使用 GPT-4o 构建博客阅读聊天机器人
| 时间:90 分钟 | 等级:高级 | GitHub |
|---|
在本教程中,你将构建一个结合了博客内容摄取和语义搜索功能的 RAG 系统。OpenAI 的 GPT-4o LLM 功能强大,但扩展其使用需要我们系统地提供上下文。
RAG 通过检索相关文档来辅助问答过程,从而增强 LLM 生成答案的能力。这种设置展示了先进搜索和人工智能语言处理的集成,以改进信息检索和生成任务。
本教程的 notebook 可在 GitHub 上获取。
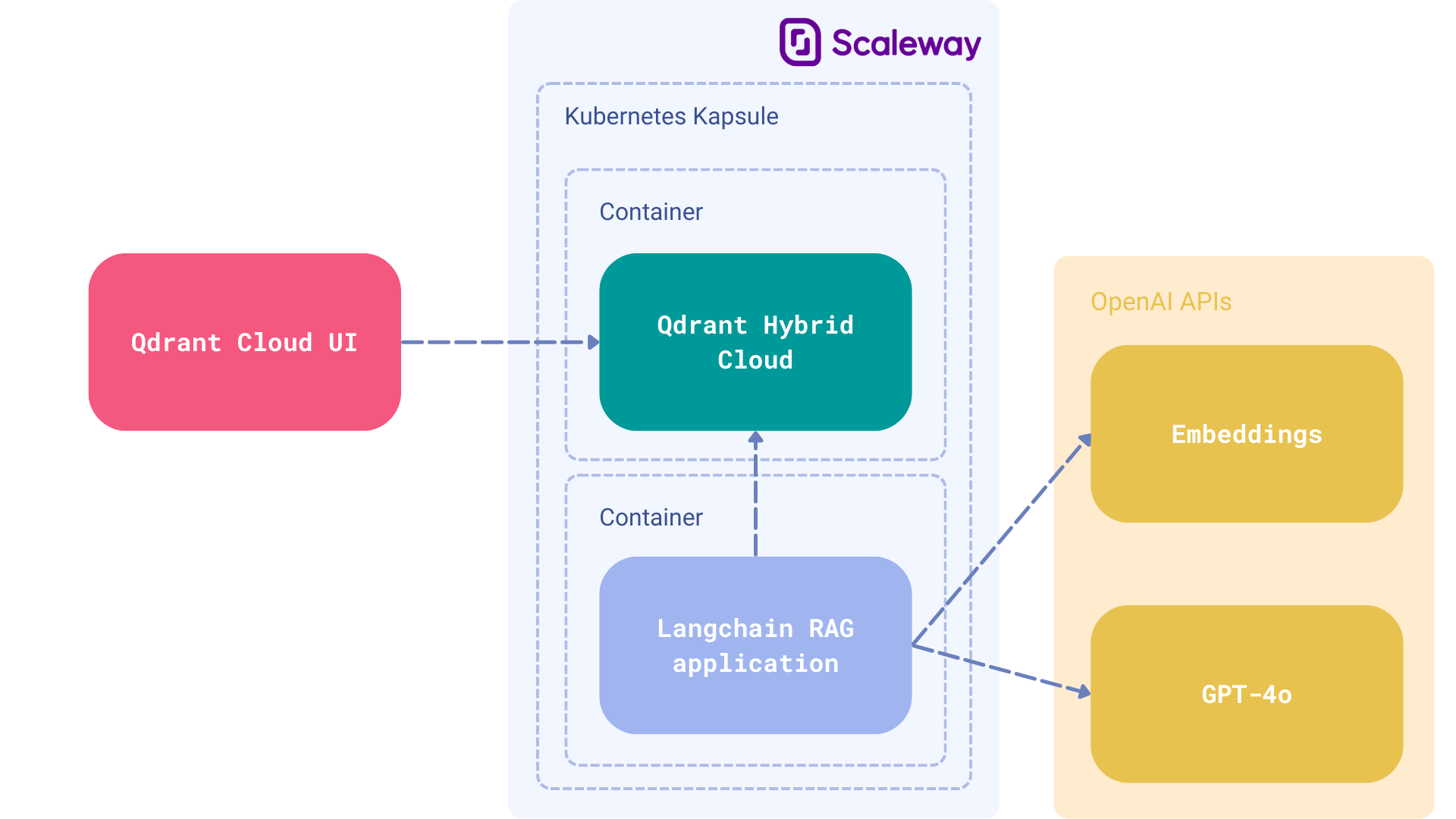
数据隐私和主权:RAG 应用通常依赖于敏感或专有的内部数据。在自己的环境中运行整个技术栈对于维护这些数据的控制至关重要。部署在 Scaleway 上的 Qdrant Hybrid Cloud 完美地满足了这一需求,提供了一个安全、可扩展的平台,同时仍能充分利用 RAG 的潜力。Scaleway 提供了无服务器 Functions 和无服务器 Jobs,两者都非常适合大规模 RAG 用例中的 embedding 创建。
组件
- 云主机:Scaleway 上的托管 Kubernetes,用于兼容 Qdrant Hybrid Cloud。
- 向量数据库:Qdrant Hybrid Cloud 作为检索的向量搜索引擎。
- LLM:由 OpenAI 开发的 GPT-4o 用作生成答案的生成器。
- 框架:LangChain,用于广泛的 RAG 功能。
Langchain 支持广泛的 LLM,并且在本教程中将 GPT-4o 用作主要生成器。你可以轻松地将其替换为你喜欢的模型,该模型可以在你的本地部署,以完成完全私有的设置。为简单起见,我们使用了 OpenAI API,但 LangChain 使这种转换变得无缝。
在 Scaleway 上部署 Qdrant Hybrid Cloud
Scaleway Kapsule 和 Kosmos 是 Scaleway 提供的托管 Kubernetes 服务。它们抽象了管理和操作 Kubernetes 集群的复杂性。主要区别在于,Kapsule 集群仅由 Scaleway 实例组成。而 Kosmos 集群是一个托管的多云 Kubernetes 引擎,允许你将来自任何云提供商的实例连接到单个托管的 Control-Plane。
- 要开始在 Scaleway 上使用托管 Kubernetes,请遵循平台特定文档。
- Kubernetes 集群启动后,你可以开始部署 Qdrant Hybrid Cloud。
前提条件
为了准备使用 Qdrant 和相关库的环境,需要安装所有必需的 Python 包。这可以使用 Poetry 完成,Poetry 是一个用于 Python 依赖管理和打包的工具。代码片段导入了执行后续任务所需的各种库,包括用于解析 HTML 和 XML 文档的 bs4,用于处理语言模型和文档加载器的 langchain 及其社区扩展,以及用于向量存储和检索的 Qdrant。这些导入为将 Qdrant 与其他自然语言处理和机器学习工具结合使用奠定了基础。
Qdrant 将在特定的 URL 上运行,访问将受 API 密钥限制。请确保也将它们作为环境变量存储。
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
可选:无论何时使用 LangChain,你还可以配置 LangSmith,这将帮助我们跟踪、监控和调试 LangChain 应用。你可以在此处注册 LangSmith。
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
现在你可以开始
import getpass
import os
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_qdrant import Qdrant
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
设置 OpenAI API 密钥
os.environ["OPENAI_API_KEY"] = getpass.getpass()
初始化语言模型
llm = ChatOpenAI(model="gpt-4o")
在此处,我们配置 Embedding 和 LLM。你可以使用 Ollama 或其他服务将其替换为你自己的模型。Scaleway 提供了一些很棒的 L4 GPU 实例,你可以在此处用于计算。
下载和解析数据
要开始处理博客文章内容,过程涉及加载和解析 HTML 内容。这可以通过使用专门为此类任务设计的工具 urllib 和 BeautifulSoup 来实现。加载和解析内容后,使用 Qdrant 对其进行索引,Qdrant 是一个用于管理和查询向量数据的强大工具。代码片段演示了如何通过指定博客的 URL 和要解析的特定 HTML 元素来加载、分块和索引博客文章的内容。这一步对于准备数据以便使用 Qdrant 进行进一步处理和分析至关重要。
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
数据分块
在处理大型文档(例如超过 42,000 个字符的博客文章)时,有效管理数据以进行处理至关重要。许多模型的上下文窗口有限,难以处理长输入,从而难以提取或找到相关信息。为了克服这个问题,将文档分成更小的块。这种方法增强了模型有效处理和检索文档中最相关部分的能力。
在这种情况下,使用 RecursiveCharacterTextSplitter 并指定块大小和重叠来将文档分成块。这种方法确保在块之间不会丢失关键信息。分割后,这些块将被索引到 Qdrant 中——一个用于高效相似性搜索和 embedding 存储的向量数据库。Qdrant.from_documents 函数用于索引,其中 documents 是分割的块,embeddings 通过 OpenAIEmbeddings 生成。整个过程在内存数据库中进行,这意味着操作无需持久存储,并且集合命名为“lilianweng”以供参考。
这种分块和索引策略显著改善了大型文档的信息管理和检索,使其成为处理数据处理工作流程中大量文本的实用解决方案。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Qdrant.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
collection_name="lilianweng",
url=os.environ["QDRANT_URL"],
api_key=os.environ["QDRANT_API_KEY"],
)
检索和生成内容
vectorstore 被用作检索器,根据向量相似性获取相关文档。hub.pull("rlm/rag-prompt") 函数用于从存储库中拉取特定提示,该提示旨在与检索到的文档和问题一起使用以生成响应。
format_docs 函数将检索到的文档格式化为一个字符串,为进一步处理做准备。这个格式化的字符串连同问题一起通过一系列操作进行处理。首先,上下文(格式化的文档)和问题由检索器和提示进行处理。然后,结果被输入到大型语言模型(llm)中以生成内容。最后,使用 StrOutputParser() 将输出解析为字符串格式。
这一系列操作展示了信息检索和内容生成的复杂方法,利用了向量搜索的语义理解能力和大型语言模型的生成能力。
现在,使用博客中的相关片段检索并生成数据L
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
调用 RAG 链
rag_chain.invoke("What is Task Decomposition?")
下一步
我们为简单的聊天机器人奠定了坚实的基础,但还有很多工作要做。如果你想让系统达到生产就绪状态,你应该考虑将该机制集成到你现有的技术栈中。我们建议
我们的向量数据库可以轻松托管在 Scaleway 上,Scaleway 是我们信任的 Qdrant Hybrid Cloud 合作伙伴。这意味着 Qdrant 可以在你的 Scaleway 区域运行,但数据库本身仍可在 Qdrant Cloud 的界面中进行管理。这两个产品都经过了兼容性和可扩展性测试,我们推荐他们的 托管 Kubernetes 服务。他们的法国部署区域(例如法国)在网络延迟和数据主权方面表现出色。对于托管 GPU,尝试使用 L4 GPU 实例进行渲染。
如果你有任何问题,欢迎在我们的 Discord 社区 提问。