RAG 中使用 Qdrant 向量数据库进行重排
在检索增强生成 (RAG) 系统中,不相关或缺失的信息会影响模型生成准确、有意义输出的能力。确保为语言模型提供最相关、上下文最丰富的文档的最佳方法之一就是通过重排。这是一个颠覆性的技术。
在本指南中,我们将深入探讨如何使用重排来提高 Qdrant 中搜索结果的相关性。我们将从一个利用 Cohere 重排模型的简单用例开始。然后,我们将通过探索 ColBERT 来提升一个层次,采用更高级的方法。完成本指南后,你将知道如何实现混合搜索、微调重排模型并显著提高准确性。
准备好了吗?让我们开始吧。
理解重排
本节分为几个关键部分,旨在帮助你轻松掌握重排的背景、机制和重要性。
背景
在搜索系统中,精确率(precision)和召回率(recall)这两个指标是成功的关键支柱。但它们是什么意思呢?精确率告诉我们检索到的结果中有多少是真正相关的,而召回率衡量的是我们捕获了所有相关结果的程度。简单来说

稀疏向量搜索通常具有较高的精确率,因为它们擅长查找精确匹配项。但是,问题在于——当相关文档不包含这些精确关键词时,你的召回率可能会受到影响。另一方面,密集向量搜索对于召回率来说是极好的,因为它们能捕捉查询的更广泛的语义含义。然而,这可能导致精确率降低,你可能会看到一些仅松散相关的结果。
这正是重排发挥作用的地方。它首先获取大量文档(提供高召回率),然后根据相关性得分重新排序靠前的候选项,从而在不损失广泛理解能力的情况下提高精确率。通常,我们在重排后只保留前 K 个候选项,以专注于最相关的结果。
工作原理
想象一下:你走进一家大型图书馆,询问关于“气候变化”的书。图书馆员为你找出了十几本书——有些是科学论文,有些是个人散文,还有一本甚至是小说。当然,它们都相关,但你拿到的第一本却是小说。这和你期望的并不完全一样,对吗?
现在,想象一位更聪明、更有洞察力的图书馆员,他真正理解你的需求。这位图书馆员清楚地知道哪些书最有影响力、最新,并且最符合你的需求。这就是重排对你的搜索结果所做的事情——它不仅仅是找到任何相关的文档;它会智能地重新排序它们,以便将最好的文档放在列表顶部。这就像拥有一个在你开口之前就知道你想要什么的图书馆员!
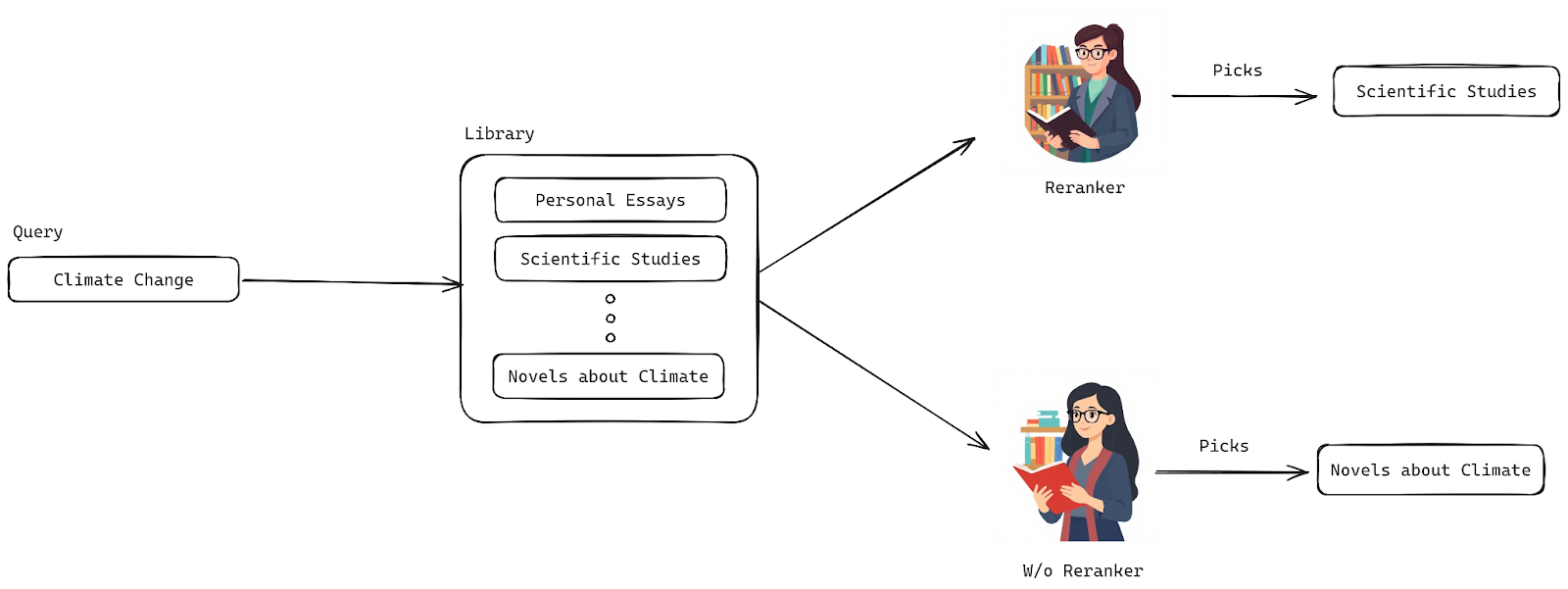
重排模型优先显示更好结果的示意图
要成为那位聪明、有洞察力的图书馆员,你的算法需要学习如何理解你的查询以及它检索到的文档。它必须有效地评估它们之间的关系,这样才能为你提供你想要的东西。
重排模型的运作方式因类型而异(稍后将讨论),但通常,它们会为每个文档-查询对计算一个相关性得分。与提前将所有内容压缩到单个向量中的嵌入模型不同,重排器通过使用完整的 Transformer 输出计算相似性得分来保留所有重要细节。结果如何?精确率更高。但是,也存在权衡——重排可能很慢。处理数百万文档可能需要数小时,这就是为什么重排器专注于优化结果,而不是搜索整个文档集的原因。
重排器有不同类型,每种都有自己的优势。让我们来分解一下:
- 交叉编码器模型(Cross Encoder Models):这些模型通过使用分类系统评估数据对(如句子或文档)来增强重排。它们输出一个从 0 到 1 的相似性得分,表示文档与查询的匹配程度。缺点是什么?交叉编码器需要同时输入查询和文档,因此它们无法单独处理文档或查询。
- 多向量重排器(Multi-Vector Rerankers,例如 ColBERT):这些模型采用更高效的方法。它们单独编码查询和文档,只在稍后进行比较,从而降低计算负担。这意味着文档表示可以预先计算,从而加快检索时间。
- 大型语言模型(LLMs)作为重排器:这是一种更新、更智能的重排方法。LLMs,如 GPT,每天都在变得更好。通过正确的指令,它们可以为你优先显示最相关的文档,利用其庞大的语言理解能力来提供更准确的结果。
这些重排器中的每一种都有其独特的方式来确保你获得最佳搜索结果,快速且与你的需求相关。
重要性
在前一节中,我们探讨了重排的背景和机制,但现在让我们谈谈使用重排带来的三大优势:
- 提高搜索准确性:重排旨在使你的搜索结果更精准、更相关。在初始排序之后,重排器介入,基于更深入的分析重新排列结果,确保最关键的信息排在前面和中心位置。研究表明,重排器可以实现显著的提升——提高大约 72% 的搜索查询的顶部结果。这是精确率上的巨大飞跃。
- 减少信息过载:如果你感觉自己淹没在搜索结果的海洋中,重排器可以来拯救你。它们过滤和微调大量信息,让你准确获得所需内容,而不会感到不知所措。这使得你的搜索体验更专注,混乱程度大大降低。
- 平衡速度和相关性:第一阶段检索和第二阶段重排在速度和准确性之间实现了完美的平衡。当然,第二阶段由于其处理能力可能会增加一些延迟,但这种权衡是值得的。你获得了高度相关的结果,而最终,这才是最重要的。
既然你知道了为什么重排是如此颠覆性的技术,让我们深入探讨实践方面的内容。
实现带有重排功能的向量搜索
在本节中,你将了解如何使用 Cohere 实现带有重排功能的向量搜索。但首先,让我们分解一下。
概述
一个典型的搜索系统包含两个主要阶段:摄取(Ingestion)和检索(Retrieval)。可以将摄取视为数据准备和加载到系统的过程,而检索则是奇迹发生的部分——你的查询从中拉出最相关的文档。
请查看下面的架构图,以了解这些阶段如何协同工作。
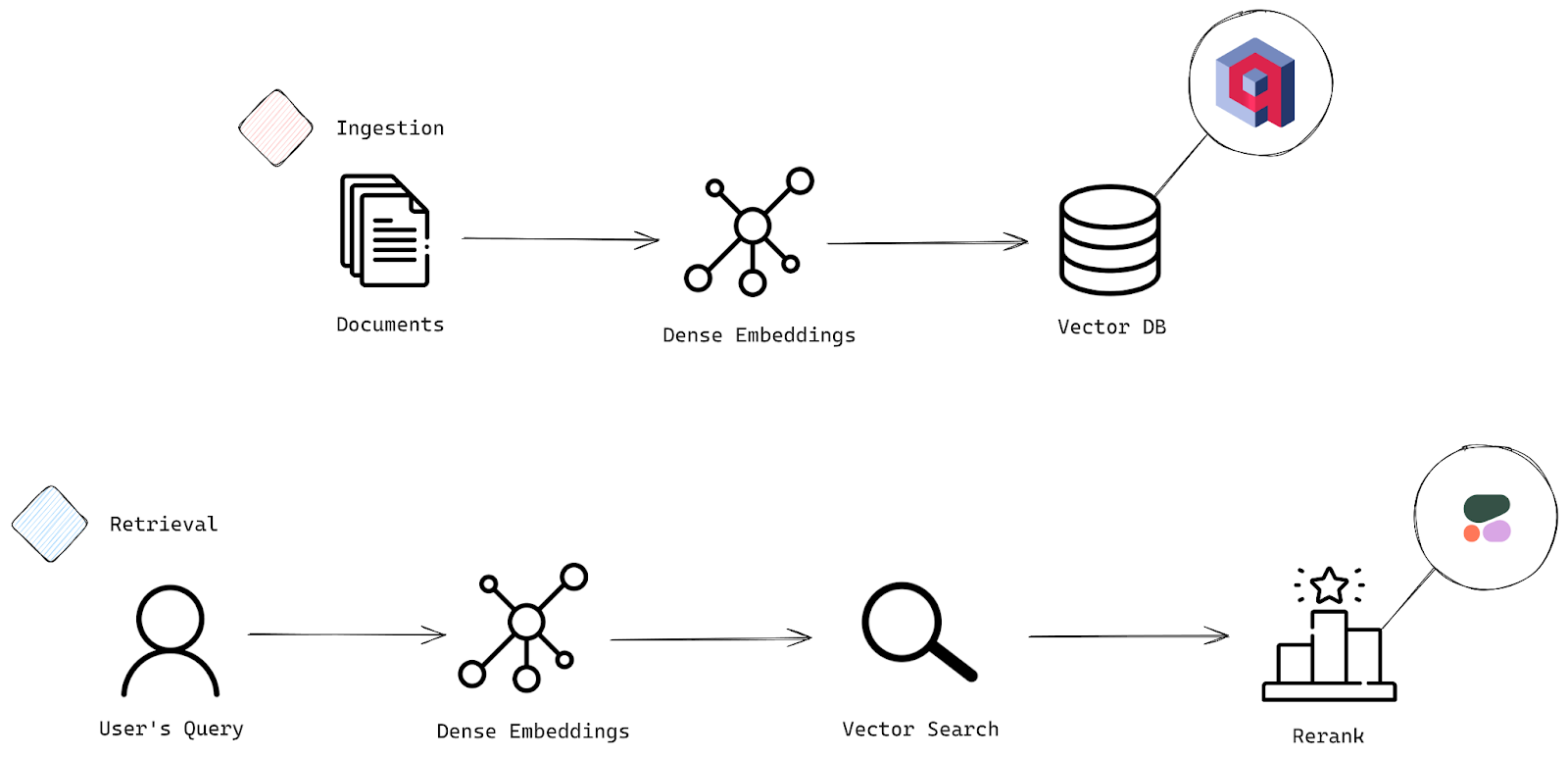
搜索系统的两个关键阶段:摄取和检索过程
摄取阶段
- 文档:一切都从这里开始。系统接收需要准备用于搜索的原始数据或文档——这是你的初始输入。
- 嵌入向量(Embeddings):接下来,这些文档被转换为稀疏或密集嵌入向量,它们本质上是向量表示。这些向量捕捉文本深层、潜在的含义,使你的系统能够基于语义意义执行智能、高效的搜索和比较。
- 向量数据库(Vector Database):一旦你的文档被转换为这些嵌入向量,它们就会存储在向量数据库中——这基本上是快速、准确的相似性搜索背后的核心力量。在这里,我们将看到 Qdrant 向量数据库的功能。
检索阶段
- 用户查询(User’s Query):现在进入检索阶段。用户提交一个查询,是时候将该查询与存储的文档进行匹配了。
- 嵌入向量:就像处理文档一样,用户的查询也被转换为稀疏或密集嵌入向量。这使得系统能够将查询的含义与存储文档的含义进行比较。
- 向量搜索(Vector Search):系统通过比较查询的嵌入向量与向量数据库中的嵌入向量,来搜索最相关的文档,并找出最接近的匹配项。
- 重排(Rerank):一旦初始结果出来,重排过程就会启动,以确保你获得最好的结果并排在前面。我们将使用 Cohere 的 rerank-english-v3.0 模型,该模型擅长重新排列英语文档以优先考虑相关性。它可以处理多达 4096 个 token,提供充足的上下文。如果你处理的是多语言数据,不用担心——Cohere 也提供了其他语言的重排模型。
实现
现在是时候深入了解实际实现了。
设置
要跟随本教程进行操作,你需要准备几个关键工具:
- Qdrant 的 Python 客户端
- Cohere
让我们使用 Python 包管理器一次性安装所有必需的组件:
pip install qdrant-client cohere
现在,让我们在一个整洁的代码块中导入所有必需的组件:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
import cohere
Qdrant 是一个强大的向量相似性搜索引擎,它提供了一个生产就绪的服务,具有易于使用的 API,用于存储、搜索和管理数据。你可以通过本地或云端设置与 Qdrant 交互,但由于我们在 Colab 中工作,让我们选择云端设置。
设置 Qdrant Cloud 的步骤
- 注册:前往 Qdrant 网站,使用你的电子邮件、Google 或 GitHub 凭据注册云账户。
- 创建你的第一个集群:登录后,导航到“概述”部分,并按照“创建第一个集群”下的引导步骤操作。
- 获取你的 API 密钥:创建集群后,将生成一个 API 密钥。此密钥将允许你使用 Python 客户端与集群交互。
- 检查你的集群:你的新集群将出现在“集群”部分下。至此,你已准备好开始与数据进行交互。
最后,在“概述”部分下,你将看到以下代码片段:
Qdrant 概述部分
添加你的 API 密钥。这将允许你的 Python 客户端连接到 Qdrant 和 Cohere。
client = QdrantClient(
url="<ADD-URL>",
api_key="<API-KEY>",
)
print(client.get_collections())
接下来,我们将设置 Cohere 进行重排。登录你的 Cohere 账户,生成一个 API 密钥,并像这样添加它:
co = cohere.Client("<API-KEY>")
摄取
摄取过程包含三个关键部分:创建集合(Collection)、将文档转换为嵌入向量(Embeddings)和 Upsert 数据。让我们分解一下。
创建集合
集合基本上是一个命名的点组(带有数据的向量),你可以通过它进行搜索。集合中的所有向量需要具有相同的大小,并使用一个距离度量进行比较。创建方法如下:
client.create_collection(
collection_name="basic-search-rerank",
vectors_config=VectorParams(size=1024, distance=Distance.DOT),
)
这里,向量大小设置为 1024,以匹配我们的密集嵌入向量,我们使用点积作为距离度量——这非常适合捕捉向量之间的相似性,尤其是在它们被归一化之后。
将文档转换为嵌入向量
让我们设置一些示例数据。这里有一个查询和一些用于演示的文档:
query = "What is the purpose of feature scaling in machine learning?"
documents = [
"In machine learning, feature scaling is the process of normalizing the range of independent variables or features. The goal is to ensure that all features contribute equally to the model, especially in algorithms like SVM or k-nearest neighbors where distance calculations matter.",
"Feature scaling is commonly used in data preprocessing to ensure that features are on the same scale. This is particularly important for gradient descent-based algorithms where features with larger scales could disproportionately impact the cost function.",
"In data science, feature extraction is the process of transforming raw data into a set of engineered features that can be used in predictive models. Feature scaling is related but focuses on adjusting the values of these features.",
"Unsupervised learning algorithms, such as clustering methods, may benefit from feature scaling as it ensures that features with larger numerical ranges don't dominate the learning process.",
"One common data preprocessing technique in data science is feature selection. Unlike feature scaling, feature selection aims to reduce the number of input variables used in a model to avoid overfitting.",
"Principal component analysis (PCA) is a dimensionality reduction technique used in data science to reduce the number of variables. PCA works best when data is scaled, as it relies on variance which can be skewed by features on different scales.",
"Min-max scaling is a common feature scaling technique that usually transforms features to a fixed range [0, 1]. This method is useful when the distribution of data is not Gaussian.",
"Standardization, or z-score normalization, is another technique that transforms features into a mean of 0 and a standard deviation of 1. This method is effective for data that follows a normal distribution.",
"Feature scaling is critical when using algorithms that rely on distances, such as k-means clustering, as unscaled features can lead to misleading results.",
"Scaling can improve the convergence speed of gradient descent algorithms by preventing issues with different feature scales affecting the cost function's landscape.",
"In deep learning, feature scaling helps in stabilizing the learning process, allowing for better performance and faster convergence during training.",
"Robust scaling is another method that uses the median and the interquartile range to scale features, making it less sensitive to outliers.",
"When working with time series data, feature scaling can help in standardizing the input data, improving model performance across different periods.",
"Normalization is often used in image processing to scale pixel values to a range that enhances model performance in computer vision tasks.",
"Feature scaling is significant when features have different units of measurement, such as height in centimeters and weight in kilograms.",
"In recommendation systems, scaling features such as user ratings can improve the model's ability to find similar users or items.",
"Dimensionality reduction techniques, like t-SNE and UMAP, often require feature scaling to visualize high-dimensional data in lower dimensions effectively.",
"Outlier detection techniques can also benefit from feature scaling, as they can be influenced by unscaled features that have extreme values.",
"Data preprocessing steps, including feature scaling, can significantly impact the performance of machine learning models, making it a crucial part of the modeling pipeline.",
"In ensemble methods, like random forests, feature scaling is not strictly necessary, but it can still enhance interpretability and comparison of feature importance.",
"Feature scaling should be applied consistently across training and test datasets to avoid data leakage and ensure reliable model evaluation.",
"In natural language processing (NLP), scaling can be useful when working with numerical features derived from text data, such as word counts or term frequencies.",
"Log transformation is a technique that can be applied to skewed data to stabilize variance and make the data more suitable for scaling.",
"Data augmentation techniques in machine learning may also include scaling to ensure consistency across training datasets, especially in computer vision tasks."
]
我们将为这些文档生成嵌入向量,使用 Cohere 的 embed-english-v3.0 模型,该模型生成 1024 维向量:
model="embed-english-v3.0"
doc_embeddings = co.embed(texts=documents,
model=model,
input_type="search_document",
embedding_types=['float'])
这段代码利用了 Cohere API 的强大功能,为你的文档列表生成嵌入向量。它使用 embed-english-v3.0 模型,将输入类型设置为“search_document”,并要求以浮点格式提供嵌入向量。结果如何?一组密集嵌入向量,每个都代表你的文档的深层语义含义。这些嵌入向量将存储在 doc_embeddings 中,随时可用。
Upsert 数据
我们需要将这些密集嵌入向量转换为 Qdrant 可以处理的格式,这就是点(Points)的作用所在。点是 Qdrant 的基本构建块——它们是由向量(即嵌入向量)和可选载荷(如文档文本)组成的记录。
下面介绍如何将这些嵌入向量转换为点:
points = []
for idx, (embedding, doc) in enumerate(zip(doc_embeddings.embeddings.float_, documents)):
point = PointStruct(
id=idx,
vector=embedding,
payload={"document": doc}
)
points.append(point)
这里发生了什么?我们正在从嵌入向量构建一个点列表:
- 首先,我们从一个空列表开始。
- 然后,我们同时遍历 doc_embeddings 和 documents,使用 enumerate() 沿途获取索引 (idx)。
- 对于每一对(一个嵌入向量及其对应的文档),我们创建一个 PointStruct。每个点包含:
- 一个 id(来自 idx)。
- 一个向量(即嵌入向量)。
- 一个载荷(即实际文档文本)。
- 每个点都被添加到我们的列表中。
完成此步骤后,就可以使用 upsert() 函数将这些点发送到你的 Qdrant 集合中:
operation_info = client.upsert(
collection_name="basic-search-rerank",
points=points
)
现在你的嵌入向量已全部设置到 Qdrant 中,可以为你的搜索提供支持了。
检索
这里的前几个步骤与摄取阶段的操作类似——就像之前一样,我们需要将查询转换为嵌入向量:
query_embeddings = co.embed(texts=[query],
model=model,
input_type="search_query",
embedding_types=['float'])
之后,我们将继续使用向量搜索检索结果,并对结果应用重排。这个两阶段过程非常高效,因为我们首先获取一小组最相关的文档,这比重排整个大型数据集快得多。
向量搜索
此代码片段使用查询嵌入向量从你的 Qdrant 集合中获取前 10 个最相关的点。
search_result = client.query_points(
collection_name="basic-search-rerank", query=query_embeddings.embeddings.float_[0], limit=10
).points
工作原理如下:我们使用 query_points 方法在“basic-search-rerank”集合中进行搜索。它将查询嵌入向量(query_embeddings 中的第一个嵌入向量)与所有文档嵌入向量进行比较,找出 10 个最接近的匹配项。匹配的点存储在 search_result 中。
以下是向量搜索结果的预览:
| ID | 文档 | 得分 |
|---|---|---|
| 0 | 在机器学习中,特征缩放是独立变量范围归一化的过程…… | 0.71 |
| 10 | 在深度学习中,特征缩放有助于稳定学习过程,从而…… | 0.69 |
| 1 | 特征缩放常用于数据预处理中,以确保特征处于同一…… | 0.68 |
| 23 | 机器学习中的数据增强技术也可能包括缩放,以确保…… | 0.64 |
| 3 | 无监督学习算法,如聚类方法,可能会受益于特征…… | 0.64 |
| 12 | 处理时间序列数据时,特征缩放有助于标准化输入…… | 0.62 |
| 19 | 在集成方法中,如随机森林,特征缩放并非严格必要…… | 0.61 |
| 21 | 在自然语言处理 (NLP) 中,处理数值……时,缩放可能会很有用。 | 0.61 |
| 20 | 特征缩放应在训练集和测试集上一致应用…… | 0.61 |
| 18 | 数据预处理步骤,包括特征缩放,可以显著影响性能…… | 0.61 |
从结果来看,检索到的数据与你的查询高度相关。现在,有了这个坚实的结果基础,是时候通过重排进一步优化它们了。
重排
这段代码提取搜索结果中的文档,并根据你的查询对它们进行重排,确保最相关的文档排在最前面。
首先,我们从搜索结果中提取文档。然后我们使用 Cohere 的重排模型来优化这些结果:
document_list = [point.payload['document'] for point in search_result]
rerank_results = co.rerank(
model="rerank-english-v3.0",
query=query,
documents=document_list,
top_n=5,
)
这里发生了什么?在第一行,我们通过从每个搜索结果点中获取‘document’字段来构建一个文档列表。然后,我们将这个列表连同原始查询一起传递给 Cohere 的 rerank 方法。使用 rerank-english-v3.0 模型,它会重新排列文档,并返回排名前 5 的结果,按它们与查询的相关性排序。
以下是重排后的结果表格,包含新的顺序及其相关性得分:
| 索引 | 文档 | 相关性得分 |
|---|---|---|
| 0 | 在机器学习中,特征缩放是独立变量或特征范围归一化的过程。 | 0.99995166 |
| 1 | 特征缩放常用于数据预处理中,以确保特征处于同一尺度。 | 0.99929035 |
| 10 | 在深度学习中,特征缩放有助于稳定学习过程,从而实现更好的性能和更快的收敛。 | 0.998675 |
| 23 | 机器学习中的数据增强技术也可能包括缩放,以确保训练数据集之间的一致性。 | 0.998043 |
| 3 | 无监督学习算法,如聚类方法,可能会受益于特征缩放。 | 0.9979967 |
如你所见,重排发挥了作用。文档 10 和 1 的位置发生了对调,这表明重排器已经对结果进行了微调,以便将最相关的内容呈现在最前面。
结论
重排是提高 RAG 系统中搜索结果相关性和精确率的强大方法。通过将 Qdrant 的向量搜索能力与 Cohere 的重排模型或 ColBERT 等工具相结合,你可以优化搜索输出,确保最相关的信息排在最前面。
本指南展示了重排如何在不牺牲召回率的情况下提高精确率,提供更精准、上下文更丰富的结果。有了这些工具,你就可以构建搜索系统,提供有意义且有影响力的用户体验。开始实现重排,将你的应用提升到新的水平!