
想象一下您销售计算机硬件。为了帮助购物者轻松在您的网站上找到产品,您需要一个用户友好的搜索引擎。

如果您销售计算机,并且拥有大量关于笔记本电脑、台式机和配件的数据,您的搜索功能应能引导客户找到他们想要的确切设备——或者至少是非常相似的匹配项。
在Qdrant中存储数据时,每个产品都是一个点,由一个id、一个vector和一个payload组成
{
"id": 1,
"vector": [0.1, 0.2, 0.3, 0.4],
"payload": {
"price": 899.99,
"category": "laptop"
}
}
id是集合中点的唯一标识符。vector是集合中点与其他点相似性的数学表示。最后,payload包含直接描述点的元数据。
虽然我们可能无法解读矢量,但我们可以从其元数据中推导出有关项目的额外信息。在这个特定案例中,我们正在查看一个价格为899.99美元的笔记本电脑数据点。
什么是过滤?
当搜索完美的计算机时,您的客户可能会得到与搜索条目在数学上相似但不完全匹配的结果。例如,如果他们搜索低于1000美元的笔记本电脑,一个没有约束的简单矢量搜索可能仍然会显示价格超过1000美元的其他笔记本电脑。
这就是为什么仅靠语义搜索可能不够。为了获得精确的结果,您需要在price上强制应用载荷过滤器。只有这样,您才能确保搜索结果符合所选择的特性。
这被称为过滤,它是矢量数据库的关键特性之一。
以下是过滤后的矢量搜索在后台的工作方式。我们将在下一节介绍其机制。
POST /collections/online_store/points/search
{
"vector": [ 0.2, 0.1, 0.9, 0.7 ],
"filter": {
"must": [
{
"key": "category",
"match": { "value": "laptop" }
},
{
"key": "price",
"range": {
"gt": null,
"gte": null,
"lt": null,
"lte": 1000
}
}
]
},
"limit": 3,
"with_payload": true,
"with_vector": false
}
过滤后的结果将是语义搜索和施加在查询上的过滤条件的组合。在接下来的页面中,我们将展示过滤在矢量搜索中是关键实践,原因有二:
- 使用Qdrant的过滤功能,您可以显著提高搜索精度。更多内容请参见下一节。
- 过滤有助于控制资源并减少计算使用。更多内容请参见载荷索引。
您将在本指南中学到什么
在矢量搜索中,过滤和排序比传统数据库更具相互依赖性。虽然SQL等数据库使用WHERE和ORDER BY等命令,但矢量搜索中这些过程的相互作用更为复杂。
大多数人使用默认设置构建矢量搜索应用程序,这些应用程序未正确配置,甚至未设置以实现精确检索。在本指南中,我们将向您展示如何使用一些易于实现的基础和高级策略来利用过滤功能充分发挥矢量搜索的作用。
请记住在Qdrant控制面板中运行所有教程代码
实现“Hello World”最简单的方法是在实时集群中尝试过滤。我们的交互式教程将向您展示如何创建集群、添加数据并尝试一些过滤子句。
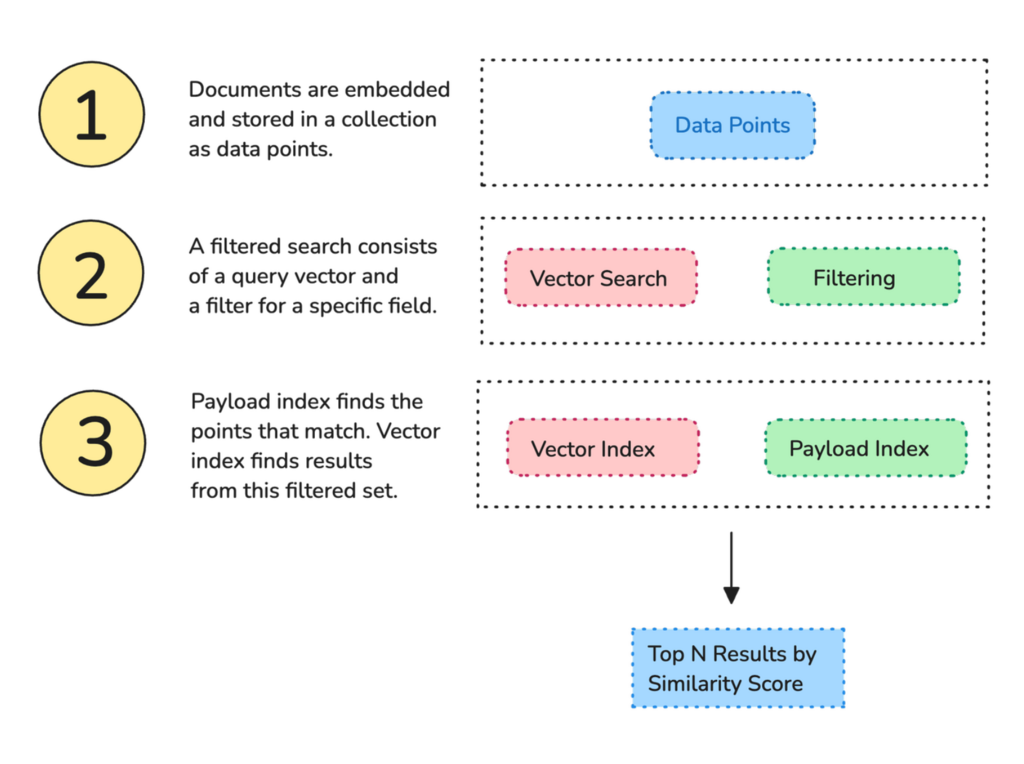
Qdrant的过滤方法
Qdrant遵循特定的方法来搜索和过滤密集矢量。
让我们看看这个三阶段图。在本例中,我们试图找到查询矢量(绿色)的最近邻。您的搜索旅程从底部(橙色)开始。
默认情况下,Qdrant连接矢量索引中的所有数据点。在您引入过滤器后,一些数据点会断开连接。矢量搜索无法跨越灰色区域,也无法到达最近邻。我们如何弥合这一差距?
图1:Qdrant如何维护可过滤矢量索引。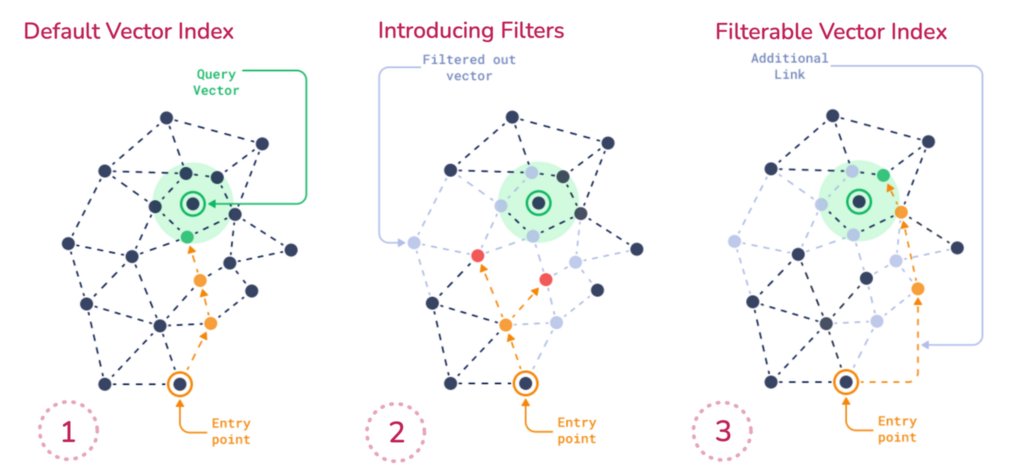
可过滤矢量索引:这项技术在剩余数据点之间构建额外的链接(橙色)。被过滤而留下的点现在可以再次遍历。Qdrant使用特殊的基于类别的方法来连接这些数据点。
Qdrant的方法与传统过滤方法对比

可过滤矢量索引是Qdrant通过向搜索图添加专用链接来解决预过滤和后过滤问题的方法。它旨在保持矢量搜索的速度优势,同时实现精确过滤,解决了在矢量搜索后应用过滤器时可能出现的低效率问题。
预过滤
在预过滤中,搜索引擎首先根据选定的元数据值缩小数据集范围,然后在过滤后的子集中进行搜索。这减少了对可能大得多的数据集进行不必要的计算。
预过滤和使用可过滤HNSW索引之间的选择取决于过滤器的基数(cardinality)。当元数据基数太低时,过滤器会变得具有限制性,并可能破坏图内的连接。这会导致搜索路径碎片化(如图1所示)。当语义搜索过程开始时,它将无法到达这些位置。
然而,在某些条件下,Qdrant仍然受益于预过滤。在低基数情况下,Qdrant的查询计划器会停止使用HNSW,并切换到仅使用载荷索引。这使得搜索过程比使用HNSW更便宜、更快。
图2:在用户端,过滤功能如下所示。我们从五款不同价格的产品开始。首先,应用1000美元的价格过滤器,缩小笔记本电脑的选择范围。然后,矢量搜索在此过滤后的集合中找到相关的结果。
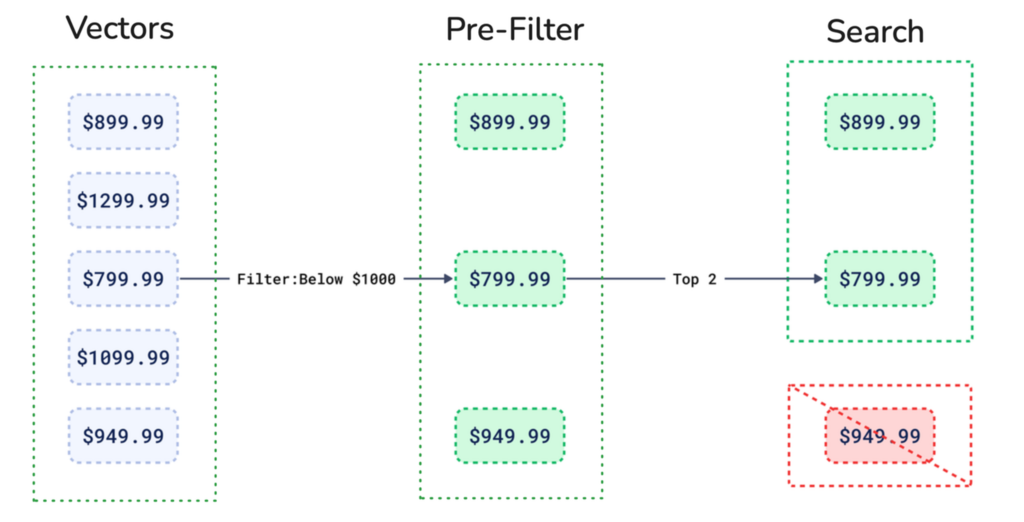
总之,在处理具有低基数元数据的小数据集时,预过滤在特定情况下是有效的。然而,不应在大数据集上使用预过滤,因为它会破坏HNSW图中的过多链接,导致准确性降低。
后过滤
在后过滤中,搜索引擎首先查找相似矢量并检索更大的结果集。然后,它根据元数据对这些结果应用过滤器。当使用低基数过滤器时,后过滤的问题就会显现出来。
在执行矢量搜索后应用低基数过滤器时,您通常会丢弃矢量搜索返回的大部分结果。
图3:在同一个示例中,我们有五款笔记本电脑。首先,矢量搜索找到最相关的两个结果,但它们可能不符合价格匹配。当应用1000美元的价格过滤器时,其他潜在结果会被丢弃。
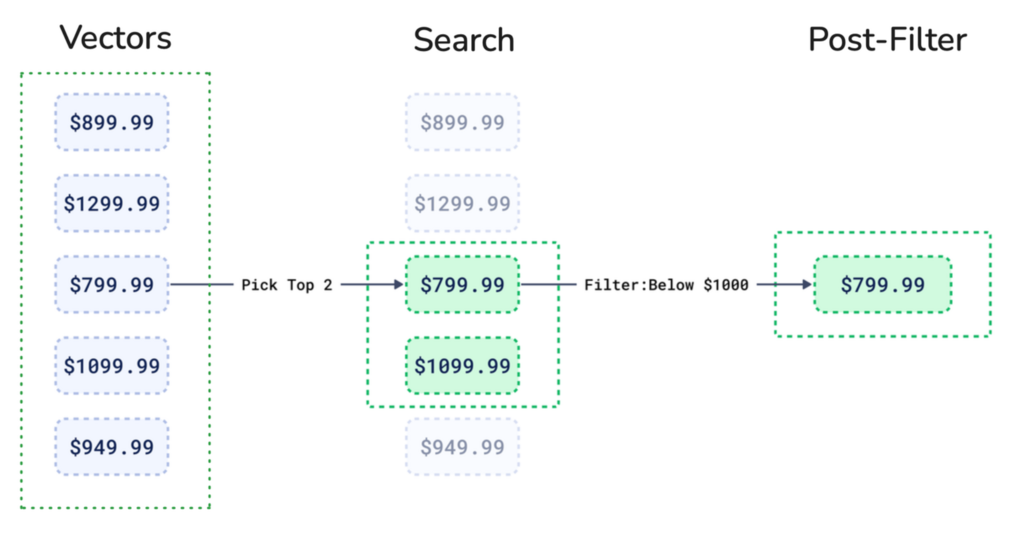
系统会浪费计算资源,因为它首先查找相似矢量,然后丢弃许多不符合过滤条件的结果。您也只能从初始的矢量搜索结果集中进行过滤。如果您想要的物品不在这个初始集合中,即使它们存在于数据库中,您也找不到它们。
基础过滤示例:电子商务和笔记本电脑
我们知道有三款可能符合我们价格点的笔记本电脑。让我们看看Qdrant的可过滤矢量索引是如何工作的,以及为什么它是捕获所有可用结果的最佳方法。
首先,为您的在线商店添加五款新的笔记本电脑。这是一个示例输入
laptops = [
(1, [0.1, 0.2, 0.3, 0.4], {"price": 899.99, "category": "laptop"}),
(2, [0.2, 0.3, 0.4, 0.5], {"price": 1299.99, "category": "laptop"}),
(3, [0.3, 0.4, 0.5, 0.6], {"price": 799.99, "category": "laptop"}),
(4, [0.4, 0.5, 0.6, 0.7], {"price": 1099.99, "category": "laptop"}),
(5, [0.5, 0.6, 0.7, 0.8], {"price": 949.99, "category": "laptop"})
]
四维矢量可以代表笔记本电脑的CPU、内存或电池寿命等特征,但在此并未指定。然而,载荷指定了确切的价格和产品类别。
现在,将过滤器设置为“价格低于1000美元”
{
"key": "price",
"range": {
"gt": null,
"gte": null,
"lt": null,
"lte": 1000
}
}
当应用价格等于/低于1000美元的过滤器时,矢量搜索返回以下结果
[
{
"id": 3,
"score": 0.9978443564622781,
"payload": {
"price": 799.99,
"category": "laptop"
}
},
{
"id": 1,
"score": 0.9938079894227599,
"payload": {
"price": 899.99,
"category": "laptop"
}
},
{
"id": 5,
"score": 0.9903751498208603,
"payload": {
"price": 949.99,
"category": "laptop"
}
}
]
如您所见,Qdrant的过滤方法更有可能捕获所有可能的搜索结果。
这个特定的示例使用了range条件进行过滤。然而,Qdrant提供了许多其他可能的过滤结构方式
有关详细的使用示例,过滤文档是最好的资源。
滚动而非搜索
您不需要使用我们的search和query API来过滤数据。scroll API是另一种选项,它允许您检索符合过滤条件的点列表。
如果您对查找相似点不感兴趣,您可以直接列出符合给定过滤器的点。搜索基于某个查询矢量为您提供最相似的点,而滚动则为您提供所有符合您过滤条件但不考虑相似性的点。
在Qdrant中,滚动用于迭代地从集合中检索大量点。当您处理大量点且不想一次性加载所有点时,这尤其有用。相反,Qdrant提供了一种方式,让您一次一页地滚动浏览这些点。
您首先向Qdrant发送一个滚动请求,其中包含特定的条件,如按载荷过滤、矢量搜索或其他标准。
让我们按商店中的价格检索前10台笔记本电脑的列表
POST /collections/online_store/points/scroll
{
"filter": {
"must": [
{
"key": "category",
"match": {
"value": "laptop"
}
}
]
},
"limit": 10,
"with_payload": true,
"with_vector": false,
"order_by": [
{
"key": "price",
}
]
}
响应包含一批符合条件的点以及用于检索下一批点的引用(偏移量或下一页令牌)。
滚动被设计为高效的。它通过一次只返回可管理的数据块,最大限度地减少服务器负载并降低客户端内存消耗。
可用过滤条件
| 条件 | 用法 | 条件 | 用法 |
|---|---|---|---|
| 匹配 | 精确值匹配。 | 范围 | 按值范围过滤。 |
| 匹配任意 | 匹配多个值。 | 日期时间范围 | 按日期范围过滤。 |
| 排除匹配 | 排除特定值。 | UUID匹配 | 按唯一ID过滤。 |
| 嵌套键 | 按嵌套数据过滤。 | 地理 | 按位置过滤。 |
| 嵌套对象 | 按嵌套对象过滤。 | 值计数 | 按元素计数过滤。 |
| 全文匹配 | 在文本字段中搜索。 | 为空 | 过滤空字段。 |
| 有ID | 按唯一ID过滤。 | 为空 | 过滤null值。 |
所有子句和条件都在Qdrant的过滤文档中有所阐述。
需要记住的过滤子句
| 子句 | 描述 | 子句 | 描述 |
|---|---|---|---|
| 必须 | 包括符合条件的项 (类似于 AND)。 | 应该 | 如果至少一个条件满足则过滤 (类似于 OR)。 |
| 不能 | 排除符合条件的项 (类似于 NOT)。 | 子句组合 | 组合多个子句以优化过滤 (类似于 AND)。 |
高级过滤示例:恐龙食性

我们还可以使用嵌套过滤来查询载荷内的对象数组。在此示例中,我们有两个点。它们分别代表一只恐龙,以及一个食物偏好(食性)列表,该列表表明它们喜欢或不喜欢的食物类型
[
{
"id": 1,
"dinosaur": "t-rex",
"diet": [
{ "food": "leaves", "likes": false},
{ "food": "meat", "likes": true}
]
},
{
"id": 2,
"dinosaur": "diplodocus",
"diet": [
{ "food": "leaves", "likes": true},
{ "food": "meat", "likes": false}
]
}
]
为确保两个条件都应用于同一个数组元素(例如,食物=肉且喜欢=真必须指代同一个食性项),您需要使用嵌套过滤器。
嵌套过滤器用于在对象数组内应用条件。它们确保条件按数组元素进行评估,而非跨所有元素。
POST /collections/dinosaurs/points/scroll
{
"filter": {
"must": [
{
"key": "diet[].food",
"match": {
"value": "meat"
}
},
{
"key": "diet[].likes",
"match": {
"value": true
}
}
]
}
}
client.scroll(
collection_name="dinosaurs",
scroll_filter=models.Filter(
must=[
models.FieldCondition(
key="diet[].food", match=models.MatchValue(value="meat")
),
models.FieldCondition(
key="diet[].likes", match=models.MatchValue(value=True)
),
],
),
)
client.scroll("dinosaurs", {
filter: {
must: [
{
key: "diet[].food",
match: { value: "meat" },
},
{
key: "diet[].likes",
match: { value: true },
},
],
},
});
use qdrant_client::qdrant::{Condition, Filter, ScrollPointsBuilder};
client
.scroll(
ScrollPointsBuilder::new("dinosaurs").filter(Filter::must([
Condition::matches("diet[].food", "meat".to_string()),
Condition::matches("diet[].likes", true),
])),
)
.await?;
import java.util.List;
import static io.qdrant.client.ConditionFactory.match;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.ScrollPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.scrollAsync(
ScrollPoints.newBuilder()
.setCollectionName("dinosaurs")
.setFilter(
Filter.newBuilder()
.addAllMust(
List.of(matchKeyword("diet[].food", "meat"), match("diet[].likes", true)))
.build())
.build())
.get();
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.ScrollAsync(
collectionName: "dinosaurs",
filter: MatchKeyword("diet[].food", "meat") & Match("diet[].likes", true)
);
发生这种情况是因为这两个点都匹配了两个条件
- “霸王龙”在
diet[1].food上匹配 food=meat,在diet[1].likes上匹配 likes=true - “梁龙”在
diet[1].food上匹配 food=meat,在diet[0].likes上匹配 likes=true
要仅检索条件应用于数组中特定元素的点(例如本示例中id为1的点),您需要使用嵌套对象过滤器。
嵌套对象过滤器可以独立查询对象数组,确保条件在单个数组元素内进行检查。
这是通过使用nested条件类型完成的,该类型包含一个指向数组的载荷键和一个要应用的过滤器。该键应引用一个对象数组,可以使用带括号或不带括号的表示法编写(例如,“data”或“data[]”)。
POST /collections/dinosaurs/points/scroll
{
"filter": {
"must": [{
"nested": {
"key": "diet",
"filter":{
"must": [
{
"key": "food",
"match": {
"value": "meat"
}
},
{
"key": "likes",
"match": {
"value": true
}
}
]
}
}
}]
}
}
client.scroll(
collection_name="dinosaurs",
scroll_filter=models.Filter(
must=[
models.NestedCondition(
nested=models.Nested(
key="diet",
filter=models.Filter(
must=[
models.FieldCondition(
key="food", match=models.MatchValue(value="meat")
),
models.FieldCondition(
key="likes", match=models.MatchValue(value=True)
),
]
),
)
)
],
),
)
client.scroll("dinosaurs", {
filter: {
must: [
{
nested: {
key: "diet",
filter: {
must: [
{
key: "food",
match: { value: "meat" },
},
{
key: "likes",
match: { value: true },
},
],
},
},
},
],
},
});
use qdrant_client::qdrant::{Condition, Filter, NestedCondition, ScrollPointsBuilder};
client
.scroll(
ScrollPointsBuilder::new("dinosaurs").filter(Filter::must([NestedCondition {
key: "diet".to_string(),
filter: Some(Filter::must([
Condition::matches("food", "meat".to_string()),
Condition::matches("likes", true),
])),
}
.into()])),
)
.await?;
import java.util.List;
import static io.qdrant.client.ConditionFactory.match;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import static io.qdrant.client.ConditionFactory.nested;
import io.qdrant.client.grpc.Points.Filter;
import io.qdrant.client.grpc.Points.ScrollPoints;
client
.scrollAsync(
ScrollPoints.newBuilder()
.setCollectionName("dinosaurs")
.setFilter(
Filter.newBuilder()
.addMust(
nested(
"diet",
Filter.newBuilder()
.addAllMust(
List.of(
matchKeyword("food", "meat"), match("likes", true)))
.build()))
.build())
.build())
.get();
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.ScrollAsync(
collectionName: "dinosaurs",
filter: Nested("diet", MatchKeyword("food", "meat") & Match("likes", true))
);
匹配逻辑被调整为在载荷数组中独立元素的级别上操作,而不是对所有数组元素一起操作。
嵌套过滤器的工作原理就像数组的每个元素都单独评估一样。如果至少有一个数组元素满足所有嵌套过滤条件,则父文档将被视为匹配项。
过滤器的其他创意用途
您可以使用过滤器检索数据点,而无需知道其id。您仅通过使用过滤器即可搜索和管理数据。让我们看看过滤器的一些创意用途
| 操作 | 描述 | 操作 | 描述 |
|---|---|---|---|
| 删除点 | 删除所有匹配过滤器的点。 | 设置载荷 | 为所有匹配过滤器的点添加载荷字段。 |
| 滚动点 | 列出所有匹配过滤器的点。 | 更新载荷 | 更新匹配过滤器的点的载荷字段。 |
| 排序点 | 列出所有点,按过滤器排序。 | 删除载荷 | 删除匹配过滤器的点的字段。 |
| 计数点 | 统计匹配过滤器的点的总数。 |
使用载荷索引进行过滤

当您开始使用Qdrant时,您的数据默认按矢量索引组织。此外,我们建议添加一个辅助数据结构——载荷索引。
就像矢量索引组织矢量一样,载荷索引会组织您的元数据。
图4:载荷索引是支持矢量搜索的附加数据结构。载荷索引(绿色部分)按基数组织候选结果,以便语义搜索(红色部分)可以快速遍历矢量索引。
仅靠语义搜索对数太字节的数据进行搜索会占用大量RAM。过滤和索引是两种简单的策略,可以减少您的计算使用量并仍然获得最佳结果。请记住,这只是一个指南。有关过滤选项的完整列表,您应阅读过滤文档。
以下是如何为元数据字段“category”创建一个单一索引
PUT /collections/computers/index
{
"field_name": "category",
"field_schema": "keyword"
}
from qdrant_client import QdrantClient
client = QdrantClient(url="https://:6333")
client.create_payload_index(
collection_name="computers",
field_name="category",
field_schema="keyword",
)
一旦您将字段标记为可索引,您无需做任何其他事情。Qdrant将在后台处理所有优化。
为什么应该索引元数据?

载荷索引充当辅助数据结构,可加快检索速度。无论何时您使用过滤器运行矢量搜索,Qdrant都会查询载荷索引——如果存在的话。
随着数据集复杂性的增加,Qdrant需要额外的资源来遍历所有数据点。如果没有适当的数据结构,搜索可能需要更长时间——或资源耗尽。
载荷索引有助于评估最具限制性的过滤器
载荷索引也用于准确估计过滤器基数,这有助于查询规划选择搜索策略。过滤器基数是指过滤器在数据集中可以匹配的 distinct 值的数量。如果基数过低,Qdrant的搜索策略可以从HNSW搜索切换到基于载荷索引的搜索。
这如何影响您的查询:根据搜索中使用的过滤器,查询执行有几种可能的场景。Qdrant根据可用的索引、条件的复杂性和过滤结果的基数选择其中一种查询执行选项。
- 规划器在选择策略之前会估计过滤结果的基数。
- 如果基数低于阈值,Qdrant会使用载荷索引检索点。
- 如果基数高于阈值,Qdrant会使用可过滤矢量索引
如果不使用载荷索引会发生什么?
在使用过滤器进行查询时,Qdrant需要估算这些过滤器的基数以定义合适的查询计划。如果您不创建载荷索引,Qdrant将无法做到这一点。它最终可能会选择次优的搜索方式,导致搜索时间极慢或结果准确性低。
如果您只依赖于搜索最近矢量,Qdrant将不得不遍历整个矢量索引。它将计算集合中每个矢量(无论是否相关)的相似度。或者,当您借助载荷索引进行过滤时,HSNW算法无需评估每个点。此外,载荷索引将帮助HNSW构建带有附加链接的图。
载荷索引是什么样子的?
载荷索引类似于传统的面向文档的数据库。它将元数据字段与其对应的点ID连接起来,以便快速检索。
在此示例中,您正在computers集合中索引所有计算机硬件。让我们看看字段category的示例载荷索引。
Payload Index by keyword:
+------------+-------------+
| category | id |
+------------+-------------+
| laptop | 1, 4, 7 |
| desktop | 2, 5, 9 |
| speakers | 3, 6, 8 |
| keyboard | 10, 11 |
+------------+-------------+
当字段被正确索引时,搜索引擎大致知道从何处开始其旅程。它可以开始查找包含相关元数据的数据点,而无需扫描整个数据集。这大大减少了引擎的工作负载。因此,查询结果更快,系统也更容易扩展。
您可以根据需要创建任意数量的载荷索引,我们建议您为您按其过滤的每个字段都这样做。
如果您的用户在查找产品类别时经常按笔记本电脑过滤,索引所有计算机元数据将加快检索速度并使结果更精确。
不同类型的载荷索引
| 索引类型 | 描述 |
|---|---|
| 全文索引 | 在大数据集中实现高效文本搜索。 |
| 租户索引 | 用于多租户架构中的数据隔离和检索效率。 |
| 主体索引 | 根据用户或账户等主要实体管理数据。 |
| 磁盘索引 | 将索引存储在磁盘上,用于管理大数据集而无需占用内存。 |
| 参数化索引 | 允许动态查询,索引可以根据用户提供的不同参数或条件进行调整。适用于价格或时间戳等数值数据。 |
在多租户设置中索引载荷
一些应用程序需要数据隔离,以便不同的用户在同一程序中看到不同的数据。在为此类复杂应用程序设置存储时,许多用户认为他们需要为隔离用户设置多个数据库。
我们经常看到这种情况。用户非常频繁地犯错,在同一个集群内为每个租户创建一个单独的集合。这会很快耗尽集群的资源。通过太多集合运行矢量搜索可能会开始占用过多的RAM。您可能会开始看到内存不足(OOM)错误和性能下降。
为了缓解这种情况,我们为多租户系统提供了广泛的支持,以便您可以在一个单一的Qdrant集合中构建整个全球应用程序。
创建或更新集合时,可以将元数据字段标记为可索引。要在共享集合中将user_id标记为租户,请执行以下操作
PUT /collections/{collection_name}/index
{
"field_name": "user_id",
"field_schema": {
"type": "keyword",
"is_tenant": true
}
}
此外,我们提供了一种通过租户索引高效组织数据的方式。这是载荷索引的另一种变体,它使得租户数据更易于访问。此时,请求会将该字段指定为租户。这意味着您可以将各种客户类型和用户ID标记为is_tenant: true。
了解更多关于在多租户环境中设置租户碎片整理的信息,
过滤和索引的关键要点

使用浮点数(小数)进行过滤
如果您按浮点数据类型过滤,您的搜索精度可能会受到限制且不准确。
浮点类型数字带有小数点,大小为64位。这里有一个示例
{
"price": 11.99
}
当您过滤特定浮点数(如11.99)时,您可能会得到不同的结果,例如11.98或12.00。由于小数的舍入方式不同,逻辑上相同的值可能看起来不同。在这种情况下,搜索精确匹配可能不可靠。
为避免不准确性,请使用不同的过滤方法。我们建议您尝试基于范围的过滤而不是精确匹配。这种方法考虑了数据中的微小差异,并提高了性能——尤其是在大型数据集上。
这里是一个示例JSON范围过滤器,用于查找大于等于11.99且小于等于该数字的值。这将检索11.99范围内的任何值,包括具有额外小数位的值。
{
"key": "price",
"range": {
"gt": null,
"gte": 11.99,
"lt": null,
"lte": 11.99
}
}
在查询中使用分页
在过滤查询中实现分页时,索引变得更加关键。对结果进行分页时,您通常需要排除已经看过的项。这通常通过应用过滤器来管理,指定哪些ID不应包含在下一组结果中。
然而,Qdrant数据模型一个有趣的方面是,单个点可以拥有同一字段的多个值,例如产品的不同颜色选项。这意味着在过滤时,如果一个ID匹配同一字段的不同值,它可能会出现多次。
正确的索引可以确保这些查询高效运行,防止重复结果并使分页更流畅。
结论:过滤的实际用例
在Qdrant这样的矢量数据库中进行过滤,可以通过实现更精确高效的数据检索,显著增强搜索能力。
作为本指南的总结,让我们看看一些过滤至关重要的实际用例
| 用例 | 矢量搜索 | 过滤 |
|---|---|---|
| 电子商务产品搜索 | 按样式或视觉相似度搜索产品 | 按价格、颜色、品牌、尺寸、评分过滤 |
| 推荐系统 | 推荐相似内容(如电影、歌曲) | 按发布日期、类型等过滤(例如,2020年后的电影) |
| 网约车中的地理空间搜索 | 寻找相似的司机或送货伙伴 | 按评分、距离半径、车辆类型过滤 |
| 欺诈与异常检测 | 检测与已知欺诈案例相似的交易 | 按金额、时间、位置过滤 |
离开之前——所有代码都在Qdrant的控制面板中
实现“Hello World”最简单的方法是在实时集群中尝试过滤。我们的交互式教程将向您展示如何创建集群、添加数据并尝试一些过滤子句。
都在您的免费集群中!
