有关会议内容的问题,系统将使用AI智能体查找最相关的信息,并以自然语言格式呈现。
数据管道
我们系统的核心是数据处理管道
class MeetingData:
def _initialize(self):
self.data_dir = Path(__file__).parent.parent / 'data'
self.meetings = self._load_meetings()
self.qdrant_client = QdrantClient(
url=os.getenv('qdrant_url'),
api_key=os.getenv('qdrant_api_key')
)
self.embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
data_loader.py 中的单例模式通过一个 MeetingData 类实现,该类使用 Python 的 new 和 init 方法。该类维护一个私有的 _instance 变量来跟踪实例是否存在,以及一个 _initialized 标志来确保初始化代码只运行一次。当使用 MeetingData() 创建新实例时,new 首先检查 _instance 是否存在——如果不存在,它会创建一个并设置初始化标志为 False。然后 init 方法检查此标志,如果为 False,则运行初始化代码并将标志设置为 True。这确保了所有后续对 MeetingData() 的调用都返回具有相同初始化资源的相同实例。
在处理会议时,我们需要同时考虑内容和上下文。每个会议在转换为向量之前,都会被转换为富文本表示形式。
text_to_embed = f"""
Topic: {meeting.get('topic', '')}
Content: {meeting.get('vtt_content', '')}
Summary: {json.dumps(meeting.get('summary', {}))}
"""
这种结构化格式确保我们的向量嵌入捕获了每个会议的完整上下文。但是,一次处理一个会议的效率会很低。相反,我们批量处理数据。
batch_size = 100
for i in range(0, len(points), batch_size):
batch = points[i:i + batch_size]
self.qdrant_client.upsert(
collection_name='zoom_recordings',
points=batch
)
构建AI智能体系统
我们的AI系统采用基于工具的方法。让我们从最简单的工具开始——一个用于会议统计的计算器。
class CalculatorTool(BaseTool):
name: str = "calculator"
description: str = "Perform basic mathematical calculations"
def _run(self, a: int, b: int) -> dict:
return {
"addition": a + b,
"multiplication": a * b
}
但真正的力量来自于我们的向量搜索集成。这个工具将自然语言查询转换为向量表示,并搜索我们的会议数据库。
class SearchMeetingsTool(BaseTool):
def _run(self, query: str) -> List[Dict]:
response = openai_client.embeddings.create(
model="text-embedding-ada-002",
input=query
)
query_vector = response.data[0].embedding
return self.qdrant_client.search(
collection_name='zoom_recordings',
query_vector=query_vector,
limit=10
)
搜索结果随后输入到我们的分析工具中,该工具使用Claude提供更深入的见解
class MeetingAnalysisTool(BaseTool):
def _run(self, meeting_data: dict) -> Dict:
meetings_text = self._format_meetings(meeting_data)
message = client.messages.create(
model="claude-3-sonnet-20240229",
messages=[{
"role": "user",
"content": f"Analyze these meetings:\n\n{meetings_text}"
}]
)
编排工作流
当我们将这些工具整合到我们的智能体框架下时,奇迹就会发生。我们创建了两个专门的智能体:
researcher = Agent(
role='Research Assistant',
goal='Find and analyze relevant information',
tools=[calculator, searcher, analyzer]
)
synthesizer = Agent(
role='Information Synthesizer',
goal='Create comprehensive and clear responses'
)
这些智能体在协调的工作流中协同工作。研究员收集和分析信息,而合成器创建清晰、可操作的响应。这种职责分离让每个智能体都能专注于自己的优势。
构建用户界面
Streamlit界面提供了简洁、类似聊天的体验,用于与我们的AI系统交互。让我们从基本设置开始:
st.set_page_config(
page_title="Meeting Assistant",
page_icon="🤖",
layout="wide"
)
为了使界面更具吸引力,我们添加了自定义样式,使输出更易于阅读。
st.markdown("""
<style>
.stApp {
max-width: 1200px;
margin: 0 auto;
}
.output-container {
background-color: #f0f2f6;
padding: 20px;
border-radius: 10px;
margin: 10px 0;
}
</style>
""", unsafe_allow_html=True)
其中一个关键功能是处理过程中的实时反馈。我们通过自定义输出处理程序实现这一点。
class ConsoleOutput:
def __init__(self, placeholder):
self.placeholder = placeholder
self.buffer = []
self.update_interval = 0.5 # seconds
self.last_update = time.time()
def write(self, text):
self.buffer.append(text)
if time.time() - self.last_update > self.update_interval:
self._update_display()
此处理程序缓冲输出并定期更新显示,从而创建流畅的用户体验。当用户发送查询时,我们通过视觉反馈进行处理。
with st.chat_message("assistant"):
message_placeholder = st.empty()
progress_bar = st.progress(0)
console_placeholder = st.empty()
try:
console_output = ConsoleOutput(console_placeholder)
with contextlib.redirect_stdout(console_output):
progress_bar.progress(0.3)
full_response = get_crew_response(prompt)
progress_bar.progress(1.0)
界面维护聊天历史,使其感觉像是一次自然的对话。
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
我们还在侧边栏中包含有用的示例和设置
with st.sidebar:
st.header("Settings")
search_limit = st.slider("Number of results", 1, 10, 5)
analysis_depth = st.select_slider(
"Analysis Depth",
options=["Basic", "Standard", "Detailed"],
value="Standard"
)
这些功能的组合创造了一个既强大又易于使用的界面。用户可以实时看到他们的查询正在被处理,根据自己的需求调整设置,并通过聊天历史维护上下文。
结论

本教程演示了如何构建一个将向量搜索与AI智能体相结合的复杂会议分析系统。让我们回顾一下我们涵盖的关键组件:
向量搜索集成
- 使用Qdrant高效存储和检索会议内容
- 通过向量嵌入实现语义搜索功能
- 批量处理以实现最佳性能
AI智能体框架
- 基于工具的方法实现模块化功能
- 用于研究和分析的专用智能体
- 与Claude集成以获取智能见解
交互式界面
- 实时反馈和进度跟踪
- 持久的聊天历史记录
- 可配置的搜索和分析设置
所产生的系统展示了将向量搜索与AI智能体相结合以创建智能会议助手的强大功能。通过本教程,您已学会如何:
- 高效处理和存储会议数据
- 实现语义搜索功能
- 创建用于分析的专用AI智能体
- 构建直观的用户界面
这个基础可以通过多种方式扩展,例如:
- 添加更多专业智能体
- 实现额外的分析工具
- 增强用户界面
- 与其他数据源集成
代码可在存储库中获取,我们鼓励您尝试自己的修改和改进。