
我们为何自建存储引擎
数据库需要一个存储和检索数据的地方。这正是 Qdrant 键值存储 所做的——它将键与值关联起来。
当我们开始构建 Qdrant 时,我们需要选择一个现成的工具来完成这项任务。因此,我们选择了 RocksDB 作为我们的嵌入式键值存储。

它成熟、可靠且文档完善。
随着时间的推移,我们遇到了一些问题。它的架构需要压缩(使用 LSMT),这导致了随机的延迟峰值。它处理通用键,而我们只将其用于顺序 ID。大量的配置选项使其功能多样,但准确调优却令人头疼。最后,与 C++ 的互操作性降低了我们的速度(尽管我们仍将支持它相当长一段时间 😭)。
虽然已经有一些用 Rust 编写的优秀选项我们可以利用,但我们需要一些定制的东西。现有的一切都不符合我们所需的方式。我们不需要通用键。我们希望完全控制何时以及哪些数据被写入和刷新。我们的系统已经内置了崩溃恢复机制。在线压缩不是优先事项,我们已经有优化器来处理这个问题。调试配置错误并没有很好地利用我们的时间。
所以我们自建了存储。从 Qdrant 1.13 版 开始,我们使用 Gridstore 进行负载和稀疏向量存储。

简单、高效,专为 Qdrant 设计。
在本文中,您将了解到
- Gridstore 的工作原理 – 深入探讨其架构和机制。
- 我们为何如此构建 – 塑造它的关键设计决策。
- 严格测试 – 我们如何确保新存储已为生产做好准备。
- 性能基准 – 展示其效率的官方指标。
我们的第一个挑战? 找出处理顺序键和可变大小数据的最佳方法。
Gridstore 架构:三大主要组件

Gridstore 的架构围绕三个关键组件构建,这些组件实现了快速查找和高效空间管理
| 组件 | 描述 |
|---|---|
| 数据层 | 以固定大小的块存储值,并使用基于指针的查找系统检索它们。 |
| 掩码层 | 使用位掩码跟踪哪些块正在使用,哪些可用。 |
| 间隙层 | 在更高层次管理块可用性,实现快速空间分配。 |
1. 用于快速检索的数据层
Gridstore 的核心是数据层,它旨在根据键快速存储和检索值。该层使我们能够进行高效读取并存储可变大小的数据。该层的主要两个组件是跟踪器和数据网格。
由于内部 ID 始终是顺序整数(0, 1, 2, 3, 4, …),因此跟踪器是一个指针数组,其中每个指针准确地告诉系统一个值的起始位置和长度。
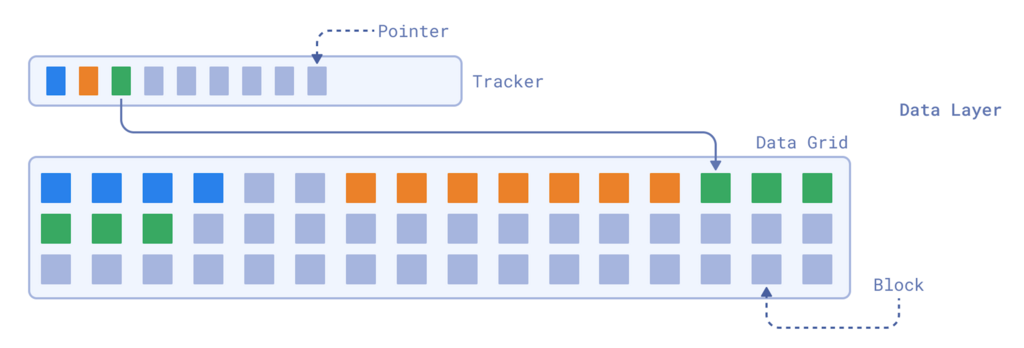
数据层使用一个指针数组来快速检索数据。
这使得查找速度极快。例如,查找键 3 只需要跳到跟踪器中的第三个位置,然后沿着指针在数据网格中找到该值。
然而,由于值的大小是可变的,数据本身存储在固定大小的块网格中,这些块被分组到更大的页面文件中。每个块的固定大小通常为 128 字节。插入值时,Gridstore 分配一个或多个连续块来存储它,确保每个块只保存单个值的数据。
2. 掩码层重用空间
掩码层帮助 Gridstore 处理更新和删除,而无需昂贵的数据压缩。Gridstore 不为每个块维护复杂的元数据,而是使用位掩码跟踪使用情况,其中每个位代表一个块,1 表示已使用,0 表示空闲。

位掩码高效跟踪块使用情况。
这使得确定新值可以写入的位置变得容易。当一个值被移除时,它会在其指针处被软删除,并且位掩码中对应的块被标记为可用。同样,当更新一个值时,新版本会写入其他地方,旧块会在位掩码处被释放。
这种方法确保 Gridstore 不会浪费空间。然而,随着存储的增长,扫描整个位掩码以查找可用块可能会变得计算成本高昂。
3. 用于有效更新的间隙层
为了进一步优化更新处理,Gridstore 引入了间隙层,它提供了块可用性的高级视图。
Gridstore 不会扫描整个位掩码,而是将位掩码分成多个区域,并跟踪每个区域内最大的连续空闲空间,即区域间隙。通过同时存储每个区域的起始和结束间隙,系统可以在需要存储大值时有效地组合多个区域。
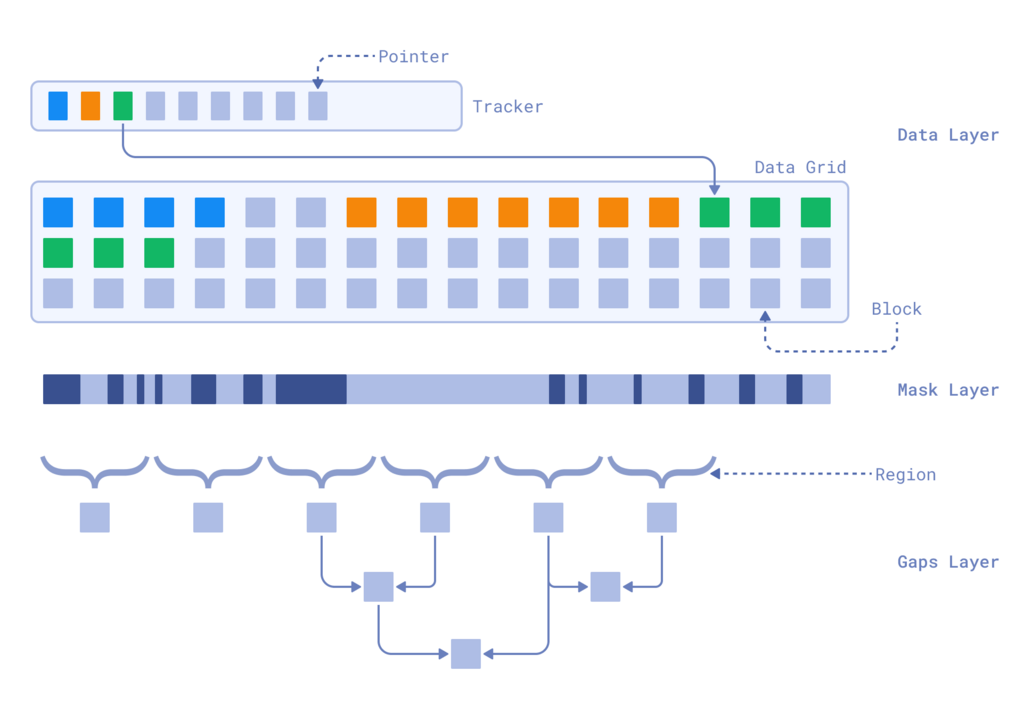
Gridstore 的完整架构
这种分层方法使 Gridstore 能够快速定位可用空间,缩减扫描所需的工作量,同时保持内存开销最小。通过此系统,为新值查找存储空间只需扫描总元数据的一小部分,即使在大型段中,更新和插入也变得高效。
在默认配置下,间隙层的作用范围是实际存储大小的百万分之一。这意味着对于每 1GB 数据,间隙层只需扫描 6KB 的元数据。通过这种机制,其他操作可以以几乎恒定时间复杂度执行。
生产中的 Gridstore:维护数据完整性

Gridstore 的架构引入了多个相互依赖的结构,这些结构必须保持同步以确保数据完整性
- 数据层存储数据并将每个键与其在存储中的位置(包括页面 ID、块偏移量及其值的大小)关联起来。
- 掩码层跟踪哪些块被占用,哪些空闲。
- 间隙层提供了一个索引化的空闲块视图,以实现高效的空间分配。
每次插入新值或更新现有值时,所有这些组件都需要以协调的方式进行修改。
现实生活中的问题发生时
现实世界的系统并非在真空中运行。故障时有发生:软件 bug 导致意外崩溃,内存耗尽迫使进程终止,磁盘无法可靠地持久化数据,以及电力损失随时可能中断操作。
关键问题是:如果在更新这些结构时发生故障会怎样?
如果一个组件更新了而另一个没有,整个系统可能会变得不一致。更糟的是,如果一个操作只部分写入磁盘,它可能导致孤立数据、不可用空间,甚至数据损坏。
通过幂等性实现稳定性:使用 WAL 恢复
为了防范这些风险,Qdrant 依赖于预写日志 (WAL)。在提交操作之前,Qdrant 确保它至少记录在 WAL 中。如果所有更新在刷新之前发生崩溃,系统可以安全地从日志中重放操作。
这种恢复机制引入了另一个基本属性:幂等性。
存储系统必须设计成在故障后重新应用相同的操作,会产生与该操作只应用一次相同的最终状态。
宏伟的解决方案:惰性更新
为实现这一点,Gridstore 延迟完成更新,优先处理写入中最关键的部分:数据本身。
| 👉 它不会立即更新所有元数据结构,而是首先写入新值,同时在缓冲区中保留轻量级的待定更改。 |
| 👉 系统仅在明确请求时才最终确定这些更新,确保在更新安全持久化之前,崩溃绝不会导致数据被标记为已删除。 |
| 👉 在最坏的情况下,Gridstore 可能需要写入相同的数据两次,导致轻微的空间开销,但它绝不会通过覆盖有效数据来损坏存储。 |
我们如何测试最终产品

首先…模型测试
Gridstore 可以通过模型测试高效地进行测试,该测试将其行为与一个简单的内存哈希图进行比较。由于 Gridstore 应该像一个持久化的哈希图一样运行,这种方法可以快速检测不一致性。
过程很简单
- 初始化一个 Gridstore 实例和一个空的哈希图。
- 在两者上运行随机操作(put、delete、update)。
- 验证每次操作后结果是否匹配。
- 比较所有键和值以确保一致性。
这种方法提供了高测试覆盖率,暴露了诸如不正确的持久化或错误的删除等问题。运行大规模模型测试可确保 Gridstore 在实际使用中保持可靠。
这是在 Rust 中生成操作的简单方法。
enum Operation {
Put(PointOffset, Payload),
Delete(PointOffset),
Update(PointOffset, Payload),
}
impl Operation {
fn random(rng: &mut impl Rng, max_point_offset: u32) -> Self {
let point_offset = rng.random_range(0..=max_point_offset);
let operation = rng.gen_range(0..3);
match operation {
0 => {
let size_factor = rng.random_range(1..10);
let payload = random_payload(rng, size_factor);
Operation::Put(point_offset, payload)
}
1 => Operation::Delete(point_offset),
2 => {
let size_factor = rng.random_range(1..10);
let payload = random_payload(rng, size_factor);
Operation::Update(point_offset, payload)
}
_ => unreachable!(),
}
}
}
模型测试是一种高价值的捕获 bug 的方法,尤其是当您的系统模仿一个定义明确的组件(如哈希图)时。如果您的组件与其他组件行为相同,那么使用模型测试只需付出一点努力就能带来很多价值。
我们可以针对 RocksDB 进行测试,但简单性更重要。一个简单的哈希图让我们能够快速运行大规模测试序列,更快地暴露问题。
为了更精确的调试,基于属性的测试增加了自动化测试生成和缩小。它以最小化的测试用例精确定位故障,使 bug 查找更快、更有效。
崩溃测试:Gridstore 能承受压力吗?
为崩溃弹性而设计是一回事,证明它在压力下有效是另一回事。为了将 Qdrant 的数据完整性推向极限,我们构建了 Crasher,一个测试台,它在 Qdrant 处理繁重的更新工作负载时残酷地杀死并重新启动 Qdrant。
Crasher 运行一个循环,持续写入数据,然后随机使 Qdrant 崩溃。每次重启时,Qdrant 都会重放其 预写日志 (WAL),我们验证数据完整性是否保持。可能的异常包括
- 数据丢失(点、向量或负载)
- 损坏的负载值
这种激进而简单的方法在长时间运行时发现了实际问题。虽然我们也使用混沌测试来处理分布式设置,但 Crasher 在本地环境中快速、可重复的故障测试方面表现出色。
测试 Gridstore 性能:基准测试

为了衡量我们新存储引擎的影响,我们使用了 Bustle,一个键值存储基准测试框架,将 Gridstore 与 RocksDB 进行比较。我们测试了三种工作负载
| 工作负载类型 | 操作分布 |
|---|---|
| 读密集型 | 95% 读取 |
| 插入密集型 | 80% 插入 |
| 更新密集型 | 50% 更新 |
结果不言而喻
各种工作负载的平均延迟全面降低,尤其是在插入方面。
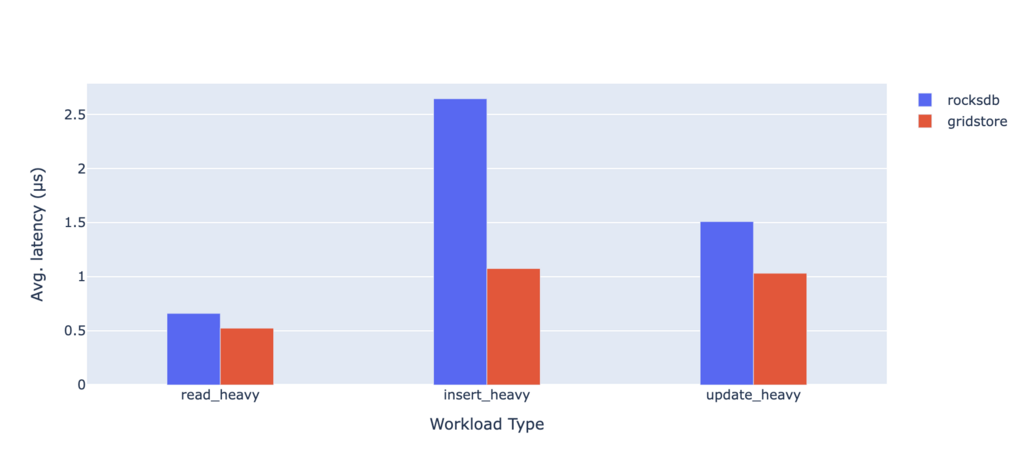
这显示了性能的明显提升。正如我们所见,对 Gridstore 的投资正在获得回报。
端到端基准测试
现在,让我们测试对真实 Qdrant 实例的影响。到目前为止,我们只将 Gridstore 集成到负载和稀疏向量中,但即使是这种部分切换也应该显示出显著的改进。
为了进行基准测试,我们使用内部的 bfb 工具来生成工作负载。我们的配置
bfb -n 2000000 --max-id 1000000 \
--sparse-vectors 0.02 \
--set-payload \
--on-disk-payload \
--dim 1 \
--sparse-dim 5000 \
--bool-payloads \
--keywords 100 \
--float-payloads true \
--int-payloads 100000 \
--text-payloads \
--text-payload-length 512 \
--skip-field-indices \
--jsonl-updates ./rps.jsonl
此基准测试会两次 upsert 100 万个点。每个点包含
- 中到大负载
- 微小的密集向量(密集向量使用不同的存储类型)
- 稀疏向量
附加配置
我们进行的测试在另一个请求中单独更新了负载数据。
没有负载索引,这确保我们测量纯粹的摄取速度。
最后,我们收集了请求延迟指标进行分析。
我们针对 Qdrant 1.12.6 运行此测试,在新旧存储后端之间切换。
最终结果
数据摄取速度快了两倍,吞吐量更平稳——巨大的胜利! 😍
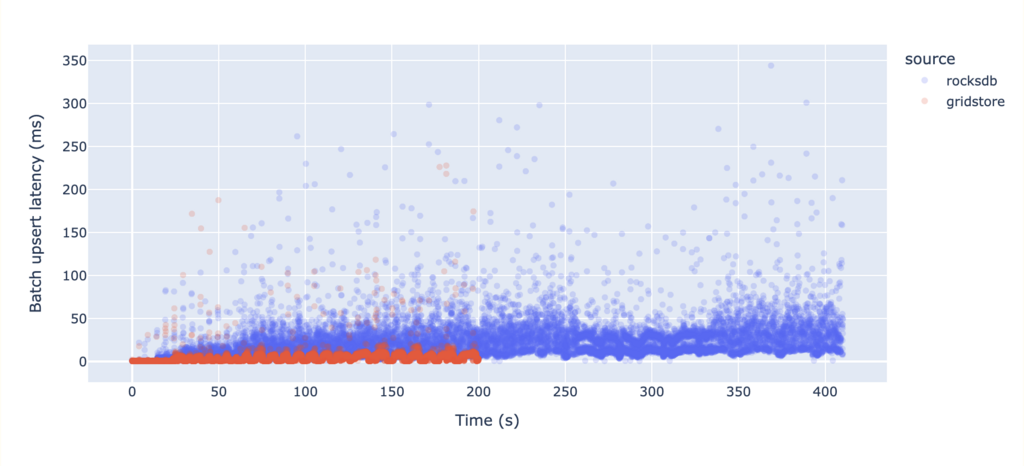
我们优化了速度,并且取得了回报——但存储大小呢?
- Gridstore:2333MB
- RocksDB:2319MB
严格来说,RocksDB 略小,但与 2 倍的摄取速度和更稳定的吞吐量相比,差异可以忽略不计。为了巨大的性能提升,这是一个小小的权衡!
试用 Gridstore
Gridstore 代表了 Qdrant 如何管理其键值存储需求方面的重大进步。它提供了卓越的性能和针对我们用例量身定制的简化更新。我们已经成功实现了更快、更可靠的数据摄取,同时即使在繁重的工作负载和意外故障下也能保持数据完整性。它已被用作磁盘上负载和稀疏向量的存储后端。
👉 重要的是要指出 Gridstore 仍然与 Qdrant 紧密集成,因此尚未作为独立 crate 发布。
其 API 仍在不断发展,我们专注于在我们的生态系统中对其进行完善,以确保最大的稳定性和性能。也就是说,我们认识到这项创新可以为更广泛的 Rust 社区带来的价值。未来,一旦 API 稳定并且我们将其与 Qdrant 充分解耦,我们将考虑将其作为对社区的贡献发布 ❤️。
目前,Gridstore 继续推动 Qdrant 的改进,展示了考虑到现代需求而设计的定制存储引擎的优势。请继续关注进一步的更新和潜在的社区发布,因为我们将继续突破性能和可靠性的界限。
简单、高效,专为 Qdrant 设计。