返回生态系统
·
2023 年 10 月 18 日数据科学和机器学习从业者常常发现自己在模型、库和框架的迷宫中穿梭。选择哪个模型、多大的嵌入尺寸以及如何进行分词等,只是您开始工作时面临的一些问题。我们理解许多数据科学家希望找到一种更简单、更直观的方式来完成嵌入工作。这就是我们构建 FastEmbed 的原因,它是一个专为速度、效率和可用性而设计的 Python 库。我们创建了易于使用的默认工作流,处理了 NLP 嵌入中 80% 的用例。

生成嵌入的现状
通常,您通过底层利用 PyTorch 或 TensorFlow 模型来生成嵌入。然而,使用这些库在易用性和计算速度方面会带来一些成本。这至少部分是因为它们既为模型推理而构建,也为模型改进(例如通过微调)而构建。
为了解决这些问题,我们构建了一个小型库,专注于快速高效地创建文本嵌入的任务。我们还决定首先只包含一小部分一流的 Transformer 模型。通过保持小巧并专注于特定用例,我们可以使我们的库专注,而不包含所有无关的依赖项。我们自带少量模型,量化模型权重,并将其与 ONNX Runtime 无缝集成。FastEmbed 在推理时间、资源利用率和性能(召回率/准确率)之间取得了平衡。
快速嵌入文本文档示例
以下是我们如何使文本文档嵌入变得简单的一个示例
这 3 行代码为您完成了大量繁重的工作:它们下载量化模型,使用 ONNX Runtime 加载它,然后运行文档的批量嵌入创建。
documents: List[str] = [
"Hello, World!",
"fastembed is supported by and maintained by Qdrant."
]
embedding_model = DefaultEmbedding()
embeddings: List[np.ndarray] = list(embedding_model.embed(documents))
代码详解
让我们逐行深入研究一个更高级的示例代码片段
这里,我们从 FastEmbed 导入 FlagEmbedding 类,并将其别名为 Embedding。这是负责根据您选择的文本模型生成嵌入的核心类。这个类也可以直接导入为 DefaultEmbedding,它就是 BAAI/bge-small-en-v1.5。
from fastembed.embedding import DefaultEmbedding
在这个名为 documents 的列表中,我们定义了四个要转换为嵌入的文本字符串。
documents: List[str] = [
"passage: Hello, World!",
"query: How is the World?",
"passage: This is an example passage.",
"fastembed is supported by and maintained by Qdrant."
]
请注意使用前缀“passage”和“query”来区分要生成的嵌入类型。这继承自 BAAI/bge 系列模型本身的跨编码器实现。这对于检索特别有用,我们强烈建议也使用这种方法。
使用诸如“query”和“passage”之类的文本前缀不仅仅是语法糖;它告知算法如何处理文本以生成嵌入。“query”前缀通常会触发模型生成针对相似性比较而优化的嵌入,而“passage”嵌入则经过微调以实现上下文理解。如果您省略前缀,将应用默认行为,但为了获得更精细的结果,建议指定前缀。
接下来,我们使用默认模型初始化 Embedding 模型:BAAI/bge-small-en-v1.5。
默认模型和其它几个模型都有一个最大为 512 个 token 的上下文窗口。此最大限制来自嵌入模型训练和设计本身。如果您想嵌入比这更长的序列,我们建议使用一些池化策略,从序列中获得单个向量。例如,您可以使用文档不同块的嵌入均值。这也是 SBERT 论文推荐的方法。
embedding_model = DefaultEmbedding()
此模型在速度和准确性之间取得了平衡,非常适合实际应用。
最后,我们调用 embedding_model 对象上的 embed() 方法,传入 documents 列表。该方法返回一个 Python 生成器,因此我们将其转换为列表以获取所有嵌入。这些嵌入是 NumPy 数组,为快速数学运算而优化。
embeddings: List[np.ndarray] = list(embedding_model.embed(documents))
embed() 方法返回一个 NumPy 数组列表,每个数组对应于原始 documents 列表中文档的嵌入。这些数组的维度由您选择的模型决定,例如对于“BAAI/bge-small-en-v1.5”,它是一个 384 维向量。
您可以轻松解析这些 NumPy 数组以用于任何下游应用程序——无论是聚类、相似性比较,还是将它们馈送到机器学习模型中进行进一步分析。
FastEmbed 的 3 个关键特性
FastEmbed 专为推理速度而构建,同时不牺牲(太多)性能
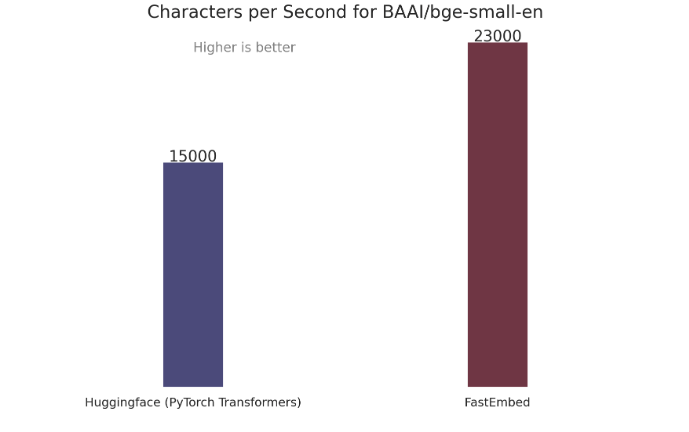
比 PyTorch Transformers 快 50%
- 性能优于 Sentence Transformers 和 OpenAI Ada-002
- 量化模型和原始模型向量的余弦相似度为 0.92
- 我们将
BAAI/bge-small-en-v1.5用作 DefaultEmbedding,因此选择它进行比较
FastEmbed 的底层实现
量化模型:我们对 CPU(和 Mac Metal)模型进行了量化——为您提供计算模型最高的性价比。我们的默认模型非常小,如果您愿意,甚至可以在 AWS Lambda 中运行它!
感谢 Huggingface 的 Optimum——它使量化模型变得更容易。
缩短安装时间
FastEmbed 通过保持较低的最低 RAM/磁盘使用率而脱颖而出。:
它设计得灵活快速,对于希望将文本嵌入集成用于生产用途的企业非常有用。对于 FastEmbed,依赖项列表非常简洁
onnx: 版本 ^1.11 – 如果可能,未来我们也力求移除此项!
- onnxruntime: 版本 ^1.15
- tqdm: 版本 ^4.65 – 仅在下载时使用
- requests: 版本 ^2.31 – 仅在下载时使用
- tokenizers: 版本 ^0.13
- 这个精简的列表服务于两个目的。首先,它显著减少了安装时间,从而实现更快的部署。其次,它限制了所需的磁盘空间量,即使对于存储受限的环境也是可行的选择。
依赖项列表中显著缺少诸如 PyTorch 之类的庞大库,而且无需 CUDA 驱动程序。这是故意的。FastEmbed 专为在 CPU 上直接提供最佳性能而设计,无需专用硬件或复杂设置。
ONNX Runtime:ONNX Runtime 使我们能够支持多种提供程序。我们进行的量化主要针对 CPU (Intel),但未来我们也打算支持 GPU 版本。这允许更大的定制和优化空间,进一步符合您特定的性能和计算要求。
当前支持的模型
我们从一小部分支持的模型开始
我们支持的所有模型都经过量化,以便实现更快的计算!
如果您正在使用 FastEmbed 并有想法或需要特定功能,请随时告诉我们。只需在我们的 GitHub 页面上提交一个 Issue。这是我们在决定下一步工作时首先查看的地方。您可以在这里提交:FastEmbed GitHub Issues。
对于 FastEmbed 的 DefaultEmbedding 模型,我们致力于支持最好的开源模型。
如果发生任何变化,您会看到新的版本号,例如从 0.0.6 到 0.1。因此,最好锁定您正在使用的 FastEmbed 版本以避免意外。
将 FastEmbed 与 Qdrant 结合使用
Qdrant 是一个向量存储(Vector Store),为现代机器学习和 AI 应用提供全面、高效且可扩展的企业解决方案。无论您是处理数十亿数据点、需要低延迟高性能的向量数据库解决方案,还是专门的量化方法——Qdrant 都专为应对这些需求而设计。
FastEmbed 与 Qdrant 向量存储能力的结合实现了透明的工作流,可实现无缝的嵌入生成、存储和检索。这简化了 API 设计——同时仍为您提供了进行重大更改的灵活性,例如,您可以使用 FastEmbed 生成您自己的嵌入(而非 DefaultEmbedding),并将其与 Qdrant 结合使用。
以下是关于如何结合使用 FastEmbed 和 Qdrant 的详细指南。
步骤 1:安装
在深入代码之前,第一步是安装 Qdrant Client 和 FastEmbed 库。这可以使用 pip 完成
对于使用 zsh 作为 shell 的用户,可能会遇到语法问题。在这种情况下,请将包名用引号括起来
pip install qdrant-client[fastembed]
步骤 2:初始化 Qdrant Client
pip install 'qdrant-client[fastembed]'
成功安装后,下一步是初始化 Qdrant Client。可以在内存中完成,也可以通过指定数据库路径来完成
步骤 3:准备文档、元数据和 ID
from qdrant_client import QdrantClient
# Initialize the client
client = QdrantClient(":memory:") # or QdrantClient(path="path/to/db")
客户端初始化后,准备您希望嵌入的文本文档,以及任何关联的元数据和唯一 ID
请注意,我们将使用的 add 方法是重载的:如果您省略 ids,我们将为您生成它们。metadata 显然是可选的。所以,您也可以简单地使用这个
docs = [
"Qdrant has Langchain integrations",
"Qdrant also has Llama Index integrations"
]
metadata = [
{"source": "Langchain-docs"},
{"source": "LlamaIndex-docs"},
]
ids = [42, 2]
步骤 4:将文档添加到 Collection
docs = [
"Qdrant has Langchain integrations",
"Qdrant also has Llama Index integrations"
]
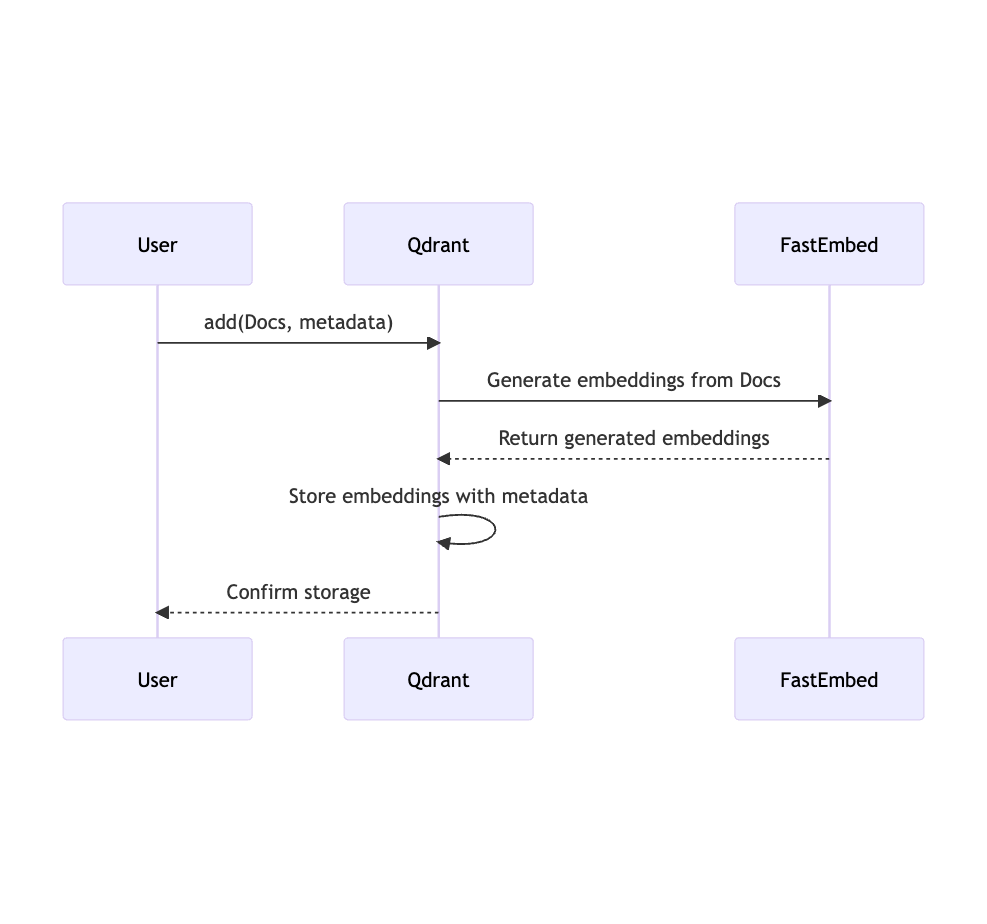
准备好文档、元数据和 ID 后,您可以使用 add 方法将这些添加到 Qdrant 中指定的 collection
在这个函数内部,Qdrant Client 使用 FastEmbed 生成文本嵌入,如果缺少 ID 则生成,然后将它们与元数据一起添加到索引中。这使用了 DefaultEmbedding 模型:BAAI/bge-small-en-v1.5
client.add(
collection_name="demo_collection",
documents=docs,
metadata=metadata,
ids=ids
)
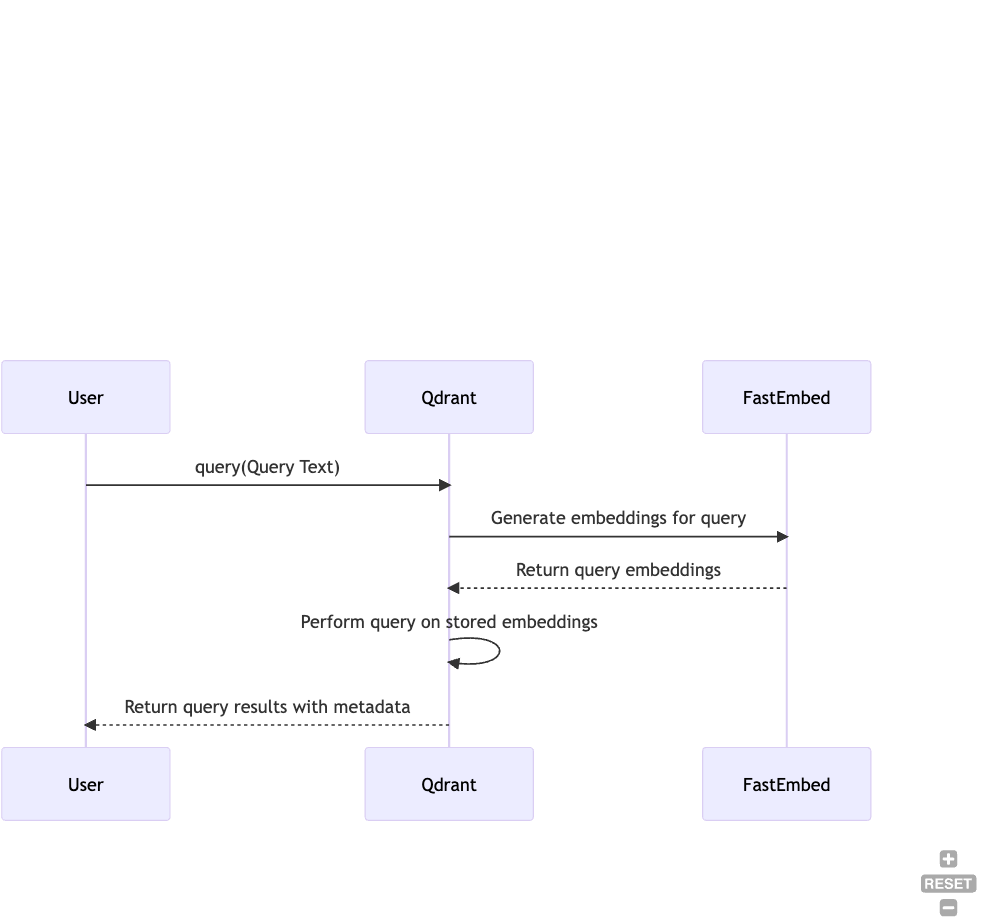
步骤 5:执行查询
最后,您可以对存储的文档执行查询。Qdrant 提供了强大的查询功能,查询结果可以轻松地按如下方式检索
在幕后,我们首先将 query_text 转换为嵌入,并用它来查询向量索引。
search_result = client.query(
collection_name="demo_collection",
query_text="This is a query document"
)
print(search_result)
通过遵循这些步骤,您可以有效地利用 FastEmbed 和 Qdrant 的组合能力,从而简化您的嵌入生成和检索任务。
Qdrant 专为处理包含数十亿数据点的大规模数据集而设计。其架构采用了诸如二元量化和标量量化等技术,实现高效的存储和检索。当您将 FastEmbed 的 CPU 优先设计和轻量级特性融入其中时,您将获得一个可以无缝扩展同时保持低延迟的系统。
总结
如果您对 FastEmbed 和 Qdrant 如何让您的搜索任务变得轻而易举感到好奇,何不试一试呢?亲自感受一下它的强大之处。以下是两种简单的入门方法
云端:在Qdrant 云端通过免费计划开始使用。
Docker 容器:如果您是自己动手型用户,可以在自己的机器上进行设置。这里有一份快速指南帮助您:使用 Docker 快速入门。
所以,请尽管尝试吧。我们很期待听到您的反馈!
最后,如果您觉得 FastEmbed 有用,并想了解我们的最新动态,在我们的 GitHub 仓库上点赞对我们意义重大。这是为仓库点赞的链接。
如果您对 FastEmbed 有任何疑问,请在 Qdrant Discord 上提问:https://discord.gg/Qy6HCJK9Dc
此页面对您有帮助吗?