使用混合搜索与产品 PDF 手册聊天
| 时间:120 分钟 | 级别:高级 | 输出:GitHub |
|---|
随着数字手册的普及以及对快速准确客户支持的需求不断增加,拥有一个能够有效解析复杂 PDF 文档并提供精确信息的聊天机器人,对于任何企业来说都可能改变游戏规则。
在本教程中,我们将引导您完成构建基于 RAG 的聊天机器人的过程,该机器人专门设计用于帮助用户理解各种家用电器的操作。我们将介绍构建系统所需的基本步骤,包括数据摄入、自然语言理解以及针对客户支持用例的响应生成。
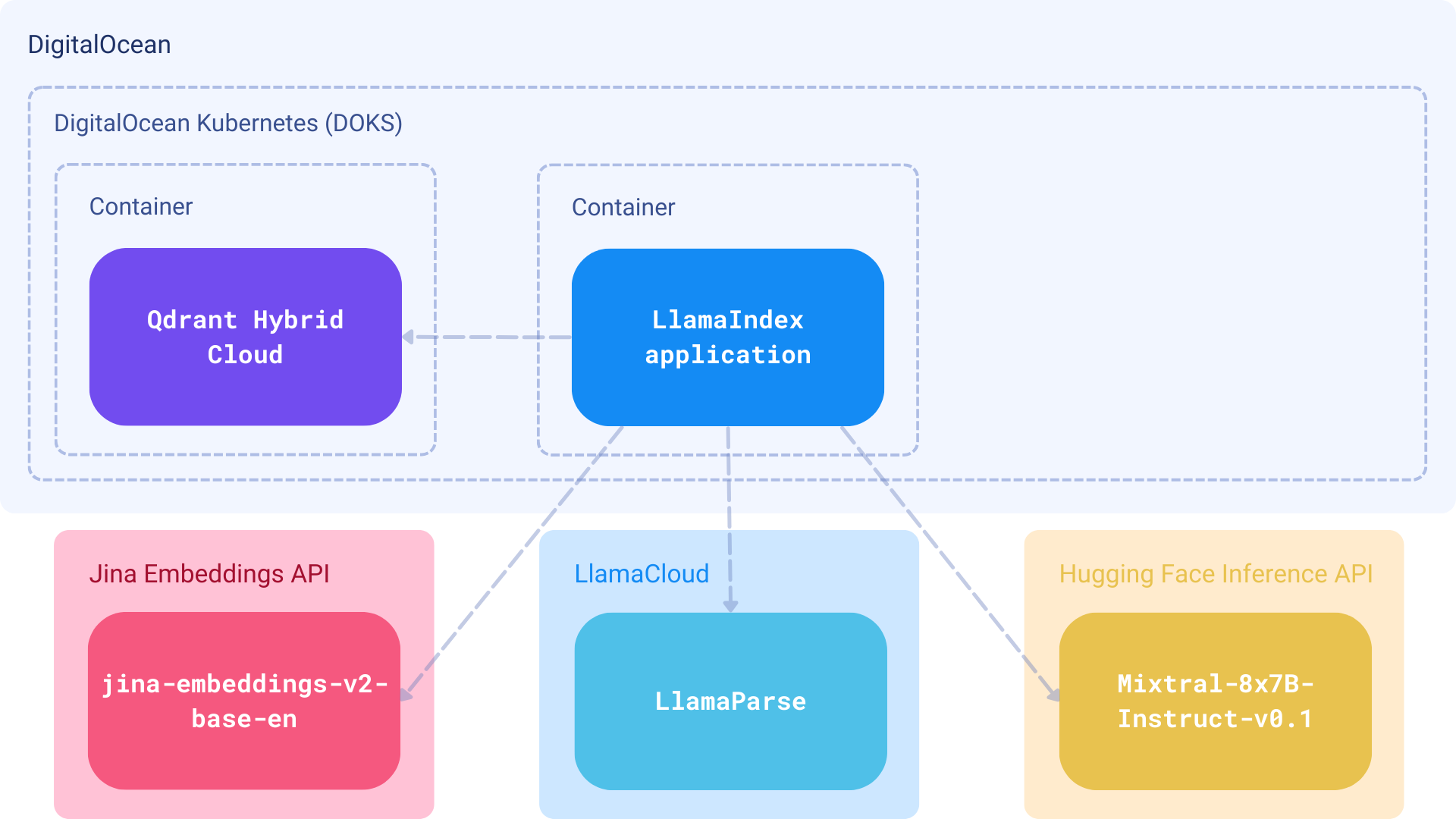
组件
- 嵌入: Jina Embeddings,通过 Jina Embeddings API 提供服务
- 数据库: Qdrant Hybrid Cloud,部署在 DigitalOcean (DOKS) 托管的 Kubernetes 集群上
- 大型语言模型 (LLM): HuggingFace 上的 Mixtral-8x7B-Instruct-v0.1 语言模型
- 框架: LlamaIndex 用于扩展的 RAG 功能和 混合搜索支持。
- 解析器: LlamaParse,用于解析包含表格和图表等嵌入对象的复杂文档。
步骤
检索增强生成 (RAG) 将搜索与语言生成相结合。使用外部信息检索系统来识别可能提供与用户查询相关信息的文档。然后,这些文档连同用户的请求一起被传递给文本生成语言模型,从而产生自然的回应。
这种方法使语言模型能够响应问题并从比其通常能够看到的大得多的文档集中访问信息。语言模型在生成响应时只会查看文档中少数相关的部分,这也有助于减少无法解释的错误。
Service Managed Kubernetes 由欧洲领先的云服务提供商 OVH 公有云实例提供支持。内置 OVHcloud 负载均衡器和磁盘。OVHcloud Managed Kubernetes 提供高可用性、合规性和 CNCF 一致性,让您能够专注于您的容器化软件层,并具有完全的可逆性。
前提条件
在 DigitalOcean 上部署 Qdrant Hybrid Cloud
DigitalOcean Kubernetes (DOKS) 是一项托管的 Kubernetes 服务,让您无需处理控制平面和容器化基础设施的复杂性即可部署 Kubernetes 集群。集群兼容标准的 Kubernetes 工具链,并与 DigitalOcean 负载均衡器和卷原生集成。
- 要开始在 DigitalOcean 上使用托管 Kubernetes,请遵循特定平台的文档。
- Kubernetes 集群启动后,您即可开始部署 Qdrant Hybrid Cloud。
- 部署完成后,您应该拥有一个正在运行的 Qdrant 集群,并具有 API 密钥。
开发环境
然后,安装所有依赖项
!pip install -U \
llama-index \
llama-parse \
python-dotenv \
llama-index-embeddings-jinaai \
llama-index-llms-huggingface \
llama-index-vector-stores-qdrant \
"huggingface_hub[inference]" \
datasets
在 .env 文件中设置密钥值
JINAAI_API_KEY
HF_INFERENCE_API_KEY
LLAMA_CLOUD_API_KEY
QDRANT_HOST
QDRANT_API_KEY
加载所有环境变量
import os
from dotenv import load_dotenv
load_dotenv('./.env')
实现
连接 Jina Embeddings 和 Mixtral 大型语言模型 (LLM)
LlamaIndex 内置支持 Jina Embeddings API。要使用它,您需要使用您的 API 密钥和模型名称初始化 JinaEmbedding 对象。
对于大型语言模型 (LLM),您需要将其封装在 llama_index.llms.CustomLLM 的子类中,以使其与 LlamaIndex 兼容。
# connect embeddings
from llama_index.embeddings.jinaai import JinaEmbedding
jina_embedding_model = JinaEmbedding(
model="jina-embeddings-v2-base-en",
api_key=os.getenv("JINAAI_API_KEY"),
)
# connect LLM
from llama_index.llms.huggingface import HuggingFaceInferenceAPI
mixtral_llm = HuggingFaceInferenceAPI(
model_name = "mistralai/Mixtral-8x7B-Instruct-v0.1",
token=os.getenv("HF_INFERENCE_API_KEY"),
)
为 RAG 准备数据
本示例将使用家用电器手册,这些手册通常以 PDF 文档形式提供。在 data 文件夹中,我们有三个文档,我们将使用它从 PDF 中提取文本内容,并将其用作简单 RAG 的知识库。
LlamaIndex Cloud 的免费计划足以满足我们的示例需求
import nest_asyncio
nest_asyncio.apply()
from llama_parse import LlamaParse
llamaparse_api_key = os.getenv("LLAMA_CLOUD_API_KEY")
llama_parse_documents = LlamaParse(api_key=llamaparse_api_key, result_type="markdown").load_data([
"data/DJ68-00682F_0.0.pdf",
"data/F500E_WF80F5E_03445F_EN.pdf",
"data/O_ME4000R_ME19R7041FS_AA_EN.pdf"
])
将数据存储到 Qdrant
以下代码执行以下操作:
- 使用 Qdrant 客户端创建向量存储;
- 使用 Jina Embeddings API 为每个块获取一个嵌入;
- 组合稀疏向量和稠密向量用于混合搜索;
- 将所有数据存储到 Qdrant;
必须从一开始就启用 Qdrant 的混合搜索 - 我们可以简单地设置 enable_hybrid=True。
# By default llamaindex uses OpenAI models
# setting embed_model to Jina and llm model to Mixtral
from llama_index.core import Settings
Settings.embed_model = jina_embedding_model
Settings.llm = mixtral_llm
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
client = qdrant_client.QdrantClient(
url=os.getenv("QDRANT_HOST"),
api_key=os.getenv("QDRANT_API_KEY")
)
vector_store = QdrantVectorStore(
client=client, collection_name="demo", enable_hybrid=True, batch_size=20
)
Settings.chunk_size = 512
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents=llama_parse_documents,
storage_context=storage_context
)
准备提示
在这里,我们将创建一个自定义提示模板。该提示要求大型语言模型 (LLM) 仅使用从 Qdrant 检索到的上下文信息。在使用混合模式查询时,我们可以分别设置 similarity_top_k 和 sparse_top_k。
sparse_top_k表示从每个稠密和稀疏查询中检索到的节点数量。similarity_top_k控制返回节点的最终数量。在上述设置中,我们最终得到 10 个节点。
然后,我们使用提示组装查询引擎。
from llama_index.core import PromptTemplate
qa_prompt_tmpl = (
"Context information is below.\n"
"-------------------------------"
"{context_str}\n"
"-------------------------------"
"Given the context information and not prior knowledge,"
"answer the query. Please be concise, and complete.\n"
"If the context does not contain an answer to the query,"
"respond with \"I don't know!\"."
"Query: {query_str}\n"
"Answer: "
)
qa_prompt = PromptTemplate(qa_prompt_tmpl)
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import get_response_synthesizer
from llama_index.core import Settings
Settings.embed_model = jina_embedding_model
Settings.llm = mixtral_llm
# retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
sparse_top_k=12,
vector_store_query_mode="hybrid"
)
# response synthesizer
response_synthesizer = get_response_synthesizer(
llm=mixtral_llm,
text_qa_template=qa_prompt,
response_mode="compact",
)
# query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
运行测试查询
现在您可以根据数据提问并接收答案
问题
result = query_engine.query("What temperature should I use for my laundry?")
print(result.response)
答案
The water temperature is set to 70 ˚C during the Eco Drum Clean cycle. You cannot change the water temperature. However, the temperature for other cycles is not specified in the context.
就这样!您可以根据需要将其扩展到任意数量的文档和复杂 PDF。