员工入职RAG系统
公共网站是与广大受众分享信息的好方法。然而,如果您不熟悉网站的结构或所使用的术语,要找到正确的信息可能会很困难。这就是搜索栏的作用,但如果您还不熟悉内容,要制定一个能返回所需结果的查询并不总是那么容易。这在公司环境中尤为重要,对于刚开始学习并尚不知道如何提出正确问题的新员工来说更是如此。您可能拥有最好的内网页面,但入职不仅仅是阅读文档,更是要理解流程。语义搜索可以帮助更轻松地找到正确的资源,但如果能像与同事聊天一样与网站聊天,会不会更容易呢?
技术进步使得使用自然语言与网站进行交互成为可能。本教程将引导您完成将 Cohere 语言模型与 Qdrant 集成以在您的文档上实现自然语言搜索的过程。我们将使用 LangChain 作为编排器。所有内容都将托管在 Oracle Cloud Infrastructure (OCI) 上,因此您可以根据需要扩展您的应用程序,并且不会将您的数据发送给第三方。当您处理机密或敏感数据时,这一点尤为重要。
构建应用程序
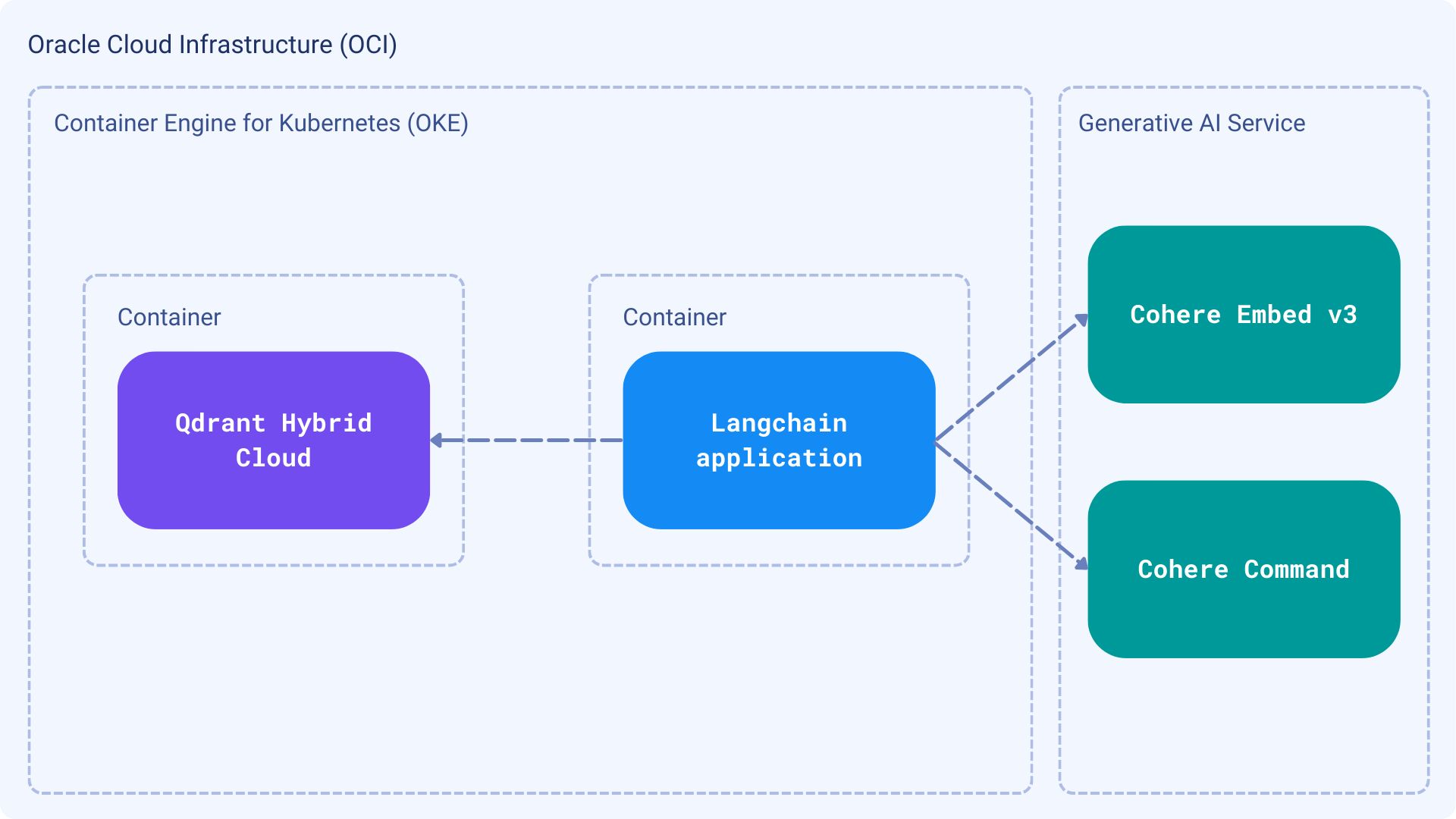
我们的应用程序将包含两个主要过程:索引和搜索。Langchain 将把所有内容连接在一起,因为我们将使用一些组件,包括 Cohere 和 Qdrant,以及一些 OCI 服务。以下是架构的高级概述
先决条件
在深入实施之前,请务必设置所有必要的账户和工具。
库
我们将使用一些 Python 库。当然,Langchain 将是我们的主要框架,但 OCI 上的 Cohere 模型可以通过 OCI SDK 访问。让我们安装所有必要的库
pip install langchain oci qdrant-client langchainhub
甲骨文云
我们的应用程序将完全运行在 Oracle Cloud Infrastructure (OCI) 上。您可以选择部署应用程序的方式。Qdrant 混合云将运行在您的 Oracle Cloud (OKE) 上运行的 Kubernetes 集群中,因此所有进程也可能部署在那里。您可以 注册 Oracle Cloud 账户以开始使用。
Cohere 模型作为 生成式 AI 服务的一部分在 OCI 上提供。我们需要 生成模型和 嵌入模型。请按照链接的教程掌握在那里使用 Cohere 模型的基础知识。
要通过编程方式访问模型,需要知道隔间 OCID。请参阅 描述如何找到它的文档。为了进一步参考,我们假设隔间 OCID 存储在环境变量中
export COMPARTMENT_OCID="<your-compartment-ocid>"
import os
os.environ["COMPARTMENT_OCID"] = "<your-compartment-ocid>"
Qdrant 混合云
运行在 Oracle Cloud 上的 Qdrant 混合云可帮助您构建一个解决方案,而无需将您的数据发送到外部服务。我们的文档提供了关于如何 在 Oracle Cloud 上部署 Qdrant 混合云的逐步指南。
Qdrant 将运行在特定的 URL 上,访问将受 API 密钥限制。请确保将它们都作为环境变量存储
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
可选:每当您使用 LangChain 时,您还可以 配置 LangSmith,这将帮助我们追踪、监控和调试 LangChain 应用程序。您可以在 此处 注册 LangSmith。
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
现在您可以开始了
import os
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
让我们创建将存储索引文档的集合。我们将使用 qdrant-client 库,我们的集合将命名为 oracle-cloud-website。我们的嵌入模型 cohere.embed-english-v3.0 生成大小为 1024 的嵌入,在创建集合时我们必须指定这一点。
from qdrant_client import QdrantClient, models
client = QdrantClient(
location=os.environ.get("QDRANT_URL"),
api_key=os.environ.get("QDRANT_API_KEY"),
)
client.create_collection(
collection_name="oracle-cloud-website",
vectors_config=models.VectorParams(
size=1024,
distance=models.Distance.COSINE,
),
)
索引过程
我们已经设置了所有必要的工具,所以让我们从索引过程开始。我们将使用 Cohere 嵌入模型将文本转换为向量,然后将它们存储在 Qdrant 中。Langchain 已与 OCI 生成式 AI 服务集成,因此我们可以轻松访问模型。
我们的数据集将非常简单,因为它将包含来自 Oracle Cloud 免费层常见问题页面的问题和答案。
问题和答案以 HTML 格式呈现,但我们不想手动提取文本并为每个子页面进行调整。相反,我们将使用 WebBaseLoader,它只是从给定的 URL 加载 HTML 内容并将其转换为文本。
from langchain_community.document_loaders.web_base import WebBaseLoader
loader = WebBaseLoader("https://www.oracle.com/cloud/free/faq/")
documents = loader.load()
我们的 documents 是一个只包含一个元素的列表,即整个页面的文本。我们需要将其分成有意义的部分,因此我们将使用 RecursiveCharacterTextSplitter 组件。它会尝试尽可能地将所有段落(然后是句子,然后是单词)保持在一起,因为这些通常看起来是语义上最强的相关文本片段。块大小和重叠都是可以根据特定用例进行调整的参数。
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=100)
split_documents = splitter.split_documents(documents)
我们的文档现在可能已被索引,但我们需要将它们转换为向量。让我们配置嵌入,以便使用 cohere.embed-english-v3.0。并非所有区域都支持生成式 AI 服务,因此我们需要指定存储模型的区域。我们将使用 us-chicago-1,但请查阅 文档以获取最新支持区域列表。
from langchain_community.embeddings.oci_generative_ai import OCIGenAIEmbeddings
embeddings = OCIGenAIEmbeddings(
model_id="cohere.embed-english-v3.0",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=os.environ.get("COMPARTMENT_OCID"),
)
现在我们可以嵌入文档并将它们存储在 Qdrant 中。我们将创建一个 Qdrant 实例并将拆分的文档添加到集合中。
from langchain.vectorstores.qdrant import Qdrant
qdrant = Qdrant(
client=client,
collection_name="oracle-cloud-website",
embeddings=embeddings,
)
qdrant.add_documents(split_documents, batch_size=20)
我们的文档现在应该已经索引并准备好进行搜索了。让我们进入下一步。
与网站对话
与网站交互的预期方法是通过聊天机器人。大型语言模型,在我们的例子中是 Cohere Command,将根据 Qdrant 使用问题作为查询返回的相关文档回答用户的问题。我们的 LLM 也托管在 OCI 上,因此我们可以像访问嵌入模型一样访问它
from langchain_community.llms.oci_generative_ai import OCIGenAI
llm = OCIGenAI(
model_id="cohere.command",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=os.environ.get("COMPARTMENT_OCID"),
)
与 Qdrant 的连接可以像我们在索引过程中那样建立。我们可以使用它来创建一个检索链,该链实现了问答过程。检索链还需要一个额外的链,该链将在将检索到的文档发送到 LLM 之前将它们组合起来。
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain import hub
retriever = qdrant.as_retriever()
combine_docs_chain = create_stuff_documents_chain(
llm=llm,
# Default prompt is loaded from the hub, but we can also modify it
prompt=hub.pull("langchain-ai/retrieval-qa-chat"),
)
retrieval_qa_chain = create_retrieval_chain(
retriever=retriever,
combine_docs_chain=combine_docs_chain,
)
response = retrieval_qa_chain.invoke({"input": "What is the Oracle Cloud Free Tier?"})
.invoke 方法的输出是一个字典状的结构,包含查询和答案,但我们也可以访问用于生成响应的源文档。这对于调试或进一步处理可能很有用。
{
'input': 'What is the Oracle Cloud Free Tier?',
'context': [
Document(
page_content='* Free Tier is generally available in regions where commercial Oracle Cloud Infrastructure service is available. See the data regions page for detailed service availability (the exact regions available for Free Tier may differ during the sign-up process). The US$300 cloud credit is available in',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'c8cf98e0-4b88-4750-be42-4157495fed2c',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='Oracle Cloud Free Tier allows you to sign up for an Oracle Cloud account which provides a number of Always Free services and a Free Trial with US$300 of free credit to use on all eligible Oracle Cloud Infrastructure services for up to 30 days. The Always Free services are available for an unlimited',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'dc291430-ff7b-4181-944a-39f6e7a0de69',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='Oracle Cloud Free Tier does not include SLAs. Community support through our forums is available to all customers. Customers using only Always Free resources are not eligible for Oracle Support. Limited support is available for Oracle Cloud Free Tier with Free Trial credits. After you use all of',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': '9e831039-7ccc-47f7-9301-20dbddd2fc07',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='looking to test things before moving to cloud, a student wanting to learn, or an academic developing curriculum in the cloud, Oracle Cloud Free Tier enables you to learn, explore, build and test for free.',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'e2dc43e1-50ee-4678-8284-6df60a835cf5',
'_collection_name': 'oracle-cloud-website'
}
)
],
'answer': ' Oracle Cloud Free Tier is a subscription that gives you access to Always Free services and a Free Trial with $300 of credit that can be used on all eligible Oracle Cloud Infrastructure services for up to 30 days. \n\nThrough this Free Tier, you can learn, explore, build, and test for free. It is aimed at those who want to experiment with cloud services before making a commitment, as wellTheir use cases range from testing prior to cloud migration to learning and academic curriculum development. '
}
其他实验
提出基本问题只是开始。您需要避免的是幻觉,即模型生成不基于实际内容的答案。Langchain 的默认提示应该已经可以防止这种情况,但您可能仍想检查它。让我们提出一个在常见问题页面上没有直接回答的问题
response = retrieval_qa.invoke({
"input": "Is Oracle Generative AI Service included in the free tier?"
})
输出
Oracle 生成式 AI 服务并未明确提及是否在免费层中提供。根据文本,300 美元的免费积分可在所有符合条件的服务上使用长达 30 天。要确认 Oracle 生成式 AI 服务是否包含在免费积分优惠中,最好查看 Oracle Cloud 官方网站或联系其支持部门。
看来 Cohere Command 模型在提供的文档中未能找到确切答案,但它尝试解释上下文并提供一个合理的答案,而没有编造信息。这是一个好迹象,表明模型在这种情况下没有产生幻觉。
总结
本教程展示了如何将 Cohere 的语言模型与 Qdrant 集成,以在您的网站上实现自然语言搜索。我们使用了 Langchain 作为编排器,并且所有内容都托管在 Oracle Cloud Infrastructure (OCI) 上。真实世界需要将此机制集成到您组织的系统中,但我们已经构建了一个可以进一步发展的坚实基础。