使用Airflow和Astronomer进行语义查询
| 时间:45分钟 | 难度:中等 |
|---|
在本教程中,您将使用 Qdrant 作为 提供程序 在 Apache Airflow 中,这是一个开源工具,可让您设置数据工程工作流。
您将以 Python 中的 DAG(有向无环图)形式编写管道。通过这种方式,您可以利用 Python 强大的功能套件和库来实现数据管道所需的几乎所有功能。
Astronomer 是一个托管平台,通过其易于使用的 CLI 和广泛的自动化功能,简化了开发和部署 Airflow 项目的过程。
当根据数据事件在 Qdrant 中运行操作或构建并行任务以生成向量嵌入时,Airflow 非常有用。通过使用 Airflow,您可以为管道设置监控和警报,以实现全面的可观测性。
先决条件
请确保您已准备好以下各项
- 正在运行的 Qdrant 实例。我们将使用来自 https://cloud.qdrant.io 的免费实例
- Astronomer CLI。在此处查找安装说明 here。
- 一个 HuggingFace token 用于生成嵌入。
实施
我们将构建一个 DAG,并行生成我们数据语料库的嵌入,并根据用户输入执行语义检索。
设置项目
Astronomer CLI 使设置 Airflow 项目变得非常简单
mkdir qdrant-airflow-tutorial && cd qdrant-airflow-tutorial
astro dev init
此命令生成运行 Airflow 本地所需的所有项目文件。您可以找到一个名为 dags 的目录,我们可以在其中放置我们的 Python DAG 文件。
要在 Airflow 中使用 Qdrant,请通过将以下内容添加到 requirements.txt 文件中来安装 Qdrant Airflow 提供程序
apache-airflow-providers-qdrant
配置凭据
我们可以使用 Airflow UI、环境变量或 airflow_settings.yml 文件设置提供程序连接。
将以下内容添加到项目中的 .env 文件。根据您的凭据替换值。
HUGGINGFACE_TOKEN="<YOUR_HUGGINGFACE_ACCESS_TOKEN>"
AIRFLOW_CONN_QDRANT_DEFAULT='{
"conn_type": "qdrant",
"host": "xyz-example.eu-central.aws.cloud.qdrant.io:6333",
"password": "<YOUR_QDRANT_API_KEY>"
}'
添加数据语料库
让我们添加一些示例数据来处理。将以下内容粘贴到 include 目录中的名为 books.txt 的文件中。
1 | To Kill a Mockingbird (1960) | fiction | Harper Lee's Pulitzer Prize-winning novel explores racial injustice and moral growth through the eyes of young Scout Finch in the Deep South.
2 | Harry Potter and the Sorcerer's Stone (1997) | fantasy | J.K. Rowling's magical tale follows Harry Potter as he discovers his wizarding heritage and attends Hogwarts School of Witchcraft and Wizardry.
3 | The Great Gatsby (1925) | fiction | F. Scott Fitzgerald's classic novel delves into the glitz, glamour, and moral decay of the Jazz Age through the eyes of narrator Nick Carraway and his enigmatic neighbour, Jay Gatsby.
4 | 1984 (1949) | dystopian | George Orwell's dystopian masterpiece paints a chilling picture of a totalitarian society where individuality is suppressed and the truth is manipulated by a powerful regime.
5 | The Catcher in the Rye (1951) | fiction | J.D. Salinger's iconic novel follows disillusioned teenager Holden Caulfield as he navigates the complexities of adulthood and society's expectations in post-World War II America.
6 | Pride and Prejudice (1813) | romance | Jane Austen's beloved novel revolves around the lively and independent Elizabeth Bennet as she navigates love, class, and societal expectations in Regency-era England.
7 | The Hobbit (1937) | fantasy | J.R.R. Tolkien's adventure follows Bilbo Baggins, a hobbit who embarks on a quest with a group of dwarves to reclaim their homeland from the dragon Smaug.
8 | The Lord of the Rings (1954-1955) | fantasy | J.R.R. Tolkien's epic fantasy trilogy follows the journey of Frodo Baggins to destroy the One Ring and defeat the Dark Lord Sauron in the land of Middle-earth.
9 | The Alchemist (1988) | fiction | Paulo Coelho's philosophical novel follows Santiago, an Andalusian shepherd boy, on a journey of self-discovery and spiritual awakening as he searches for a hidden treasure.
10 | The Da Vinci Code (2003) | mystery/thriller | Dan Brown's gripping thriller follows symbologist Robert Langdon as he unravels clues hidden in art and history while trying to solve a murder mystery with far-reaching implications.
现在,是时候动手编写我们的 Airflow DAG 了!
编写 dag
我们将以下内容添加到 dags 目录中的 books_recommend.py 文件中。让我们看看它对每个任务的作用。
import os
import requests
from airflow.decorators import dag, task
from airflow.models.baseoperator import chain
from airflow.models.param import Param
from airflow.providers.qdrant.hooks.qdrant import QdrantHook
from airflow.providers.qdrant.operators.qdrant import QdrantIngestOperator
from pendulum import datetime
from qdrant_client import models
QDRANT_CONNECTION_ID = "qdrant_default"
DATA_FILE_PATH = "include/books.txt"
COLLECTION_NAME = "airflow_tutorial_collection"
EMBEDDING_MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
EMBEDDING_DIMENSION = 384
SIMILARITY_METRIC = models.Distance.COSINE
def embed(text: str) -> list:
HUGGINFACE_URL = f"https://api-inference.huggingface.co/pipeline/feature-extraction/{EMBEDDING_MODEL_ID}"
response = requests.post(
HUGGINFACE_URL,
headers={"Authorization": f"Bearer {os.getenv('HUGGINGFACE_TOKEN')}"},
json={"inputs": [text], "options": {"wait_for_model": True}},
)
return response.json()[0]
@dag(
dag_id="books_recommend",
start_date=datetime(2023, 10, 18),
schedule=None,
catchup=False,
params={"preference": Param("Something suspenseful and thrilling.", type="string")},
)
def recommend_book():
@task
def import_books(text_file_path: str) -> list:
data = []
with open(text_file_path, "r") as f:
for line in f:
_, title, genre, description = line.split("|")
data.append(
{
"title": title.strip(),
"genre": genre.strip(),
"description": description.strip(),
}
)
return data
@task
def init_collection():
hook = QdrantHook(conn_id=QDRANT_CONNECTION_ID)
if not hook.conn..collection_exists(COLLECTION_NAME):
hook.conn.create_collection(
COLLECTION_NAME,
vectors_config=models.VectorParams(
size=EMBEDDING_DIMENSION, distance=SIMILARITY_METRIC
),
)
@task
def embed_description(data: dict) -> list:
return embed(data["description"])
books = import_books(text_file_path=DATA_FILE_PATH)
embeddings = embed_description.expand(data=books)
qdrant_vector_ingest = QdrantIngestOperator(
conn_id=QDRANT_CONNECTION_ID,
task_id="qdrant_vector_ingest",
collection_name=COLLECTION_NAME,
payload=books,
vectors=embeddings,
)
@task
def embed_preference(**context) -> list:
user_mood = context["params"]["preference"]
response = embed(text=user_mood)
return response
@task
def search_qdrant(
preference_embedding: list,
) -> None:
hook = QdrantHook(conn_id=QDRANT_CONNECTION_ID)
result = hook.conn.query_points(
collection_name=COLLECTION_NAME,
query=preference_embedding,
limit=1,
with_payload=True,
).points
print("Book recommendation: " + result[0].payload["title"])
print("Description: " + result[0].payload["description"])
chain(
init_collection(),
qdrant_vector_ingest,
search_qdrant(embed_preference()),
)
recommend_book()
import_books:此任务读取包含图书信息(如标题、流派和描述)的文本文件,然后将数据作为字典列表返回。
init_collection:此任务在 Qdrant 数据库中初始化一个集合,我们将在其中存储图书描述的向量表示。
embed_description:这是一个动态任务,为列表中的每本书创建一个映射任务实例。该任务使用 embed 函数为每个描述生成向量嵌入。要使用不同的嵌入模型,您可以调整 EMBEDDING_MODEL_ID、EMBEDDING_DIMENSION 值。
embed_user_preference:在这里,我们获取用户的输入并使用与图书描述相同的预训练模型将其转换为向量。
qdrant_vector_ingest:此任务使用 QdrantIngestOperator 将图书数据摄取到 Qdrant 集合中,将每本书的描述与其相应的向量嵌入相关联。
search_qdrant:最后,此任务使用向量化的用户偏好在 Qdrant 数据库中执行搜索。它根据向量相似性在集合中查找最相关的图书。
运行 DAG
前往您的终端并运行 astro dev start
应该会生成一个本地 Airflow 容器。您现在可以通过 https://:8080 访问 Airflow UI。点击 books_recommend 访问我们的 DAG。
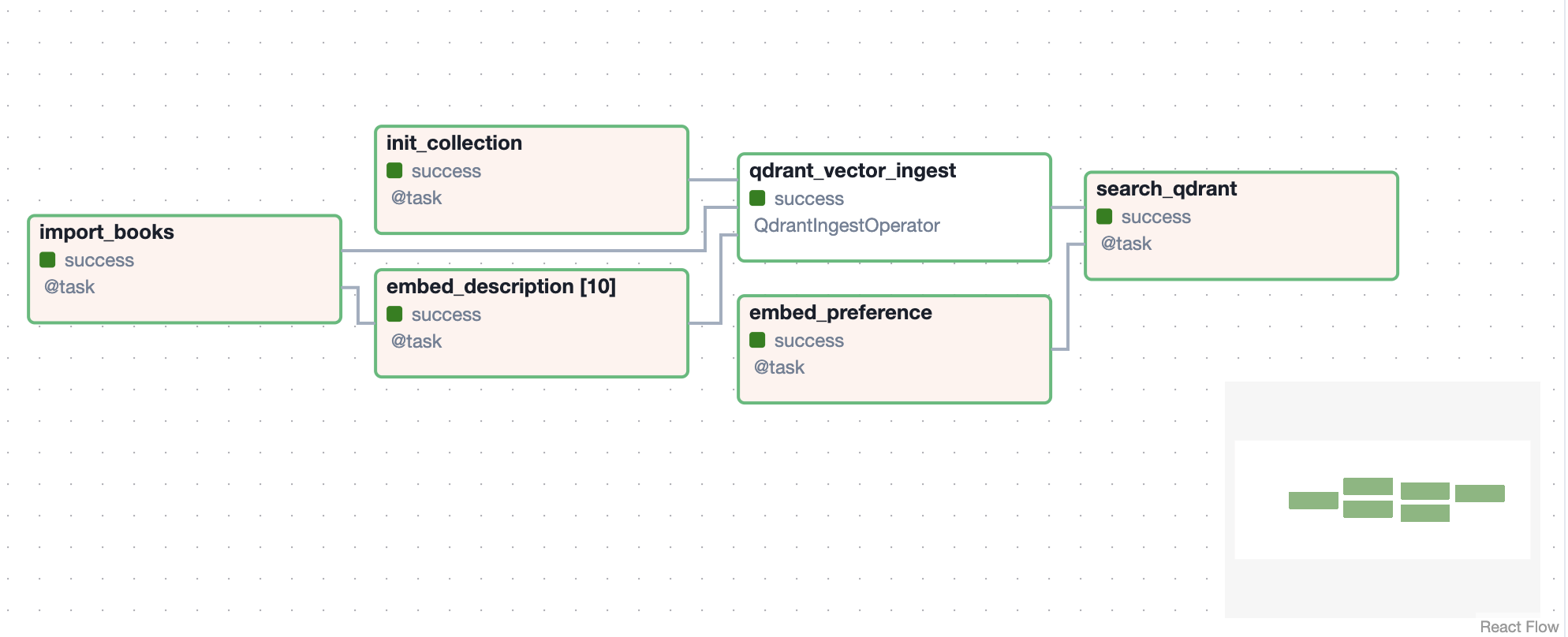
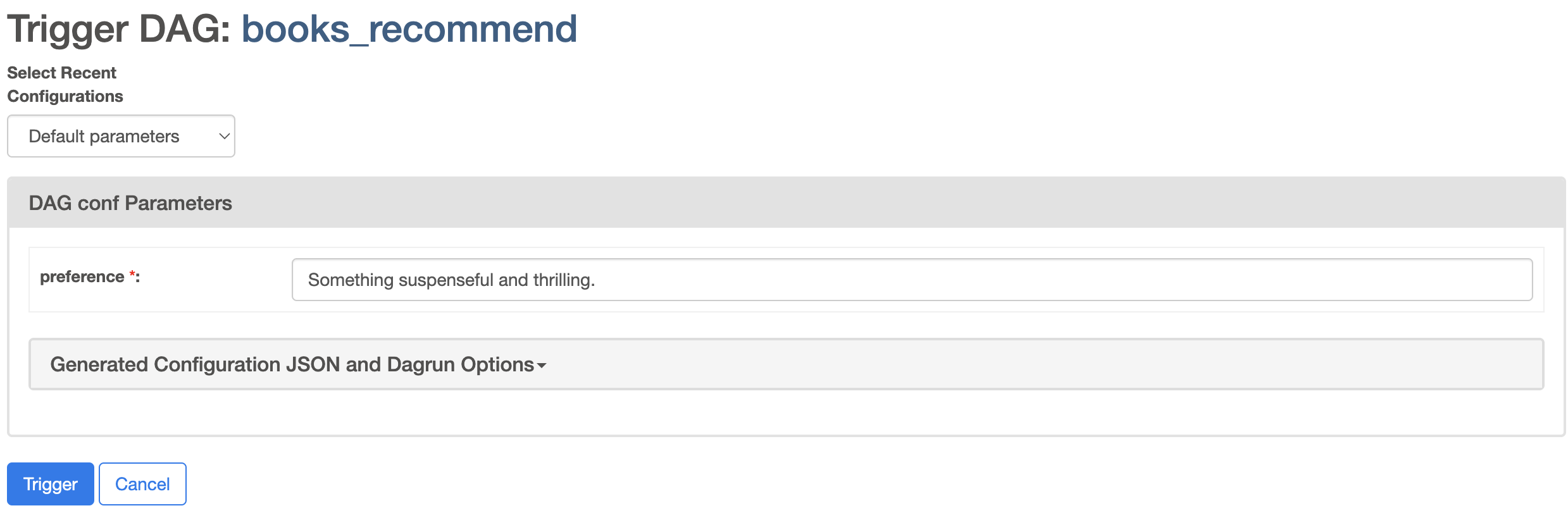
点击右侧的播放按钮运行 DAG。系统会要求您输入您的偏好,默认值已填写。
DAG 运行完成后,您应该能够在 search_qdrant 任务的日志中看到搜索的输出。

瞧,这是一个与 Qdrant 接口的 Airflow 管道!随意摆弄和探索 Airflow。下面有一些可能派上用场的参考资料。