Databricks 上的 Qdrant
| 时长:30 分钟 | 难度:中等 | 完整 Notebook |
|---|
Databricks 是一个用于处理大数据和 AI 的统一分析平台。它基于 Apache Spark 构建,后者是一个强大的开源分布式计算系统,非常适合处理大规模数据集和执行复杂的分析任务。
Apache Spark 设计用于横向扩展,这意味着它可以通过在机器集群上分配计算来处理生成向量嵌入等耗时操作。这种可扩展性在处理大型数据集时至关重要。
在本例中,我们将演示如何使用 Qdrant 的 FastEmbed 库对数据集生成密集和稀疏嵌入。然后,我们将使用 Databricks 上的 Qdrant Spark 连接器 将这些向量化数据加载到 Qdrant 集群中。
设置 Databricks 项目
按照官方文档指南设置一个Databricks 集群。
安装 Qdrant Spark 连接器 作为库
在集群仪表盘中导航到
Libraries(库)部分。点击右上角的
Install New(安装新的)打开库安装模态框。在 Maven 包中搜索
io.qdrant:spark:VERSION并点击Install(安装)。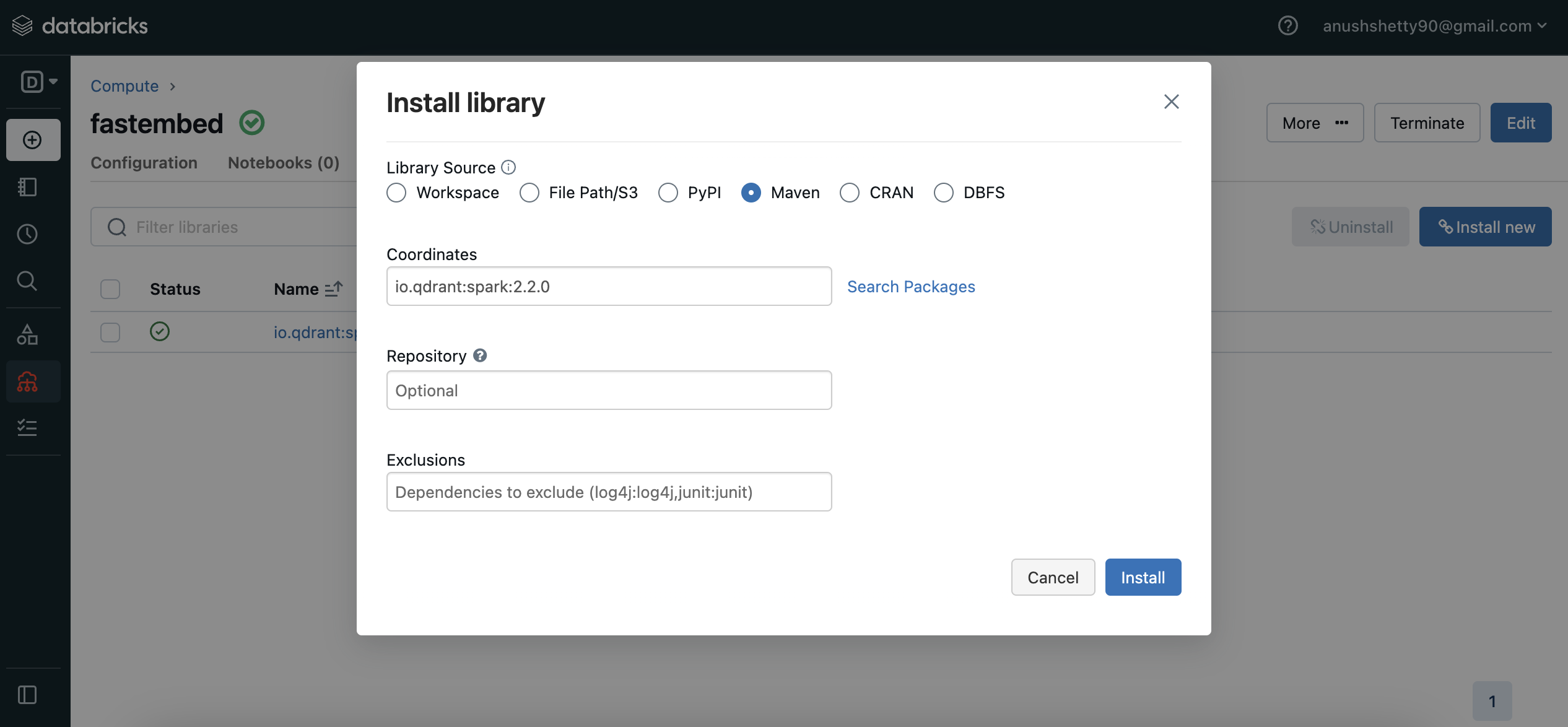
在您的集群上创建一个新的Databricks notebook,开始使用您的数据和库。
下载数据集
- 安装所需的依赖项
%pip install fastembed datasets
- 下载数据集
from datasets import load_dataset
dataset_name = "tasksource/med"
dataset = load_dataset(dataset_name, split="train")
# We'll use the first 100 entries from this dataset and exclude some unused columns.
dataset = dataset.select(range(100)).remove_columns(["gold_label", "genre"])
- 将数据集转换为 Spark 数据框
dataset.to_parquet("/dbfs/pq.pq")
dataset_df = spark.read.parquet("file:/dbfs/pq.pq")
向量化数据
在本节中,我们将使用 FastEmbed 为我们的行生成密集和稀疏向量。我们将创建一个用户自定义函数 (UDF) 来处理此步骤。
创建向量化函数
from fastembed import TextEmbedding, SparseTextEmbedding
def vectorize(partition_data):
# Initialize dense and sparse models
dense_model = TextEmbedding(model_name="BAAI/bge-small-en-v1.5")
sparse_model = SparseTextEmbedding(model_name="Qdrant/bm25")
for row in partition_data:
# Generate dense and sparse vectors
dense_vector = next(dense_model.embed(row.sentence1))
sparse_vector = next(sparse_model.embed(row.sentence2))
yield [
row.sentence1, # 1st column: original text
row.sentence2, # 2nd column: original text
dense_vector.tolist(), # 3rd column: dense vector
sparse_vector.indices.tolist(), # 4th column: sparse vector indices
sparse_vector.values.tolist(), # 5th column: sparse vector values
]
我们使用 BAAI/bge-small-en-v1.5 模型生成密集嵌入,使用 BM25 生成稀疏嵌入。
在数据框上应用 UDF
接下来,将我们的vectorize UDF 应用到 Spark 数据框上以生成嵌入。
embeddings = dataset_df.rdd.mapPartitions(vectorize)
mapPartitions() 方法返回一个 弹性分布式数据集 (RDD),然后应将其转换回 Spark 数据框。
使用向量化数据构建新的 Spark 数据框
现在,我们将使用指定的 schema 构建一个新的 Spark 数据框 (embeddings_df),其中包含向量化数据。
from pyspark.sql.types import StructType, StructField, StringType, ArrayType, FloatType, IntegerType
# Define the schema for the new dataframe
schema = StructType([
StructField("sentence1", StringType()),
StructField("sentence2", StringType()),
StructField("dense_vector", ArrayType(FloatType())),
StructField("sparse_vector_indices", ArrayType(IntegerType())),
StructField("sparse_vector_values", ArrayType(FloatType()))
])
# Create the new dataframe with the vectorized data
embeddings_df = spark.createDataFrame(data=embeddings, schema=schema)
将数据上传到 Qdrant
创建 Qdrant 集合
- 遵循文档,使用适当的配置创建集合。以下是一个支持密集和稀疏向量的示例请求:
PUT /collections/{collection_name} { "vectors": { "dense": { "size": 384, "distance": "Cosine" } }, "sparse_vectors": { "sparse": {} } }将数据框上传到 Qdrant
options = {
"qdrant_url": "<QDRANT_GRPC_URL>",
"api_key": "<QDRANT_API_KEY>",
"collection_name": "<QDRANT_COLLECTION_NAME>",
"vector_fields": "dense_vector",
"vector_names": "dense",
"sparse_vector_value_fields": "sparse_vector_values",
"sparse_vector_index_fields": "sparse_vector_indices",
"sparse_vector_names": "sparse",
"schema": embeddings_df.schema.json(),
}
embeddings_df.write.format("io.qdrant.spark.Qdrant").options(**options).mode(
"append"
).save()
请务必将占位符值 (<QDRANT_GRPC_URL>, <QDRANT_API_KEY>, <QDRANT_COLLECTION_NAME>) 替换为您实际的值。如果未指定 id_field 选项,Qdrant Spark 连接器将为每个点生成随机 UUID。
您应看到的命令输出类似于:
Command took 40.37 seconds -- by xxxxx90@xxxxxx.com at 4/17/2024, 12:13:28 PM on fastembed
结论
我们的教程到此结束!欢迎您探索 Databricks、Spark 和 Qdrant 中提供的更多功能,并尝试不同的模型、参数和特性。
数据工程愉快!