区域特定合同管理系统
| 时间:90 分钟 | 难度:高级 |
|---|
合同管理受益于检索增强生成(RAG),它简化了处理冗长商业合同文本的过程。在AI的帮助下,可以提出复杂的问题并生成充分知情的答案,从而实现高效的文档管理。这对于拥有广泛业务关系的企业,如航运公司、建筑公司和咨询机构来说,是无价的。由于安全和监管要求(例如欧洲的GDPR),此类合同的访问通常仅限于授权团队成员,因此需要安全的存储实践。
公司希望他们的数据在特定的地理边界内存储和处理。因此,本以RAG为中心的教程重点介绍如何处理区域性云提供商。您将使用Aleph Alpha的嵌入和LLM设置一个合同管理系统。您将在德国商业云提供商STACKIT上托管所有内容。在这个平台上,您将运行Qdrant混合云以及您的RAG应用程序的其余部分。此设置将确保您的数据在德国存储和处理。
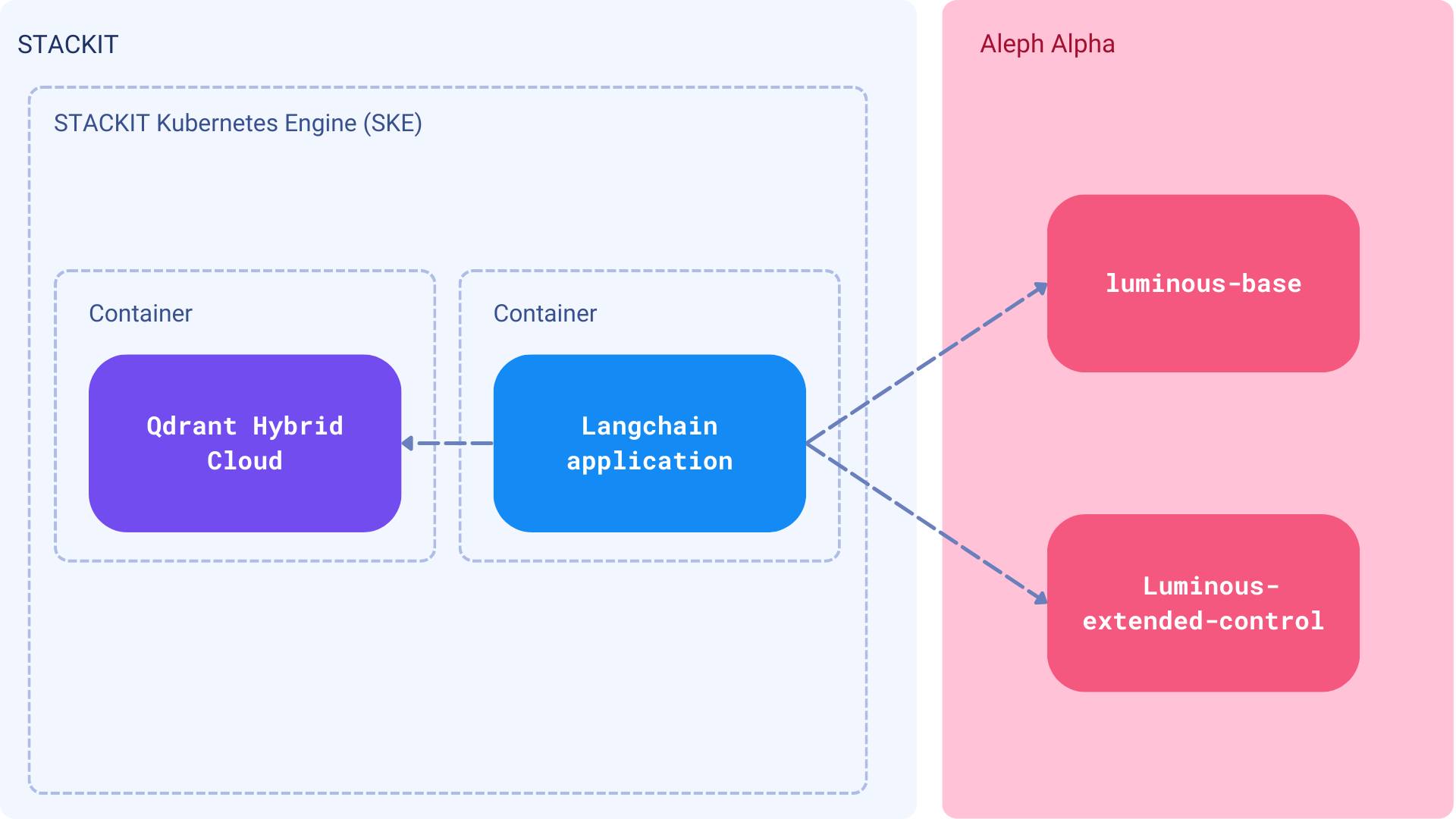
组件
合同管理平台不是一个简单的命令行工具,而是一个应该对所有团队成员开放的应用程序。它需要一个界面来上传、搜索和管理文档。理想情况下,系统应与组织的现有堆栈集成,并从LDAP或Active Directory继承权限/访问控制。
注意:在本教程中,我们将为这样的系统打下坚实的基础。然而,实施整个解决方案取决于您的组织设置。
- 数据集 - 从互联网上抓取的使用不同格式(如PDF或DOCx)的文档集合
- 非对称语义嵌入 - Aleph Alpha 嵌入,用于将查询和文档转换为向量
- 大型语言模型 - Luminous-extended-control 模型,但您可以尝试Luminous系列中的其他模型
- Qdrant 混合云 - 一个用于存储向量和搜索文档的知识库
- STACKIT - 一个德国商业云,用于运行Qdrant混合云和应用程序进程
我们将实现上传文档、将其转换为向量并存储在Qdrant中的过程。然后,我们将构建一个搜索界面来查询文档并获取答案。所有这些都假设用户在一定权限下与系统交互,并且只能访问他们被允许访问的文档。
先决条件
Aleph Alpha 账户
由于您将使用Aleph Alpha的模型,请注册他们的托管服务并获取API令牌。准备好后,将其存储为环境变量。
export ALEPH_ALPHA_API_KEY="<your-token>"
import os
os.environ["ALEPH_ALPHA_API_KEY"] = "<your-token>"
STACKIT 上的 Qdrant 混合云
请参阅我们的文档以了解如何在STACKIT上部署Qdrant混合云。部署完成后,您将获得与Qdrant服务器交互的API端点。我们也将它存储在环境变量中。
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
Qdrant 将运行在特定的 URL 上,访问将受 API 密钥限制。请确保将它们都作为环境变量存储
可选:每当您使用 LangChain 时,您还可以 配置 LangSmith,这将帮助我们追踪、监控和调试 LangChain 应用程序。您可以在 此处 注册 LangSmith。
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
实施
为了构建应用程序,我们可以使用Aleph Alpha和Qdrant的官方SDK。然而,为了简化过程,让我们使用LangChain。该框架已经与这两种服务集成,因此我们可以将精力集中在开发业务逻辑上。
Qdrant 集合
Aleph Alpha 嵌入默认是高维向量,维度为5120。然而,该模型的一个非常独特的特性是它们可以被压缩到128的大小,并且准确性性能略有下降(根据文档,下降4-6%)。Qdrant 即使可以轻松存储原始向量,并且为了节省空间并加快检索速度,启用二进制量化似乎是个好主意。让我们创建一个具有此类设置的集合。
from qdrant_client import QdrantClient, models
client = QdrantClient(
location=os.environ["QDRANT_URL"],
api_key=os.environ["QDRANT_API_KEY"],
)
client.create_collection(
collection_name="contracts",
vectors_config=models.VectorParams(
size=5120,
distance=models.Distance.COSINE,
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True,
)
)
),
)
我们将使用contracts集合来存储文档的向量。always_ram标志设置为True以将量化向量保存在RAM中,这将加快搜索过程。我们还希望限制对单个文档的访问,因此只有具有适当权限的用户才能看到它们。在Qdrant中,这应该通过添加一个定义谁可以访问文档的有效载荷字段来解决。我们将此字段称为roles,并将其设置为一个包含可以访问文档的角色字符串数组。
client.create_payload_index(
collection_name="contracts",
field_name="metadata.roles",
field_schema=models.PayloadSchemaType.KEYWORD,
)
由于我们使用Langchain,roles字段是metadata的嵌套字段,因此我们必须将其定义为metadata.roles。模式表明该字段是一个关键字,这意味着它是一个字符串或字符串数组。我们将使用客户名称作为角色,因此访问控制将基于客户名称。
摄取管道
语义搜索系统以高质量数据为基础。通过Langchain 的非结构化集成,摄取各种文档格式(如PDF、Microsoft Word文件和PowerPoint演示文稿)变得毫不费力。然而,智能地分割文本至关重要,以避免将整个文档转换为向量;相反,它们应该被分成有意义的块。随后,提取的文档使用Aleph Alpha嵌入转换为向量并存储在Qdrant集合中。
让我们从定义组件并将它们连接起来开始
embeddings = AlephAlphaAsymmetricSemanticEmbedding(
model="luminous-base",
aleph_alpha_api_key=os.environ["ALEPH_ALPHA_API_KEY"],
normalize=True,
)
qdrant = Qdrant(
client=client,
collection_name="contracts",
embeddings=embeddings,
)
现在是时候索引我们的文档了。每个文档都是一个单独的文件,我们还必须知道客户名称才能正确设置访问控制。单个文档可能存在多个角色,所以让我们将它们保存在一个列表中。
documents = {
"data/Data-Processing-Agreement_STACKIT_Cloud_version-1.2.pdf": ["stackit"],
"data/langchain-terms-of-service.pdf": ["langchain"],
}
文档可能看起来像这样

每个都必须先分成块;没有万能药。我们的分块算法将是简单的,基于递归分割,最大块大小为500个字符,重叠100个字符。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
)
现在我们可以遍历文档,将它们分成块,使用Aleph Alpha嵌入模型将它们转换为向量,并将它们存储在Qdrant中。
from langchain_community.document_loaders.unstructured import UnstructuredFileLoader
for document_path, roles in documents.items():
document_loader = UnstructuredFileLoader(file_path=document_path)
# Unstructured loads each file into a single Document object
loaded_documents = document_loader.load()
for doc in loaded_documents:
doc.metadata["roles"] = roles
# Chunks will have the same metadata as the original document
document_chunks = text_splitter.split_documents(loaded_documents)
# Add the documents to the Qdrant collection
qdrant.add_documents(document_chunks, batch_size=20)
我们的集合已经充满了数据,我们可以开始搜索它了。在实际场景中,摄取过程应该自动化,并由上传到系统的新文档触发。由于我们已经使用在Kubernetes上运行的Qdrant混合云,我们可以轻松地将摄取管道部署为作业到同一环境中。在STACKIT上,您可能使用STACKIT Kubernetes Engine (SKE)并在容器中启动它。Compute Engine也是一个选择,但这完全取决于您组织的具体情况。
搜索应用
专业的文档管理系统有很多功能,但语义搜索尚未成为标准。我们将构建一个简单的搜索机制,它可以与现有系统集成。搜索过程非常简单:我们使用相同的Aleph Alpha模型将查询转换为向量,然后在Qdrant集合中搜索最相似的文档。访问控制也适用,因此用户只能看到他们被允许查看的文档。
我们首先创建我们选择的LLM实例,并将最大令牌数设置为200,因为默认值为64,这可能对于我们的目的来说太低了。
from langchain.llms.aleph_alpha import AlephAlpha
llm = AlephAlpha(
model="luminous-extended-control",
aleph_alpha_api_key=os.environ["ALEPH_ALPHA_API_KEY"],
maximum_tokens=200,
)
然后,我们可以将组件组合在一起并构建搜索过程。RetrievalQA是一个实现问答检索过程的类,具有指定的检索器和大型语言模型。Qdrant的实例可以转换为检索器,并带有将传递给similarity_search方法的额外过滤器。该过滤器是像常规Qdrant查询中一样创建的,其中roles字段设置为用户的角色。
user_roles = ["stackit", "aleph-alpha"]
qdrant_retriever = qdrant.as_retriever(
search_kwargs={
"filter": models.Filter(
must=[
models.FieldCondition(
key="metadata.roles",
match=models.MatchAny(any=user_roles)
)
]
)
}
)
我们将用户角色设置为stackit和aleph-alpha,这样用户就可以看到这些客户可以访问的文档,但不能看到其他客户的文档。最后一步是创建RetrievalQA实例并使用它来搜索文档,并带有自定义提示。
from langchain.prompts import PromptTemplate
from langchain.chains.retrieval_qa.base import RetrievalQA
prompt_template = """
Question: {question}
Answer the question using the Source. If there's no answer, say "NO ANSWER IN TEXT".
Source: {context}
### Response:
"""
prompt = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
retrieval_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=qdrant_retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt},
)
response = retrieval_qa.invoke({"query": "What are the rules of performing the audit?"})
print(response["result"])
输出
The rules for performing the audit are as follows:
1. The Customer must inform the Contractor in good time (usually at least two weeks in advance) about any and all circumstances related to the performance of the audit.
2. The Customer is entitled to perform one audit per calendar year. Any additional audits may be performed if agreed with the Contractor and are subject to reimbursement of expenses.
3. If the Customer engages a third party to perform the audit, the Customer must obtain the Contractor's consent and ensure that the confidentiality agreements with the third party are observed.
4. The Contractor may object to any third party deemed unsuitable.
还有一些其他参数可以调整以优化搜索过程。k参数定义应该返回多少个文档,但Langchain也允许我们通过选择搜索操作的类型来控制检索过程。默认是similarity,它只是向量搜索,但我们也可以使用mmr,它代表最大边际相关性(Maximal Marginal Relevance)。这是一种使搜索结果多样化的技术,因此用户可以获得最相关的文档,也是最多样化的文档。mmr搜索较慢,但可能更用户友好。
我们的搜索应用程序已准备就绪,我们可以将其部署到与STACKIT上的摄取管道相同的环境中。这里也适用相同的规则,因此您可以根据组织的具体情况使用SKE或Compute Engine。
下一步
我们为合同管理系统打下了坚实的基础,但仍有很多工作要做。如果您想让系统投入生产,您应该考虑将机制实现到您现有的堆栈中。如果您有任何问题,请随时在我们的Discord社区提问。