Apache Spark
Spark是一个为大数据处理和分析设计的分布式计算框架。Qdrant-Spark 连接器使 Qdrant 成为 Spark 中的存储目的地。
安装
要将连接器集成到您的 Spark 环境中,请从下面列出的来源之一获取 JAR 文件。
- GitHub 发布
包含所有所需依赖项的打包jar文件可以在这里找到。
- 从源代码构建
要从源代码构建jar文件,您需要安装JDK@8和Maven。满足要求后,在项目根目录运行以下命令。
mvn package -DskipTests
JAR 文件将默认写入target目录。
- Maven Central
在 Maven Central 上这里找到该项目。
用法
创建支持 Qdrant 的 Spark 会话
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(
"spark.jars",
"path/to/file/spark-VERSION.jar", # Specify the path to the downloaded JAR file
)
.master("local[*]")
.appName("qdrant")
.getOrCreate()
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder
.config("spark.jars", "path/to/file/spark-VERSION.jar") // Specify the path to the downloaded JAR file
.master("local[*]")
.appName("qdrant")
.getOrCreate()
import org.apache.spark.sql.SparkSession;
public class QdrantSparkJavaExample {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.config("spark.jars", "path/to/file/spark-VERSION.jar") // Specify the path to the downloaded JAR file
.master("local[*]")
.appName("qdrant")
.getOrCreate();
}
}
加载数据
在使用此连接器加载数据之前,必须提前创建具有适当向量维度和配置的集合。
连接器支持摄取多个命名/未命名、密集/稀疏向量。
点击每个以展开。
未命名/默认向量
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", <QDRANT_GRPC_URL>)
.option("collection_name", <QDRANT_COLLECTION_NAME>)
.option("embedding_field", <EMBEDDING_FIELD_NAME>) # Expected to be a field of type ArrayType(FloatType)
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
命名向量
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", <QDRANT_GRPC_URL>)
.option("collection_name", <QDRANT_COLLECTION_NAME>)
.option("embedding_field", <EMBEDDING_FIELD_NAME>) # Expected to be a field of type ArrayType(FloatType)
.option("vector_name", <VECTOR_NAME>)
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
注意
embedding_field和vector_name选项是为了向后兼容而保留的。建议使用vector_fields和vector_names来表示命名向量,如下所示。
多个命名向量
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("vector_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("vector_names", "<VECTOR_NAME>,<ANOTHER_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
稀疏向量
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("sparse_vector_value_fields", "<COLUMN_NAME>")
.option("sparse_vector_index_fields", "<COLUMN_NAME>")
.option("sparse_vector_names", "<SPARSE_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
多个稀疏向量
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("sparse_vector_value_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_index_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_names", "<SPARSE_VECTOR_NAME>,<ANOTHER_SPARSE_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
命名密集向量和稀疏向量的组合
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("vector_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("vector_names", "<VECTOR_NAME>,<ANOTHER_VECTOR_NAME>")
.option("sparse_vector_value_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_index_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("sparse_vector_names", "<SPARSE_VECTOR_NAME>,<ANOTHER_SPARSE_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
多向量
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("multi_vector_fields", "<COLUMN_NAME>")
.option("multi_vector_names", "<MULTI_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
多个多向量
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("multi_vector_fields", "<COLUMN_NAME>,<ANOTHER_COLUMN_NAME>")
.option("multi_vector_names", "<MULTI_VECTOR_NAME>,<ANOTHER_MULTI_VECTOR_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
无向量 - 整个数据帧作为有效载荷存储
<pyspark.sql.DataFrame>
.write
.format("io.qdrant.spark.Qdrant")
.option("qdrant_url", "<QDRANT_GRPC_URL>")
.option("collection_name", "<QDRANT_COLLECTION_NAME>")
.option("schema", <pyspark.sql.DataFrame>.schema.json())
.mode("append")
.save()
Databricks
您可以将qdrant-spark连接器作为库在Databricks中使用。
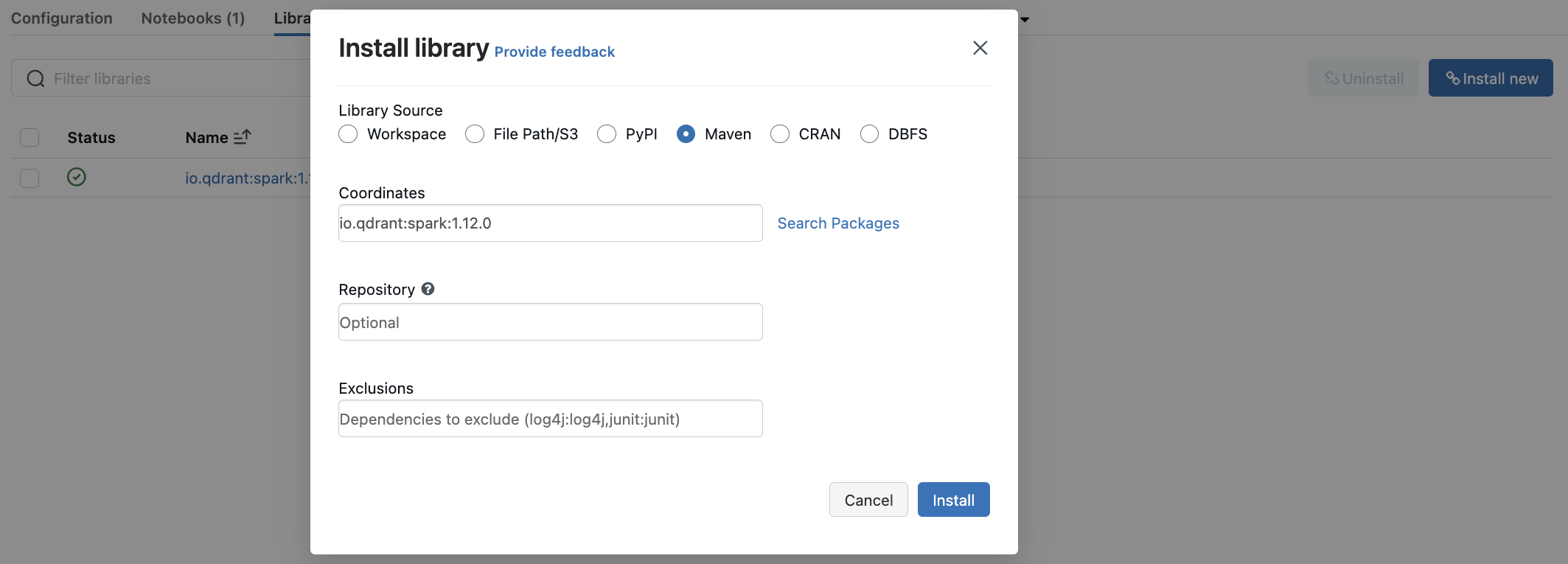
- 进入 Databricks 集群仪表板中的
Libraries部分。 - 选择
Install New以打开库安装模式。 - 在 Maven 包中搜索
io.qdrant:spark:VERSION并点击Install。
数据类型支持
根据提供的schema,适当的 Spark 数据类型被映射到 Qdrant 有效载荷。
选项和 Spark 类型
| 选项 | 描述 | 列数据类型 | 必填 |
|---|---|---|---|
qdrant_url | Qdrant 实例的 gRPC URL。例如:https://:6334 | - | ✅ |
collection_name | 写入数据的集合名称 | - | ✅ |
schema | 数据帧模式的 JSON 字符串 | - | ✅ |
embedding_field | 存储嵌入的列名(已弃用 - 请改用vector_fields) | ArrayType(FloatType) | ❌ |
id_field | 存储点 ID 的列名。默认值:随机 UUID | StringType或IntegerType | ❌ |
batch_size | 上传批次的最大大小。默认值:64 | - | ❌ |
retries | 上传重试次数。默认值:3 | - | ❌ |
api_key | 用于身份验证的 Qdrant API 密钥 | - | ❌ |
vector_name | 集合中向量的名称。 | - | ❌ |
vector_fields | 存储向量的列名,用逗号分隔。 | ArrayType(FloatType) | ❌ |
vector_names | 集合中向量的名称,用逗号分隔。 | - | ❌ |
sparse_vector_index_fields | 存储稀疏向量索引的列名,用逗号分隔。 | ArrayType(IntegerType) | ❌ |
sparse_vector_value_fields | 存储稀疏向量值的列名,用逗号分隔。 | ArrayType(FloatType) | ❌ |
sparse_vector_names | 集合中稀疏向量的名称,用逗号分隔。 | - | ❌ |
multi_vector_fields | 存储多向量值的列名,用逗号分隔。 | ArrayType(ArrayType(FloatType)) | ❌ |
multi_vector_names | 集合中多向量的名称,用逗号分隔。 | - | ❌ |
shard_key_selector | 在 upsert 期间使用的自定义分片键名称,用逗号分隔。 | - | ❌ |
wait | 等待每个批次 upsert 完成。true或false。默认为true。 | - | ❌ |
欲了解更多信息,请务必查看Qdrant-Spark GitHub 仓库。Apache Spark 指南可在此处获取。祝您数据处理愉快!