通过 Confluent 使用 Kafka 设置数据流
作者: M K Pavan Kumar,IIITDM 库努尔分校研究学者。专注于幻觉缓解技术和 RAG 方法。• GitHub • Medium
简介
本指南将引导您详细了解安装和设置 Qdrant Sink Connector、构建必要基础设施以及创建实用实验应用程序的步骤。通过本文,您将深入了解如何利用这种强大的集成来简化数据工作流,最终增强数据驱动的实时语义搜索和 RAG 应用程序的性能和功能。
在此示例中,原始数据将来自 Azure Blob 存储和 MongoDB。
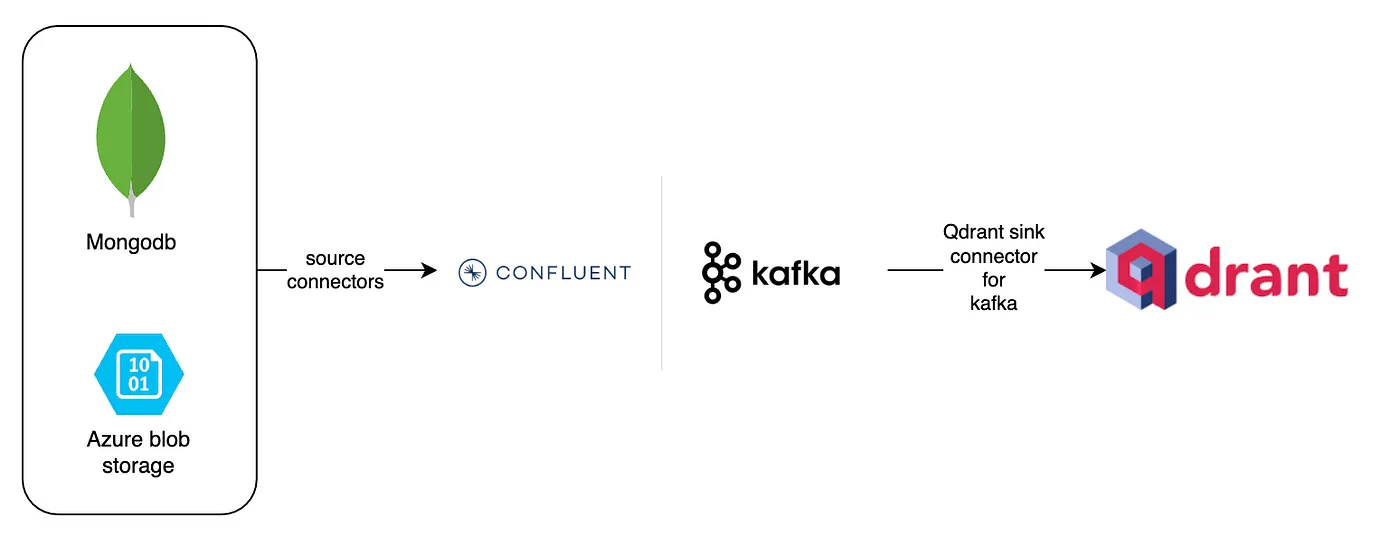
图 1:使用 Kafka 和 Qdrant 进行实时变更数据捕获 (CDC)。
架构
源系统
该架构始于源系统,由 MongoDB 和 Azure Blob 存储表示。这些系统对于存储和管理原始数据至关重要。MongoDB 是一种流行的 NoSQL 数据库,以其处理各种数据格式的灵活性和横向扩展能力而闻名。它广泛用于需要高性能和可扩展性的应用程序。另一方面,Azure Blob 存储是微软的云对象存储解决方案。它设计用于存储大量的非结构化数据,例如文本或二进制数据。通过源连接器提取这些源的数据,这些连接器负责实时捕获更改并将其流式传输到 Kafka。
Kafka
该架构的核心是 Kafka,一个分布式事件流平台,每天能够处理数万亿个事件。Kafka 充当中心枢纽,可以从各种源中获取数据,进行处理,并分发到各种下游系统。其容错和可扩展设计确保数据能够可靠地实时传输和处理。Kafka 处理高吞吐量、低延迟数据流的能力使其成为实时数据处理和分析的理想选择。使用 Confluent 增强了 Kafka 的功能,为管理 Kafka 集群和流处理提供了额外的工具和服务。
Qdrant
然后,处理后的数据被路由到 Qdrant,一个专为相似性搜索设计的高度可扩展的向量搜索引擎。Qdrant 擅长管理和搜索高维向量数据,这对于涉及机器学习和 AI 的应用程序(例如推荐系统、图像识别和自然语言处理)至关重要。Kafka 的 Qdrant Sink Connector 在此发挥关键作用,实现 Kafka 和 Qdrant 之间的无缝集成。此连接器允许将向量数据实时摄入 Qdrant,确保数据始终是最新的,并可用于高性能相似性搜索。
集成和管道的重要性
这些组件的集成形成了一个强大而高效的数据流管道。Qdrant Sink Connector 确保流经 Kafka 的数据持续摄入 Qdrant,无需任何手动干预。这种实时集成对于依赖最新数据进行决策和分析的应用程序至关重要。通过结合 MongoDB 和 Azure Blob 存储的数据存储优势、Kafka 的数据流传输优势以及 Qdrant 的向量搜索优势,该管道为实时管理和处理大量数据提供了强大的解决方案。该架构的可扩展性、容错性和实时处理能力是其有效性的关键,使其成为现代数据驱动应用程序的多功能解决方案。
Confluent Kafka 平台安装
要安装 Confluent Kafka 平台(本地自管理),请遵循以下 3 个简单步骤
下载并解压分发文件
- 访问 Confluent 安装页面。
- 下载分发文件(tar、zip 等)。
- 使用以下命令解压下载的文件
tar -xvf confluent-<version>.tar.gz
或者
unzip confluent-<version>.zip
配置环境变量
# Set CONFLUENT_HOME to the installation directory:
export CONFLUENT_HOME=/path/to/confluent-<version>
# Add Confluent binaries to your PATH
export PATH=$CONFLUENT_HOME/bin:$PATH
在本地运行 Confluent 平台
# Start the Confluent Platform services:
confluent local start
# Stop the Confluent Platform services:
confluent local stop
Qdrant 安装
要在本地安装和运行 Qdrant(自管理),您可以使用 Docker,这简化了过程。首先,请确保您的系统上已安装 Docker。然后,您可以使用以下命令从 Docker Hub 拉取 Qdrant 镜像并运行它
docker pull qdrant/qdrant
docker run -p 6334:6334 -p 6333:6333 qdrant/qdrant
这将下载 Qdrant 镜像并启动一个 Qdrant 实例,可在 https://:6333 访问。有关更详细的说明和替代安装方法,请参阅 Qdrant 安装文档。
Qdrant-Kafka Sink 连接器安装
要使用 Confluent Hub 安装 Qdrant Kafka 连接器,您可以使用简单的 confluent-hub install 命令。此命令通过消除手动配置文件操作的需要来简化过程。要安装 Qdrant Kafka 连接器版本 1.1.0,请在终端中执行以下命令
confluent-hub install qdrant/qdrant-kafka:1.1.0
此命令直接从 Confluent Hub 下载并将指定的连接器安装到您的 Confluent Platform 或 Kafka Connect 环境中。安装过程确保自动处理所有必要的依赖项,从而实现 Qdrant Kafka 连接器与您现有设置的无缝集成。安装后,可以使用 Confluent Control Center 或 Kafka Connect REST API 配置和管理连接器,从而在 Kafka 和 Qdrant 之间实现高效的数据流,而无需复杂的 manual 设置。
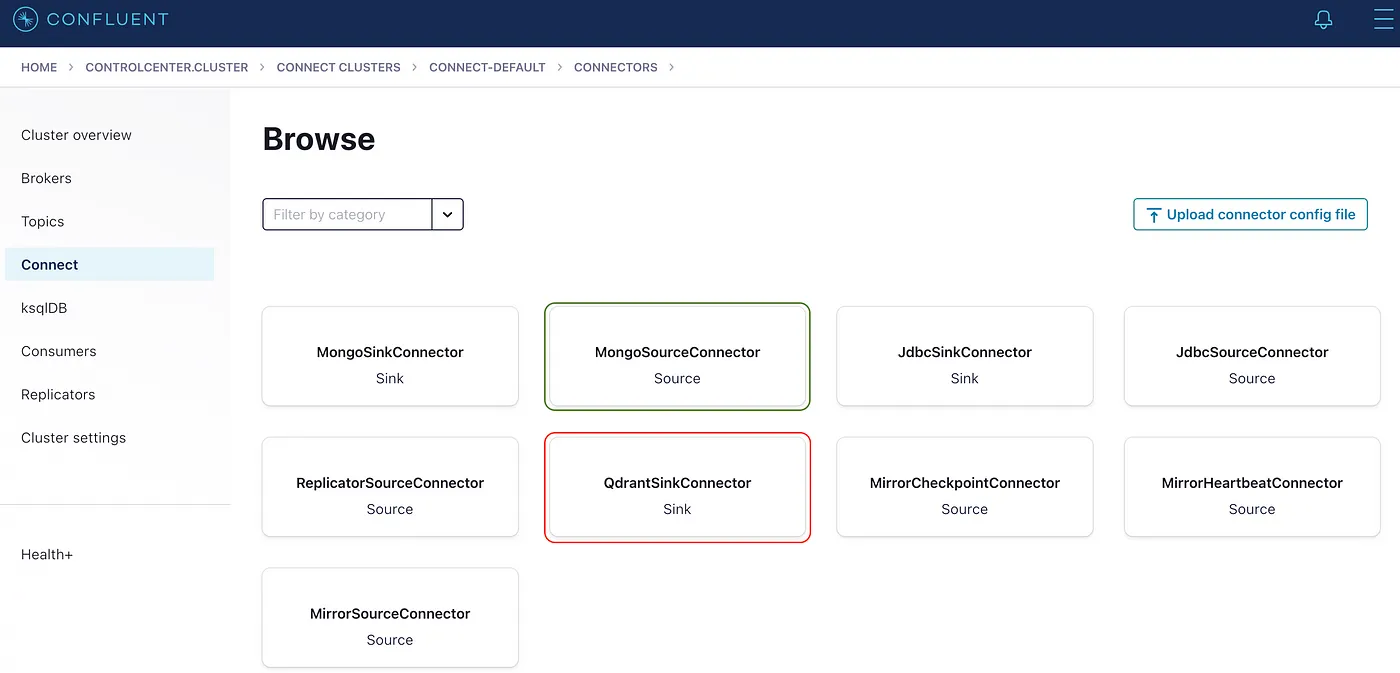
图 2:本地 Confluent 平台显示安装后的 Source 和 Sink 连接器。
安装连接器后,请确保按如下方式配置。请记住,您的 key.converter 和 value.converter 对于 Kafka 将消息从主题安全地传递到 Qdrant 非常重要。
{
"name": "QdrantSinkConnectorConnector_0",
"config": {
"value.converter.schemas.enable": "false",
"name": "QdrantSinkConnectorConnector_0",
"connector.class": "io.qdrant.kafka.QdrantSinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"topics": "topic_62,qdrant_kafka.docs",
"errors.deadletterqueue.topic.name": "dead_queue",
"errors.deadletterqueue.topic.replication.factor": "1",
"qdrant.grpc.url": "https://:6334",
"qdrant.api.key": "************"
}
}
MongoDB 安装
为了让 Kafka 将 MongoDB 作为源连接,您的 MongoDB 实例应该以 replicaSet 模式运行。下面是 docker compose 文件,它将启动一个单节点 replicaSet 模式的 MongoDB 实例。
version: "3.8"
services:
mongo1:
image: mongo:7.0
command: ["--replSet", "rs0", "--bind_ip_all", "--port", "27017"]
ports:
- 27017:27017
healthcheck:
test: echo "try { rs.status() } catch (err) { rs.initiate({_id:'rs0',members:[{_id:0,host:'host.docker.internal:27017'}]}) }" | mongosh --port 27017 --quiet
interval: 5s
timeout: 30s
start_period: 0s
start_interval: 1s
retries: 30
volumes:
- "mongo1_data:/data/db"
- "mongo1_config:/data/configdb"
volumes:
mongo1_data:
mongo1_config:
同样,按如下方式安装和配置源连接器。
confluent-hub install mongodb/kafka-connect-mongodb:latest
安装 MongoDB 连接器后,连接器配置应如下所示
{
"name": "MongoSourceConnectorConnector_0",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSourceConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"connection.uri": "mongodb://127.0.0.1:27017/?replicaSet=rs0&directConnection=true",
"database": "qdrant_kafka",
"collection": "docs",
"publish.full.document.only": "true",
"topic.namespace.map": "{\"*\":\"qdrant_kafka.docs\"}",
"copy.existing": "true"
}
}
实验应用程序
基础设施设置完成后,现在是时候创建我们的一个简单应用程序并检查我们的设置了。我们应用程序的目标是将数据插入到 MongoDB 中,并最终使用 变更数据捕获 (CDC) 将其摄入 Qdrant。
requirements.txt
fastembed==0.3.1
pymongo==4.8.0
qdrant_client==1.10.1
project_root_folder/main.py
这只是示例代码。然而,它可以根据您的用例扩展到数百万个操作。
from pymongo import MongoClient
from utils.app_utils import create_qdrant_collection
from fastembed import TextEmbedding
collection_name: str = 'test'
embed_model_name: str = 'snowflake/snowflake-arctic-embed-s'
# Step 0: create qdrant_collection
create_qdrant_collection(collection_name=collection_name, embed_model=embed_model_name)
# Step 1: Connect to MongoDB
client = MongoClient('mongodb://127.0.0.1:27017/?replicaSet=rs0&directConnection=true')
# Step 2: Select Database
db = client['qdrant_kafka']
# Step 3: Select Collection
collection = db['docs']
# Step 4: Create a Document to Insert
description = "qdrant is a high available vector search engine"
embedding_model = TextEmbedding(model_name=embed_model_name)
vector = next(embedding_model.embed(documents=description)).tolist()
document = {
"collection_name": collection_name,
"id": 1,
"vector": vector,
"payload": {
"name": "qdrant",
"description": description,
"url": "https://qdrant.org.cn/documentation"
}
}
# Step 5: Insert the Document into the Collection
result = collection.insert_one(document)
# Step 6: Print the Inserted Document's ID
print("Inserted document ID:", result.inserted_id)
project_root_folder/utils/app_utils.py
from qdrant_client import QdrantClient, models
client = QdrantClient(url="https://:6333", api_key="<YOUR_KEY>")
dimension_dict = {"snowflake/snowflake-arctic-embed-s": 384}
def create_qdrant_collection(collection_name: str, embed_model: str):
if not client.collection_exists(collection_name=collection_name):
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(size=dimension_dict.get(embed_model), distance=models.Distance.COSINE)
)
在运行应用程序之前,以下是 MongoDB 和 Qdrant 数据库的状态。
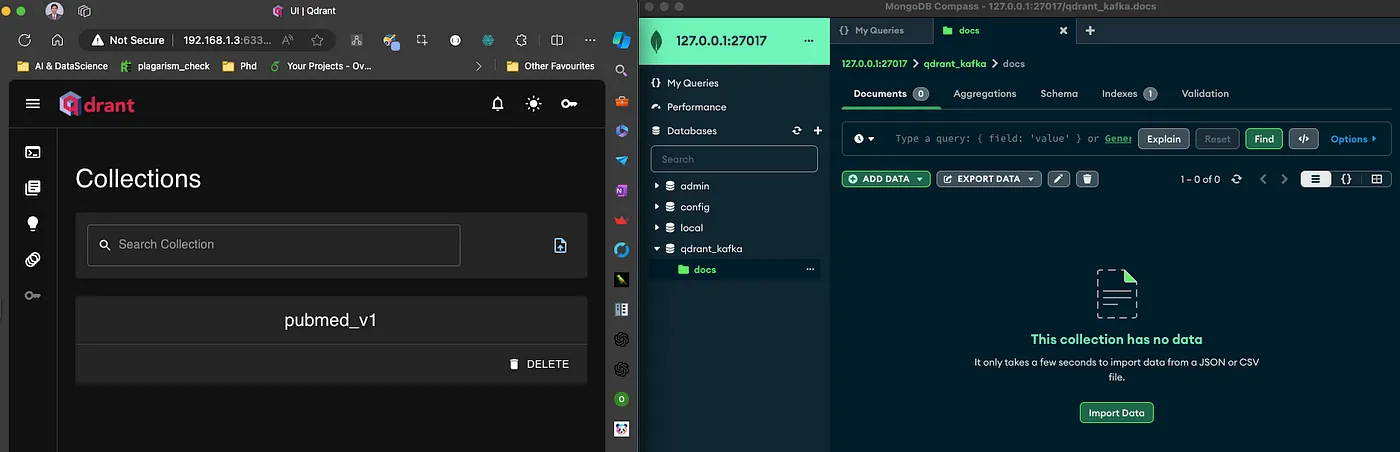
图 3:初始状态:MongoDB 的 docs 集合中没有名为 test 的集合且没有数据。
运行代码后,数据将进入 MongoDB,CDC 将被触发,最终 Qdrant 将接收此数据。
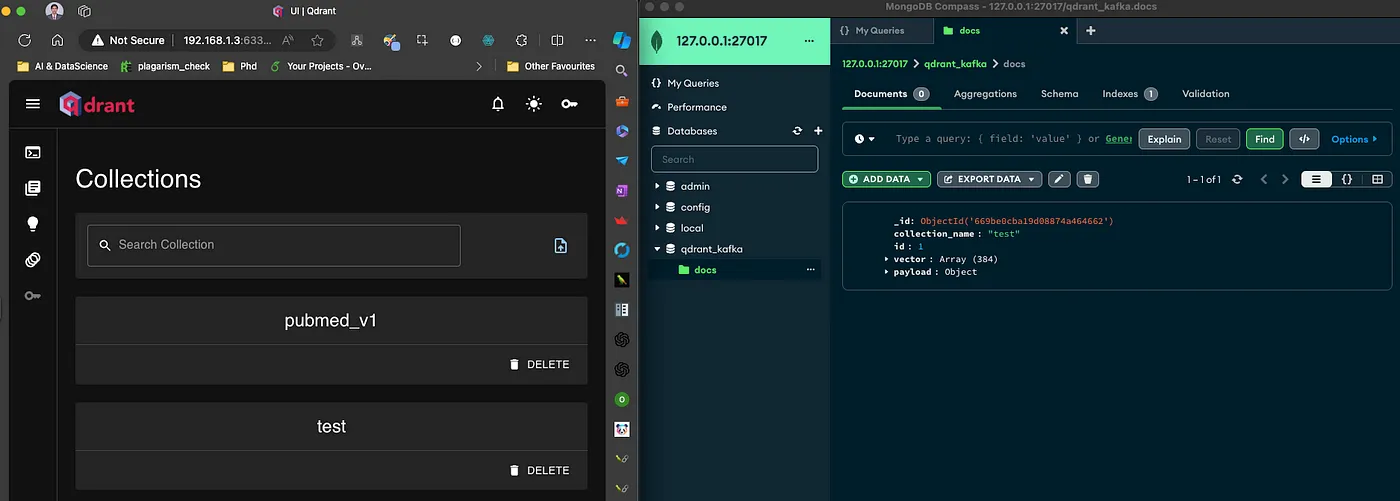
图 4:自动创建 test Qdrant 集合。
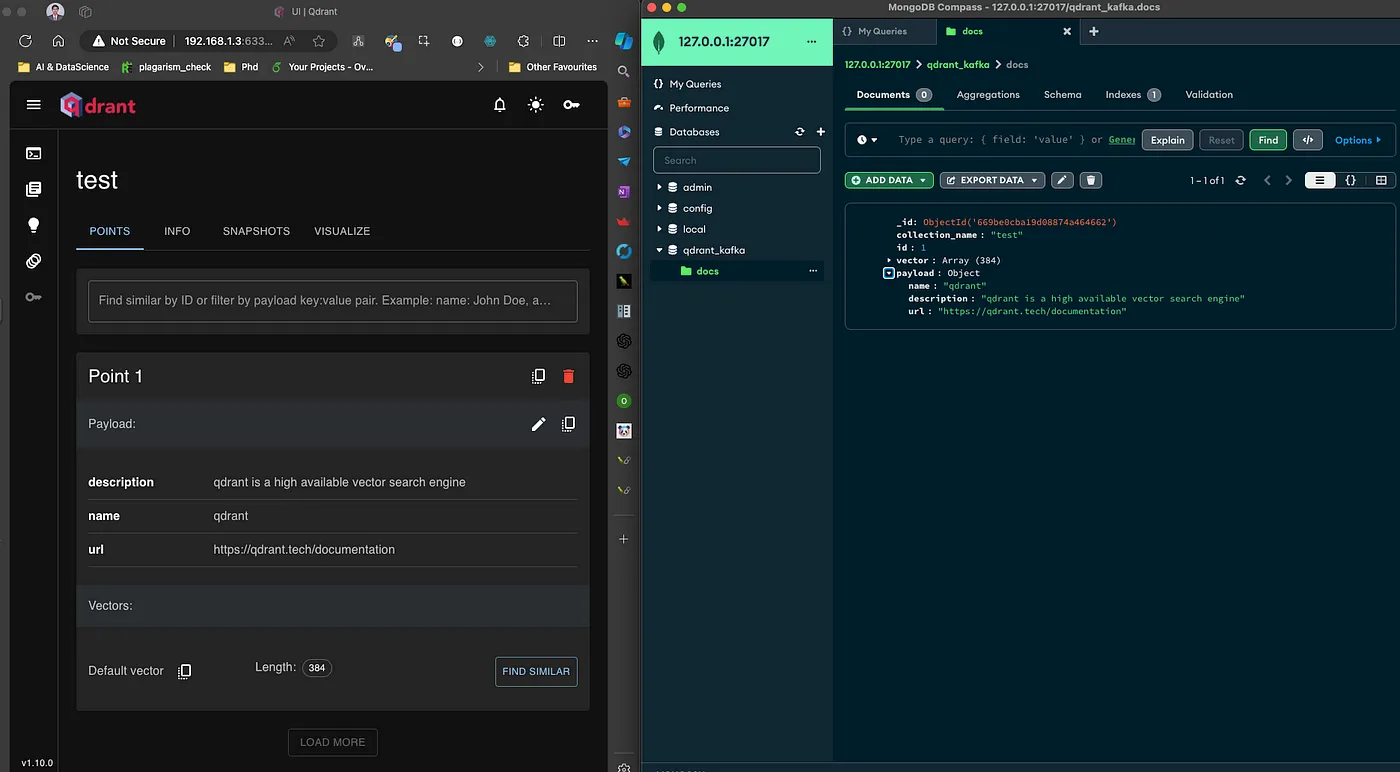
图 5:数据已插入到 MongoDB 和 Qdrant。
结论
总之,使用 Qdrant Sink Connector 将 Kafka 与 Qdrant 集成,为实时数据流和处理提供了一个无缝高效的解决方案。此设置不仅增强了数据管道的功能,还确保高维向量数据持续索引并随时可用于相似性搜索。通过遵循安装和设置指南,您可以轻松建立从 MongoDB 和 Azure Blob Storage 等源系统,通过 Kafka,到 Qdrant 的强大数据流。此架构使现代应用程序能够利用实时数据洞察和高级搜索功能,为创新的数据驱动解决方案铺平道路。