使用 LangGraph 和 Qdrant 实现代理式 RAG
传统检索增强生成 (RAG) 系统遵循一条直接的路径:查询 → 检索 → 生成。当然,这在许多场景中都运行良好。但我们不得不承认,当您处理需要多个步骤或整合不同类型信息的复杂查询时,这种线性方法常常力不从心。
代理式 RAG 通过引入 AI 代理,将事情提升了一个档次。这些代理能够协调多个检索步骤,并智能地决定如何收集和使用您所需的信息。可以这样理解:在代理式 RAG 工作流中,RAG 只是一个更庞大、更多功能工具包中的一个强大工具。
通过将 LangGraph 强大的状态管理与 Qdrant 尖端的向量搜索相结合,我们将构建一个不仅能回答问题,还能巧妙应对复杂、多步骤信息检索任务的系统。
我们将构建什么
我们将构建一个 AI 代理,使用 LangGraph 回答有关 Hugging Face 和 Transformers 文档的问题。我们 AI 代理的核心是 LangGraph,它就像管弦乐队中的指挥。它引导着各个组件之间的流程——决定何时检索信息、何时执行网络搜索以及何时生成响应。
这些组件包括:两个 Qdrant 向量存储和 Brave 网页搜索引擎。然而,我们的代理并不只是盲目地遵循一条路径。相反,它会评估每个查询,并决定是使用第一个向量存储、第二个向量存储,还是搜索网络。
这种选择性方法为您的系统提供了灵活性,使其能够为工作选择最佳数据源,而不是像传统 RAG 那样每次都被锁定在相同的检索过程中。虽然本教程不会深入探讨查询优化,但您在此处学到的概念是为将来添加该功能奠定的坚实基础。
工作流程
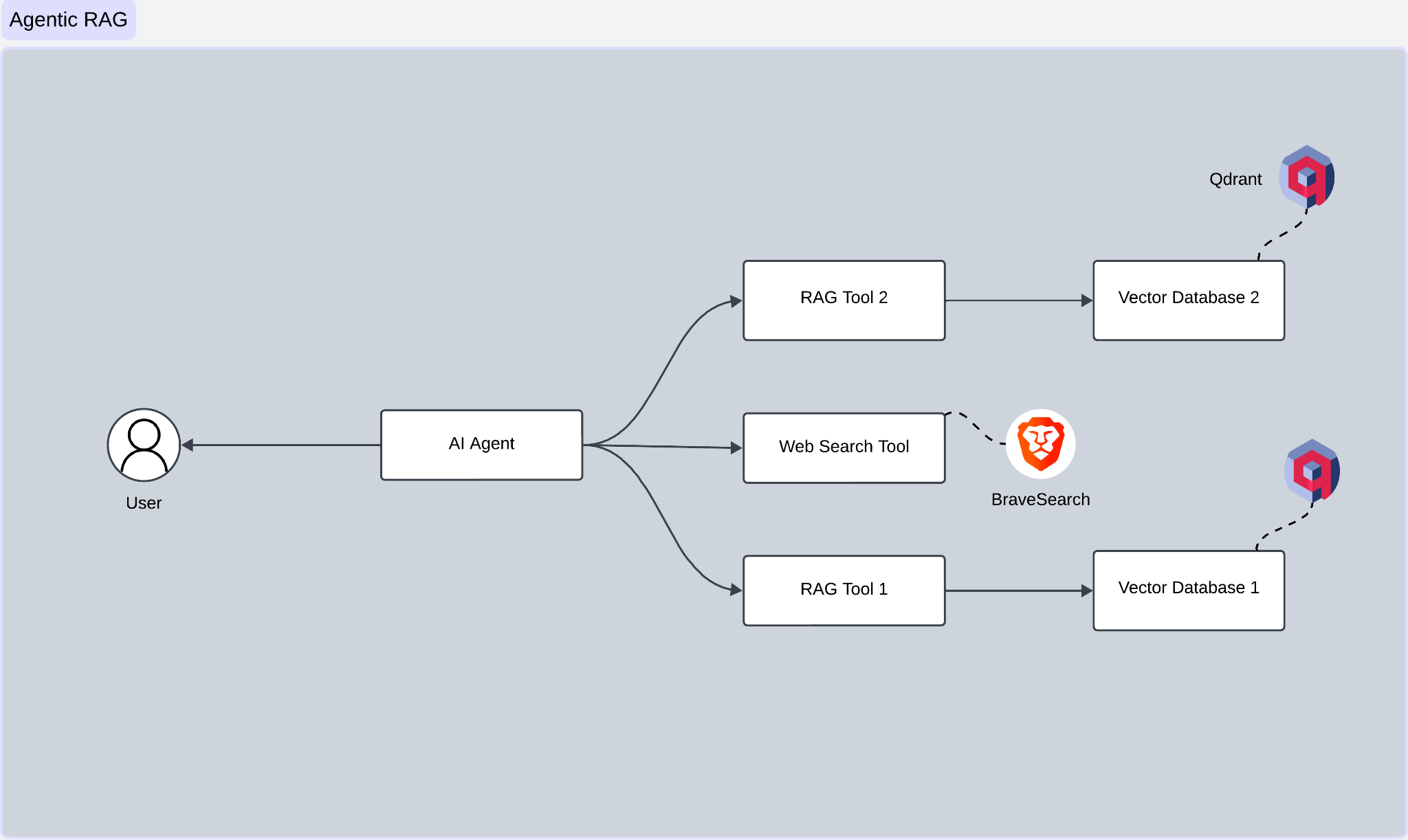
| 步骤 | 描述 |
|---|---|
| 1. 用户输入 | 您首先通过聊天机器人或网络表单等界面输入查询或请求。此查询将直接发送到 AI 代理,即操作的大脑。 |
| 2. AI 代理处理查询 | AI 代理分析您的查询,找出您的问题以及哪些工具或数据源能最好地回答您的问题。 |
| 3. 工具选择 | 根据其分析,AI 代理选择合适的工具。您的数据分散在两个向量数据库中,代理根据查询选择合适的数据库。对于需要实时或外部网络数据的查询,代理会利用由 BraveSearchAPI 提供支持的网络搜索工具。 |
| 4. 查询执行 | AI 代理随后将其选定的工具投入工作 - RAG 工具 1 查询向量数据库 1。 - RAG 工具 2 查询向量数据库 2。 - 网络搜索工具 使用搜索 API 深入互联网。 |
| 5. 数据检索 | 结果出炉 - 向量数据库 1 和 2 返回与您的查询最相关的文档。 - 网络搜索工具提供最新或外部信息。 |
| 6. 响应生成 | AI 代理使用文本生成模型(如 GPT)根据您的查询精心制作详细而准确的响应。 |
| 7. 用户响应 | 经过优化的响应通过界面返回给您,即可使用。 |
技术栈
该架构利用尖端工具为高效的代理式 RAG 工作流提供支持。以下是其组件和您所需技术的快速概述
- AI 代理: 系统的核心,此代理解析您的查询,选择正确的工具并整合响应。我们将使用 OpenAI 的 gpt-4o 作为推理引擎,由 LangGraph 无缝管理。
- 嵌入: 使用 OpenAI 的 text-embedding-3-small 模型将查询转换为向量嵌入。
- 向量数据库: 嵌入存储并用于相似性搜索,Qdrant 作为我们首选的数据库。
- LLM: 使用 OpenAI 的 gpt-4o 生成响应,确保答案准确且符合上下文。
- 搜索工具: 为了扩展 RAG 的功能,我们添加了一个由 BraveSearchAPI 提供支持的网页搜索组件,非常适合实时和外部数据检索。
- 工作流管理: 整个编排和决策流使用 LangGraph 构建,提供处理复杂工作流所需的灵活性和智能。
准备好从头开始构建这个系统了吗?让我们开始吧!
实施
在我们开始构建代理之前,让我们先进行所有设置。
导入
以下是所需关键导入的列表
import os
import json
from typing import Annotated, TypedDict
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langgraph import StateGraph, tool, ToolNode, ToolMessage
from langchain.document_loaders import HuggingFaceDatasetLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import ChatOpenAI
from qdrant_client import QdrantClient
from qdrant_client.http.models import VectorParams
from brave_search import BraveSearch
Qdrant 向量数据库设置
我们将使用 Qdrant Cloud 作为文档嵌入的向量存储。以下是如何设置它
| 步骤 | 描述 |
|---|---|
| 1. 创建账户 | 如果您还没有账户,请前往 Qdrant Cloud 并注册。 |
| 2. 设置集群 | 登录您的账户,并在仪表板上找到 Create New Cluster 按钮。按照提示进行配置 - 选择您首选的区域。 - 选择免费套餐进行测试。 |
| 3. 保护您的详细信息 | 集群准备就绪后,请记下这些详细信息 - 集群 URL(例如,https://xxx-xxx-xxx.aws.cloud.qdrant.io) - API 密钥 |
妥善保存这些信息以备将来使用!
OpenAI API 配置
您的 OpenAI API 密钥将为嵌入生成和语言模型交互提供动力。访问 OpenAI 平台并注册一个账户。在仪表板的 API 部分,创建一个新的 API 密钥。我们将使用 text-embedding-3-small 模型进行嵌入,并使用 GPT-4 作为语言模型。
Brave 搜索
为了增强搜索能力,我们将集成 Brave Search。访问 Brave API 并完成其 API 访问请求过程以获取 API 密钥。此密钥将为我们的代理启用网页搜索功能。
为了增加安全性,请将所有 API 密钥存储在 .env 文件中。
OPENAI_API_KEY = <your-openai-api-key>
QDRANT_KEY = <your-qdrant-api-key>
QDRANT_URL = <your-qdrant-url>
BRAVE_API_KEY = <your-brave-api-key>
然后加载环境变量
load_dotenv()
qdrant_key = os.getenv("QDRANT_KEY")
qdrant_url = os.getenv("QDRANT_URL")
brave_key = os.getenv("BRAVE_API_KEY")
文档处理
在创建代理之前,我们需要处理并存储文档。我们将使用 Hugging Face 的两个数据集:其通用文档和特定于 Transformers 的文档。
这是我们的文档预处理函数
def preprocess_dataset(docs_list):
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=700,
chunk_overlap=50,
disallowed_special=()
)
doc_splits = text_splitter.split_documents(docs_list)
return doc_splits
此函数通过将文档拆分成可管理的小块来处理我们的文档,通过重叠确保在小块边界处保留重要的上下文。我们将使用 HuggingFaceDatasetLoader 将数据集加载到 Hugging Face 文档中。
hugging_face_doc = HuggingFaceDatasetLoader("m-ric/huggingface_doc","text")
transformers_doc = HuggingFaceDatasetLoader("m-ric/transformers_documentation_en","text")
在此演示中,我们从数据集中选择前 50 个文档并将它们传递给处理函数。
hf_splits = preprocess_dataset(hugging_face_doc.load()[:number_of_docs])
transformer_splits = preprocess_dataset(transformers_doc.load()[:number_of_docs])
我们的拆分已准备就绪。让我们在 Qdrant 中创建一个集合来存储它们。
定义状态
在 LangGraph 中,状态是指在过程或一系列操作执行期间的特定点存储和维护的数据或信息。状态捕获系统需要跟踪的中间或最终结果,以管理和控制任务流,
LangGraph 使用基于状态的系统。我们这样定义我们的状态
class State(TypedDict):
messages: Annotated[list, add_messages]
让我们构建我们的工具。
构建工具
我们的代理配备了三个强大的工具
- Hugging Face 文档检索器
- Transformers 文档检索器
- 网络搜索工具
让我们首先定义一个检索器,它接受文档和集合名称,然后返回一个检索器。查询使用 OpenAIEmbeddings 转换为向量。
def create_retriever(collection_name, doc_splits):
vectorstore = QdrantVectorStore.from_documents(
doc_splits,
OpenAIEmbeddings(model="text-embedding-3-small"),
url=qdrant_url,
api_key=qdrant_key,
collection_name=collection_name,
)
return vectorstore.as_retriever()
Hugging Face 文档检索器和 Transformers 文档检索器都使用相同的函数。通过这种设置,为每个工具创建单独的工具变得非常简单。
hf_retriever_tool = create_retriever_tool(
hf_retriever,
"retriever_hugging_face_documentation",
"Search and return information about hugging face documentation, it includes the guide and Python code.",
)
transformer_retriever_tool = create_retriever_tool(
transformer_retriever,
"retriever_transformer",
"Search and return information specifically about transformers library",
)
对于网络搜索,我们使用 Brave Search 创建了一个简单而有效的工具
@tool("web_search_tool")
def search_tool(query):
search = BraveSearch.from_api_key(api_key=brave_key, search_kwargs={"count": 3})
return search.run(query)
search_tool 函数利用 BraveSearch API 执行搜索。它接受一个查询,使用 API 密钥检索前 3 个搜索结果,并返回结果。
接下来,我们将设置并集成我们的工具与语言模型
tools = [hf_retriever_tool, transformer_retriever_tool, search_tool]
tool_node = ToolNode(tools=tools)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
llm_with_tools = llm.bind_tools(tools)
在这里,ToolNode 类处理和协调我们的工具
class ToolNode:
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
ToolNode 类通过初始化工具列表并将工具名称映射到其对应的函数来处理工具执行。它处理输入字典,提取最后一条消息,并检查来自 LLM 工具调用能力提供商(如 Anthropic、OpenAI 等)的 tool_calls。
路由和决策
我们的代理需要确定何时使用工具以及何时结束循环。此决定由路由函数管理
def route(state: State):
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
整合所有部分:图
最后,我们将构建将所有内容连接在一起的图
graph_builder = StateGraph(State)
graph_builder.add_node("agent", agent)
graph_builder.add_node("tools", tool_node)
graph_builder.add_conditional_edges(
"agent",
route,
{"tools": "tools", END: END},
)
graph_builder.add_edge("tools", "agent")
graph_builder.add_edge(START, "agent")
图看起来像这样
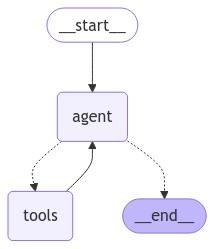
图 3:使用 LangGraph 的代理式 RAG
运行代理
设置好一切后,我们可以使用一个简单的函数运行我们的代理
def run_agent(user_input: str):
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
现在,您已准备好提出有关 Hugging Face 和 Transformers 的问题!我们的代理将在需要时智能地结合文档信息和网络搜索结果。
例如,您可以询问
In the Transformers library, are there any multilingual models?
代理将深入研究 Transformers 文档,提取有关多语言模型的相关详细信息,并提供清晰、全面的答案。
响应可能如下所示
Yes, the Transformers library includes several multilingual models. Here are some examples:
BERT Multilingual:
Models like `bert-base-multilingual-uncased` can be used just like monolingual models.
XLM (Cross-lingual Language Model):
Models like `xlm-mlm-ende-1024` (English-German), `xlm-mlm-enfr-1024` (English-French), and others use language embeddings to specify the language used at inference.
M2M100:
Models like `facebook/m2m100_418M` and `facebook/m2m100_1.2B` are used for multilingual translation.
MBart:
Models like `facebook/mbart-large-50-one-to-many-mmt` and `facebook/mbart-large-50-many-to-many-mmt` are used for multilingual machine translation across 50 languages.
These models are designed to handle multiple languages and can be used for tasks like translation, classification, and more.
结论
我们已经成功实现了代理式 RAG。但这仅仅是一个开始——您可以探索更多内容,将您的系统提升到新的水平。
代理式 RAG 正在改变企业将数据源与 AI 连接的方式,从而实现更智能、更动态的交互。在本教程中,您学习了如何构建一个代理式 RAG 系统,该系统将 LangGraph、Qdrant 和网络搜索的强大功能整合到一个无缝的工作流中。
该系统不仅能从 Hugging Face 和 Transformers 文档中检索相关信息。它还在需要时智能地回退到网络搜索,确保每个查询都能得到回答。以 Qdrant 作为向量数据库主干,您将获得快速、可扩展的语义搜索,即使在海量数据集中也能出色地检索精确信息。
为了真正掌握这种方法的潜力,何不将这些概念应用到您自己的项目中呢?自定义我们分享的模板以适应您独特的用例,并为您的业务需求释放代理式 RAG 的全部潜力。可能性是无限的。