为 Cohere RAG 实现自定义连接器
| 时间:45分钟 | 难度:中等 |
|---|
实现检索增强生成(Retrieval Augmented Generation)的通常方法要求用户使用法学硕士可能依赖的相关上下文构建提示,并手动将其发送给模型。Cohere 在这方面非常独特,因为他们的模型现在可以与外部工具对话并自行提取有意义的数据。您几乎可以连接任何数据源,并让 Cohere 法学硕士知道如何访问它。显然,向量搜索与法学硕士配合得很好,并且在您的数据上实现语义搜索是一个典型的案例。
Cohere RAG 具有许多有趣的功能,例如行内引用,它们帮助您引用用于生成响应的文档的特定部分。
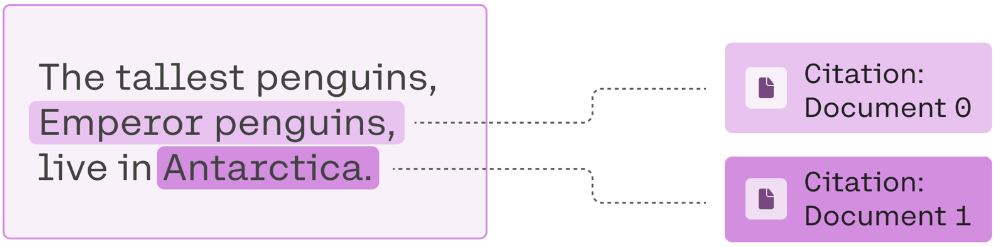
来源: https://docs.cohere.com/docs/retrieval-augmented-generation-rag
连接器必须实现特定的接口,并将数据源公开为 HTTP REST API。Cohere 文档描述了创建连接器的一般过程。本教程将指导您逐步围绕 Qdrant 构建此类服务。
Qdrant 连接器
您可能已经有一些想要引入法学硕士的集合。也许您的管道是使用一些流行的库(如 Langchain、Llama Index 或 Haystack)设置的。Cohere 连接器甚至可以实现更复杂的逻辑,例如混合搜索。在我们的案例中,我们将从一个新的 Qdrant 集合开始,使用 Cohere Embed v3 索引数据,构建连接器,最后将其与Command-R 模型连接。
构建集合
首先,让我们构建一个集合并将其配置为 Cohere embed-multilingual-v3.0 模型。它生成 1024 维嵌入,我们可以选择 Qdrant 中可用的任何距离度量。我们的连接器将充当软件工程师的私人助理,它将公开我们的笔记以建议优先级或要执行的操作。
from qdrant_client import QdrantClient, models
client = QdrantClient(
"https://my-cluster.cloud.qdrant.io:6333",
api_key="my-api-key",
)
client.create_collection(
collection_name="personal-notes",
vectors_config=models.VectorParams(
size=1024,
distance=models.Distance.DOT,
),
)
我们的笔记将表示为简单的 JSON 对象,其中包含特定笔记的title和text。嵌入将仅从text字段创建。
notes = [
{
"title": "Project Alpha Review",
"text": "Review the current progress of Project Alpha, focusing on the integration of the new API. Check for any compatibility issues with the existing system and document the steps needed to resolve them. Schedule a meeting with the development team to discuss the timeline and any potential roadblocks."
},
{
"title": "Learning Path Update",
"text": "Update the learning path document with the latest courses on React and Node.js from Pluralsight. Schedule at least 2 hours weekly to dedicate to these courses. Aim to complete the React course by the end of the month and the Node.js course by mid-next month."
},
{
"title": "Weekly Team Meeting Agenda",
"text": "Prepare the agenda for the weekly team meeting. Include the following topics: project updates, review of the sprint backlog, discussion on the new feature requests, and a brainstorming session for improving remote work practices. Send out the agenda and the Zoom link by Thursday afternoon."
},
{
"title": "Code Review Process Improvement",
"text": "Analyze the current code review process to identify inefficiencies. Consider adopting a new tool that integrates with our version control system. Explore options such as GitHub Actions for automating parts of the process. Draft a proposal with recommendations and share it with the team for feedback."
},
{
"title": "Cloud Migration Strategy",
"text": "Draft a plan for migrating our current on-premise infrastructure to the cloud. The plan should cover the selection of a cloud provider, cost analysis, and a phased migration approach. Identify critical applications for the first phase and any potential risks or challenges. Schedule a meeting with the IT department to discuss the plan."
},
{
"title": "Quarterly Goals Review",
"text": "Review the progress towards the quarterly goals. Update the documentation to reflect any completed objectives and outline steps for any remaining goals. Schedule individual meetings with team members to discuss their contributions and any support they might need to achieve their targets."
},
{
"title": "Personal Development Plan",
"text": "Reflect on the past quarter's achievements and areas for improvement. Update the personal development plan to include new technical skills to learn, certifications to pursue, and networking events to attend. Set realistic timelines and check-in points to monitor progress."
},
{
"title": "End-of-Year Performance Reviews",
"text": "Start preparing for the end-of-year performance reviews. Collect feedback from peers and managers, review project contributions, and document achievements. Consider areas for improvement and set goals for the next year. Schedule preliminary discussions with each team member to gather their self-assessments."
},
{
"title": "Technology Stack Evaluation",
"text": "Conduct an evaluation of our current technology stack to identify any outdated technologies or tools that could be replaced for better performance and productivity. Research emerging technologies that might benefit our projects. Prepare a report with findings and recommendations to present to the management team."
},
{
"title": "Team Building Event Planning",
"text": "Plan a team-building event for the next quarter. Consider activities that can be done remotely, such as virtual escape rooms or online game nights. Survey the team for their preferences and availability. Draft a budget proposal for the event and submit it for approval."
}
]
存储嵌入和元数据相当简单。
import cohere
import uuid
cohere_client = cohere.Client(api_key="my-cohere-api-key")
response = cohere_client.embed(
texts=[
note.get("text")
for note in notes
],
model="embed-multilingual-v3.0",
input_type="search_document",
)
client.upload_points(
collection_name="personal-notes",
points=[
models.PointStruct(
id=uuid.uuid4().hex,
vector=embedding,
payload=note,
)
for note, embedding in zip(notes, response.embeddings)
]
)
我们的集合现在已准备好进行搜索。在现实世界中,笔记集会随时间变化,因此摄取过程不会那么直接。这些数据尚未公开给法学硕士,但我们将在下一步构建连接器。
连接器网络服务
FastAPI 是一个现代 Web 框架,是简单 HTTP API 的完美选择。我们将把它用于连接器。只有一个端点,这是模型要求的。它将接受/search路径上的 POST 请求。需要一个query参数。让我们定义一个相应的模型。
from pydantic import BaseModel
class SearchQuery(BaseModel):
query: str
RAG 连接器无需以任何特定格式返回文档。有一些值得遵循的最佳实践,但 Cohere 模型在这方面非常灵活。结果只需作为 JSON 返回,输出的results属性中包含一个对象列表。我们将使用与 Qdrant 有效负载相同的文档结构,因此无需转换。这需要创建另外两个模型。
from typing import List
class Document(BaseModel):
title: str
text: str
class SearchResults(BaseModel):
results: List[Document]
一旦我们的模型类准备就绪,我们就可以实现逻辑,获取查询并提供与其相关的笔记。请注意,法学硕士不会定义要返回的文档数量。您要将多少文档引入上下文完全取决于您。
我们需要与两个服务交互——Qdrant 服务器和 Cohere API。FastAPI 有一个依赖注入的概念,我们将使用它来提供两个客户端的实现。
在查询的情况下,我们需要在调用 Cohere API 时将input_type设置为search_query。
from fastapi import FastAPI, Depends
from typing import Annotated
app = FastAPI()
def client() -> QdrantClient:
return QdrantClient(config.QDRANT_URL, api_key=config.QDRANT_API_KEY)
def cohere_client() -> cohere.Client:
return cohere.Client(api_key=config.COHERE_API_KEY)
@app.post("/search")
def search(
query: SearchQuery,
client: Annotated[QdrantClient, Depends(client)],
cohere_client: Annotated[cohere.Client, Depends(cohere_client)],
) -> SearchResults:
response = cohere_client.embed(
texts=[query.query],
model="embed-multilingual-v3.0",
input_type="search_query",
)
results = client.query_points(
collection_name="personal-notes",
query=response.embeddings[0],
limit=2,
).points
return SearchResults(
results=[
Document(**point.payload)
for point in results
]
)
如果安装了uvicorn服务器,我们的应用程序可以在本地启动用于开发目的。
uvicorn main:app
FastAPI 在https://:8000/docs上公开了一个交互式文档,我们可以在其中测试我们的端点。/search端点在那里可用。
我们可以与它交互并检查将针对特定查询返回的文档。例如,我们想回忆一下我们应该如何处理项目的基础设施。
curl -X "POST" \
-H "Content-type: application/json" \
-d '{"query": "Is there anything I have to do regarding the project infrastructure?"}' \
"https://:8000/search"
输出应如下所示
{
"results": [
{
"title": "Cloud Migration Strategy",
"text": "Draft a plan for migrating our current on-premise infrastructure to the cloud. The plan should cover the selection of a cloud provider, cost analysis, and a phased migration approach. Identify critical applications for the first phase and any potential risks or challenges. Schedule a meeting with the IT department to discuss the plan."
},
{
"title": "Project Alpha Review",
"text": "Review the current progress of Project Alpha, focusing on the integration of the new API. Check for any compatibility issues with the existing system and document the steps needed to resolve them. Schedule a meeting with the development team to discuss the timeline and any potential roadblocks."
}
]
}
连接到 Command-R
我们的网络服务已实现,但仅在我们本地机器上运行。在 Command-R 可以与它交互之前,它必须公开给公众。对于快速实验,使用ngrok等服务设置隧道可能就足够了。我们不会在本教程中涵盖所有细节,但他们的快速入门是一篇很好的资源,逐步描述了该过程。另外,您也可以部署带有公共 URL 的服务。
一旦完成,我们可以先创建连接器,然后告诉模型使用它,同时通过聊天 API 进行交互。创建连接器是对 Cohere 客户端的一次调用
connector_response = cohere_client.connectors.create(
name="personal-notes",
url="https:/this-is-my-domain.app/search",
)
connector_response.connector将是一个描述符,其中id是其中一个属性。我们将像这样使用此标识符进行交互
response = cohere_client.chat(
message=(
"Is there anything I have to do regarding the project infrastructure? "
"Please mention the tasks briefly."
),
connectors=[
cohere.ChatConnector(id=connector_response.connector.id)
],
model="command-r",
)
我们将model更改为command-r,因为这是目前公众可用的最佳 Cohere 模型。response.text是模型的输出
Here are some of the tasks related to project infrastructure that you might have to perform:
- You need to draft a plan for migrating your on-premise infrastructure to the cloud and come up with a plan for the selection of a cloud provider, cost analysis, and a gradual migration approach.
- It's important to evaluate your current technology stack to identify any outdated technologies. You should also research emerging technologies and the benefits they could bring to your projects.
您只需创建一次特定的连接器!请不要为您发送给chat方法的每条消息都调用cohere_client.connectors.create。
总结
我们构建了一个 Cohere RAG 连接器,它与您存储在 Qdrant 中的现有知识库集成。我们只介绍了基本流程,但在实际场景中,您还应该考虑例如构建身份验证系统以防止未经授权的访问。