电影推荐系统
| 时间:120 分钟 | 难度:高级 | 输出:GitHub |
|---|
在本教程中,您将构建一个根据定义偏好推荐电影的机制。像 Qdrant 这样的向量数据库非常适合存储高维数据,例如用户和物品嵌入。它们可以通过基于高级索引技术快速检索相似条目来实现个性化推荐。在这个特定案例中,我们将使用稀疏向量来创建一个高效准确的推荐系统。
隐私和主权:由于偏好数据是专有的,因此应将其存储在安全受控的环境中。我们的向量数据库可以轻松地托管在OVHcloud上,OVHcloud 是我们值得信赖的 Qdrant 混合云合作伙伴。这意味着 Qdrant 可以从您的 OVHcloud 区域运行,但数据库本身仍可通过 Qdrant Cloud 的界面进行管理。这两个产品都经过兼容性和可扩展性测试,我们推荐其托管 Kubernetes 服务。
要查看完整输出,请使用我们包含完整说明的笔记本。
组件
- 数据集:MovieLens 数据集包含用户给出的电影列表和评分。
- 云:OVHcloud,带有托管 Kubernetes。
- 向量数据库:在OVHcloud上运行的Qdrant 混合云。
方法论:我们正在采用协同过滤方法从提供的数据集中构建推荐系统。协同过滤的原理是,如果两个用户有相似的品味,他们很可能会喜欢相似的电影。利用这个概念,我们将识别评分与我们密切一致的用户,并探索他们喜欢但我们尚未看过的电影。为此,我们将每个用户的评分表示为高维稀疏空间中的向量。使用 Qdrant,我们将对这些向量进行索引,并搜索评分向量与我们密切匹配的用户。最终,我们将看到与我们相似的用户喜欢哪些电影。
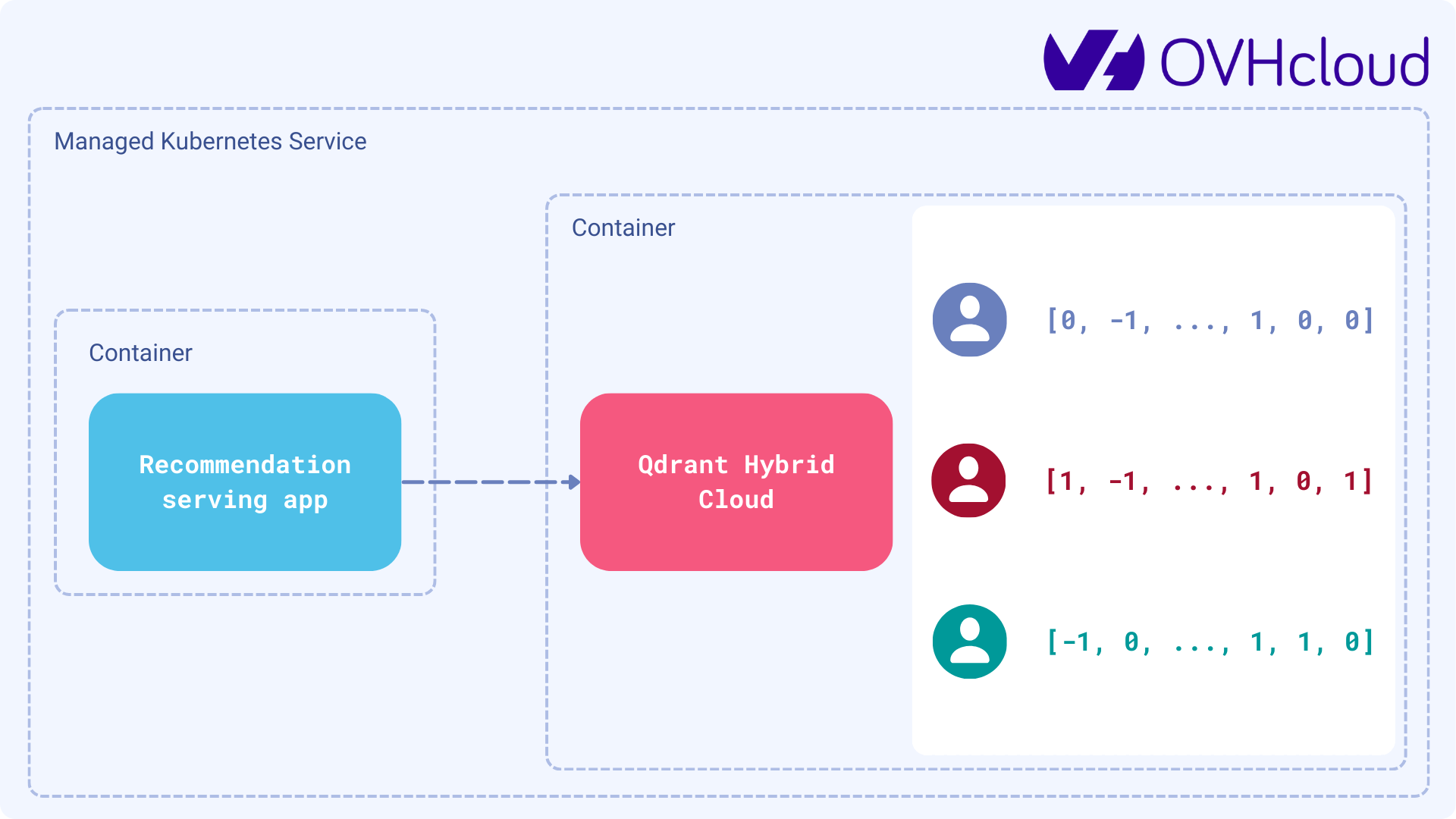
在 OVHcloud 上部署 Qdrant 混合云
Service Managed Kubernetes 由领先的欧洲云提供商 OVH 公共云实例提供支持。内置 OVHcloud 负载均衡器和磁盘。OVHcloud Managed Kubernetes 提供高可用性、合规性和 CNCF 一致性,让您能够专注于容器化软件层,并具有完全可逆性。
- 要开始在 OVHcloud 上使用托管 Kubernetes,请遵循特定于平台的文档。
- 一旦您的 Kubernetes 集群启动并运行,您就可以开始部署 Qdrant 混合云。
先决条件
下载并解压 MovieLens 数据集
mkdir -p data
wget https://files.grouplens.org/datasets/movielens/ml-1m.zip
unzip ml-1m.zip -d data
必要的库使用 pip 安装,包括用于数据操作的 pandas、用于与 Qdrant 接口的 qdrant-client 以及用于管理环境变量的 *-dotenv。
!pip install -U \
pandas \
qdrant-client \
*-dotenv
.env 文件用于安全地存储敏感信息,例如 Qdrant 主机 URL 和 API 密钥。
QDRANT_HOST
QDRANT_API_KEY
将所有环境变量加载到设置中
import os
from dotenv import load_dotenv
load_dotenv('./.env')
实施
将 MovieLens 数据集中的数据加载到 pandas DataFrames 中,以方便数据操作和分析。
from qdrant_client import QdrantClient, models
import pandas as pd
加载用户数据
users = pd.read_csv(
'data/ml-1m/users.dat',
sep='::',
names=['user_id', 'gender', 'age', 'occupation', 'zip'],
engine='*'
)
users.head()
添加电影
movies = pd.read_csv(
'data/ml-1m/movies.dat',
sep='::',
names=['movie_id', 'title', 'genres'],
engine='*',
encoding='latin-1'
)
movies.head()
最后,添加评分
ratings = pd.read_csv(
'data/ml-1m/ratings.dat',
sep='::',
names=['user_id', 'movie_id', 'rating', 'timestamp'],
engine='*'
)
ratings.head()
规范化评分
稀疏向量可以利用负值,因此我们可以将评分规范化为平均值为 0 且标准差为 1。这种规范化确保评分一致且以零为中心,从而实现准确的相似性计算。在这种情况下,我们可以考虑我们不喜欢的电影。
ratings.rating = (ratings.rating - ratings.rating.mean()) / ratings.rating.std()
获取结果
ratings.head()
数据准备
现在您将用户评分转换为稀疏向量,其中每个向量代表不同电影的评分。此步骤为在 Qdrant 中索引数据做准备。
首先,创建一个配置了稀疏向量的集合。对于稀疏向量,您无需指定维度,因为它会从数据中自动提取。
from collections import defaultdict
user_sparse_vectors = defaultdict(lambda: {"values": [], "indices": []})
for row in ratings.itertuples():
user_sparse_vectors[row.user_id]["values"].append(row.rating)
user_sparse_vectors[row.user_id]["indices"].append(row.movie_id)
连接到 Qdrant 并创建一个名为 movielens 的集合
client = QdrantClient(
url = os.getenv("QDRANT_HOST"),
api_key = os.getenv("QDRANT_API_KEY")
)
client.create_collection(
"movielens",
vectors_config={},
sparse_vectors_config={
"ratings": models.SparseVectorParams()
}
)
将用户评分作为稀疏向量以及用户元数据上传到 Qdrant 中的 movielens 集合。此步骤用生成推荐所需的数据填充数据库。
def data_generator():
for user in users.itertuples():
yield models.PointStruct(
id=user.user_id,
vector={
"ratings": user_sparse_vectors[user.user_id]
},
payload=user._asdict()
)
client.upload_points(
"movielens",
data_generator()
)
推荐
指定个人电影评分,其中正评分表示喜欢,负评分表示不喜欢。这些评分作为寻找具有相似品味的相似用户的基础。
个人评分被转换为适用于查询 Qdrant 的稀疏向量表示。此向量代表用户对不同电影的偏好。
让我们尝试为自己推荐一些东西
1 = Like
-1 = dislike
# Search with movies[movies.title.str.contains("Matrix", case=False)].
my_ratings = {
2571: 1, # Matrix
329: 1, # Star Trek
260: 1, # Star Wars
2288: -1, # The Thing
1: 1, # Toy Story
1721: -1, # Titanic
296: -1, # Pulp Fiction
356: 1, # Forrest Gump
2116: 1, # Lord of the Rings
1291: -1, # Indiana Jones
1036: -1 # Die Hard
}
inverse_ratings = {k: -v for k, v in my_ratings.items()}
def to_vector(ratings):
vector = models.SparseVector(
values=[],
indices=[]
)
for movie_id, rating in ratings.items():
vector.values.append(rating)
vector.indices.append(movie_id)
return vector
查询 Qdrant 以根据提供的个人评分查找具有相似品味的用户。搜索返回相似用户及其评分的列表,从而促进协同过滤。
results = client.query_points(
"movielens",
query=to_vector(my_ratings),
using="ratings",
with_vectors=True, # We will use those to find new movies
limit=20
).points
电影评分根据每部电影在相似用户评分中出现的频率及其评分权重进行计算。此步骤识别具有相似品味的用户中受欢迎的电影。计算每部电影在相似用户评分中出现的频率
def results_to_scores(results):
movie_scores = defaultdict(lambda: 0)
for user in results:
user_scores = user.vector['ratings']
for idx, rating in zip(user_scores.indices, user_scores.values):
if idx in my_ratings:
continue
movie_scores[idx] += rating
return movie_scores
评分最高的电影根据其评分进行排序,并作为推荐打印给用户。这些推荐根据用户的偏好量身定制,并与他们的品味保持一致。按评分对电影进行排序并打印前五名
movie_scores = results_to_scores(results)
top_movies = sorted(movie_scores.items(), key=lambda x: x[1], reverse=True)
for movie_id, score in top_movies[:5]:
print(movies[movies.movie_id == movie_id].title.values[0], score)
结果
Star Wars: Episode V - The Empire Strikes Back (1980) 20.02387858
Star Wars: Episode VI - Return of the Jedi (1983) 16.443184379999998
Princess Bride, The (1987) 15.840068229999996
Raiders of the Lost Ark (1981) 14.94489462
Sixth Sense, The (1999) 14.570322149999999