
向量量化是一种数据压缩技术,用于减小高维数据的大小。压缩向量可减少内存使用,同时保留几乎所有必要信息。此方法可提高存储效率并加快搜索操作速度,尤其适用于大型数据集。
处理高维向量时,例如来自 OpenAI 等提供商的嵌入向量,一个单一的 1536 维向量需要 6 KB 的内存。
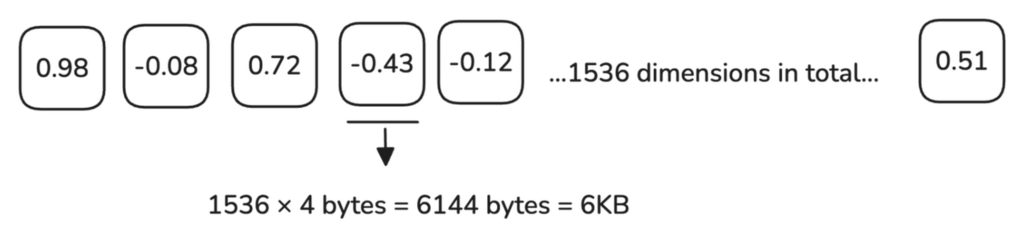
100 万个向量大约需要 6 GB 内存,随着数据集增长到数百万个向量,内存和处理需求显著增加。
要理解为何此过程计算需求如此之高,让我们来看一下 HNSW 索引的本质。
HNSW(分层可导航小世界)索引以分层图的形式组织向量,将每个向量连接到其最近邻居。在每一层,算法缩小搜索区域,直到到达较低层,从而有效地找到与查询最接近的匹配项。
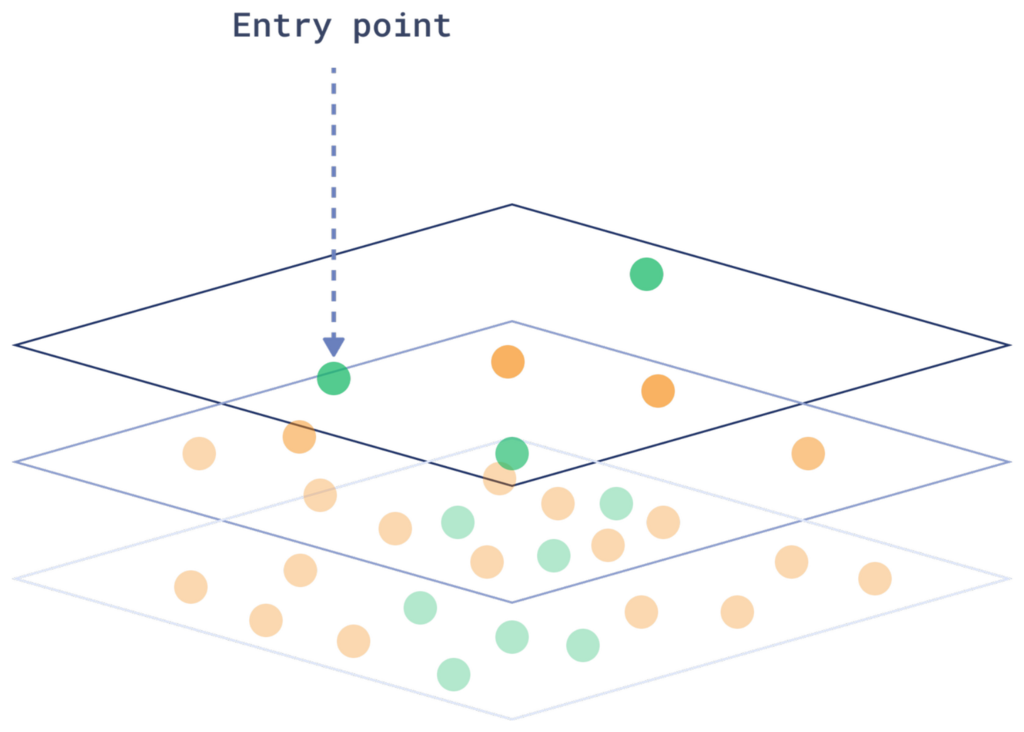
每次添加新向量时,系统必须确定其在现有图中的位置,这个过程类似于搜索。这使得向量的插入和搜索都成为复杂的操作。
HNSW 索引面临的关键挑战之一是它需要大量的随机读取和在图中进行顺序遍历。这使得此过程计算成本高昂,尤其是在处理数百万个高维向量时。
系统必须以不可预测的方式在图中的各个点之间跳转。这种不可预测性使得优化变得困难,并且随着数据集的增长,内存和处理需求显著增加。
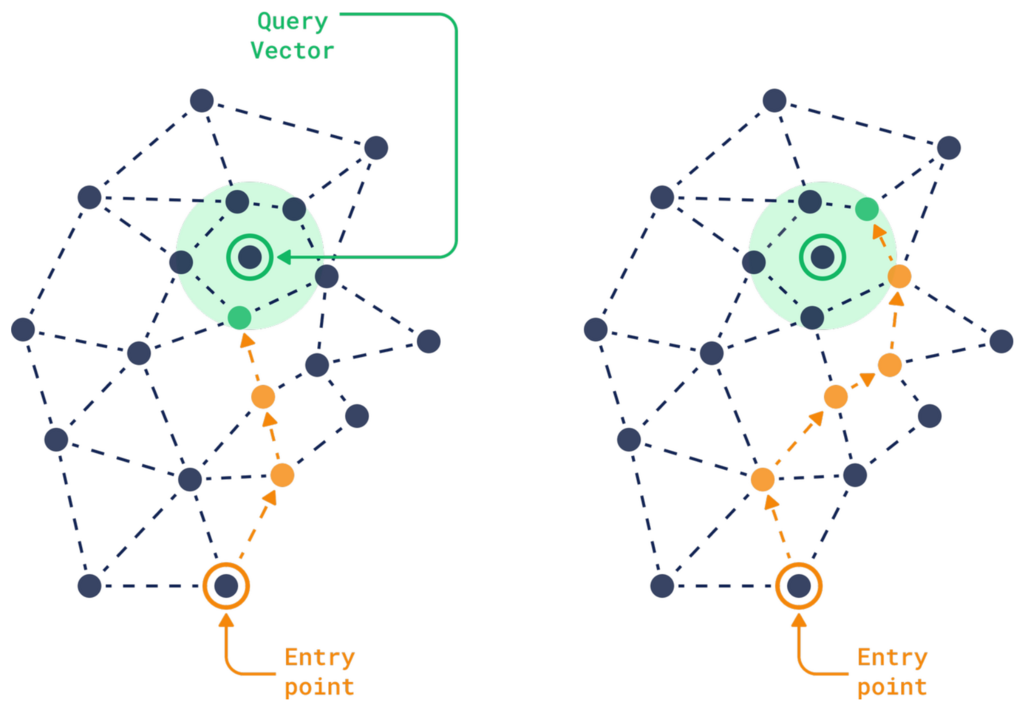
由于向量需要存储在如 RAM 或 SSD 之类的快速存储中以实现低延迟搜索,随着数据大小的增长,有效存储和处理它的成本也随之增加。
量化提供了一种解决方案,通过将向量压缩到更小的内存大小,使过程更有效率。
有几种方法可以实现这一点,在这里我们将重点介绍三种主要方法

1. 什么是标量量化?

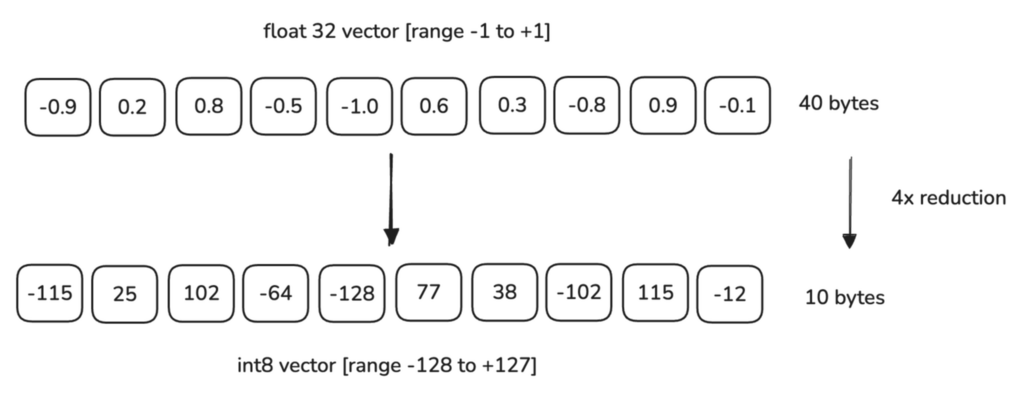
在 Qdrant 中,每个维度由一个 float32 值表示,它使用 4 字节内存。使用 标量量化时,我们将向量映射到一个更小的 int8 类型可以表示的范围。一个 int8 只占 1 字节,可以表示 256 个值(从 -128 到 127,或 0 到 255)。这将使内存大小减少 75%。
例如,如果我们的数据范围在 -1.0 到 1.0 之间,标量量化会将这些值转换为 int8 可以表示的范围,即在 -128 到 127 之间。系统会映射 float32 值到此范围。
这是一个此过程的简单线性示例:
要在 Qdrant 中设置标量量化,您需要在创建或更新集合时包含 quantization_config 部分:
PUT /collections/{collection_name}
{
"vectors": {
"size": 128,
"distance": "Cosine"
},
"quantization_config": {
"scalar": {
"type": "int8",
"quantile": 0.99,
"always_ram": true
}
}
}
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=128, distance=models.Distance.COSINE),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
quantile=0.99,
always_ram=True,
),
),
)
quantile 参数用于计算量化边界。例如,如果您指定 0.99 分位数,最极端的 1% 值将被排除在量化边界之外。
此参数仅影响结果精度,不影响内存占用。如果搜索质量显著下降,您可以调整它。
如果您希望提高搜索速度和压缩率而不过多损失精度,标量量化是一个不错的选择。它还能稍微提高性能,因为使用 int8 值进行距离计算(如点积或余弦相似度)比使用 float32 值计算简单得多。
虽然标量量化的性能提升可能无法与二值量化(我们稍后讨论)相比,但在二值量化不适合您的用例时,它仍然是一个出色的默认选择。
2. 什么是二值量化?

二值量化是一个绝佳的选择,如果您希望减少内存使用同时显著提升速度。它通过将高维向量转换为简单的二值(0 或 1)表示来实现。
- 大于零的值转换为 1。
- 小于或等于零的值转换为 0。
考虑我们最初的例子,一个 1536 维向量需要 6 KB 内存(每个 float32 值 4 字节)。
经过二值量化后,每个维度减少到 1 位(1/8 字节),因此所需内存为:
$$ \frac{1536 \text{ dimensions}}{8 \text{ bits per byte}} = 192 \text{ bytes} $$
这带来了 32 倍的内存减少。
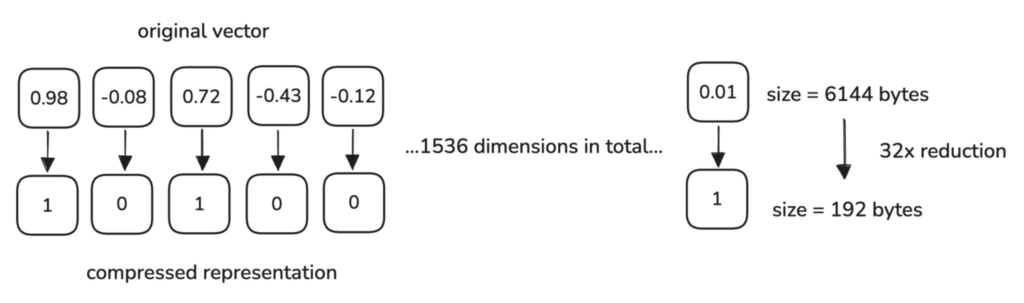
Qdrant 在索引期间自动执行二值量化过程。向量被添加到您的集合时,每个 32 位浮点分量将根据您定义的配置转换为二值。
设置方法如下:
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"binary": {
"always_ram": true
}
}
}
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True,
),
),
)
与标量量化和乘积量化相比,二值量化是提供最显著处理速度提升的量化方法。这是因为二值表示允许系统使用高度优化的 CPU 指令,例如 XOR 和 Popcount,以实现快速距离计算。
根据数据集和硬件的不同,它可以将搜索操作速度提高高达 40 倍。
并非所有模型都与二值量化同样兼容,在上面的比较中,我们仅使用了兼容的模型。某些模型量化后可能会出现更大的精度损失。我们建议对至少具有 1024 维度的模型使用二值量化,以最大程度地减少精度损失。
已显示与此方法具有最佳兼容性的模型包括:
- OpenAI text-embedding-ada-002 (1536 维)
- Cohere AI embed-english-v2.0 (4096 维)
这些模型在获得显著的速度和内存提升的同时,精度损失最小。
尽管二值量化速度极快且内存效率高,但其权衡在于精度和模型兼容性,因此您可能需要使用过采样和重评分等技术来确保搜索质量。
如果您有兴趣更详细地了解二值量化,包括实现示例、基准测试结果和使用建议,请查阅我们关于二值量化 - 向量搜索,速度提升 40 倍的专题文章。
3. 什么是乘积量化?

乘积量化是一种通过用一组较小的代表性点来表示高维向量,从而对其进行压缩的方法。
这个过程首先将原始高维向量分割成更小的子向量。每个子向量代表原始向量的一部分,捕获数据的不同特征。
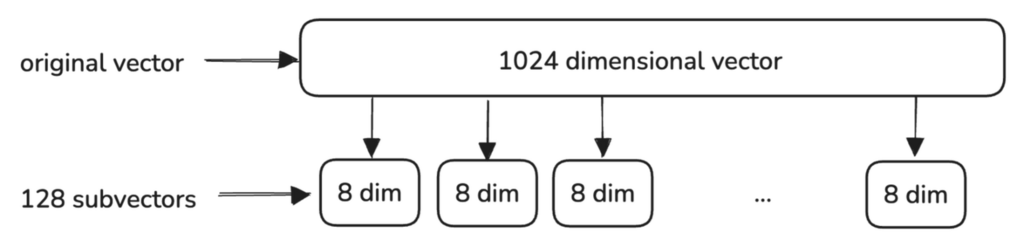
为每个子向量创建一个单独的码本,代表数据空间中常见模式出现的区域。
Qdrant 中的码本在索引过程中自动训练。当向量添加到集合时,Qdrant 使用您在 quantization_config 中指定的量化设置来构建码本并量化向量。设置方法如下:
PUT /collections/{collection_name}
{
"vectors": {
"size": 1024,
"distance": "Cosine"
},
"quantization_config": {
"product": {
"compression": "x32",
"always_ram": true
}
}
}
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1024, distance=models.Distance.COSINE),
quantization_config=models.ProductQuantization(
product=models.ProductQuantizationConfig(
compression=models.CompressionRatio.X32,
always_ram=True,
),
),
)
码本中的每个区域由一个质心定义,该质心作为代表性点,总结了该区域的特征。我们不将每个数据点都视为同等重要,而是可以将相似的子向量分组在一起,并用一个捕获该组一般特征的单个质心来代表它们。
乘积量化中使用的质心是使用 K-means 聚类算法确定的。
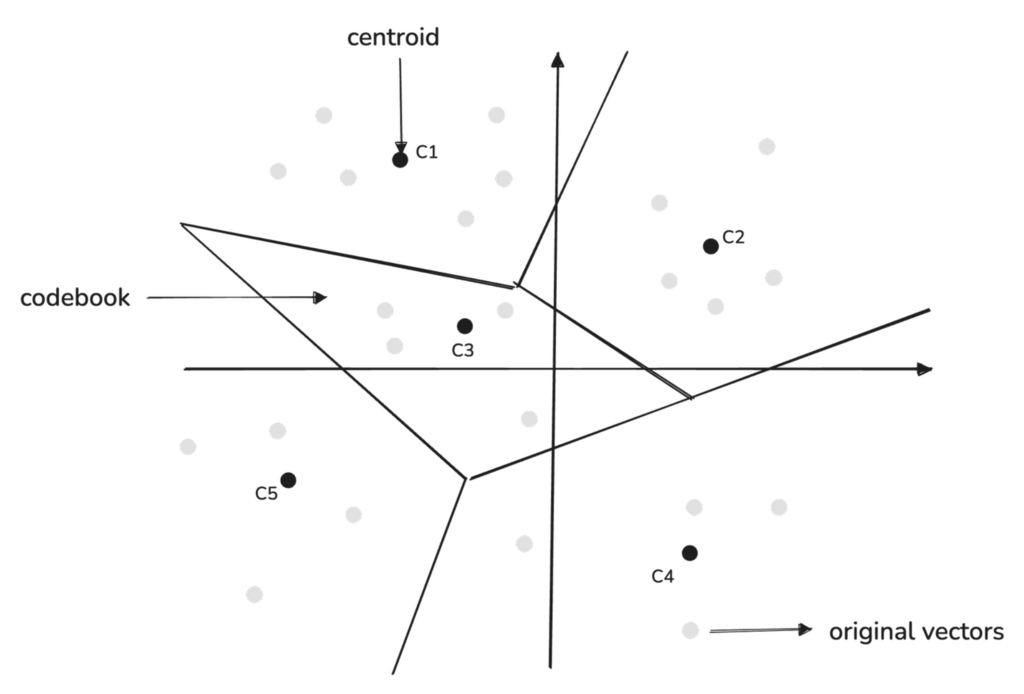
Qdrant 在其实现中始终选择 K = 256 作为质心的数量,这是基于 256 是单个字节可以表示的最大唯一值的这一事实。
这使得压缩过程非常高效,因为每个质心索引都可以存储在一个字节中。
原始高维向量通过将每个子向量映射到其相应码本中最接近的质心来量化。
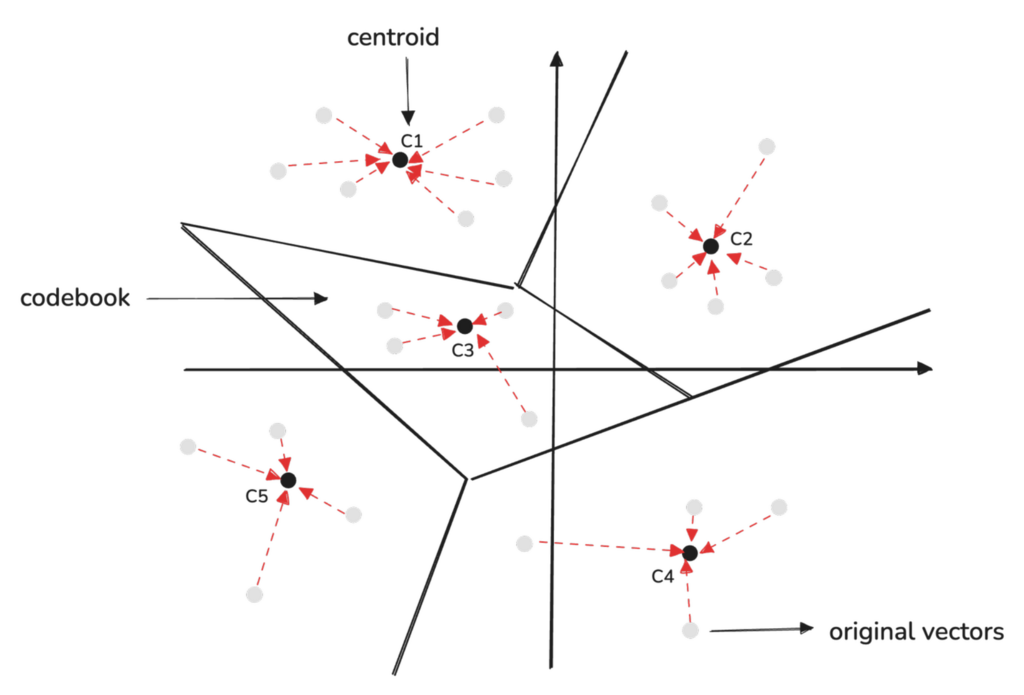
压缩后的向量存储每个子向量最接近的质心的索引。
例如,一个 1024 维向量,最初占用 4096 字节,通过将其表示为 128 个索引(每个索引指向一个子向量的质心),被减少到仅 128 字节:
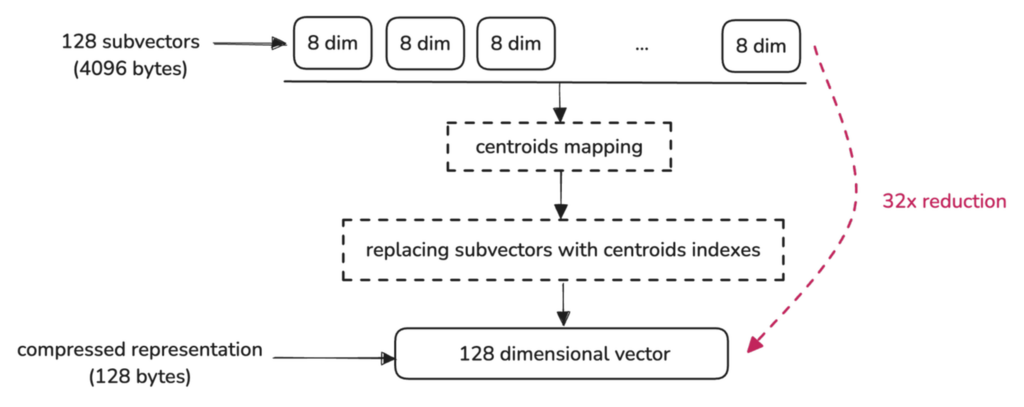
设置量化并添加向量后,您可以像往常一样执行搜索。Qdrant 将自动使用量化向量,从而优化速度和内存使用。您可以选择启用重评分以获得更高的精度。
POST /collections/{collection_name}/points/search
{
"query": [0.22, -0.01, -0.98, 0.37],
"params": {
"quantization": {
"rescore": true
}
},
"limit": 10
}
client.query_points(
collection_name="my_collection",
query_vector=[0.22, -0.01, -0.98, 0.37], # Your query vector
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
rescore=True # Enables rescoring with original vectors
)
),
limit=10 # Return the top 10 results
)
乘积量化可以显著减少内存使用,在某些配置下可实现高达 64 倍的压缩。然而,需要注意的是,这种程度的压缩可能会导致质量显著下降。
如果您的应用程序需要高精度或实时性能,乘积量化可能不是最佳选择。但是,如果节省内存至关重要且可接受一定程度的精度损失,它仍然可能是一个理想的解决方案。
以下是三种方法在速度、精度和压缩方面的比较,改编自 Qdrant 文档:
| 量化方法 | 精度 | 速度 | 压缩率 |
|---|---|---|---|
| 标量 | 0.99 | 高达 2倍 | 4 |
| 乘积 | 0.7 | 0.5 | 高达 64倍 |
| 二值 | 0.95* | 高达 40倍 | 32 |
* - 适用于兼容模型
要更深入地了解您可以预期的基准测试结果,请查阅我们关于向量搜索中的乘积量化的专题文章。
重评分、过采样和重新排名
当我们使用标量、二值或乘积量化等量化方法时,我们正在压缩向量以节省内存并提高性能。然而,这种压缩会去除原始向量的一些细节。
这可能会稍微降低相似性搜索的精度,因为量化向量是原始数据的近似。为了减轻这种精度损失,您可以使用过采样和重评分,这有助于提高最终搜索结果的精度。
在此过程中,原始向量从未被删除,您可以随时通过更新集合配置轻松切换量化方法或参数。
此过程分步工作原理如下:
1. 初步量化搜索
执行搜索时,Qdrant 根据量化数据确定的与查询向量的相似性,使用量化向量检索前 K 个候选。这一步很快,因为我们使用的是量化向量。

2. 过采样
过采样是一种有助于弥补因量化而损失的精度的技术。由于量化简化了向量,初步搜索中可能会遗漏一些相关的匹配项。为了避免这种情况,您可以检索更多候选者,增加最相关向量进入最终结果的机会。
您可以通过设置 oversampling 参数来控制额外候选者的数量。例如,如果您所需的检索结果数量 (limit) 是 4,并且您设置了 2 的 oversampling 系数,Qdrant 将检索 8 个候选者 (4 × 2)。
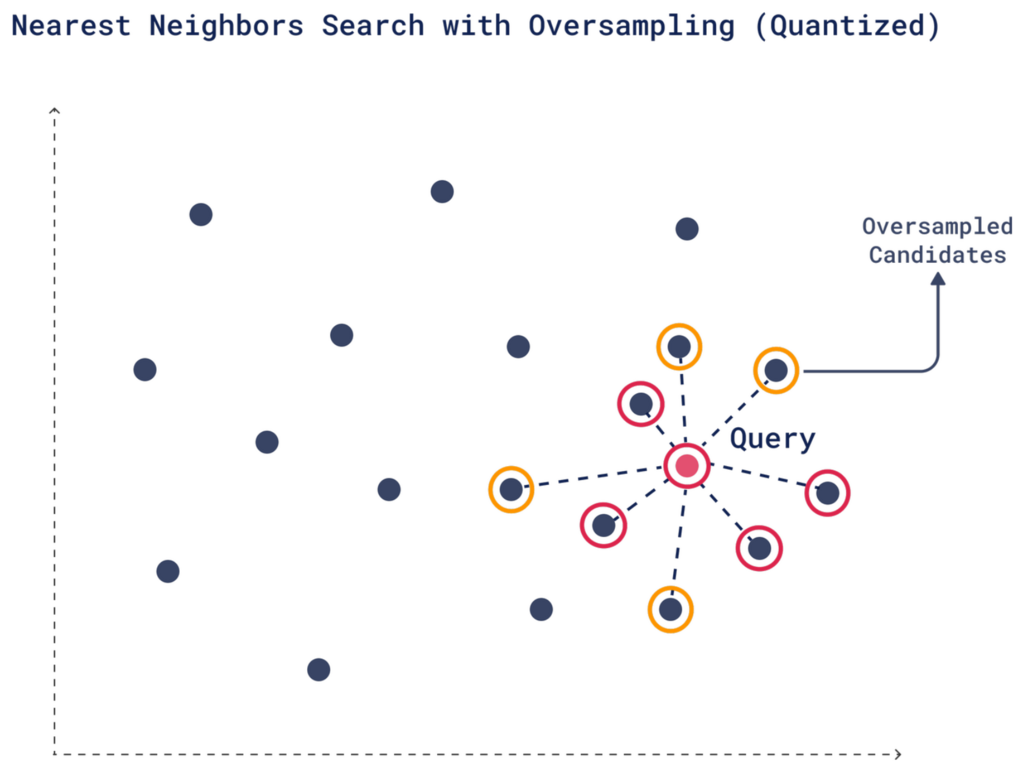
您可以调整过采样系数,以控制 Qdrant 在初始池中包含多少额外向量。更多候选者意味着更有机会获得高质量的 Top-K 结果,尤其是在使用原始向量重评分之后。
3. 使用原始向量重评分
在过采样收集更多潜在匹配项后,将根据附加标准重新评估每个候选项,以确保对查询具有更高的精度和相关性。
重评分过程将量化向量映射到其对应的原始向量,使您可以考虑上下文、元数据或未包含在初步搜索中的附加相关性等因素,从而获得更精确的结果。
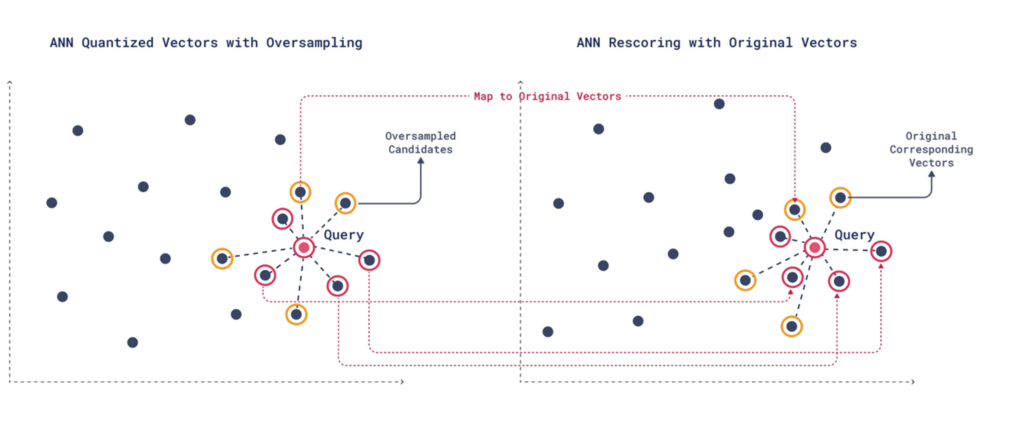
在重评分过程中,过采样中排名较低的候选者之一可能被证明是比原始 Top-K 候选者中某些更好的匹配。
尽管重评分使用原始的、较大的向量,但由于只读取了非常少量的向量,该过程仍然快得多。初步的量化搜索已经确定了要读取、重评分和重新排名的特定向量。
4. 重新排名
利用重评分产生的新相似度分数,重新排名是根据更新后的相似度分数确定最终 Top-K 候选者的过程。
例如,在我们设置 limit 为 4 的情况下,一个在初步量化搜索中排名第 6 的候选者在重评分后其分数可能会提高,因为原始向量捕获了更多上下文或元数据。结果,该候选者在重新排名后可能会进入最终的前 4 名,取代初步搜索中一个不太相关的选项。
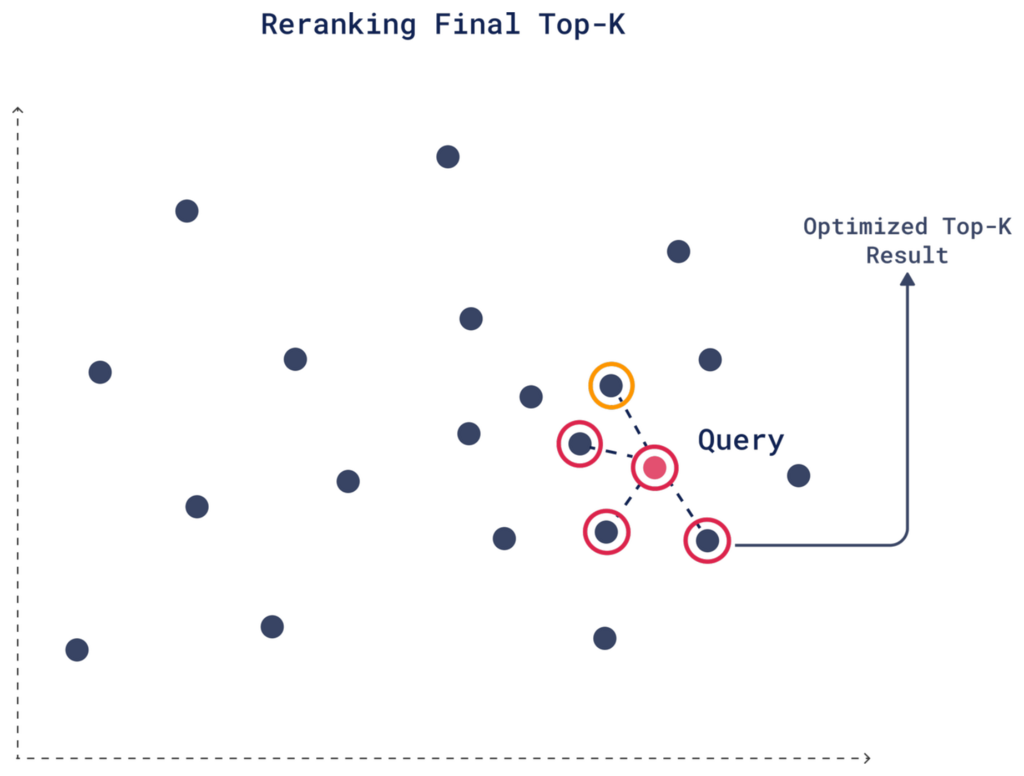
设置方法如下:
POST /collections/{collection_name}/points/search
{
"query": [0.22, -0.01, -0.98, 0.37],
"params": {
"quantization": {
"rescore": true,
"oversampling": 2
}
},
"limit": 4
}
client.query_points(
collection_name="my_collection",
query_vector=[0.22, -0.01, -0.98, 0.37],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
rescore=True, # Enables rescoring with original vectors
oversampling=2 # Retrieves extra candidates for rescoring
)
),
limit=4 # Desired number of final results
)
您可以调整 oversampling 系数,在搜索速度和结果精度之间找到适当的平衡。
如果量化影响了需要高精度的应用程序的性能,将过采样与重评分结合是一个不错的选择。然而,如果您需要更快的搜索并且可以容忍一定的精度损失,您可能选择使用过采样而不进行重评分,或者将过采样系数调整到较低的值。
在磁盘与内存之间分配资源
Qdrant 存储量化和原始向量。默认情况下,启用量化时,原始向量和量化向量都存储在 RAM 中。您可以将原始向量移动到磁盘以显著减少 RAM 使用并降低系统成本。仅仅启用量化是不够的——您需要通过设置 on_disk=True 显式将原始向量移动到磁盘。
这是一个配置示例:
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine",
"on_disk": true # Move original vectors to disk
},
"quantization_config": {
"binary": {
"always_ram": true # Store only quantized vectors in RAM
}
}
}
client.update_collection(
collection_name="my_collection",
vectors_config=models.VectorParams(
size=1536,
distance=models.Distance.COSINE,
on_disk=True # Move original vectors to disk
),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True # Store only quantized vectors in RAM
)
)
)
如果不显式设置 on_disk=True,即使启用了量化,您也看不到任何 RAM 节省。因此,请务必根据您的内存和性能需求配置存储和量化选项。如果您的存储磁盘延迟高,考虑禁用重评分以保持速度。
使用 io_uring 加速重评分
处理大量量化向量集合时,需要频繁读取磁盘以获取原始数据和压缩数据进行重评分操作。虽然 mmap 通过减少用户态到内核态的转换有助于提高 I/O 效率,但在处理磁盘上的大型数据集时,由于需要频繁读取磁盘,重评分仍然可能变慢。
在基于 Linux 的系统上,io_uring 允许多个磁盘操作并行处理,从而显著减少 I/O 开销。这种优化在重评分期间尤其有效,因为在初步搜索之后需要重新评估多个向量。使用 io_uring,Qdrant 可以以最高效的方式从磁盘检索和重评分向量,从而提高整体搜索性能。
当您执行向量量化并将数据存储在磁盘上时,Qdrant 通常需要并行访问多个向量。如果没有 io_uring,由于系统在处理许多磁盘访问方面的限制,此过程可能会变慢。
要在 Qdrant 中启用 io_uring,请将以下内容添加到您的存储配置中:
storage:
async_scorer: true # Enable io_uring for async storage
如果未进行此配置,Qdrant 将默认使用 mmap 进行磁盘 I/O 操作。
有关 io_uring 与传统 I/O 方法(如 mmap)的比较及其基准测试的更多信息,请查阅Qdrant 的 io_uring 实现文章。
量化数据与非量化数据的性能对比
如果量化向量可用,Qdrant 默认使用它们。如果您想评估量化对搜索结果的影响,可以暂时禁用它来比较量化搜索和非量化搜索的结果。为此,请在查询中设置 ignore: true:
POST /collections/{collection_name}/points/query
{
"query": [0.22, -0.01, -0.98, 0.37],
"params": {
"quantization": {
"ignore": true,
}
},
"limit": 4
}
client.query_points(
collection_name="{collection_name}",
query=[0.22, -0.01, -0.98, 0.37],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
ignore=True
)
),
)
切换量化方法
不确定您是否选择了正确的量化方法?在 Qdrant 中,您可以灵活地移除量化并仅依靠原始向量,调整量化类型,或随时更改压缩参数,而不会影响您的原始向量。
例如,要切换到二值量化并调整压缩率,您可以使用 update_collection 方法更新集合的量化配置:
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"binary": {
"always_ram": true,
"compression_rate": 0.8 # Set the new compression rate
}
}
}
client.update_collection(
collection_name="my_collection",
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True, # Store only quantized vectors in RAM
compression_rate=0.8 # Set the new compression rate
)
),
)
如果您决定关闭量化并仅使用原始向量,您可以使用 quantization_config=None 完全移除量化设置:
PUT /collections/my_collection
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": null # Remove quantization and use original vectors only
}
client.update_collection(
collection_name="my_collection",
quantization_config=None # Remove quantization and rely on original vectors only
)
总结

标量量化、乘积量化和二值量化等量化方法提供了强大的方式来优化内存使用和提高搜索性能,尤其是在处理大量高维向量数据集时。每种方法都在内存节省、计算速度和精度之间权衡。
以下是一些最后的思考,帮助您为您的需求选择正确的量化方法:
| 量化方法 | 主要特点 | 何时使用 |
|---|---|---|
| 二值量化 | • 最快且内存效率最高的方法 • 搜索速度提升高达 40倍,内存占用减少 32倍 | • 与经过测试的模型配合使用,如 OpenAI 的 text-embedding-ada-002 和 Cohere 的 embed-english-v2.0• 当速度和内存效率至关重要时 |
| 标量量化 | • 精度损失最小 • 内存占用减少高达 4倍 | • 大多数应用程序的安全默认选择。 • 在精度、速度和压缩之间提供了良好的平衡。 |
| 乘积量化 | • 最高压缩率 • 内存占用减少高达 64倍 | • 当最大程度减少内存占用是首要任务时 • 如果可以容忍一定的精度损失和较慢的索引速度,这是可接受的 |
了解更多
如果您想了解更多关于在使用 Qdrant 进行量化时如何提高精度、内存效率和速度的信息,我们的文档中有一个专门的量化技巧部分,解释了所有可用于提升结果的量化技巧。
通过观看 Qdrant CTO Andrey Vasnetsov 的此访谈,了解更多关于如何在二值量化中使用过采样来优化实时精度:
关注向量搜索和量化的最新动态,分享您的项目,提问,加入我们的向量搜索社区!