
使用 LangChain 将 S3 数据发送到 Qdrant 向量存储
| 时间:30分钟 | 级别:新手 |
|---|
将数据摄取到向量存储中对于构建有效的搜索和检索算法至关重要,特别是因为近 80% 的数据是非结构化的,缺乏任何预定义的格式。
在本教程中,我们将创建一个精简的数据摄取管道,直接从 AWS S3 中提取数据并将其馈送到 Qdrant。我们将深入研究向量嵌入,将非结构化数据转换为允许您语义搜索文档的格式。准备好发现从非结构化数据中发现隐藏见解的新方法吧!
摄取工作流架构
我们将在此工作流中设置一个强大的文档摄取和分析管道,使用云存储、自然语言处理 (NLP) 工具和嵌入技术。从 S3 存储桶中的原始数据开始,我们将使用 LangChain 对其进行预处理,将嵌入 API 应用于文本和图像,并将结果存储在 Qdrant 中——一个针对相似性搜索优化的向量数据库。
图 1:数据摄取工作流架构
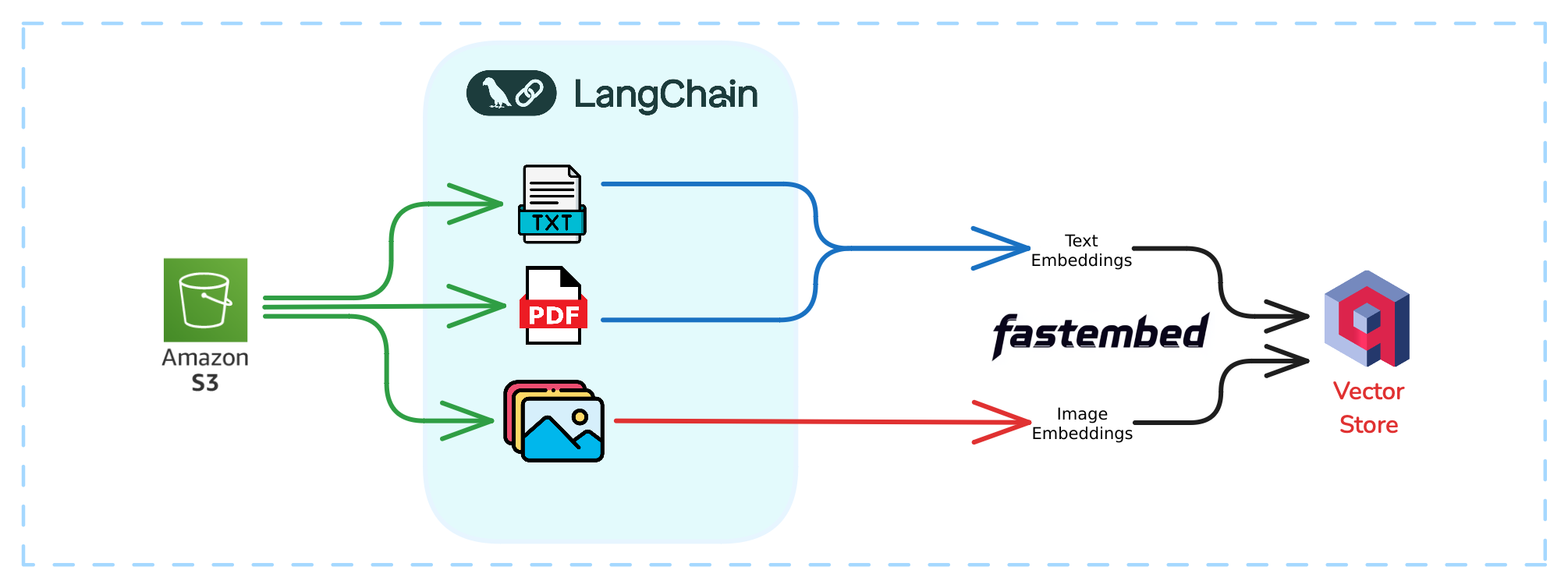
让我们分解一下这个工作流的每个组件
- S3 存储桶:这是我们的起点——一个用于各种文件类型(如 PDF、图像和文本)的集中式、可扩展存储解决方案。
- LangChain:作为管道的编排器,LangChain 处理提取、预处理和管理数据流以生成嵌入。它简化了 PDF 的处理,因此您无需担心在此处应用 OCR(光学字符识别)。
- Qdrant:作为您的向量数据库,Qdrant 存储嵌入及其有效载荷,从而实现所有内容类型的有效相似性搜索和检索。
先决条件

在本节中,您将获得从 S3 存储桶摄取数据的分步指南。但在我们深入探讨之前,请确保您已满足所有先决条件
| 样本数据 | 我们将使用一个样本数据集,其中每个文件夹都包含文本格式的产品评论以及相应的图像。 |
| AWS 账户 | 一个具有 S3 服务访问权限的活跃 AWS 账户。 |
| Qdrant 云 | 一个具有 WebUI 访问权限的 Qdrant Cloud 账户,用于管理集合和运行查询。 |
| LangChain | 您将使用这个 流行框架 将所有内容联系起来。 |
支持的文档类型
用于摄取的文档可以是各种类型,例如 PDF、文本文件或图像。我们将使用带有支持文档类型的文件夹来组织一个结构化的 S3 存储桶,以进行测试和实验。
Python 环境
确保您拥有一个安装了这些库的 Python 环境(Python 3.9 或更高版本)
boto3
langchain-community
langchain
python-dotenv
unstructured
unstructured[pdf]
qdrant_client
fastembed
访问密钥:将您的 AWS 访问密钥、S3 密钥和 Qdrant API 密钥存储在 .env 文件中,以便于访问。这是一个示例 .env 文件。
ACCESS_KEY = ""
SECRET_ACCESS_KEY = ""
QDRANT_KEY = ""
步骤 1:从 S3 摄取数据

LangChain 框架可以轻松地从 AWS S3 等存储服务摄取数据,并内置支持加载 PDF、图像和文本文件等格式的文档。
要将 LangChain 与 S3 连接,您将使用 S3DirectoryLoader,它允许您将文件直接从 S3 存储桶加载到 LangChain 的管道中。
示例:配置 LangChain 从 S3 加载文件
以下是如何设置 LangChain 从 S3 存储桶摄取数据的方法
from langchain_community.document_loaders import S3DirectoryLoader
# Initialize the S3 document loader
loader = S3DirectoryLoader(
"product-dataset", # S3 bucket name
"p_1", #S3 Folder name containing the data for the first product
aws_access_key_id=aws_access_key_id, # AWS Access Key
aws_secret_access_key=aws_secret_access_key # AWS Secret Access Key
)
# Load documents from the specified S3 bucket
docs = loader.load()
步骤 2:将文档转换为嵌入
嵌入是这里的秘密武器——它们是数据的数字表示(如文本、图像或音频),以易于比较的形式捕获“含义”。通过将文本和图像转换为嵌入,您将能够快速有效地执行相似性搜索。将嵌入视为将有意义的见解从数据存储和检索到 Qdrant 的桥梁。
我们将用于生成嵌入的模型
为了启动,我们将使用两个强大的模型
- 用于转换文本数据的
sentence-transformers/all-MiniLM-L6-v2嵌入。 - 用于图像数据的
CLIP(对比语言-图像预训练)。
文档处理函数

接下来,我们将定义两个函数——process_text 和 process_image 来处理文档管道中的不同文件类型。process_text 函数从基于文本的文档中提取并返回原始内容,而 process_image 从 S3 源检索图像并将其加载到内存中。
from PIL import Image
def process_text(doc):
source = doc.metadata['source'] # Extract document source (e.g., S3 URL)
text = doc.page_content # Extract the content from the text file
print(f"Processing text from {source}")
return source, text
def process_image(doc):
source = doc.metadata['source'] # Extract document source (e.g., S3 URL)
print(f"Processing image from {source}")
bucket_name, object_key = parse_s3_url(source) # Parse the S3 URL
response = s3.get_object(Bucket=bucket_name, Key=object_key) # Fetch image from S3
img_bytes = response['Body'].read()
img = Image.open(io.BytesIO(img_bytes))
return source, img
用于文档处理的辅助函数
为了从 S3 检索图像,辅助函数 parse_s3_url 将 S3 URL 分解为其存储桶和关键组件。这对于从 S3 存储中获取图像至关重要。
def parse_s3_url(s3_url):
parts = s3_url.replace("s3://", "").split("/", 1)
bucket_name = parts[0]
object_key = parts[1]
return bucket_name, object_key
步骤 3:将嵌入加载到 Qdrant

现在您的文档已处理并转换为嵌入,下一步是将这些嵌入加载到 Qdrant 中。
在 Qdrant 中创建集合
在 Qdrant 中,数据以集合组织,每个集合代表一组嵌入(或点)及其相关的元数据(有效载荷)。要存储前面生成的嵌入,您首先需要创建一个集合。
以下是如何在 Qdrant 中创建集合以存储文本和图像嵌入的方法
def create_collection(collection_name):
qdrant_client.create_collection(
collection_name,
vectors_config={
"text_embedding": models.VectorParams(
size=384, # Dimension of text embeddings
distance=models.Distance.COSINE, # Cosine similarity is used for comparison
),
"image_embedding": models.VectorParams(
size=512, # Dimension of image embeddings
distance=models.Distance.COSINE, # Cosine similarity is used for comparison
),
},
)
create_collection("products-data")
此函数创建一个集合,用于存储文本(384 维度)和图像(512 维度)嵌入,使用余弦相似度比较集合中的嵌入。
设置好集合后,您可以将嵌入加载到 Qdrant 中。这涉及将嵌入及其相关的元数据(有效载荷)插入(或更新)到指定的集合中。
以下是将嵌入加载到 Qdrant 中的代码
def ingest_data(points):
operation_info = qdrant_client.upsert(
collection_name="products-data", # Collection where data is being inserted
points=points
)
return operation_info
摄取说明
- 插入数据点:
qdrant_client上的 upsert 方法将每个 PointStruct 插入到指定的集合中。如果具有相同 ID 的点已存在,它将使用新值进行更新。 - 操作信息: 该函数返回
operation_info,其中包含有关 upsert 操作的详细信息,例如成功状态或任何潜在错误。
运行摄取代码
以下是如何调用函数并摄取数据的方法
from qdrant_client import models
if __name__ == "__main__":
collection_name = "products-data"
create_collection(collection_name)
for i in range(1,6): # Five documents
folder = f"p_{i}"
loader = S3DirectoryLoader(
"product-dataset",
folder,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key
)
docs = loader.load()
points, text_review, product_image = [], "", ""
for idx, doc in enumerate(docs):
source = doc.metadata['source']
if source.endswith(".txt") or source.endswith(".pdf"):
_text_review_source, text_review = process_text(doc)
elif source.endswith(".png"):
product_image_source, product_image = process_image(doc)
if text_review:
point = models.PointStruct(
id=idx, # Unique identifier for each point
vector={
"text_embedding": models.Document(
text=text_review, model="sentence-transformers/all-MiniLM-L6-v2"
),
"image_embedding": models.Image(
image=product_image, model="Qdrant/clip-ViT-B-32-vision"
),
},
payload={"review": text_review, "product_image": product_image_source},
)
points.append(point)
operation_info = ingest_data(points)
print(operation_info)
PointStruct 使用这些关键参数实例化
id:每个嵌入的唯一标识符,通常是递增的索引。
vector:一个字典,包含要嵌入的文本和图像输入。
qdrant-client在底层使用 FastEmbed 自动从这些输入中本地生成向量表示。payload:一个字典,存储额外的元数据,如产品评论和图像引用,这对于搜索期间的检索和上下文非常有价值。
该代码动态从 S3 存储桶加载文件夹,分别处理文本和图像文件,并将其嵌入和相关数据存储在专用列表中。然后它为每个数据条目创建一个 PointStruct,并调用摄取函数将其加载到 Qdrant 中。
探索 Qdrant WebUI 仪表板
将嵌入加载到 Qdrant 后,您可以使用 WebUI 仪表板可视化和管理您的集合。仪表板提供了一个清晰、结构化的界面,用于查看集合及其数据。让我们在下一节中仔细看看。
步骤 4:在 Qdrant WebUI 中可视化数据
要开始在 Qdrant WebUI 中可视化数据,请转到概览部分并选择访问数据库。
图 2:从 Qdrant UI 访问数据库 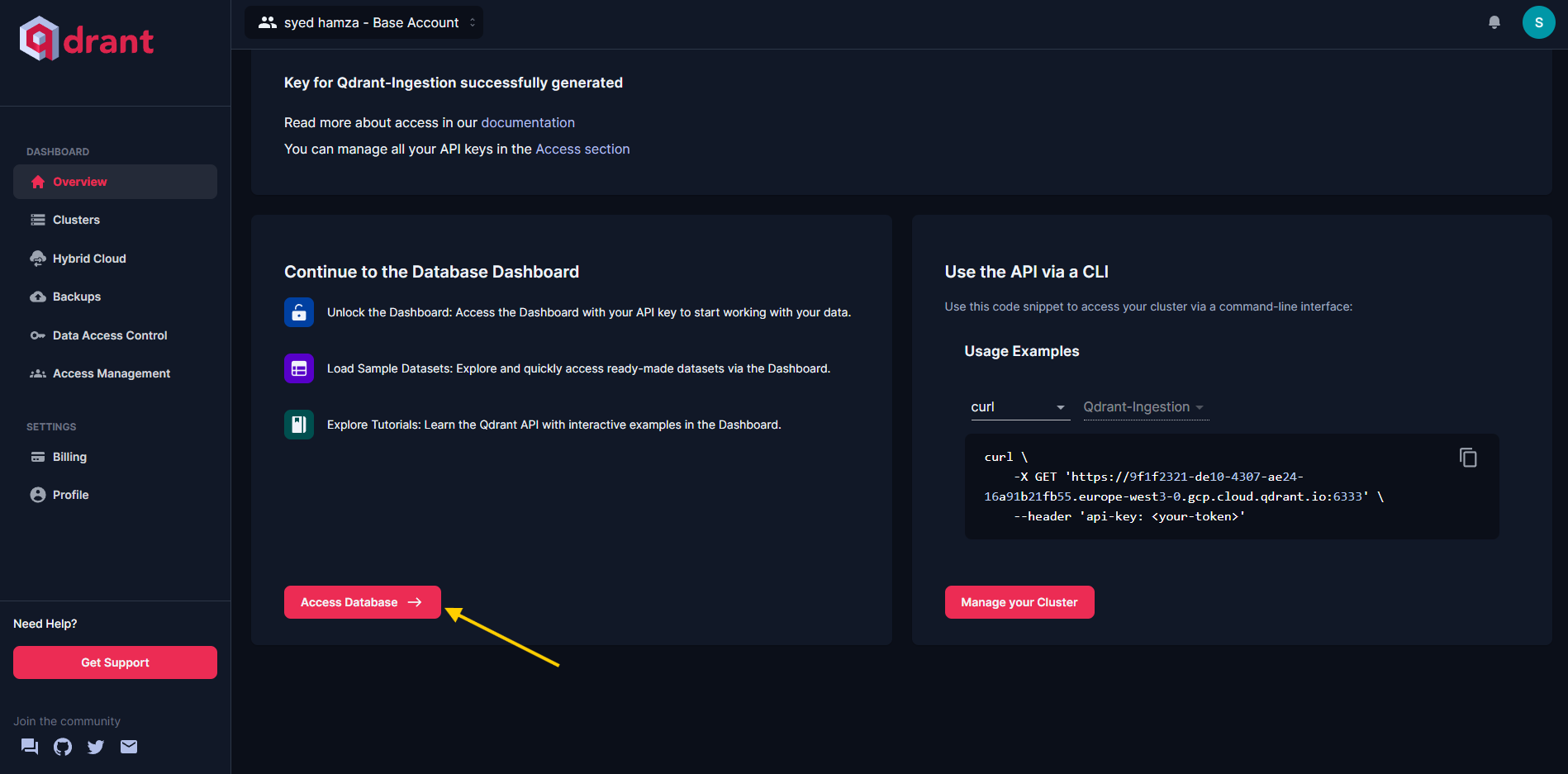
出现提示时,输入您的 API 密钥。进入后,您将能够查看您的集合和相应的数据点。您应该会看到您的集合显示如下
图 3:Qdrant 中的 product-data 集合 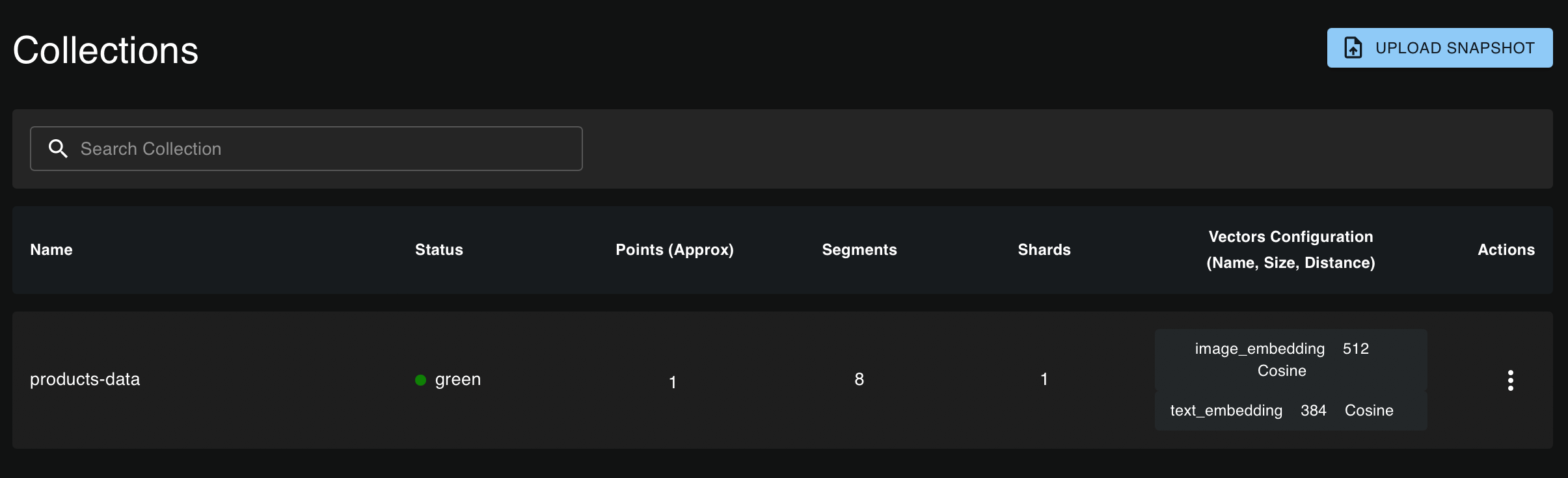
以下是摄取到 Qdrant 的最新点
图 4:添加到 product-data 集合的最新点 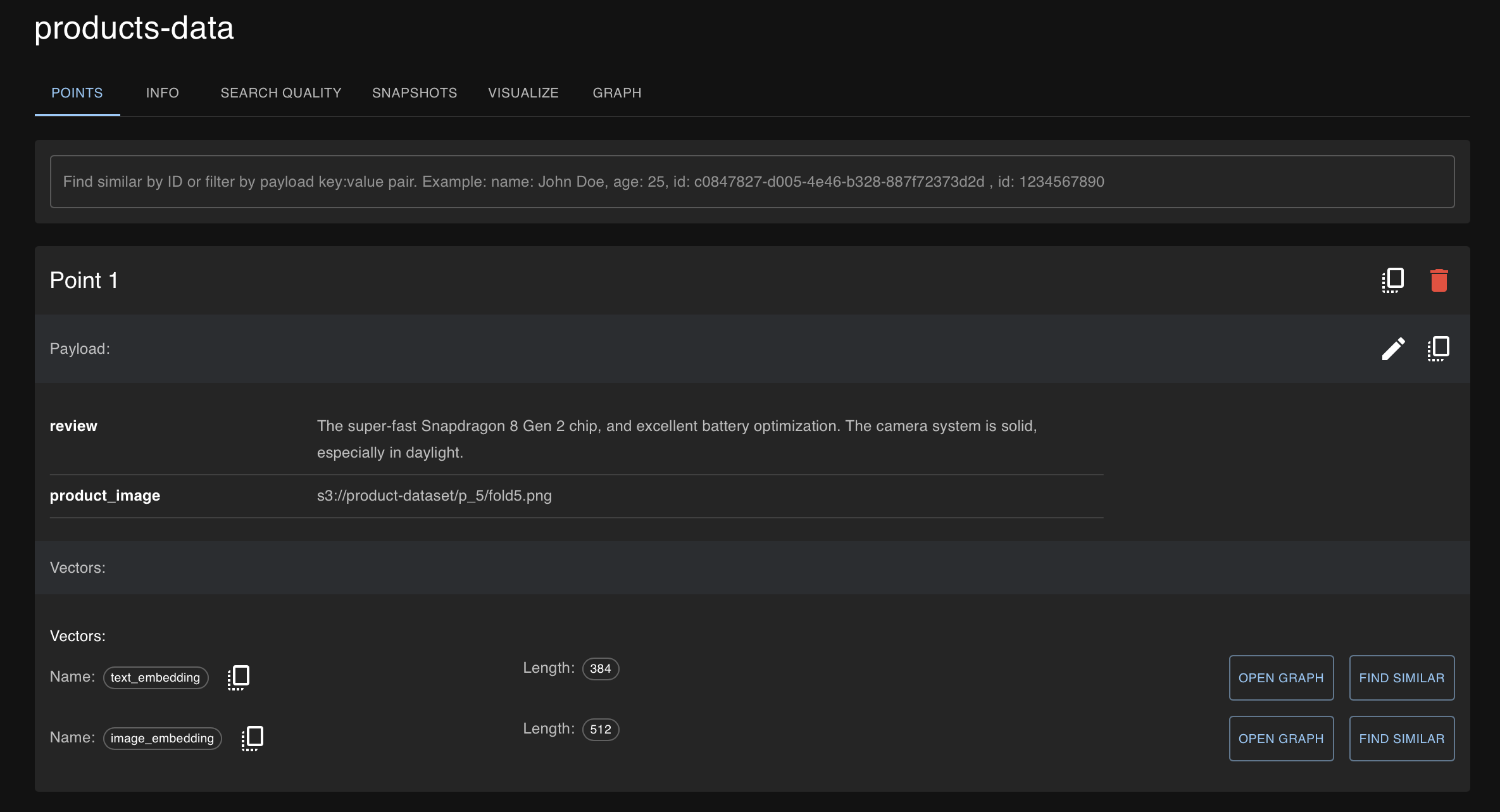
Qdrant WebUI 的搜索功能允许您在集合中执行向量搜索。通过应用过滤器和参数的选项,检索相关嵌入和探索数据中的关系变得容易。要开始,请转到左侧面板中的控制台,您可以在其中创建查询
图 5:Qdrant 控制台概览 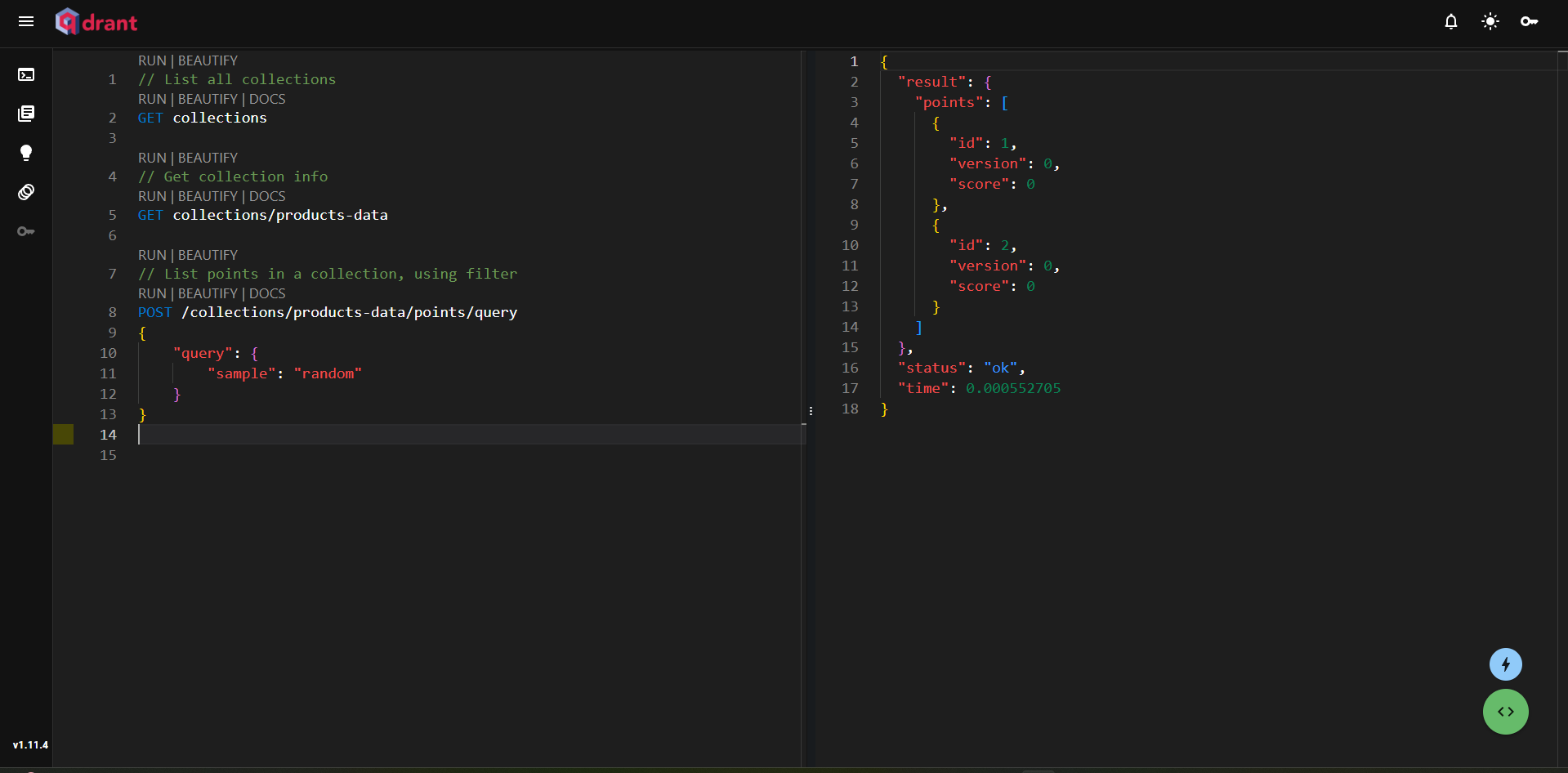
第一个查询检索所有集合,第二个从 product-data 集合中获取点,第三个执行示例查询。这表明在 Qdrant UI 中与数据交互是多么简单。
现在,让我们使用查询从数据库中检索一些文档!
图 6:查询 Qdrant 客户端以检索相关文档 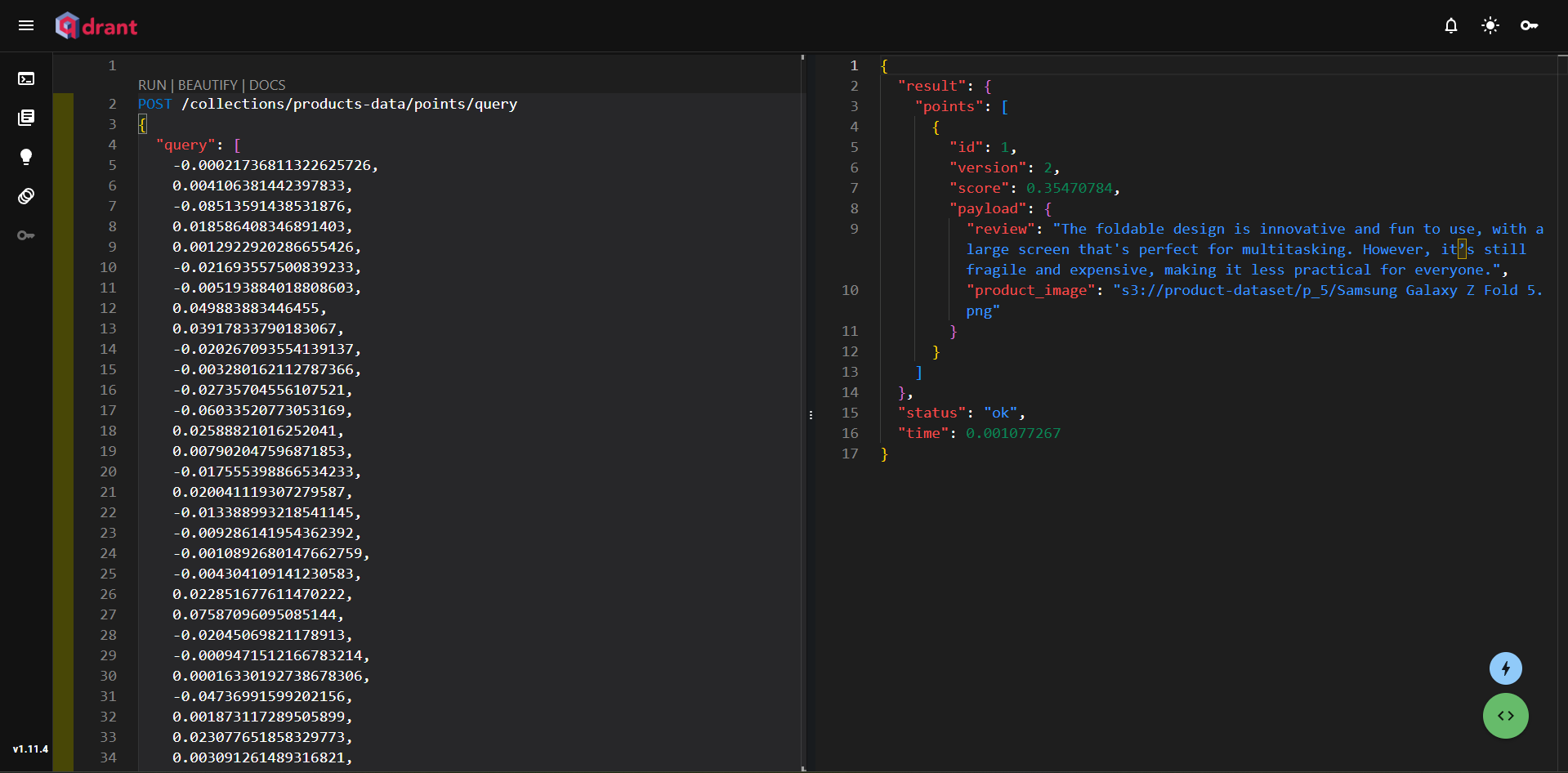
在此示例中,我们查询了设计改进的手机。然后,我们使用 OpenAI 将文本转换为向量,并检索了突出设计改进的相关手机评论。
结论
在本指南中,我们设置了一个 S3 存储桶,摄取了各种数据类型,并将嵌入存储在 Qdrant 中。使用 LangChain,我们动态处理文本和图像文件,使其易于处理每种文件类型。
现在轮到你了。尝试使用不同的数据类型(例如视频)进行实验,并探索 Qdrant 的高级功能以增强您的应用程序。要开始,请立即注册 Qdrant。
