使用Qdrant和DSPy构建思维链医疗聊天机器人
从 LLM 获取医疗信息可能导致幻觉或过时信息。依赖此类信息可能导致严重的医疗后果。构建一个值得信赖且具备上下文感知能力的医疗聊天机器人可以解决这个问题。
在本文中,我们将探讨如何使用以下方法应对这些挑战:
- 检索增强生成 (RAG):聊天机器人不是从头开始回答问题,而是在回答问题之前从医学文献中检索信息。
- 筛选:用户可以按专业和出版年份筛选结果,确保信息准确且最新。
让我们来探索构建医疗机器人所需的技术。
技术栈概述
为了构建一个强大且值得信赖的医疗聊天机器人,我们将结合以下技术:
- Qdrant Cloud:Qdrant 是一款高性能的向量搜索引擎,用于存储和检索大量嵌入。在此项目中,我们将使用它来支持在数百万份医疗文档中进行快速准确的搜索,并支持密集和多向量 (ColBERT) 检索,以提供上下文感知答案。
- Stanford DSPy:DSPy 是我们将用于获取最终答案的 AI 框架。它允许医疗机器人检索相关信息并逐步推理,以生成准确且可解释的答案。

数据集准备和索引
医疗聊天机器人的好坏取决于其可访问的知识。对于本项目,我们将利用 MIRIAD 医疗数据集,这是一个包含大量医疗段落的大规模集合,并富含出版年份和专业等元数据。
使用密集和 ColBERT 多向量进行索引
为了实现高质量的检索,我们将使用两个模型嵌入每个医疗段落:
- 密集嵌入:这些使用
BAAI/bge-small-en模型生成,并捕捉段落的通用语义含义。 - ColBERT 多向量:这些提供更细粒度的表示,从而实现精确的结果排序。
dense_documents = [
models.Document(text=doc, model="BAAI/bge-small-en") for doc in ds["passage_text"]
]
colbert_documents = [
models.Document(text=doc, model="colbert-ir/colbertv2.0")
for doc in ds["passage_text"]
]
collection_name = "miriad"
# Create collection
if not client.collection_exists(collection_name):
client.create_collection(
collection_name=collection_name,
vectors_config={
"dense": models.VectorParams(size=384, distance=models.Distance.COSINE),
"colbert": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
hnsw_config=models.HnswConfigDiff(m=0), # reranker: no indexing
),
},
)
我们禁用了 ColBERT 多向量的索引,因为它将仅用于重新排序。要了解更多信息,请查看如何在 Qdrant 中有效使用多向量表示进行重新排序文章。
批量上传到 Qdrant
为避免触及 API 限制,我们分批上传数据,每批包含:
- 段落文本
- ColBERT 和密集嵌入。
year和specialty元数据字段。
BATCH_SIZE = 3
points_batch = []
for i in range(len(ds["passage_text"])):
point = models.PointStruct(
id=i,
vector={"dense": dense_documents[i], "colbert": colbert_documents[i]},
payload={
"passage_text": ds["passage_text"][i],
"year": ds["year"][i],
"specialty": ds["specialty"][i],
},
)
points_batch.append(point)
if len(points_batch) == BATCH_SIZE:
client.upsert(collection_name=collection_name, points=points_batch)
print(f"Uploaded batch ending at index {i}")
points_batch = []
# Final flush
if points_batch:
client.upsert(collection_name=collection_name, points=points_batch)
print("Uploaded final batch.")
检索增强生成 (RAG) 管道
我们的聊天机器人将使用检索增强生成 (RAG) 管道,以确保其答案基于医学文献。
DSPy 和 Qdrant 的集成
应用程序的核心是 Qdrant 向量数据库,它提供发送到 DSPy 的信息以生成最终答案。当用户提交查询时,会发生以下情况:
- DSPy 对 Qdrant 向量数据库进行搜索,以检索顶级文档并回答查询。结果还根据特定专业在特定年份范围内进行筛选。
- 然后使用 ColBERT 多向量嵌入对检索到的段落进行重新排序,从而获得最相关和上下文最合适的答案。
- DSPy 使用这些段落通过思维链推理来指导语言模型生成最准确的答案。
def rerank_with_colbert(query_text, min_year, max_year, specialty):
from fastembed import TextEmbedding, LateInteractionTextEmbedding
# Encode query once with both models
dense_model = TextEmbedding("BAAI/bge-small-en")
colbert_model = LateInteractionTextEmbedding("colbert-ir/colbertv2.0")
dense_query = list(dense_model.embed(query_text))[0]
colbert_query = list(colbert_model.embed(query_text))[0]
# Combined query: retrieve with dense,
# rerank with ColBERT
results = client.query_points(
collection_name=collection_name,
prefetch=models.Prefetch(query=dense_query, using="dense"),
query=colbert_query,
using="colbert",
limit=5,
with_payload=True,
query_filter=Filter(
must=[
FieldCondition(key="specialty", match=MatchValue(value=specialty)),
FieldCondition(
key="year",
range=models.Range(gt=None, gte=min_year, lt=None, lte=max_year),
),
]
),
)
points = results.points
docs = []
for point in points:
docs.append(point.payload["passage_text"])
return docs
该管道确保每个响应都基于真实和最新的医学文献,并符合用户的需求。
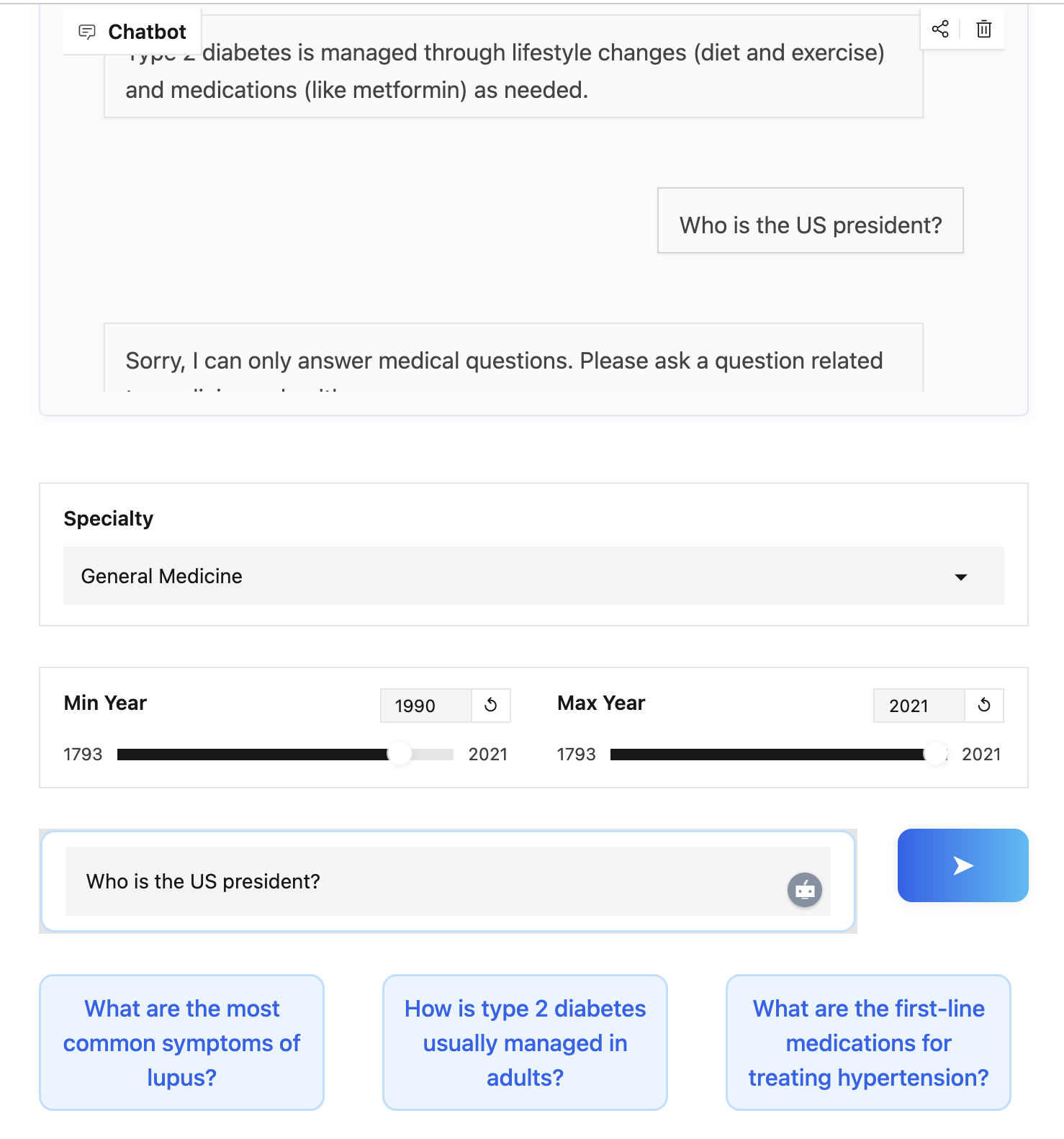
防护栏和医疗问题检测
由于这是一个医疗聊天机器人,我们可以引入一个简单的防护栏,以确保它不会回应与天气等无关的问题。这可以使用 DSPy 模块实现。
聊天机器人会在尝试回答每个问题之前检查它是否与医疗相关。这是通过一个 DSPy 模块实现的,该模块将每个传入的查询分类为医疗或非医疗。如果问题与医疗无关,聊天机器人将拒绝回答,从而降低错误信息或不当回复的风险。
class MedicalGuardrail(dspy.Module):
def forward(self, question):
prompt = (
"""
Is the following question a medical question?
Answer with 'Yes' or 'No'.n"
f"Question: {question}n"
"Answer:
"""
)
response = dspy.settings.lm(prompt)
answer = response[0].strip().lower()
return answer.startswith("yes")
if not self.guardrail.forward(question):
class DummyResult:
final_answer = """
Sorry, I can only answer medical questions.
Please ask a question related to medicine or healthcare
"""
return DummyResult()
通过将此防护栏与专业和年份筛选相结合,我们确保聊天机器人:
- 仅回答医疗问题。
- 回答来自最新医学文献的问题。
- 通过将其答案基于所提供的文献,不会编造答案。
结论
通过利用 Qdrant 和 DSPy,您可以构建一个生成准确且最新医疗回复的医疗聊天机器人。Qdrant 提供技术并实现快速可扩展的检索,而 DSPy 则综合这些信息以提供基于医学文献的正确答案。因此,您可以实现一个真实、安全且提供相关回复的医疗系统。请查看此笔记本中的整个项目。您需要一个免费的 Qdrant Cloud 帐户才能运行该笔记本。