使用 Neo4j 和 Qdrant 构建 GraphRAG 代理

| 时间:30分钟 | 难度:中等 | 输出:GitHub |
|---|
为了使人工智能 (AI) 系统更智能、更可靠,我们面临一个悖论:大型语言模型 (LLM) 具有卓越的推理能力,但它们难以以人类直观的方式连接信息。尽管开创性,但检索增强生成 (RAG) 方法在处理复杂信息综合时往往力不从心。当被要求连接不相关的信息或理解大型文档中的整体概念时,这些系统经常会错过人类专家显而易见的 K 键连接。
为了解决这些问题,微软推出了 GraphRAG,它使用知识图谱 (KG) 而不是向量作为 LLM 的上下文。GraphRAG 主要依赖 LLM 来创建和查询 KG。然而,这种对 LLM 的依赖可能会导致许多问题。我们将通过结合向量数据库和图数据库来解决这些挑战。
本教程将演示如何使用 Neo4j 和 Qdrant 构建一个带向量搜索的 GraphRAG 系统。
| 附加材料 |
|---|
| 本高级教程基于我们最初的集成文档:Neo4j - Qdrant 集成 |
| 本教程的输出在我们的 GitHub 示例仓库中:Python 中的 Neo4j - Qdrant 代理 |
观看视频
RAG 及其挑战
RAG 结合了基于检索和生成式 AI,通过来自知识库(如向量数据库)的相关、最新信息来增强 LLM。然而,RAG 面临一些挑战
- 理解上下文: 模型可能会误解查询,尤其是在上下文复杂或模糊时,从而导致不正确或不相关的答案。
- 平衡相似性与相关性: RAG 系统难以确保检索到的信息既相似又与上下文相关。
- 答案完整性: 传统 RAG 可能无法捕获复杂查询的所有相关细节,这些查询需要 LLM 找到上下文中未明确存在的关。
GraphRAG 简介
与通常依赖文档检索的 RAG 不同,GraphRAG 构建知识图谱 (KG) 以捕获实体及其关系。对于需要 AI 系统具备人类智能水平的数据集或用例,GraphRAG 提供了一个有前景的解决方案
- 它可以遵循关系链来回答复杂查询,使其适用于超越简单文档检索的更好推理。
- 图结构允许对上下文有更深入的理解,从而产生更准确和相关的响应。
GraphRAG 的工作流程如下
- LLM 分析数据集以识别实体(人物、地点、组织)及其关系,创建一个全面的知识图谱,其中实体是节点,它们的连接形成边。
- 自下而上的聚类算法将 KG 组织成层次语义组。这创建了相关信息的有意义片段,从而能够理解不同抽象级别的信息。
- GraphRAG 在回答查询时使用 KG 和语义聚类来选择 LLM 的相关上下文。
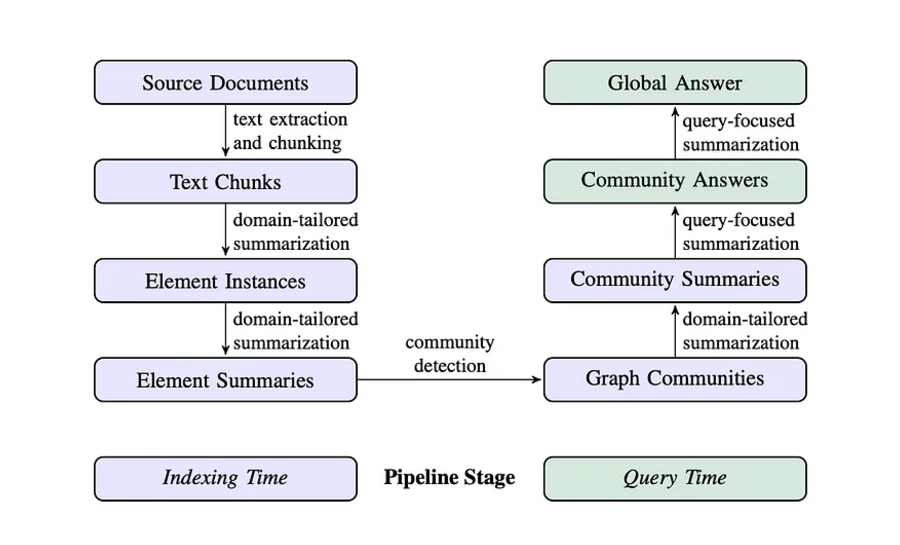
图 1:GraphRAG 摄取和检索的完整图景
GraphRAG 的挑战
尽管 GraphRAG 具有优势,但以 LLM 为中心的 GraphRAG 方法面临一些挑战
- 使用 LLM 构建 KG: 由于 LLM 负责构建知识图谱,因此存在不一致性、偏差或错误传播以及对所用本体缺乏控制等风险。但是,我们在实现中使用了 LLM 来提取本体。
- 使用 LLM 查询 KG: 图谱构建完成后,LLM 会将人类查询转换为 Cypher(Neo4j 的声明式查询语言)。然而,用 Cypher 编写复杂查询可能会导致不准确的结果。
- 可伸缩性和成本考虑: 为了实用,应用程序必须同时具有可伸缩性和成本效益。依赖 LLM 会增加成本并降低可伸缩性,因为每次添加、查询或生成数据时都会使用它们。
为了解决这些挑战,GraphRAG 可能需要一个更受控和结构化的知识表示系统才能大规模地最佳运行。
架构概述
该架构有两个主要组件:摄取和检索与生成。摄取将原始数据处理成结构化知识和向量表示,而检索和生成则实现高效的查询和响应生成。
此过程分为两个步骤:摄取,其中准备和存储数据,以及检索和生成,其中查询和利用准备好的数据。让我们从摄取开始。
摄取
GraphRAG 摄取管道结合了图数据库和向量数据库以改进 RAG 工作流。
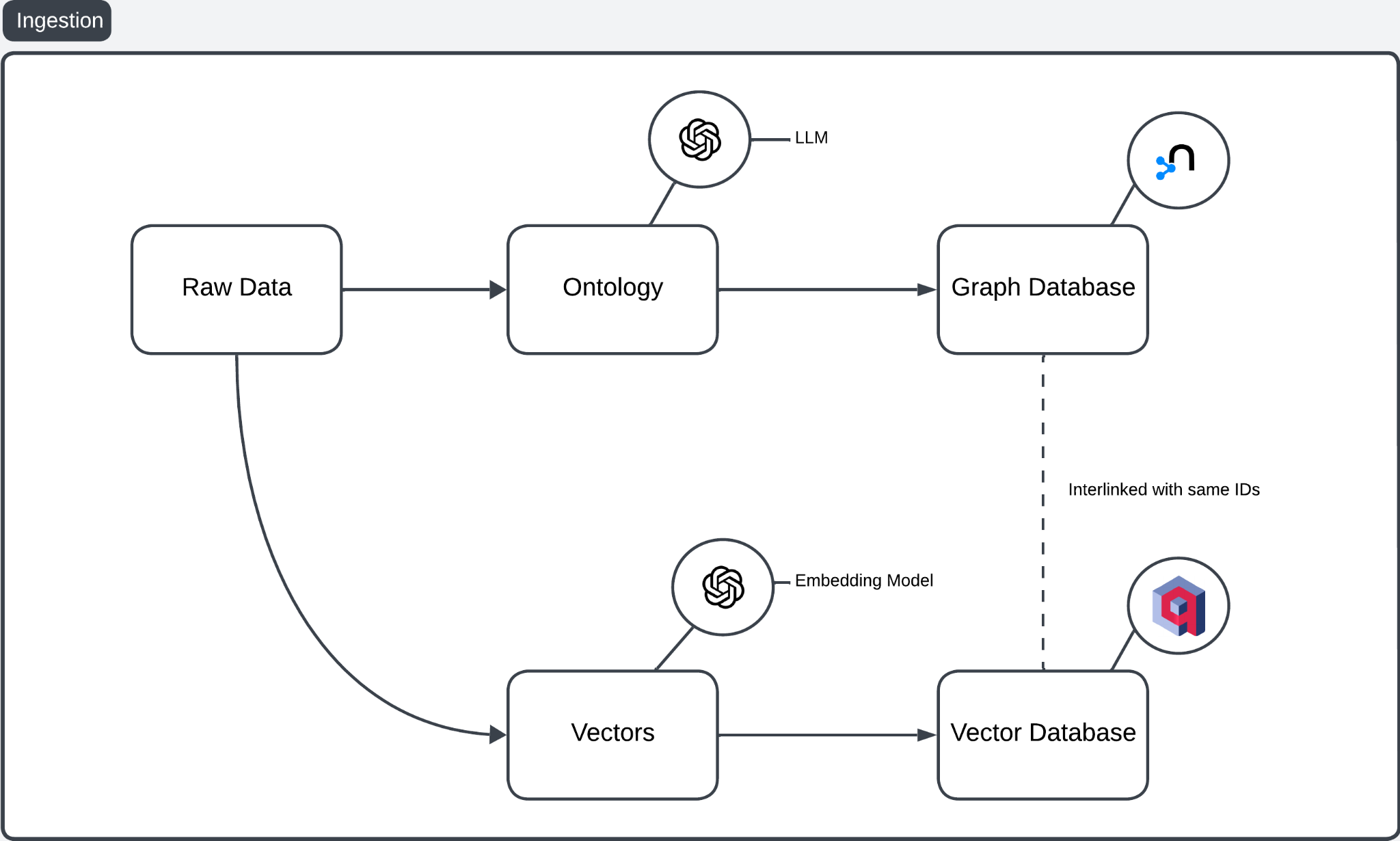
图 2:摄取管道概述
让我们来分解一下
- 原始数据: 作为基础,包含非结构化或结构化内容。
- 本体创建: LLM 将原始数据处理成本体,结构化实体、关系和层次结构。存在更好的方法从原始数据中提取更结构化的信息,例如使用 NER 识别人物、组织和地点的名称。与 LLM 不同,这种方法创建。
- 图数据库: 本体存储在图数据库中以捕获复杂关系。
- 向量嵌入: 嵌入模型将原始数据转换为捕获语义相似性的高维向量。
- 向量数据库: 这些嵌入存储在向量数据库中以进行基于相似性的检索。
- 数据库互连: 图数据库(例如 Neo4j)和向量数据库(例如 Qdrant)共享唯一的 ID,从而实现本体驱动结果和向量驱动结果之间的交叉引用。
检索与生成
检索和生成过程旨在通过利用语义搜索和基于图的上下文提取来处理用户查询。
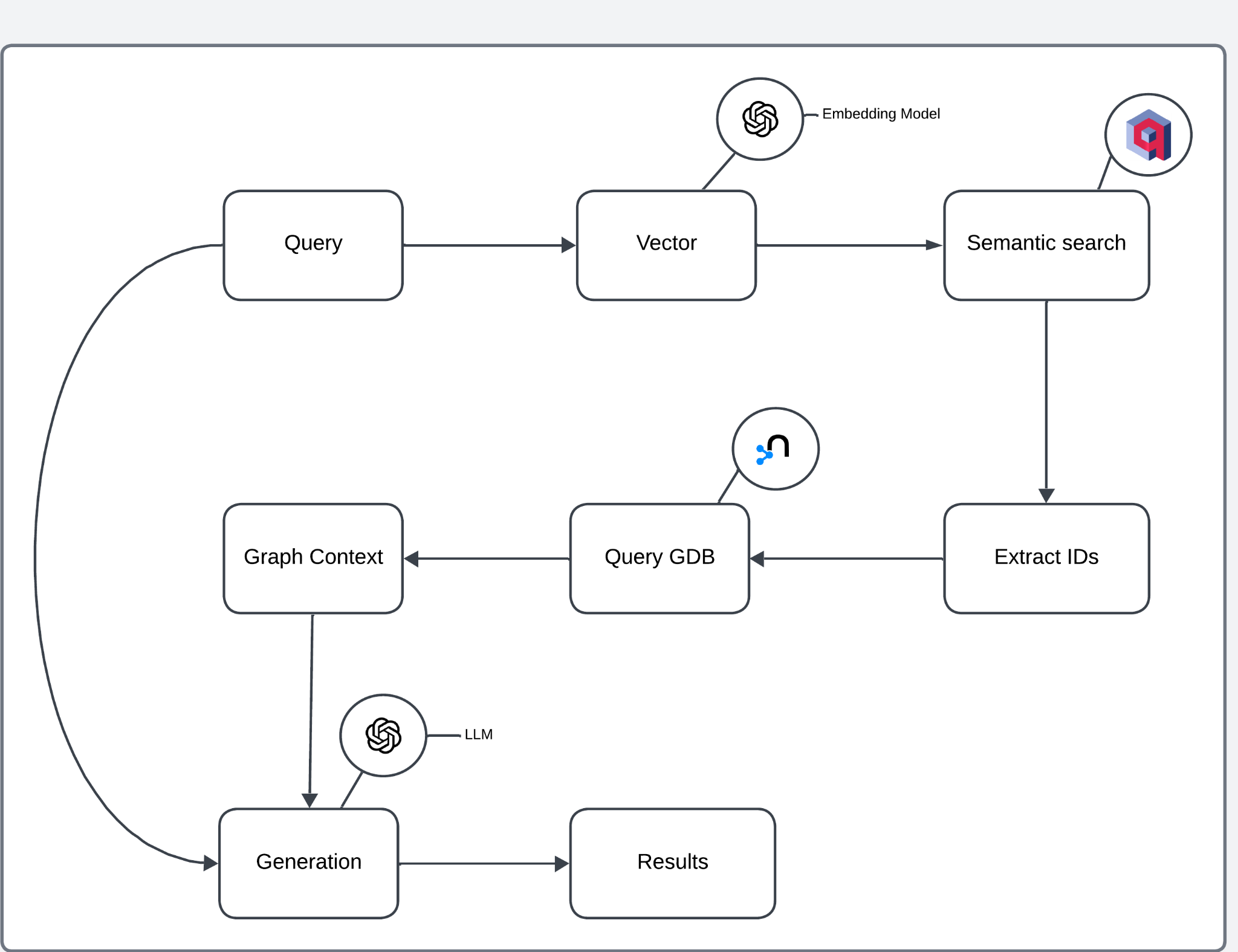
图 3:检索和生成管道概述
该架构可以分解为以下步骤
- 查询向量化: 嵌入模型将用户查询转换为高维向量。
- 语义搜索: 向量在向量数据库中执行基于相似性的搜索,检索相关文档或条目。
- ID 提取: 从语义搜索结果中提取的 ID 用于查询图数据库。
- 图上下文检索: 图数据库提供上下文信息,包括与提取的 ID 链接的关系和实体。
- 响应生成: 从图中检索到的上下文传递给 LLM 以生成最终响应。
- 结果: 生成的响应返回给用户。
该架构结合了两个数据库的优势
- 使用向量数据库进行语义搜索: 用户查询首先进行语义处理,以识别最相关的数据点,而无需显式关键字匹配。
- 使用图数据库进行上下文扩展: 从向量数据库查询中检索到的 ID 或实体查询图数据库以获取详细关系,从而用结构化上下文丰富检索到的数据。
- 增强生成: 该架构结合了语义相关性(来自向量数据库)和基于图的上下文,使 LLM 能够生成更具信息量、更准确和上下文更丰富的响应。
实施
我们将逐步介绍一个完整的管道,该管道将数据摄取到 Neo4j 和 Qdrant 中,检索相关数据,并使用基于检索到的图上下文的 LLM 生成响应。
此管道的主要组件包括数据摄取(到 Neo4j 和 Qdrant)、检索和生成步骤。
先决条件
这些是教程的先决条件,分为设置、导入和两个数据库的初始化。
设置
让我们从 Qdrant 和 Neo4j 的实例设置开始。
Qdrant 设置
要创建 Qdrant 实例,您可以使用它们的托管服务 (Qdrant Cloud) 或设置自托管集群。为简单起见,我们将使用 Qdrant 云
- 前往Qdrant Cloud并注册或登录。
- 登录后,点击创建新集群。
- 按照屏幕上的说明创建您的集群。
- 集群创建成功后,您将获得一个集群 URL 和 API 密钥,您将在客户端中使用它们与 Qdrant 进行交互。
Neo4j 设置
要设置 Neo4j 实例,您可以使用 Neo4j Aura(云服务)或自行托管。我们将使用 Neo4j Aura
- 前往 Neo4j Aura 并注册/登录。
- 设置完成后,如果是第一次,将创建一个实例。
- 数据库设置完成后,您将收到连接 URI、用户名和密码。
出于安全考虑,我们可以在 .env 文件中添加以下内容。
导入
首先,我们导入使用 Neo4j、Qdrant、OpenAI 和其他实用函数所需的库。
from neo4j import GraphDatabase
from qdrant_client import QdrantClient, models
from dotenv import load_dotenv
from pydantic import BaseModel
from openai import OpenAI
from collections import defaultdict
from neo4j_graphrag.retrievers import QdrantNeo4jRetriever
import uuid
import os
- Neo4j: 用于存储和查询图数据库。
- Qdrant: 用于语义相似性搜索的向量数据库。
- dotenv: 加载凭据和 API 密钥的环境变量。
- Pydantic: 确保在与图数据交互时数据结构正确。
- OpenAI: 与 OpenAI API 接口以生成响应和嵌入。
- neo4j_graphrag: 一个帮助包,用于从 Qdrant 和 Neo4j 中检索数据。
设置环境变量
在初始化客户端之前,我们从环境变量加载必要的凭据。
# Load environment variables
load_dotenv()
# Get credentials from environment variables
qdrant_key = os.getenv("QDRANT_KEY")
qdrant_url = os.getenv("QDRANT_URL")
neo4j_uri = os.getenv("NEO4J_URI")
neo4j_username = os.getenv("NEO4J_USERNAME")
neo4j_password = os.getenv("NEO4J_PASSWORD")
openai_key = os.getenv("OPENAI_API_KEY")
这确保敏感信息(如 API 密钥和数据库凭据)安全地存储在环境变量中。
初始化 Neo4j 和 Qdrant 客户端
现在,我们使用凭据初始化 Neo4j 和 Qdrant 客户端。
# Initialize Neo4j driver
neo4j_driver = GraphDatabase.driver(neo4j_uri, auth=(neo4j_username, neo4j_password))
# Initialize Qdrant client
qdrant_client = QdrantClient(
url=qdrant_url,
api_key=qdrant_key
)
- Neo4j: 我们设置了与 Neo4j 图数据库的连接。
- Qdrant: 我们初始化了与 Qdrant 向量存储的连接。
这将连接 Neo4j 和 Qdrant,我们现在可以开始摄取。
摄取
我们将遵循架构部分中介绍的摄取管道的工作流程。让我们从实现的角度来检查它。
定义输出解析器
单个和 GraphComponents 类将 LLM 的响应结构化为可用格式。
class single(BaseModel):
node: str
target_node: str
relationship: str
class GraphComponents(BaseModel):
graph: list[single]
这些类有助于确保 OpenAI LLM 的数据正确解析为图组件(节点和关系)。
定义 OpenAI 客户端和 LLM 解析器函数
我们现在初始化 OpenAI 客户端并定义一个函数,用于向 LLM 发送提示并解析其响应。
client = OpenAI()
def openai_llm_parser(prompt):
completion = client.chat.completions.create(
model="gpt-4o-2024-08-06",
response_format={"type": "json_object"},
messages=[
{
"role": "system",
"content":
""" You are a precise graph relationship extractor. Extract all
relationships from the text and format them as a JSON object
with this exact structure:
{
"graph": [
{"node": "Person/Entity",
"target_node": "Related Entity",
"relationship": "Type of Relationship"},
...more relationships...
]
}
Include ALL relationships mentioned in the text, including
implicit ones. Be thorough and precise. """
},
{
"role": "user",
"content": prompt
}
]
)
return GraphComponents.model_validate_json(completion.choices[0].message.content)
此函数向 LLM 发送一个提示,要求它从提供的文本中提取图组件(节点和关系)。响应被解析为结构化图数据。
提取图组件
函数 extract_graph_components 处理原始数据,提取节点和关系作为图组件。
def extract_graph_components(raw_data):
prompt = f"Extract nodes and relationships from the following text:\n{raw_data}"
parsed_response = openai_llm_parser(prompt) # Assuming this returns a list of dictionaries
parsed_response = parsed_response.graph # Assuming the 'graph' structure is a key in the parsed response
nodes = {}
relationships = []
for entry in parsed_response:
node = entry.node
target_node = entry.target_node # Get target node if available
relationship = entry.relationship # Get relationship if available
# Add nodes to the dictionary with a unique ID
if node not in nodes:
nodes[node] = str(uuid.uuid4())
if target_node and target_node not in nodes:
nodes[target_node] = str(uuid.uuid4())
# Add relationship to the relationships list with node IDs
if target_node and relationship:
relationships.append({
"source": nodes[node],
"target": nodes[target_node],
"type": relationship
})
return nodes, relationships
此函数获取原始数据,使用 LLM 将其解析为图组件,然后为节点和关系分配唯一的 ID。
将数据摄取到 Neo4j
函数 ingest_to_neo4j 将提取的图数据(节点和关系)摄取到 Neo4j 中。
def ingest_to_neo4j(nodes, relationships):
"""
Ingest nodes and relationships into Neo4j.
"""
with neo4j_driver.session() as session:
# Create nodes in Neo4j
for name, node_id in nodes.items():
session.run(
"CREATE (n:Entity {id: $id, name: $name})",
id=node_id,
name=name
)
# Create relationships in Neo4j
for relationship in relationships:
session.run(
"MATCH (a:Entity {id: $source_id}), (b:Entity {id: $target_id}) "
"CREATE (a)-[:RELATIONSHIP {type: $type}]->(b)",
source_id=relationship["source"],
target_id=relationship["target"],
type=relationship["type"]
)
return nodes
在这里,我们在 Neo4j 图数据库中创建节点和关系。节点是实体,关系连接这些实体。
这将数据摄取到 Neo4j 中,在示例数据集上它看起来像这样
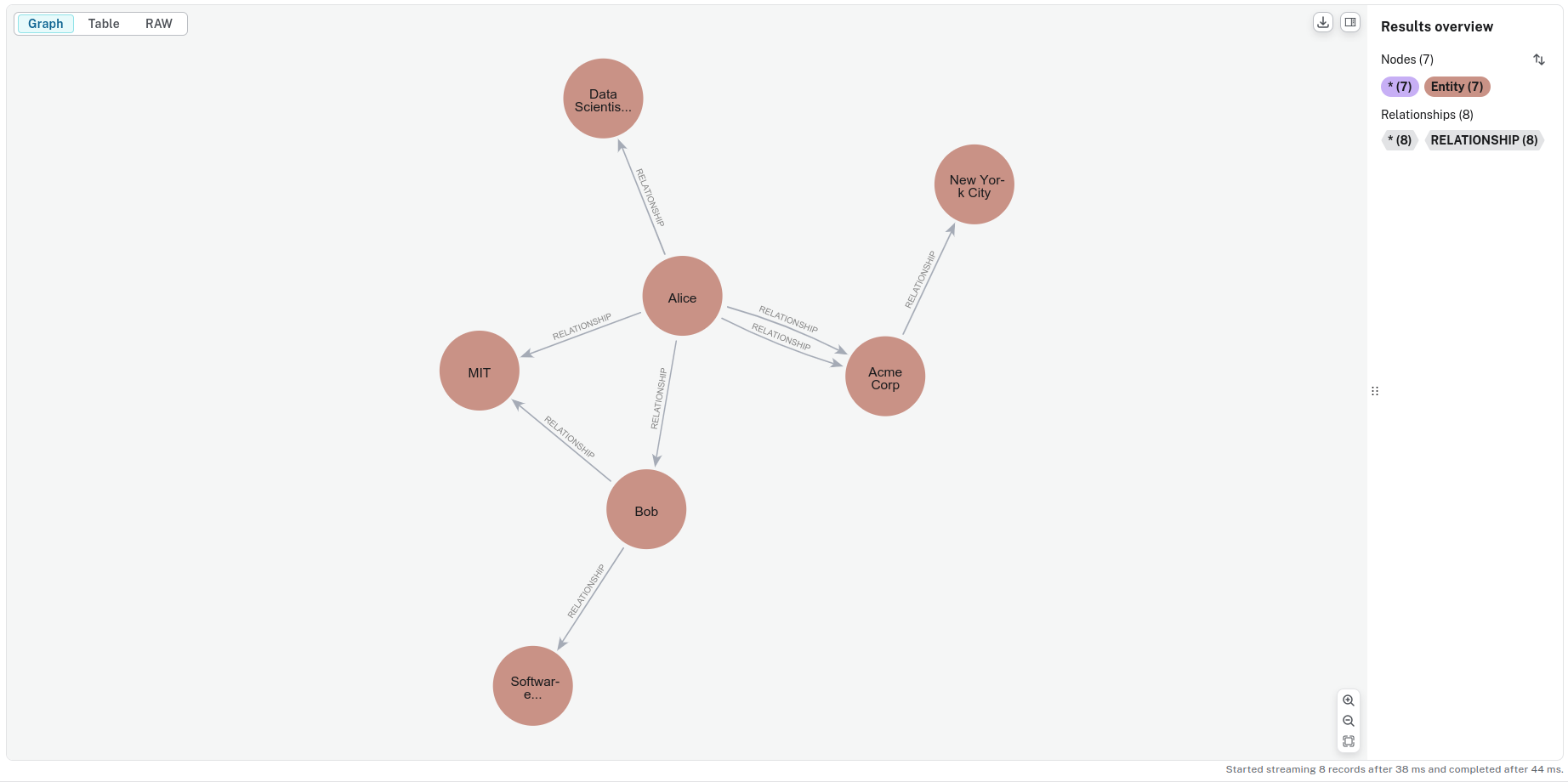
图 4:知识图谱的可视化
让我们探索如何将节点与其 ID 映射,并将此信息连同向量一起集成到 Qdrant 中。首先,让我们创建一个 Qdrant 集合。
创建 Qdrant 集合
一旦您设置了 Qdrant 实例,您就可以创建一个集合。Qdrant 中的集合保存向量以供搜索和检索。
def create_collection(client, collection_name, vector_dimension):
尝试
# Try to fetch the collection status
try:
collection_info = client.get_collection(collection_name)
print(f"Skipping creating collection; '{collection_name}' already exists.")
except Exception as e:
# If collection does not exist, an error will be thrown, so we create the collection
if 'Not found: Collection' in str(e):
print(f"Collection '{collection_name}' not found. Creating it now...")
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(size=vector_dimension, distance=models.Distance.COSINE)
)
print(f"Collection '{collection_name}' created successfully.")
else:
print(f"Error while checking collection: {e}")
- Qdrant 客户端: QdrantClient 用于连接到 Qdrant 实例。
- 创建集合: create_collection 函数检查集合是否存在。如果不存在,它会创建一个具有指定向量维度和距离度量(在这种情况下为余弦相似度)的集合。
生成嵌入
接下来,我们定义一个函数,用于使用 OpenAI API 为文本生成嵌入。
def openai_embeddings(text):
response = client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return response.data[0].embedding
此函数使用 OpenAI 的嵌入模型将输入文本转换为向量表示。
摄取到 Qdrant
让我们将数据摄取到向量数据库中。
def ingest_to_qdrant(collection_name, raw_data, node_id_mapping):
embeddings = [openai_embeddings(paragraph) for paragraph in raw_data.split("\n")]
qdrant_client.upsert(
collection_name=collection_name,
points=[
{
"id": str(uuid.uuid4()),
"vector": embedding,
"payload": {"id": node_id}
}
for node_id, embedding in zip(node_id_mapping.values(), embeddings)
]
)
ingest_to_qdrant 函数为原始数据中的每个段落生成嵌入,并将其存储在 Qdrant 集合中。它将每个嵌入与一个唯一的 ID 及其来自 node_id_mapping 字典的相应节点 ID 相关联,确保正确链接以便以后检索。
检索与生成
在本节中,我们将为系统创建检索和生成引擎。
构建检索器
检索器集成了向量搜索和图数据,能够通过 Qdrant 进行语义相似性搜索,并从 Neo4j 获取相关图数据。这丰富了 RAG 过程并允许更明智的响应。
def retriever_search(neo4j_driver, qdrant_client, collection_name, query):
retriever = QdrantNeo4jRetriever(
driver=neo4j_driver,
client=qdrant_client,
collection_name=collection_name,
id_property_external="id",
id_property_neo4j="id",
)
results = retriever.search(query_vector=openai_embeddings(query), top_k=5)
return results
QdrantNeo4jRetriever 处理向量搜索和图数据获取,将 Qdrant 用于基于向量的检索,将 Neo4j 用于基于图的查询。
向量搜索
qdrant_client连接到 Qdrant 以进行高效的向量相似性搜索。collection_name指定向量的存储位置。id_property_external="id"映射用于检索的外部实体 ID。
图获取
neo4j_driver连接到 Neo4j 以查询图数据。id_property_neo4j="id"确保 Qdrant 中的实体 ID 与 Neo4j 中的图节点匹配。
查询 Neo4j 以获取相关图数据
在检索器提供了相关 ID 后,我们需要根据特定的实体 ID 从 Neo4j 数据库中获取子图数据。
def fetch_related_graph(neo4j_client, entity_ids):
query = """
MATCH (e:Entity)-[r1]-(n1)-[r2]-(n2)
WHERE e.id IN $entity_ids
RETURN e, r1 as r, n1 as related, r2, n2
UNION
MATCH (e:Entity)-[r]-(related)
WHERE e.id IN $entity_ids
RETURN e, r, related, null as r2, null as n2
"""
with neo4j_client.session() as session:
result = session.run(query, entity_ids=entity_ids)
subgraph = []
for record in result:
subgraph.append({
"entity": record["e"],
"relationship": record["r"],
"related_node": record["related"]
})
if record["r2"] and record["n2"]:
subgraph.append({
"entity": record["related"],
"relationship": record["r2"],
"related_node": record["n2"]
})
return subgraph
函数 fetch_related_graph 接受一个 Neo4j 客户端和一个 entity_ids 列表。它运行一个 Cypher 查询,根据给定的实体 ID 查找相关节点(实体)及其关系。该查询匹配实体 (e:Entity) 并通过任何关系 [r] 查找相关节点。该函数返回一个子图数据列表,其中每个记录包含实体、关系和 related_node。
此子图对于生成上下文以回答用户查询至关重要。
设置图上下文
实现的第二部分涉及准备图上下文。我们将从 Neo4j 数据库中获取相关的子图数据并将其格式化以供模型使用。让我们来分解一下。
def format_graph_context(subgraph):
nodes = set()
edges = []
for entry in subgraph:
entity = entry["entity"]
related = entry["related_node"]
relationship = entry["relationship"]
nodes.add(entity["name"])
nodes.add(related["name"])
edges.append(f"{entity['name']} {relationship['type']} {related['name']}")
return {"nodes": list(nodes), "edges": edges}
函数 format_graph_context 处理 Neo4j 查询返回的子图。它提取图的实体(节点)和关系(边)。节点集确保每个实体只添加一次。边列表以可读格式捕获关系:实体 1 关系 实体 2。
与 LLM 集成
现在我们有了图上下文,我们需要为像 GPT-4 这样的语言模型生成一个提示。这是检索增强生成 (RAG) 的核心所在——我们将图数据和用户查询组合成一个全面的提示供模型使用。
def graphRAG_run(graph_context, user_query):
nodes_str = ", ".join(graph_context["nodes"])
edges_str = "; ".join(graph_context["edges"])
prompt = f"""
You are an intelligent assistant with access to the following knowledge graph:
Nodes: {nodes_str}
Edges: {edges_str}
Using this graph, Answer the following question:
User Query: "{user_query}"
"""
try:
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Provide the answer for the following question:"},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message
except Exception as e:
return f"Error querying LLM: {str(e)}"
函数 graphRAG_run 接受图上下文(节点和边)和用户查询,将它们组合成一个结构化提示供 LLM 使用。节点和边被格式化为可读字符串,以构成 LLM 输入的一部分。然后,LLM 使用生成的提示进行查询,要求它使用图上下文来完善用户查询并提供答案。如果模型成功生成响应,它将返回答案。
端到端管道
最后,让我们将所有内容集成到一个端到端管道中,我们将在其中摄取一些示例数据,运行检索过程,并查询语言模型。
if __name__ == "__main__":
print("Script started")
print("Loading environment variables...")
load_dotenv('.env.local')
print("Environment variables loaded")
print("Initializing clients...")
neo4j_driver = GraphDatabase.driver(neo4j_uri, auth=(neo4j_username, neo4j_password))
qdrant_client = QdrantClient(
url=qdrant_url,
api_key=qdrant_key
)
print("Clients initialized")
print("Creating collection...")
collection_name = "graphRAGstoreds"
vector_dimension = 1536
create_collection(qdrant_client, collection_name, vector_dimension)
print("Collection created/verified")
print("Extracting graph components...")
raw_data = """Alice is a data scientist at TechCorp's Seattle office.
Bob and Carol collaborate on the Alpha project.
Carol transferred to the New York office last year.
Dave mentors both Alice and Bob.
TechCorp's headquarters is in Seattle.
Carol leads the East Coast team.
Dave started his career in Seattle.
The Alpha project is managed from New York.
Alice previously worked with Carol at DataCo.
Bob joined the team after Dave's recommendation.
Eve runs the West Coast operations from Seattle.
Frank works with Carol on client relations.
The New York office expanded under Carol's leadership.
Dave's team spans multiple locations.
Alice visits Seattle monthly for team meetings.
Bob's expertise is crucial for the Alpha project.
Carol implemented new processes in New York.
Eve and Dave collaborated on previous projects.
Frank reports to the New York office.
TechCorp's main AI research is in Seattle.
The Alpha project revolutionized East Coast operations.
Dave oversees projects in both offices.
Bob's contributions are mainly remote.
Carol's team grew significantly after moving to New York.
Seattle remains the technology hub for TechCorp."""
nodes, relationships = extract_graph_components(raw_data)
print("Nodes:", nodes)
print("Relationships:", relationships)
print("Ingesting to Neo4j...")
node_id_mapping = ingest_to_neo4j(nodes, relationships)
print("Neo4j ingestion complete")
print("Ingesting to Qdrant...")
ingest_to_qdrant(collection_name, raw_data, node_id_mapping)
print("Qdrant ingestion complete")
query = "How is Bob connected to New York?"
print("Starting retriever search...")
retriever_result = retriever_search(neo4j_driver, qdrant_client, collection_name, query)
print("Retriever results:", retriever_result)
print("Extracting entity IDs...")
entity_ids = [item.content.split("'id': '")[1].split("'")[0] for item in retriever_result.items]
print("Entity IDs:", entity_ids)
print("Fetching related graph...")
subgraph = fetch_related_graph(neo4j_driver, entity_ids)
print("Subgraph:", subgraph)
print("Formatting graph context...")
graph_context = format_graph_context(subgraph)
print("Graph context:", graph_context)
print("Running GraphRAG...")
answer = graphRAG_run(graph_context, query)
print("Final Answer:", answer)
以下是正在发生的事情
- 首先,定义用户查询(“Bob 是如何与纽约建立联系的?”)。
- QdrantNeo4jRetriever 根据用户查询的嵌入在 Qdrant 向量数据库中搜索相关实体。它检索前 5 个结果 (top_k=5)。
- entity_ids 从检索器结果中提取。
- fetch_related_graph 函数从 Neo4j 数据库中检索相关实体及其关系。
- format_graph_context 函数以 LLM 可以理解的格式准备图数据。
- 最后,调用 graphRAG_run 函数来生成和查询语言模型,根据检索到的图上下文生成答案。
通过此,我们成功创建了 GraphRAG,一个能够捕获复杂关系并提供比基线 RAG 方法改进的性能的系统。
Qdrant + Neo4j GraphRAG 的优势
在 GraphRAG 架构中将 Qdrant 与 Neo4j 结合提供了几个引人注目的优势,尤其是在召回率和精确度组合、上下文理解、对复杂查询的适应性以及更好的成本和可伸缩性方面。
- 改进的召回率和精确度: 通过利用 Qdrant(一个高效的向量搜索引擎)和 Neo4j 强大的图数据库,该系统受益于语义搜索和基于关系的检索。Qdrant 识别相关向量并捕获查询和存储数据之间的相似性。同时,Neo4j 通过其图结构增加了一层连接,确保检索到相关且上下文链接的信息。这种组合提高了召回率(检索更广泛的相关结果)和精确度(提供更准确和上下文相关的结果),解决了传统基于检索的 AI 系统中的常见挑战。
- 增强的上下文理解: Neo4j 通过将信息表示为图来增强上下文理解,其中实体及其关系被自然建模。当与 Qdrant 集成时,系统可以根据向量嵌入检索相似项,以及那些符合所需关系上下文的项,从而产生更细致和有意义的响应。
- 对复杂查询的适应性: 结合 Qdrant 和 Neo4j 使系统能够高度适应复杂查询。Qdrant 处理相关数据的向量搜索,而 Neo4j 的图功能则通过关系实现复杂的查询。这允许进行多跳推理和处理传统搜索引擎难以应对的复杂结构化查询。
- 更好的成本和可伸缩性: GraphRAG 本身需要大量资源,因为它依赖 LLM 来构建和查询知识图谱。它还采用聚类算法来创建语义聚类以进行本地搜索。这些可能会阻碍可伸缩性并增加成本。Qdrant 通过向量搜索解决了本地搜索问题,而 Neo4j 的知识图谱则用于更精确的答案查询,从而提高了效率和准确性。此外,与使用 LLM 相比,基于命名实体识别 (NER) 的技术可以进一步降低成本,但这主要取决于数据集。
结论
GraphRAG 与 Neo4j 和 Qdrant 标志着检索增强生成向前迈出了重要一步。这种混合方法通过结合向量搜索和图数据库提供了显著优势。Qdrant 的语义搜索功能增强了召回准确性,而 Neo4j 的关系建模提供了更深层次的上下文理解。
我们探讨的实现模板为您的项目提供了基础。您可以根据您的具体需求对其进行调整和定制,无论是用于文档分析、知识管理还是其他信息检索任务。
随着 AI 系统的发展,这种技术组合展示了我们如何构建更智能、更高效的解决方案。我们鼓励您尝试这种方法,并发现它如何增强您的应用程序。